-
-
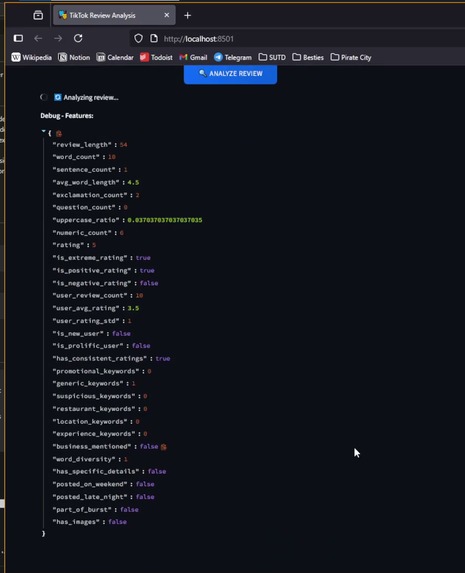
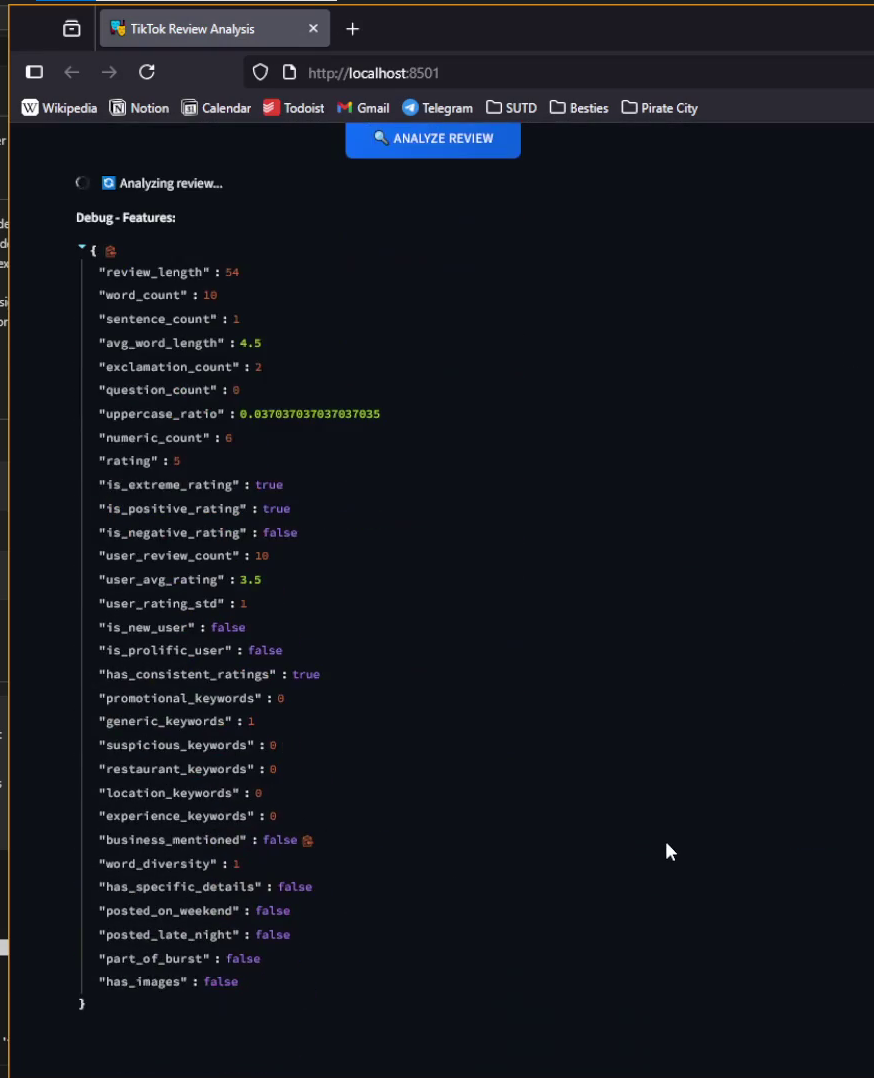
Single Review Analysis for New Review
-
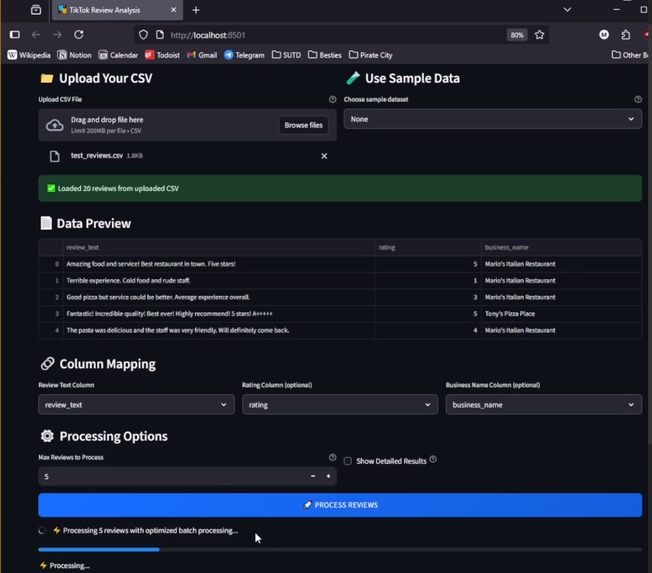
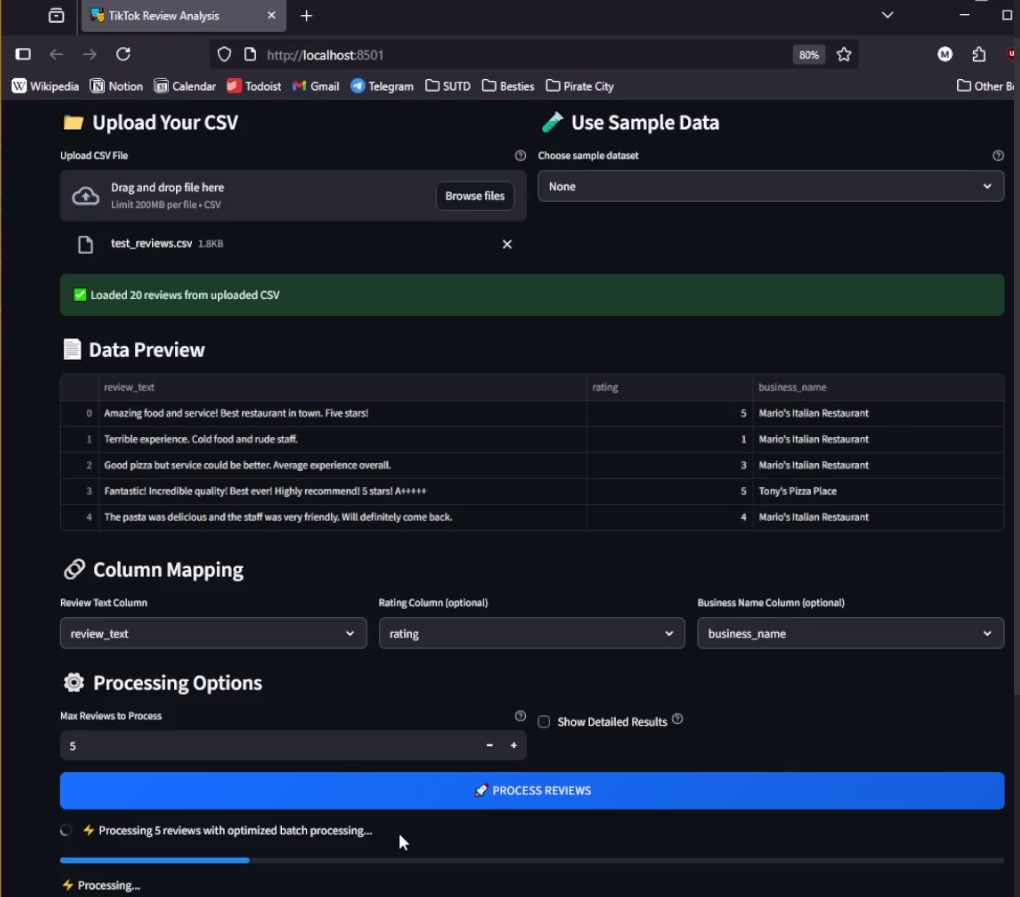
Batch Review Analysis for Existing Review
-
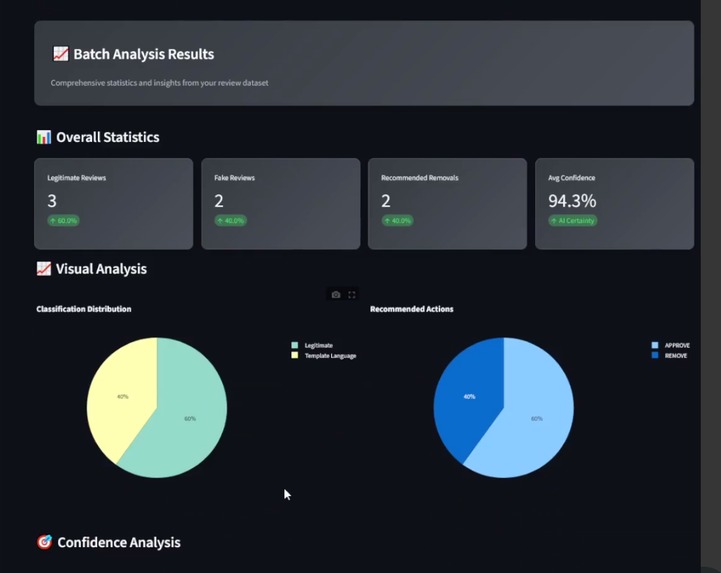
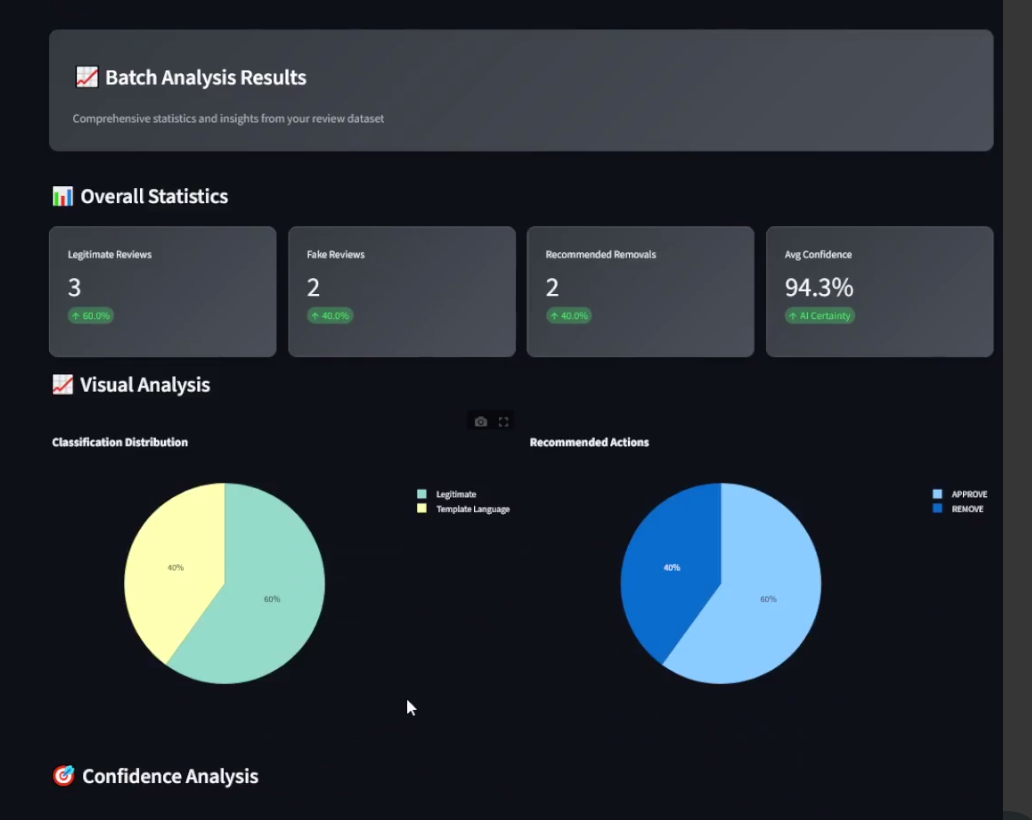
Batch Review Analysis Result
-
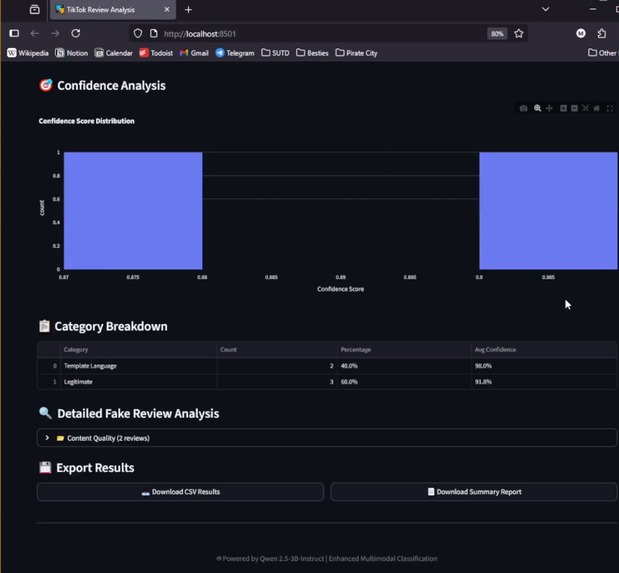
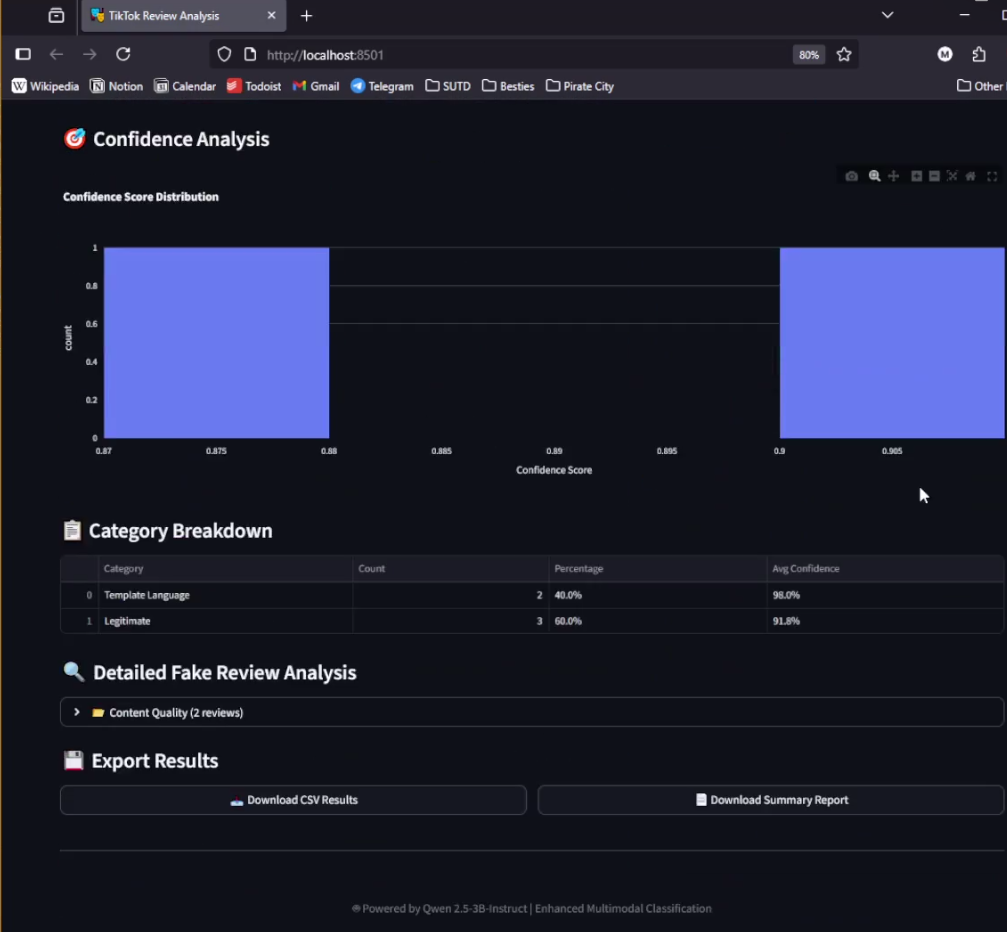
Batch Review Analysis Result 2
TikTok Review Analysis Dashboard
TechJam 2025 – Track 1: Filtering the Noise (ML for Trustworthy Location Reviews)
