-
-
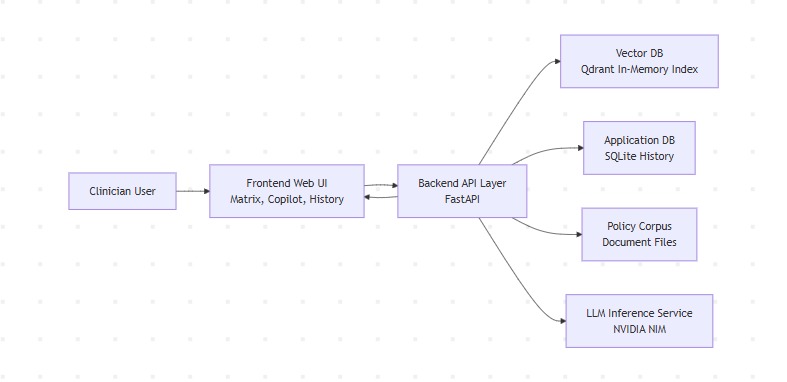
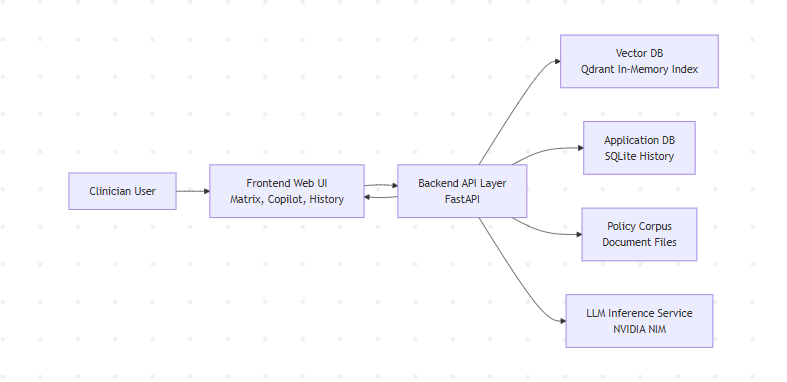
High-Level Architecture
-
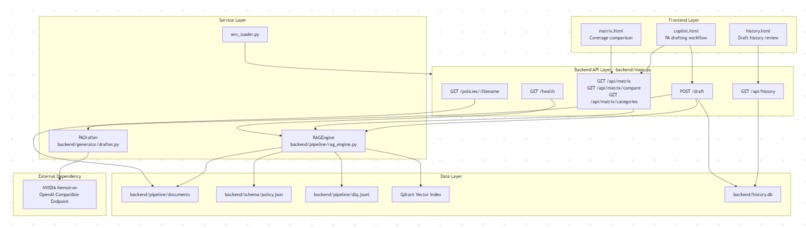
