Inspiration
Last month a grandmother got a call in her grandson's voice, crying that he'd been in an accident and needed bail money. She wired it. It was never her grandson; three seconds of audio from a video he'd posted was enough to clone him. This is now one of the fastest-growing categories of fraud, and video deepfakes are catching up to voice.
What hit us was that the defenses on offer don't work for the person being targeted. Spam filters check who is calling, the number, never whether the voice itself is real. And you cannot ask a frightened person to detect a deepfake in real time, under fear and urgency. Worse, even a perfect detector loses eventually: cloning improves every month, so pure detection is an arms race the defender is structurally one step behind on.
That reframed the problem for us. The goal isn't a better detector. It's a defense that doesn't degrade as the fakes get better. That's the idea Timbre is built around: you cannot out-clone a question.
What it does
Timbre screens both phone calls and video calls for AI impersonation, and offers a way to protect your own voice. Three pillars:
1. Screen (live phone calls, the headline). A real Twilio call is screened in real time, two layers at once:
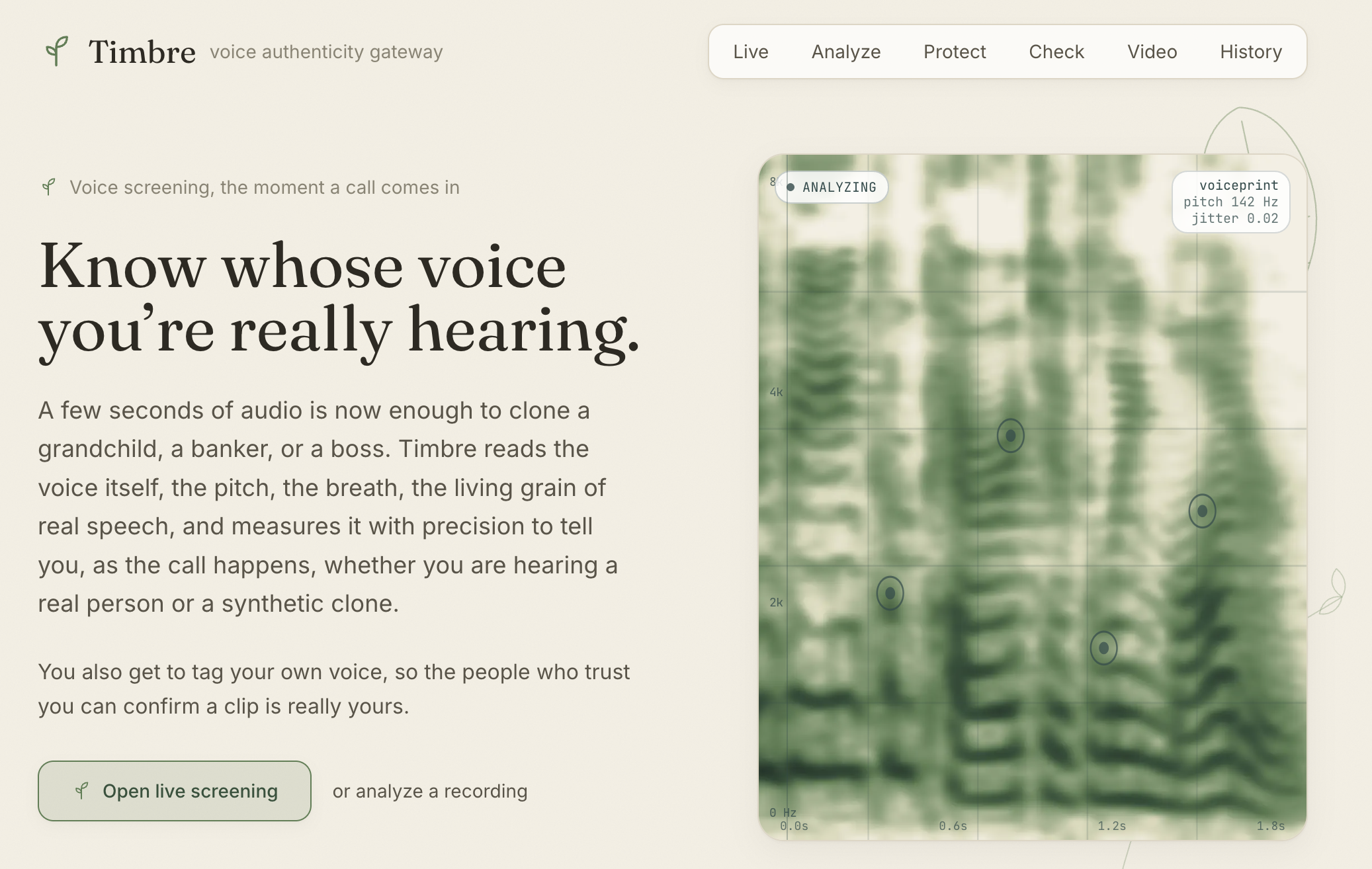
- A deepfake voice detector scores the voice for clone artifacts as the call happens (a phone-tuned DSP model on the live 8 kHz path; a DSP + wav2vec2 SSL ensemble on uploads).
