-
-

Predictive Glucose Leve Spikes using Ridge Regression (ML)
-

App Notification for Predicted Glucose Spike/Risk
-
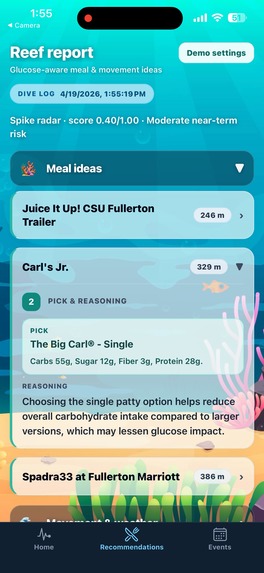
Locations from Google Maps API -> Nutrition info by Human Delta -> Suggestions by Gemini
-
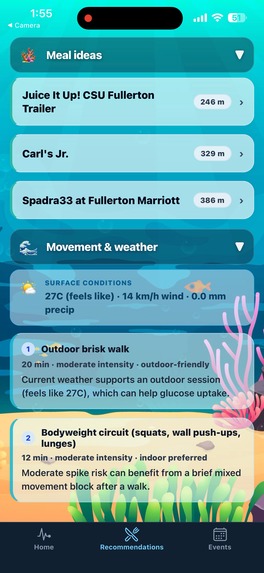
Exercises based on current weather
-

Automatically Logged Events
-