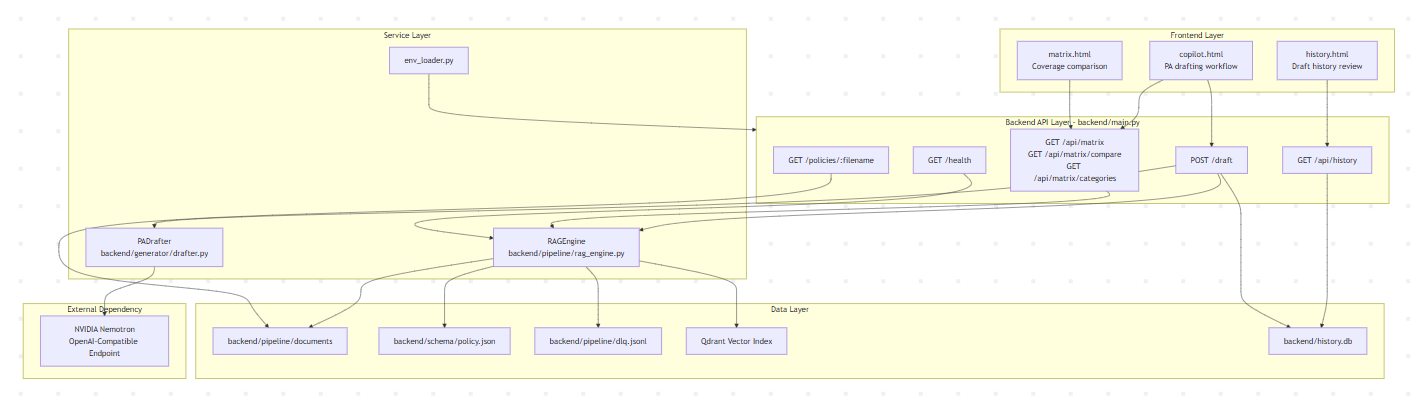
Low-Level Architecture
-
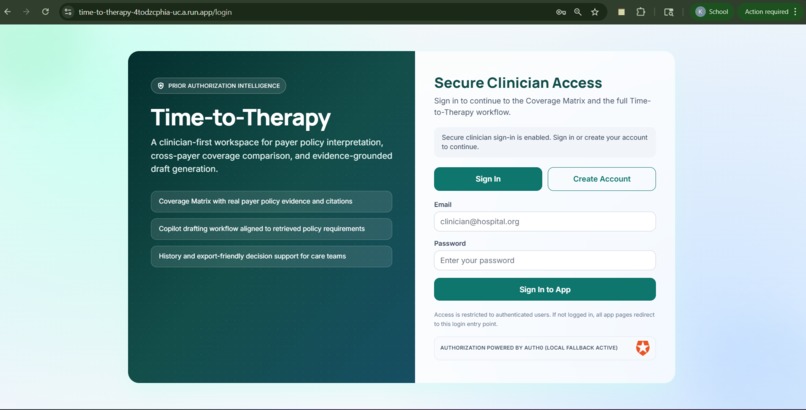
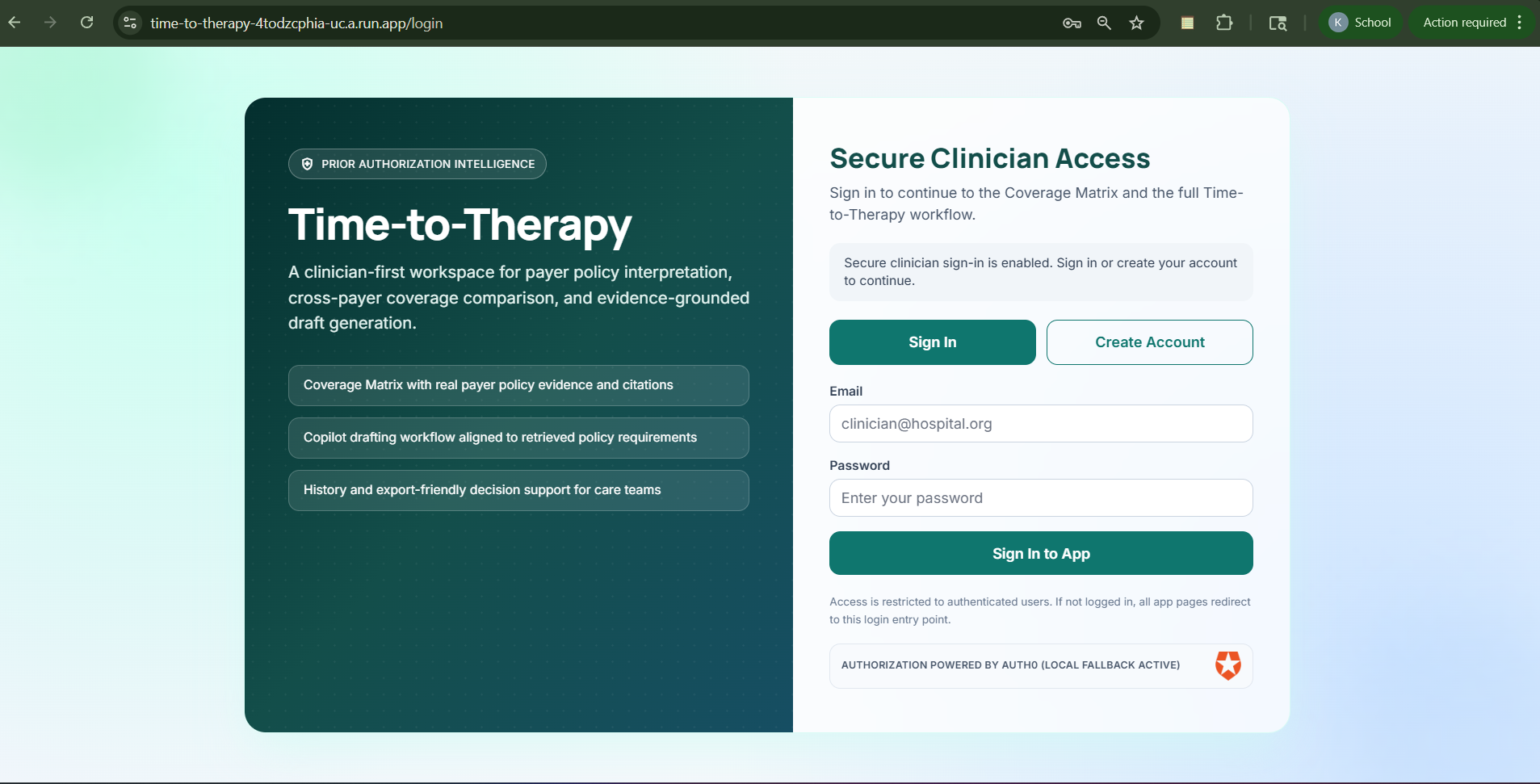
Login & Signup Page
-