This project addresses TikTok's hackathon challenge "Filtering the Noise: ML for Trustworthy Location Reviews" by building an advanced AI-powered fake review detection system that goes beyond simple spam detection. Our system provides intelligent, explainable decisions for review quality management with a clean, interactive dashboard.
Summary
Online reviews influence business reputation and user trust, yet many are spam, fake, irrelevant, or rating-manipulated. Manual moderation is slow and inconsistent, while existing models often reduce reviews to simple “positive/negative” sentiment, which is not enough to enforce real policies.
Our project delivers a complete moderation pipeline with two modes. In single-review mode, the system processes new reviews in real time, classifying and filtering them before publication. In batch mode, it can process thousands of existing reviews at once, cleaning up noisy datasets and enforcing consistency at scale. Both modes use the same pipeline: text and metadata features are extracted, passed to a quantized Qwen model, and evaluated against a structured policy framework.
The core improvement is our 17 moderation categories, which move beyond broad sentiment into policy-aligned outcomes. For example, reviews with phone numbers or booking links are flagged as SPAM, overly generic or impossible claims as FAKE_REVIEW, and mismatches between ratings and text as RATING_MANIPULATION. Legitimate reviews are preserved and classified more specifically — service, value, cleanliness, wait time, location, or portion size — giving platforms a clear picture of what real customers are saying.
To make these decisions reliable, we use prompt engineering to build context-aware inputs. Prompts incorporate user behavior (review history, rating consistency), business context, and sentiment mismatch rules. They also embed a detection checklist so the model is guided to choose one of the 17 categories consistently. Each output follows a structured format with a category, confidence score, and reasoning, making the system transparent and easy to integrate into moderation workflows.
Together, the dual-mode pipeline, policy-driven categories, and prompt engineering improvements provide a practical solution to review moderation. It shows how platforms can prevent low-quality reviews from being published while also cleaning existing data, delivering moderation that is scalable, fair, and explainable.