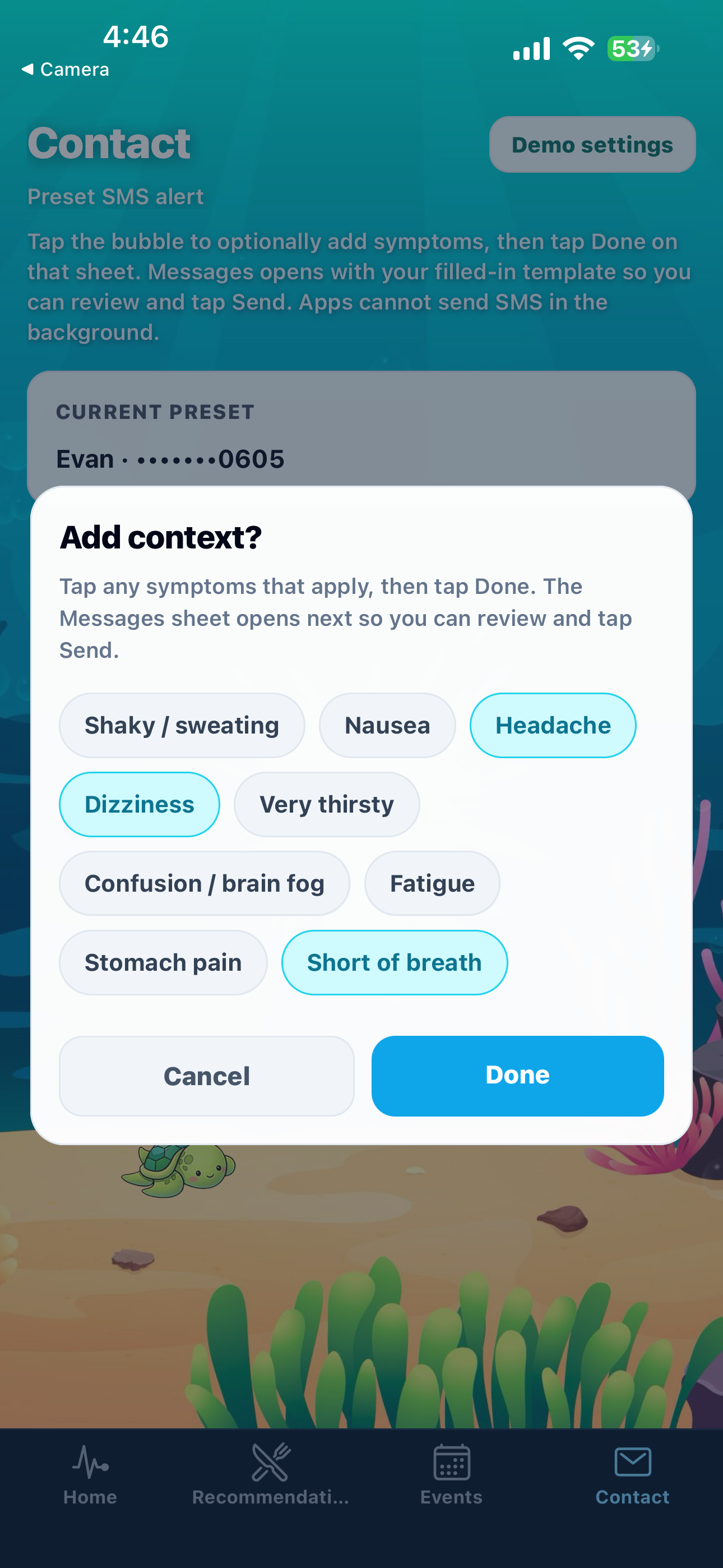
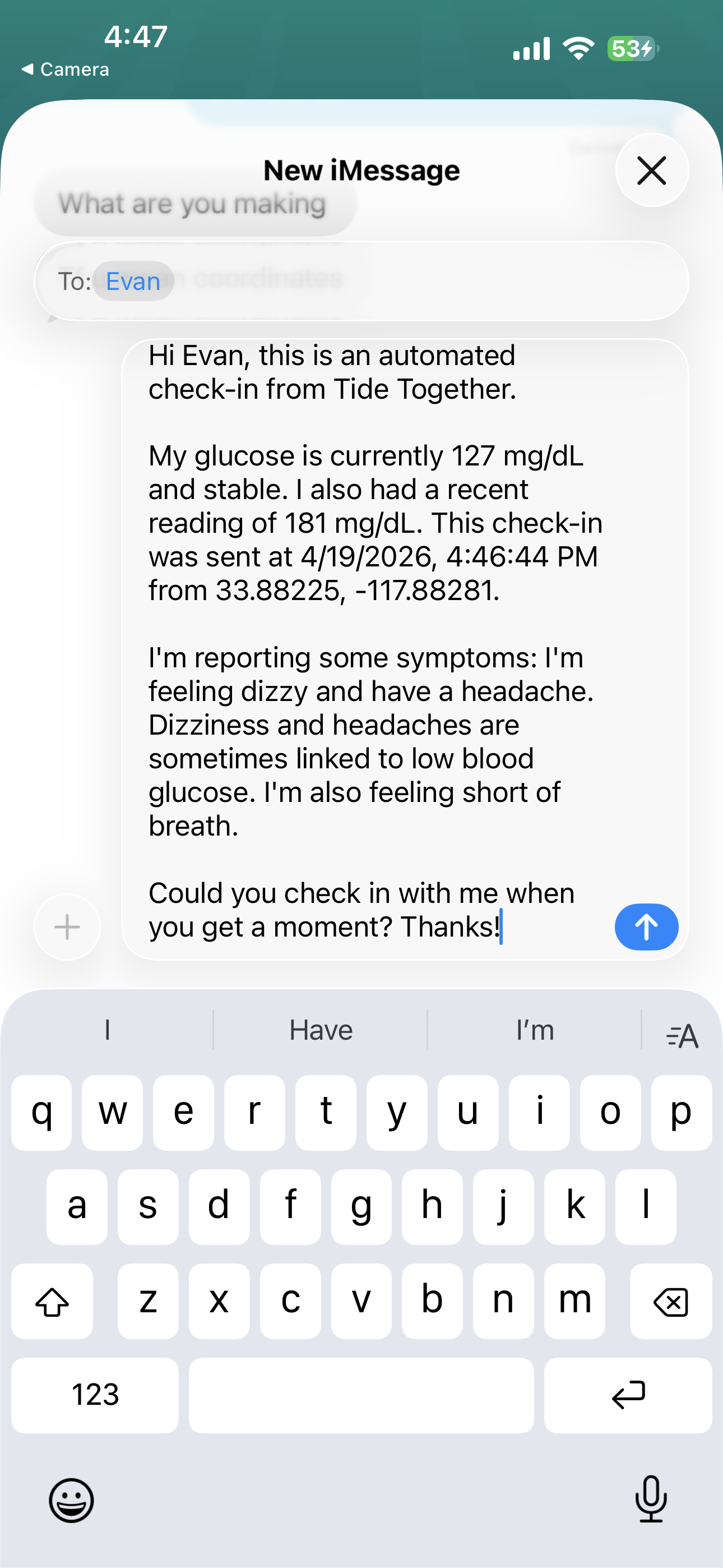
Automated SMS for accountability & possible emergencies
-
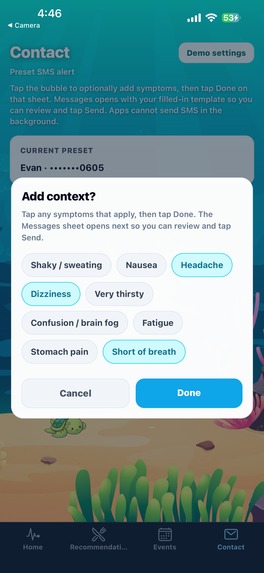
T2D Symptoms
-