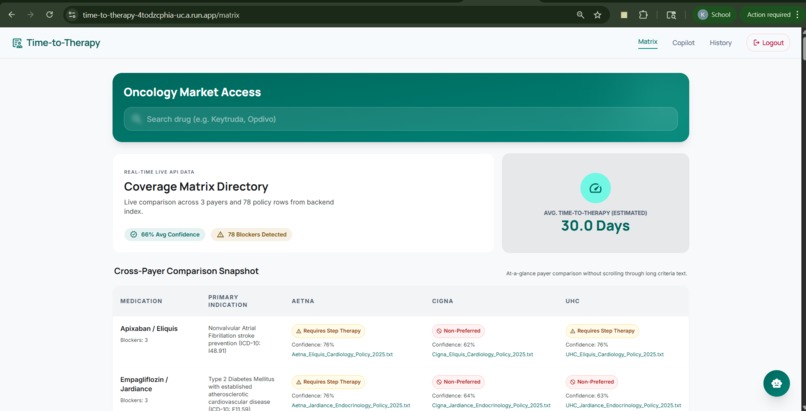
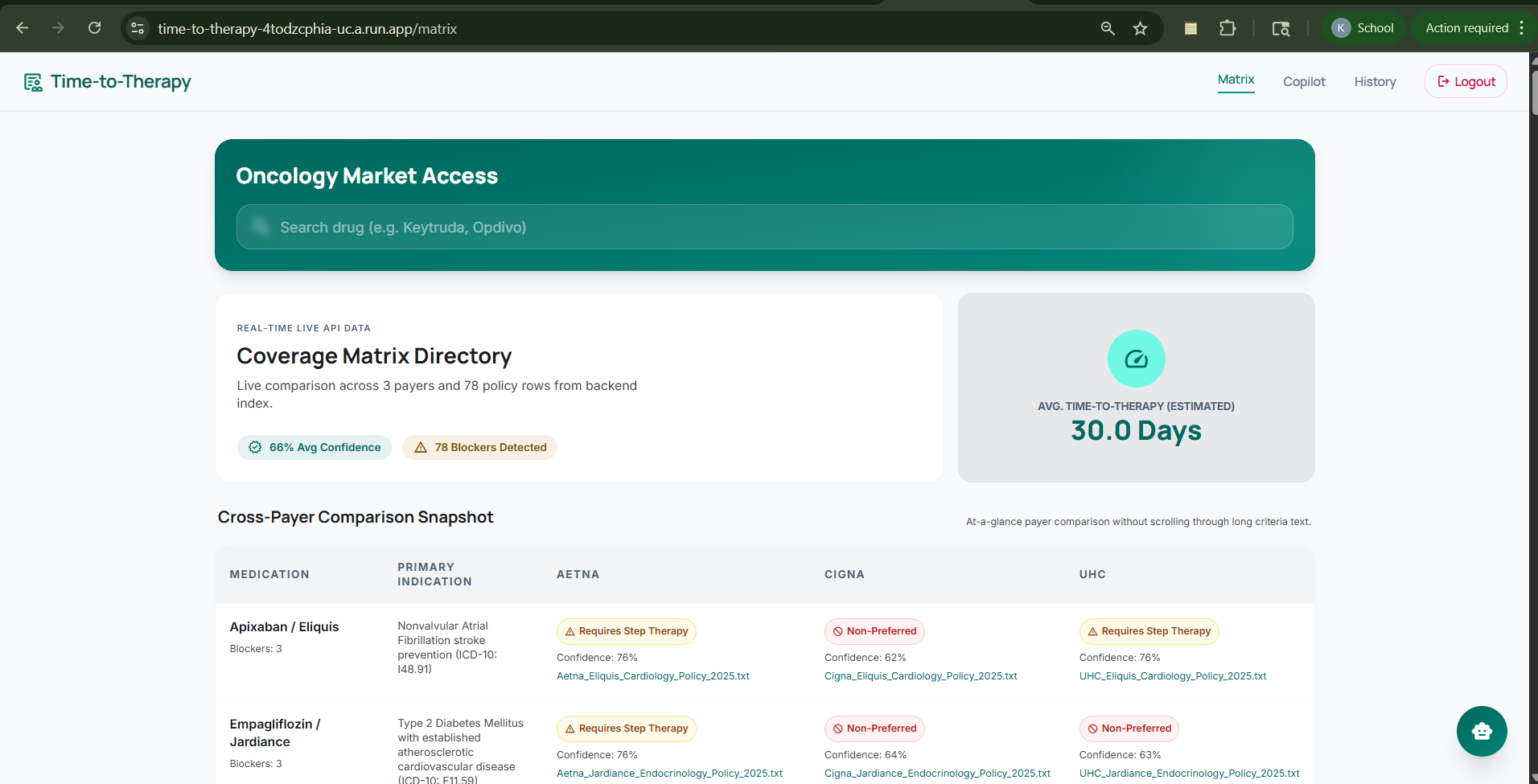
Matrix Dashboard
-
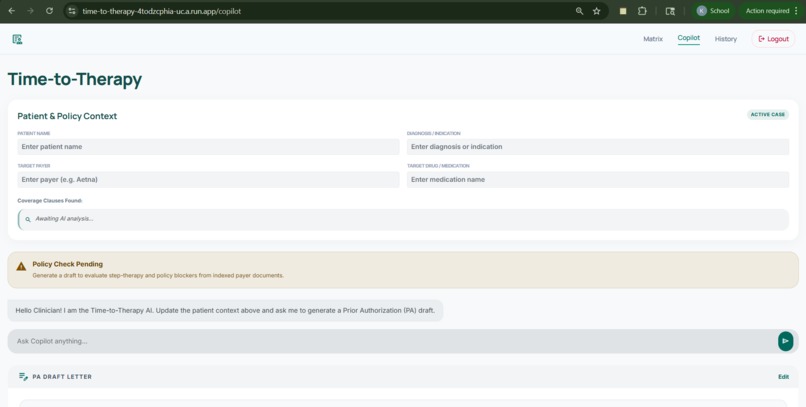
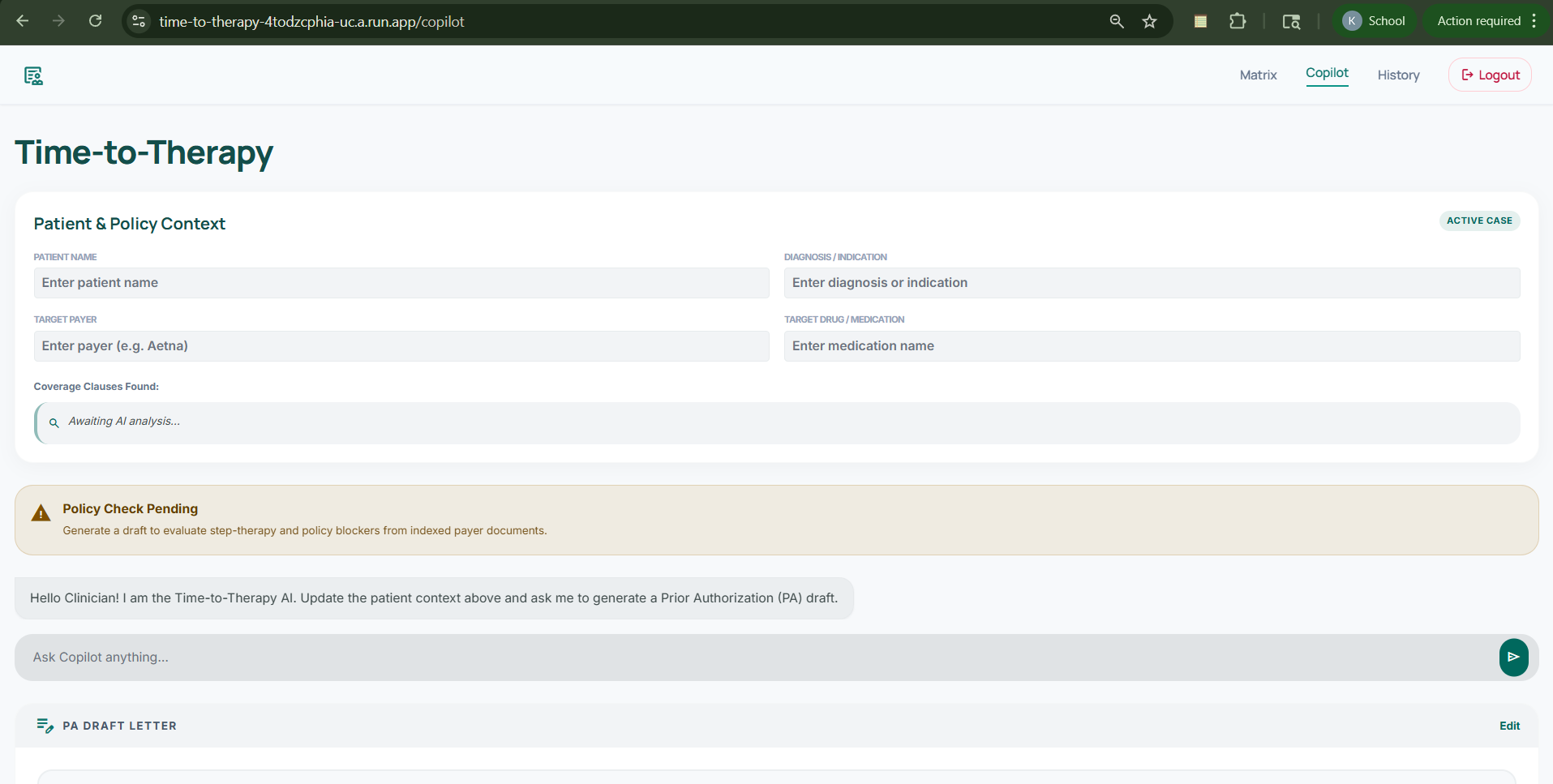
Copilot Page
