-
-

youtube thumbnail
-
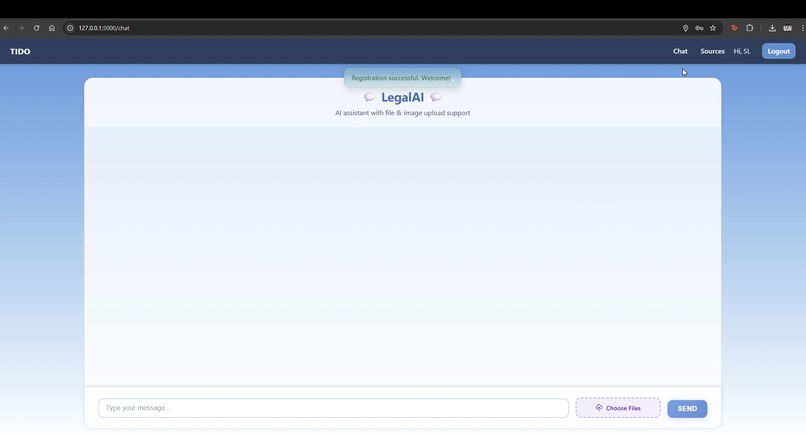
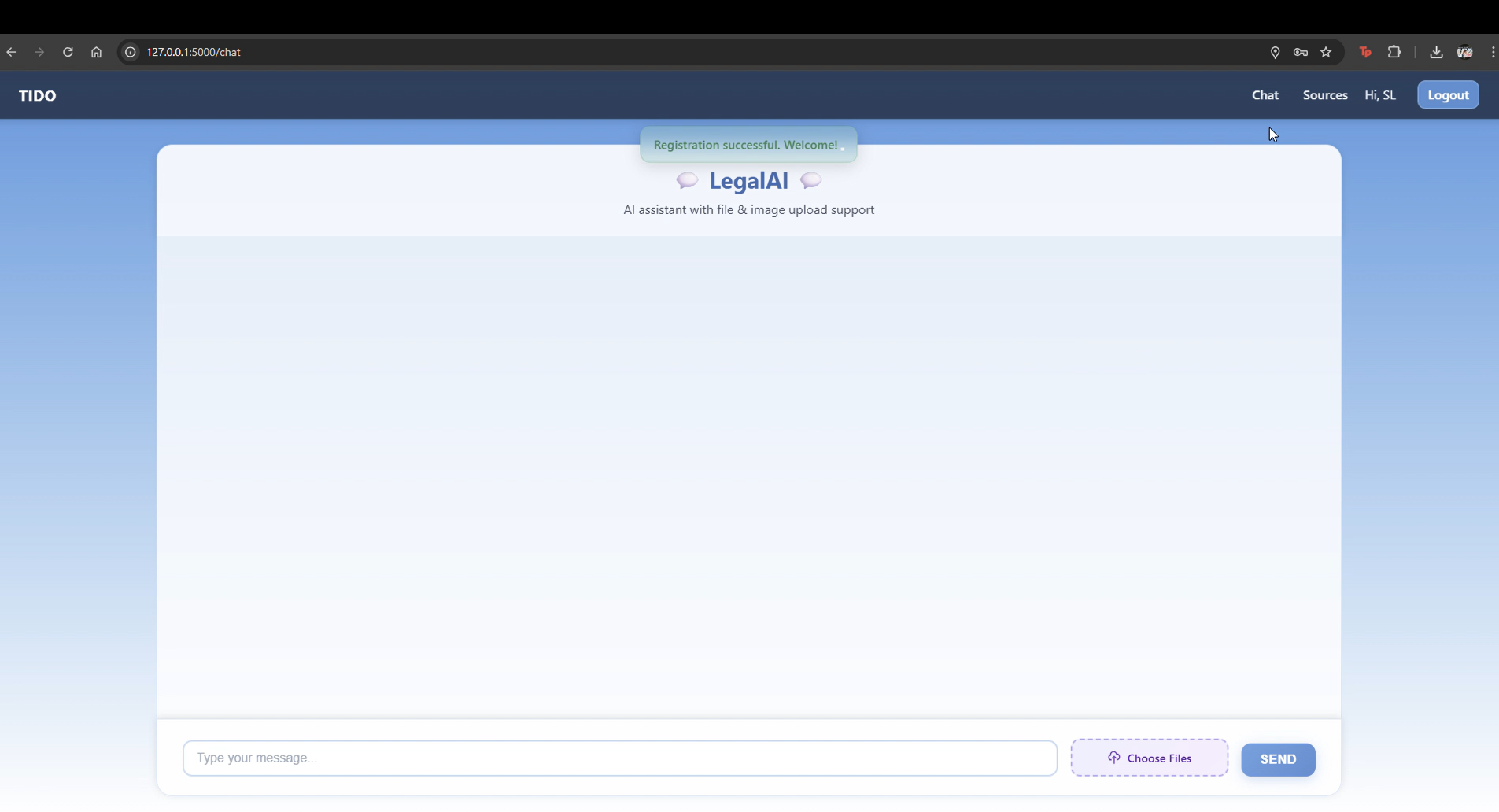
chat interface
-
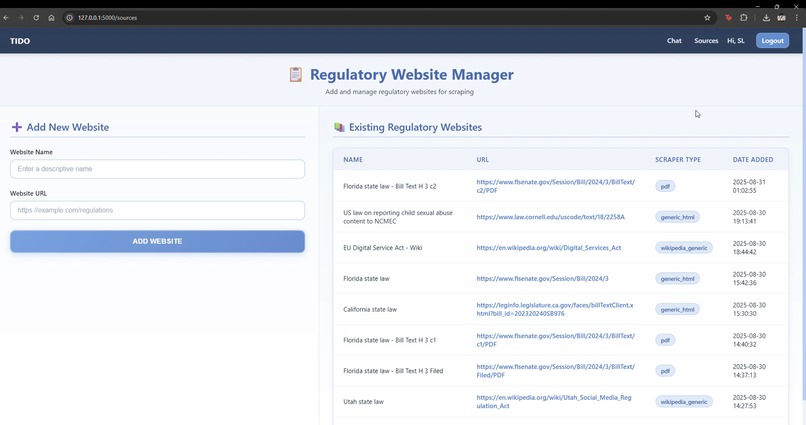
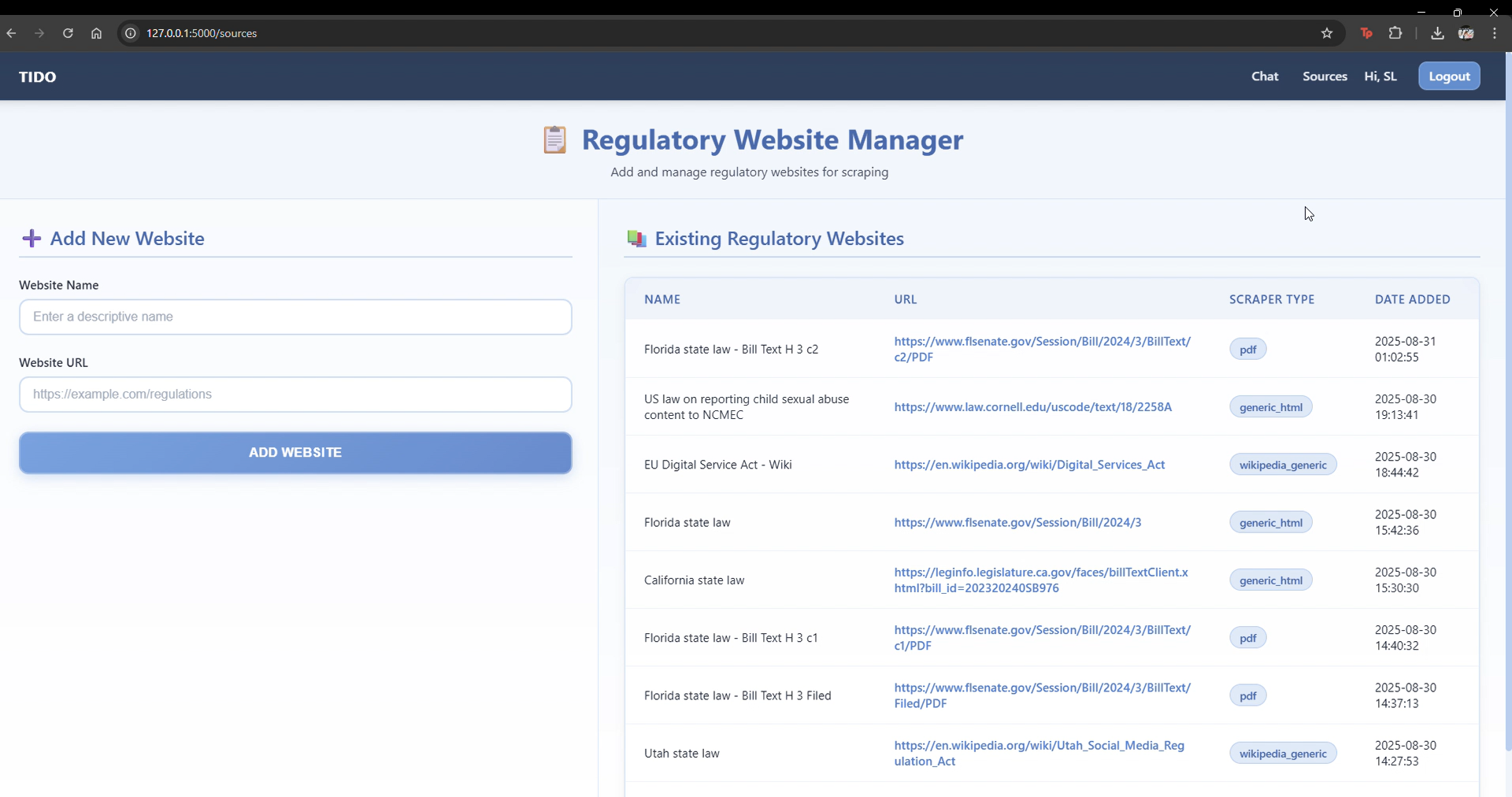
source page

From Guesswork to Governance: Automating Geo-Regulation with LLM
💡 Inspiration
Our project was inspired by a critical and often overlooked challenge for global companies: navigating the complex web of regional regulations for every new product feature. At TikTok, where feature rollouts are rapid and global, ensuring geo-specific compliance is a manual, reactive, and high-risk process. We saw a clear opportunity to transform this from a blind spot into a traceable, auditable, and proactive function. The core idea was to build an intelligent system that could not only identify compliance risks but also automatically update its knowledge, creating a scalable, automated legal guardian for product development.