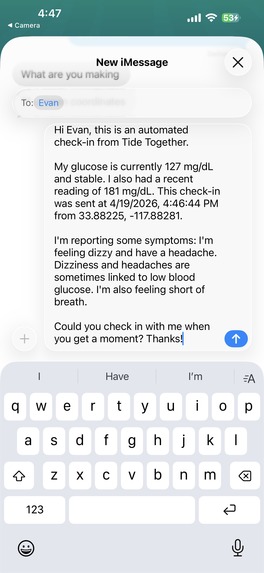
LLM Refined text refined with web-indexed ADA
-
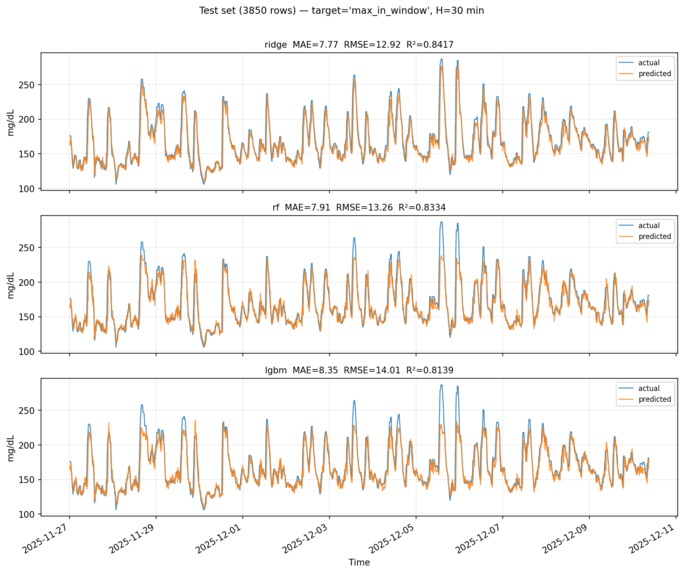
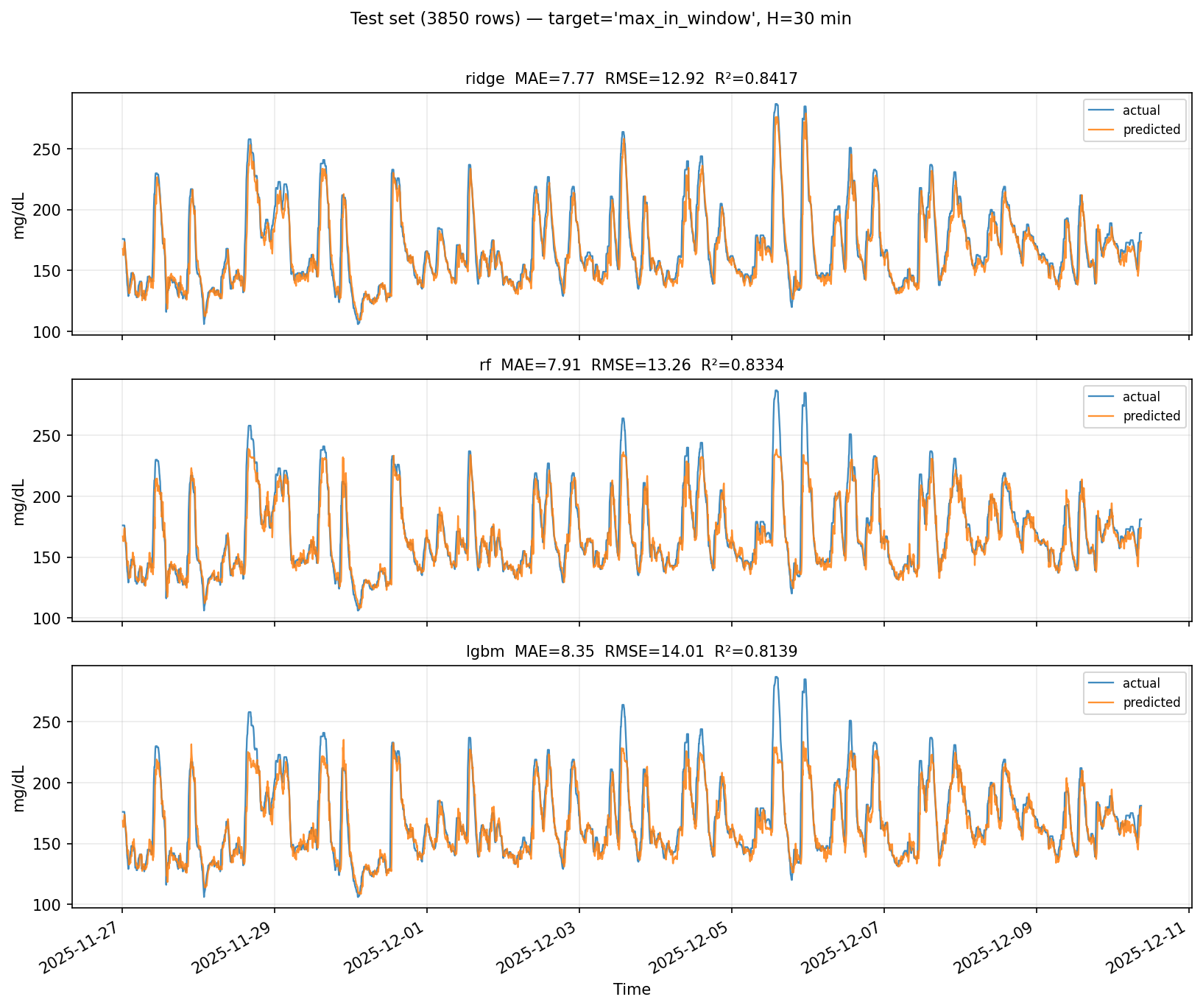
Ridge, Random Forest, and LightGBM; True vs Predicted