-
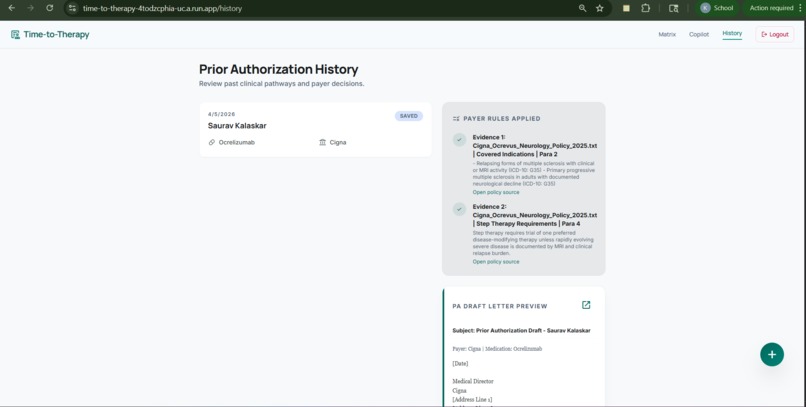
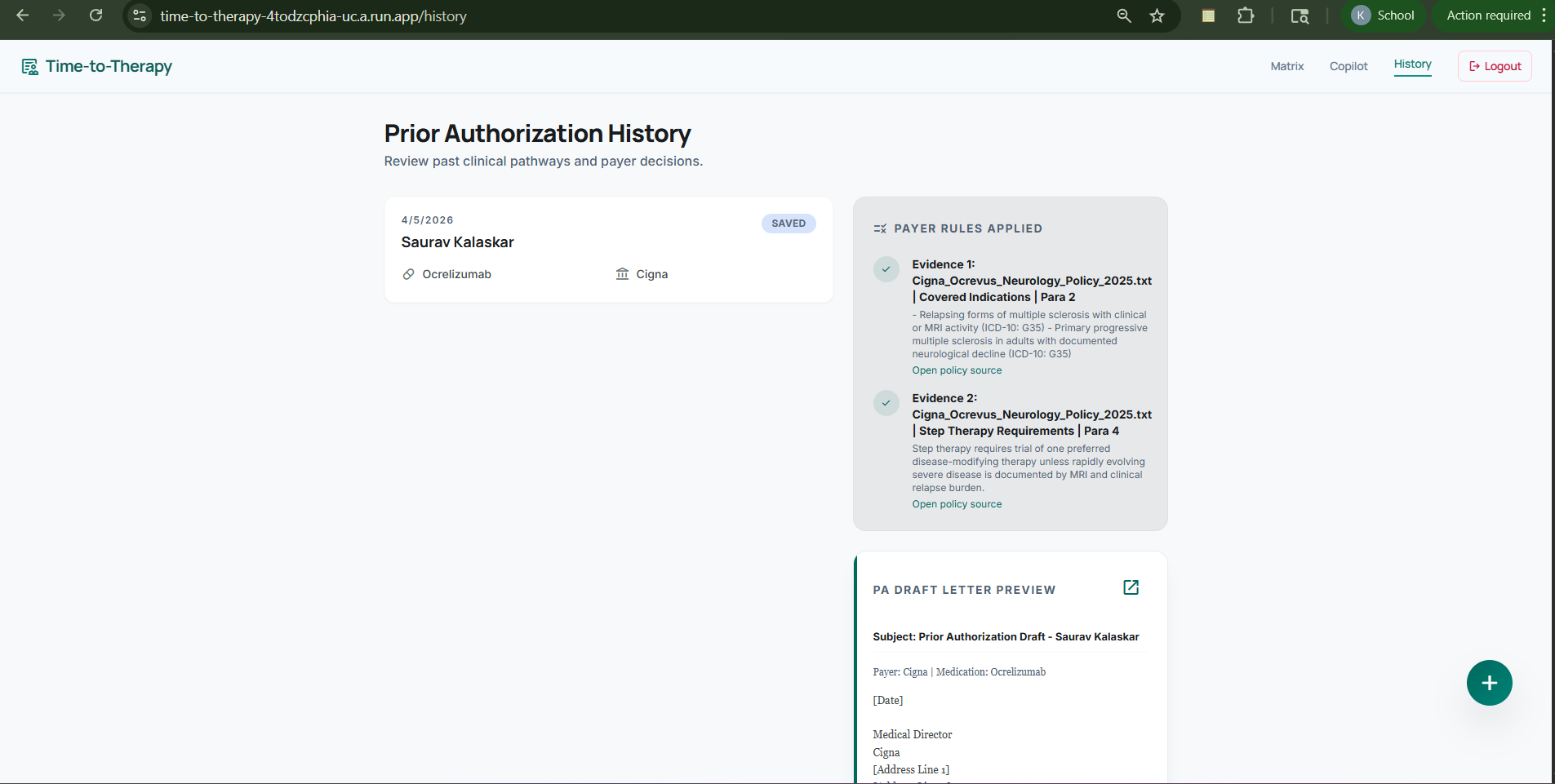
History Page
Inspiration
Prior authorization for specialty medications is still a major source of delay in patient care. We were inspired by how much time care teams lose navigating long payer policy documents, comparing requirements across insurers, and drafting authorization or appeal letters under pressure. That process is repetitive, fragmented, and high stakes, especially when patients are waiting to start therapy.