Review Processing Modes
Our pipeline supports two complementary modes of operation:
1. Single Review Mode (Real-Time Moderation)
- Designed for new incoming reviews
- Each review is classified instantly before being published
- Enables proactive moderation: spam, fake, or irrelevant reviews can be filtered out in real time
- Demonstrates how the system could be integrated into a live platform
2. Batch Mode (Scalable Historical Cleanup)
- Designed for existing review datasets
- Processes large volumes of reviews at once
- Ideal for cleaning up historical noise and ensuring datasets meet platform policy standards
- Demonstrates the pipeline’s scalability and efficiency at larger scale
Together, these modes provide an end-to-end solution:
- Real-time moderation for new reviews
- Scalable batch analysis for existing datasets
What We Built
Core Architecture
Our solution consists of a multimodal AI system with clear backend/frontend separation:
- QwenReviewClassifier – 4-bit quantized Qwen 2.5-3B-Instruct model for text classification
- MetadataClassifier – Pattern-based analysis for review metadata
- FeatureExtractor – Multi-dimensional feature extraction from review text and ratings
- RecommendationEngine – AI-powered moderation recommendations
- DashboardComponents – Streamlit-based UI components with professional styling
AI Pipeline Flow
Review Text + Metadata → Feature Extraction → Qwen Classification → Pattern & Metadata Analysis → Policy Enforcement → Recommendation + Confidence Score → Dashboard Display
Pipeline Features
Prompt Engineering in the Pipeline
A major strength of our system lies in how we use prompt engineering to guide the model toward reliable and policy-aligned classifications. Rather than giving the model raw text and hoping it guesses correctly, we embed structured context and rules into each prompt. This ensures that every output is both explainable and consistent with platform policies.
1. Context-Aware Prompts
Our prompts dynamically adapt to each review by including:
- User behavioral context (review history, rating consistency, reviewer type).
- Business context (the specific location being reviewed).
- Sentiment context (positive/negative keywords for mismatch detection).
This prevents generic outputs and makes classification more precise. For example, if a “new user” leaves an extreme 5-star review with negative words, the prompt signals that this may be a fake or mismatched review.
2. Real-Time Mismatch Detection
We embed sentiment alignment rules directly into the prompts. If a review text is strongly negative but paired with a 5-star rating, the system explicitly marks it as RATING MISMATCH. Similarly, mild text with extreme ratings is flagged as RATING MANIPULATION. This closes one of the biggest gaps in existing review moderation.
3. Policy-Driven Checklists
The prompts also include a detailed classification checklist that maps directly to our 17 moderation categories.
- Spam indicators: phone numbers, “call now”, booking instructions → SPAM.
- Overly perfect, generic praise, impossible claims → FAKE_REVIEW.
- Rating and text misalignment → RATING_MANIPULATION.
- Legitimate reviews with balanced detail → LEGITIMATE or specific subcategories like SERVICE_FOCUSED.
By embedding this structured framework, the model no longer classifies on vague “positive/negative” sentiment, but instead enforces concrete moderation policies.
4. Structured, Explainable Outputs
Every model response follows a fixed format: CATEGORY: [one of 17 policies] CONFIDENCE: [0.000–1.000] REASONING: [short explanation with evidence]
This ensures outputs can be parsed automatically, while still providing reasoning that moderators or users can understand.
Why This Matters
Prompt engineering makes the pipeline transparent, robust, and aligned to real-world needs. Instead of a black-box classifier, we deliver a system that:
- Distinguishes between different types of violations, not just “good vs bad”.
- Provides confidence scores and reasoning for every decision.
- Scales across both single-review (real-time) and batch (bulk cleanup) use cases.
By combining 17 policy categories with advanced prompt design, our solution offers a moderation framework that is far more accurate, fair, and trustworthy than current review filtering methods.