- An interactive voice challenge-response: the call prompts the caller to state their name, repeat a random phrase, and answer a simple question, verified live via Twilio speech transcription. A pre-recorded or one-way clone can sound perfect and still fail this, because it can't repeat a phrase it never heard or answer a question on the spot. This is generator-agnostic: it does not degrade as deepfakes improve.
Verdicts are calm and three-way: CONNECT · CHALLENGE · BLOCK.
2. Video (live video-call liveness). An in-browser webcam check using MediaPipe face-landmark tracking, with the same challenge-response idea (blink twice, turn your head, lean in) plus blink rate, head micro-motion, and an rPPG heart-rate estimate. A photo or pre-rendered deepfake held to the camera can't follow a random on-command prompt, so it flags. Same principle as the audio side.
3. Tag (protect your own voice, the bonus). Our own spread-spectrum audio watermark embeds an inaudible, recoverable mark into a voice clip so it can be proven yours later. A public Check verifies whether a clip carries a Timbre tag and who registered it.
Plus a persisted call History (so it feels like a real service) and a parchment / botanical UI built around a real voiceprint spectrogram.
How we built it
- Telephony / Screen: Twilio Voice + Media Streams.
/voicereturns TwiML that runs an interactive challenge flow (prompts + Twilio speech transcription to verify answers) and starts a<Start><Stream>to a FastAPI WebSocket, which decodes the 8 kHz μ-law frames and scores a rolling window. Verdicts push to the dashboard over SSE. - Detector: librosa-based DSP feature extraction (pitch, jitter, shimmer, formants, breath/energy, MFCC + Δ + ΔΔ) for the live phone path; on uploads, an ensemble of that DSP model with a wav2vec2 SSL model we trained on real-world deepfakes (In-the-Wild) and modern vocoders (WaveFake).
- Video: in-browser MediaPipe face landmarks, blink-rate and head micro-motion from the landmark stream, and an rPPG heart-rate estimate from facial skin-tone variation, all driving the same challenge prompts.
- Tag: our own spread-spectrum watermark in the STFT magnitude domain, with a
/tagembed and a/checkcorrelate-and-decode. - Backend: Python 3.11, FastAPI (HTTP + WebSocket), numpy/scipy.
- Storage: local SQLite (
backend/timbre.db) for both call history and the tag registry. Zero external setup. - Frontend: Next.js + Tailwind in a warm parchment / botanical design, with a hero built around a real voiceprint spectrogram.
Challenges we ran into
- The model arms race was real and humbling. We evaluated several popular pretrained deepfake detectors and found most of them broken in practice on real-world audio. We trained our own ensemble and it competes with modern neural TTS, but we confirmed honestly that a top-tier commercial clone can still slip past pure detection. Rather than hide that, we built the product around it: the limitation is exactly why we added the challenge-response backstop.
- Why we added challenge-response. Once we accepted that no detector wins the arms race forever, the design followed: pair detection with something generator-agnostic. A live, unpredictable question is something no recording can answer, on voice or on video.
- Hardware limits on training. We didn't have the compute or time to train a large model on a huge corpus, so we focused our training on real-world deepfake data (In-the-Wild) and modern vocoders (WaveFake), and leaned on the ensemble and the challenge-response rather than chasing a single giant model.
- Phone audio is hostile. Twilio delivers 8 kHz μ-law, lossy and narrowband. A detector trained on clean studio audio falls apart on it, so we kept a phone-tuned DSP model on the live path and trained/evaluated with phone-realistic conditions in mind.
- Live transcription and rPPG are noisy. Verifying challenge answers via speech transcription and estimating heart rate from a webcam are both imperfect, so we treated them as evidence with confidence, not absolutes, and made the challenge logic tolerant of transcription slop while still catching a recording that can't respond at all.
Accomplishments that we're proud of
- A genuinely live, end-to-end Screen: a real phone call gets a real-time verdict combining a detector and an interactive challenge.
- The challenge-response insight, working on both audio and video, that gives Timbre a defense that doesn't degrade as deepfakes improve.
- An honest, trained detector ensemble (DSP + wav2vec2 on In-the-Wild / WaveFake) instead of a fake or an LLM guess.
- Our own spread-spectrum watermark that survives ordinary re-encoding.
- A product that feels real: persisted call history, a public tag check, and a warm, accessible UI a grandparent could use.
What we learned
- The instinct to "just build a better detector" is a trap for this problem. The detector is necessary but never sufficient, because the attacker controls the generator and it only gets better.
- The strongest defenses are the ones that don't depend on the quality of the fake. A live, unpredictable challenge is one of them.
- Honesty is an asset here, not a liability. Naming the detector's ceiling out loud is what makes the architecture credible.
- Phone and webcam are messy real-world signals; designing for that from the start beats porting a clean-data model later.
What's next
- A richer, harder-to-game library of voice and video challenges.
- Continuous training on fresh real-world threat data; the dataset is part of the moat.
- Tighter joint audio-plus-video verification for video calls.
- Caregiver alerts on BLOCK for elderly relatives.
- A telecom / carrier partnership to put Screen in front of the call at the network edge, and a metered API for the Video liveness and Tag checks.
Built With
- fastapi
- librosa
- mediapipe
- next.js
- numpy
- python
- react
- scikit-learn
- scipy
- tailwind-css
- twilio
- typescript
- uvicorn
- wav2vec2
- websockets

Log in or sign up for Devpost to join the conversation.