We wanted to build something practical: a tool that shortens the path from prescription to treatment by helping teams find the right policy information quickly, compare payer criteria side by side, and generate stronger, evidence-grounded prior authorization drafts.
What it does
Time-to-Therapy Prior Authorization Copilot brings three capabilities into one workflow:
- A Coverage Matrix that shows side-by-side payer coverage criteria
- A Copilot Drafting experience that takes patient context, retrieves relevant policy evidence, and generates a prior authorization draft
- A Draft History view that stores previous drafts along with the supporting policy evidence used
The system is designed to be grounded in indexed payer policy content, not generic output. When relevant evidence is missing, it explicitly returns: Policy data not found in current coverage index. That makes the workflow more transparent and trustworthy.
How we built it
We built the backend with FastAPI and the frontend with HTML, Tailwind CSS, and JavaScript. The application is powered by a retrieval-augmented workflow that parses payer policy documents, chunks them, validates them against a schema, embeds them deterministically, and stores them in Qdrant for semantic retrieval.
For generation, we used an OpenAI-compatible NVIDIA NIM Nemotron endpoint to draft prior authorization letters based on retrieved policy clauses. We used SQLite to persist draft history and evidence metadata so users can review previous outputs.
The overall flow is:
- Policy documents are loaded from local payer files
- Relevant policy records are extracted and validated
- Policy chunks are indexed for semantic search
- Users query the matrix or submit patient context for drafting
- The backend retrieves matching evidence and returns structured responses with source metadata
Challenges we ran into
One of the biggest challenges was dealing with the inconsistency of payer policies. Different payers express similar criteria in very different ways, which makes extraction, comparison, and normalization difficult. Building a matrix from indexed policy content rather than hardcoded rows made the solution more useful, but also much more complex.
Another challenge was keeping the drafting experience grounded. It is easy for an LLM to generate plausible text, but much harder to ensure that every recommendation is supported by real retrieved policy language. We had to design for missing-data cases and make sure the system failed clearly instead of inventing evidence.
We also worked within practical constraints: the current vector index is in-memory, the policy corpus comes from local documents, and real-time payer API integrations are outside the scope of this version.
Accomplishments that we're proud of
We are proud that we built an end-to-end workflow rather than a disconnected demo. The project does not just generate text. It compares payer criteria, retrieves supporting policy evidence, produces a grounded draft, and stores the result for later review.
We are also proud of the system's transparency. Instead of hiding the retrieval step, we made evidence and source attribution part of the user experience. The explicit no-data behavior is another accomplishment because it keeps the product honest when the current index does not support an answer.
Finally, we are proud that the project is testable and structured. We included smoke tests for routes, matrix filtering, draft behavior, history persistence, and frontend-backend wiring, which makes the prototype more reliable and extensible.
What we learned
We learned that in healthcare-adjacent workflows, retrieval quality matters just as much as generation quality. A draft is only useful if the evidence behind it is relevant, attributable, and easy to inspect.
We also learned the importance of designing for trust. In this kind of workflow, users need more than a polished answer. They need to understand why that answer was produced and what policy language supports it.
On the engineering side, we learned how to connect document ingestion, schema validation, vector retrieval, LLM drafting, persistence, and frontend workflows into a single product experience. We also came away with a deeper appreciation for just how fragmented payer policy logic is in the real world.
What's next for Time-to-Therapy Prior Authorization Copilot
Our next step is to expand the policy corpus and improve policy normalization across more payers and drug categories. We also want to move from an in-memory index to a more production-ready retrieval layer that supports larger datasets and more durable indexing.
Beyond that, we would like to add stronger citation UX, better appeal-letter support, and deeper workflow customization based on payer and therapy type. Longer term, we see opportunities for integration with operational healthcare systems so this can fit more naturally into real prior authorization workflows.
The long-term vision is simple: reduce administrative burden, improve transparency, and help patients get to therapy faster.

Log in or sign up for Devpost to join the conversation.