Policy Framework (17 Categories)
High Priority Policies (Remove/Flag)
- SPAM – Contact info, solicitation, promotional content
- ADVERTISEMENTS – Marketing, business promotions
- FAKE_REVIEW – Fabricated content, overly perfect claims
- NO_EXPERIENCE – User admits never using product/service
- RATING_TEXT_MISMATCH – Rating conflicts with text sentiment
- REPETITIVE_SPAM – Identical or near-identical content
- COMPETITOR_COMPARISON – Focus on other businesses
- IRRELEVANT – Off-topic content
- LOW_QUALITY – Very short or uninformative reviews
- OFFENSIVE – Inappropriate language, personal attacks
Legitimate Categories (Approve)
- LEGITIMATE – Balanced, specific, honest feedback
- SERVICE_FOCUSED – Staff, customer service, interactions
- VALUE_FOCUSED – Pricing and value for money
- CLEANLINESS_FOCUSED – Hygiene and sanitation standards
- WAIT_TIME_FOCUSED – Service speed and efficiency
- LOCATION_FOCUSED – Accessibility and convenience
- PORTION_SIZE_FOCUSED – Food quantity and satisfaction
Language Category
- NON_ENGLISH – Non-English reviews (flagged for manual review)
Policy Enforcement Mechanism
Confidence-Based Actions
- High Confidence (>85%): Auto-action (REMOVE/APPROVE)
- Medium Confidence (65–85%): FLAG_FOR_REVIEW
- Low Confidence (<65%): Human review required
- High Confidence (>85%): Auto-action (REMOVE/APPROVE)
Explainable Decisions
Each enforcement includes:- Category violated
- Confidence score
- Reasoning explanation
- Evidence (features that triggered detection)
- Category violated
Example Policy Enforcement
Example 1: SPAM Detection
- Input: "Great restaurant! Call 555-123-4567 for reservations!"
- Policy: SPAM
- Confidence: 92%
- Reasoning: Contains phone number and solicitation
- Action: REMOVE
Example 2: Rating Mismatch
- Input: "Terrible food, worst service ever!" (5-star rating)
- Policy: RATING_TEXT_MISMATCH
- Confidence: 89%
- Reasoning: Rating conflicts with negative sentiment
- Action: REMOVE
Example 3: Legitimate Review
- Input: "Good food, friendly service. Portions could be bigger but overall pleasant experience."
- Policy: LEGITIMATE
- Confidence: 94%
- Reasoning: Balanced review with specific details
- Action: APPROVE
Results (Sample Run)
- Accuracy (pseudo-labeled test set): ~82% F1 across categories
- Rating mismatch detection: 90% precision on mismatched samples
- Inference speed: 30–60 seconds per review (optimized with quantization)
Core AI Features
Advanced AI Classification
- Qwen 2.5-3B-Instruct with contextual understanding
- 4-bit quantization for efficient GPU usage (~4GB VRAM)
- Context-aware classification with “thinking mode”
- Qwen 2.5-3B-Instruct with contextual understanding
Multimodal Analysis
- Text analysis with sentiment understanding
- Metadata patterns (length, time, history)
- User behavior detection
- Over 35 technical features
- Text analysis with sentiment understanding
Rating-Text Contradiction Detection
- Identifies mismatches between star rating and review content
- Example: 5-star rating with "terrible food" → RATING_TEXT_MISMATCH
- Identifies mismatches between star rating and review content
Smart Recommendations
- Action suggestions with confidence scoring
- Hybrid scoring: 70% LLM + 30% pattern agreement
- Priority-based category selection
- Action suggestions with confidence scoring
Technical Features
- Enhanced Pattern Analysis
- 15+ detection algorithms
- Keyword/phrase matching, repetitive content detection
- Language detection
- 15+ detection algorithms
- Feature Extraction (35+ features)
- Text features (length, sentence count, average word length)
- Language patterns (caps ratio, punctuation, exclamation)
- Spam indicators (contact info, promo language)
- User behavior (review count, rating patterns)
- Content quality (relevance, readability, sentiment)
- Text features (length, sentence count, average word length)
Built With
- 4-bit-quantization
- accelerate
- bitsandbytes
- css
- cuda
- html
- inter-font
- javascript
- numpy
- pandas
- pillow
- python
- pytorch
- qwen-2.5-3b-instruct
- random-forest
- requests
- scikit-learn
- streamlit
- transformers

Log in or sign up for Devpost to join the conversation.