🤖 What It Does
"From Guesswork to Governance" is an AI-powered prototype that automates geo-compliance checks for new product features. It provides an internal, secure chat interface where product teams can query a feature's compliance requirements. The system's core function is to analyze the query against a dynamically populated database of legal documents, providing an instant compliance flag, a clear rationale, and links to the relevant regulations. This transforms a manual, high-risk process into a proactive, transparent, and auditable one.
🛠️ How We Built It
Our solution is a full-stack web application built on a robust Python and JavaScript foundation. The backend, powered by Flask, serves as the central hub connecting our frontend, AI models, and database. Here's a quick look at the Flask app setup:
from flask import Flask
app = Flask(__name__)
The user interface, created with HTML, CSS, and JavaScript, offers a simple and secure experience. Upon logging in, a user can access two key functionalities:
AI Chat Interface: For querying compliance requirements for a new feature.
Source Management Page: To upload new legal documents.
The heart of our system lies in the AI-driven data pipeline. When a new legal URL is provided, our solution performs several steps:
Web Scraping: We used BeautifulSoup4 for HTML parsing and a dual-method approach for PDFs. First, we attempt a fast text extraction using Pdfplumber. If this fails, we fall back to converting the PDF into high-resolution images with PyMuPDF, then performing Optical Character Recognition (OCR) with Tesseract and PIL to extract the text.
Data Processing: The extracted raw text undergoes a thorough cleaning process to remove duplicates and normalize the data.
Vectorization & Storage: We use Ollama to classify the cleaned legal texts into relevant sections before storing them in our MongoDB database.
For the user query function, we built a Retrieval-Augmented Generation (RAG) model. This model uses KNN (k-nearest neighbors) to find the most relevant legal information from the database, which is then fed into a LLaMA 3.2 model to generate a precise and well-reasoned response.
🚧 Challenges We Ran Into
We encountered several challenges throughout the development process:
PDF Parsing: Extracting text from PDFs proved to be a major hurdle. Some documents were image-based, necessitating the OCR fallback method. This required careful implementation of the
PyMuPDFandTesseractpipeline to ensure accurate text recognition.Ollama Integration: Integrating the Ollama model for text classification posed challenges, particularly in defining the correct input and output schemas to ensure accurate and consistent classification of legal jargon.
Security: Building a secure application for internal use required us to be meticulous with security protocols. We had to implement and configure several libraries such as Flask-Login, Werkzeug, and Flask-Talisman to protect against common web vulnerabilities.
Handling Ambiguity: The legal language itself presented a challenge. Concepts like
Age-sensitive logic (ASL)orGeofencesare often not explicitly defined in regulations. Our RAG model and theLLaMA 3.2model had to be carefully prompted and fine-tuned to handle this kind of ambiguous terminology and provide accurate, contextual responses. The optional fields from the sample dataset likerelated regulationsorreasoningwere a great help here.
🎉 Accomplishments That We're Proud Of
We are most proud of successfully building a complete, end-to-end prototype that turns a complex, manual process into an automated, scalable solution. We built a robust data pipeline that intelligently handles unstructured data from the web, including image-based PDFs, ensuring our system's knowledge is always up-to-date. Most importantly, we've created a system that provides not just an answer, but a traceable, auditable output with clear reasoning and regulatory references, which is crucial for mitigating risk in a real-world corporate environment.
🧠 What We Learned
This project was a deep dive into the practical application of AI and web development for a real-world business problem. We learned the importance of building a resilient data pipeline, especially for handling unstructured data like PDFs. The fallback OCR method was a crucial lesson in building a robust system that can handle different data formats effectively. We also gained valuable experience integrating multiple disparate technologies—from web frameworks like Flask and security libraries like CSRFProtect to AI models and databases—into a single, cohesive solution. The most significant learning was how to design an AI system that not only generates answers but also proves its reasoning with auditable sources.
🚀 What's Next for TIDO
Looking ahead, we aim to expand the capabilities of our system. This includes:
Expanding Data Sources: Integrating with official government API feeds and subscription-based legal databases to enrich our knowledge base.
Multi-LLM Integration: Adding support for different LLMs to allow for performance comparisons and to handle a wider variety of query types.
Advanced UI & Analytics: Developing a more comprehensive dashboard for compliance managers to view trends, track compliance flags, and manage regulations at a higher level.
Proactive Monitoring: Implementing a system to proactively monitor regulatory changes and automatically alert relevant teams.



Log in or sign up for Devpost to join the conversation.