-
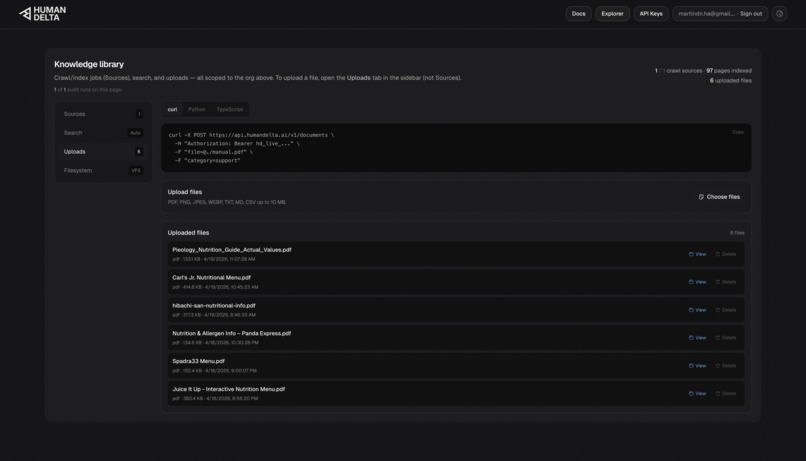
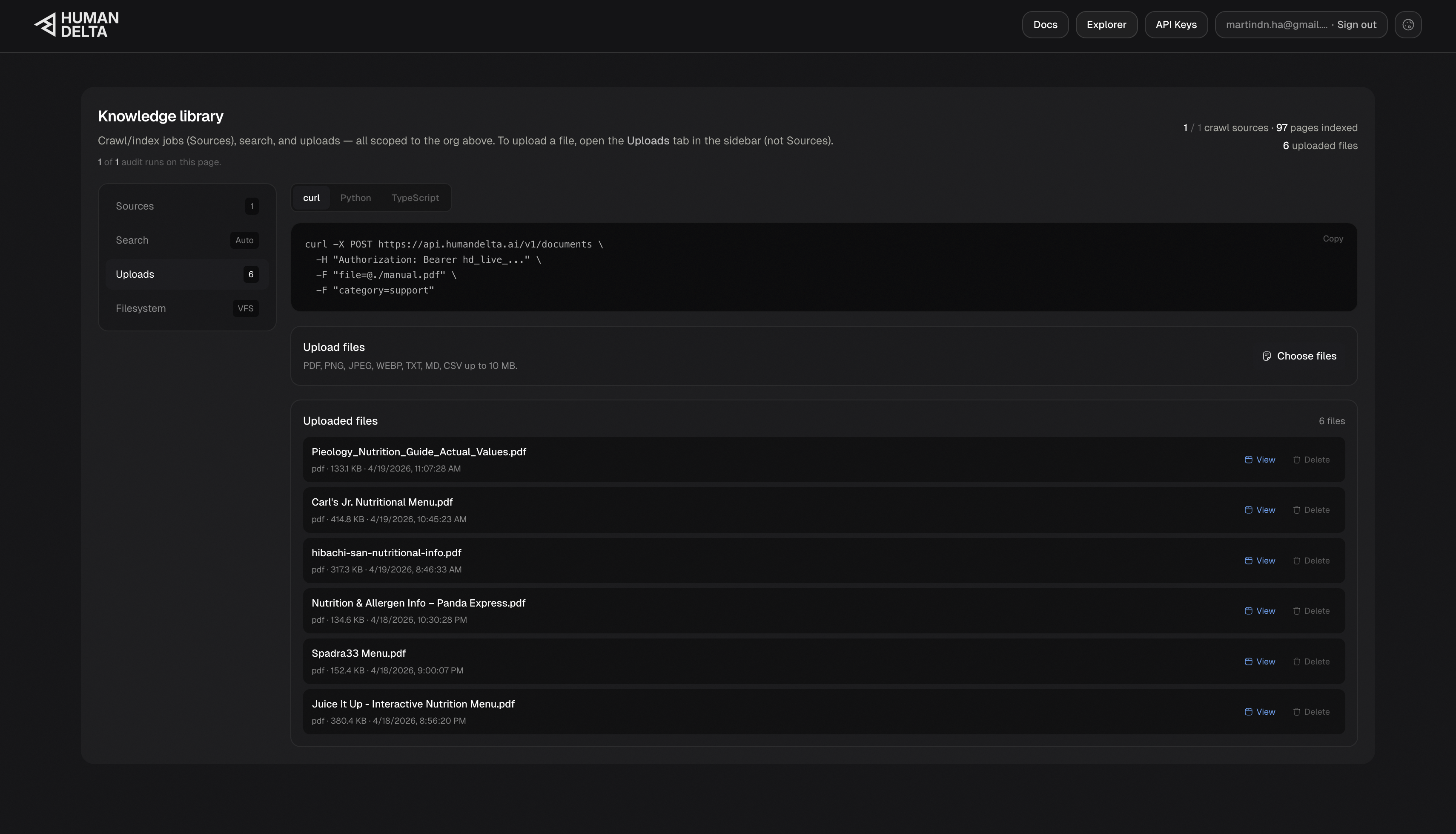
Human Delta; Relevant documents & Web Indexed American Diabetes Association (ADA)


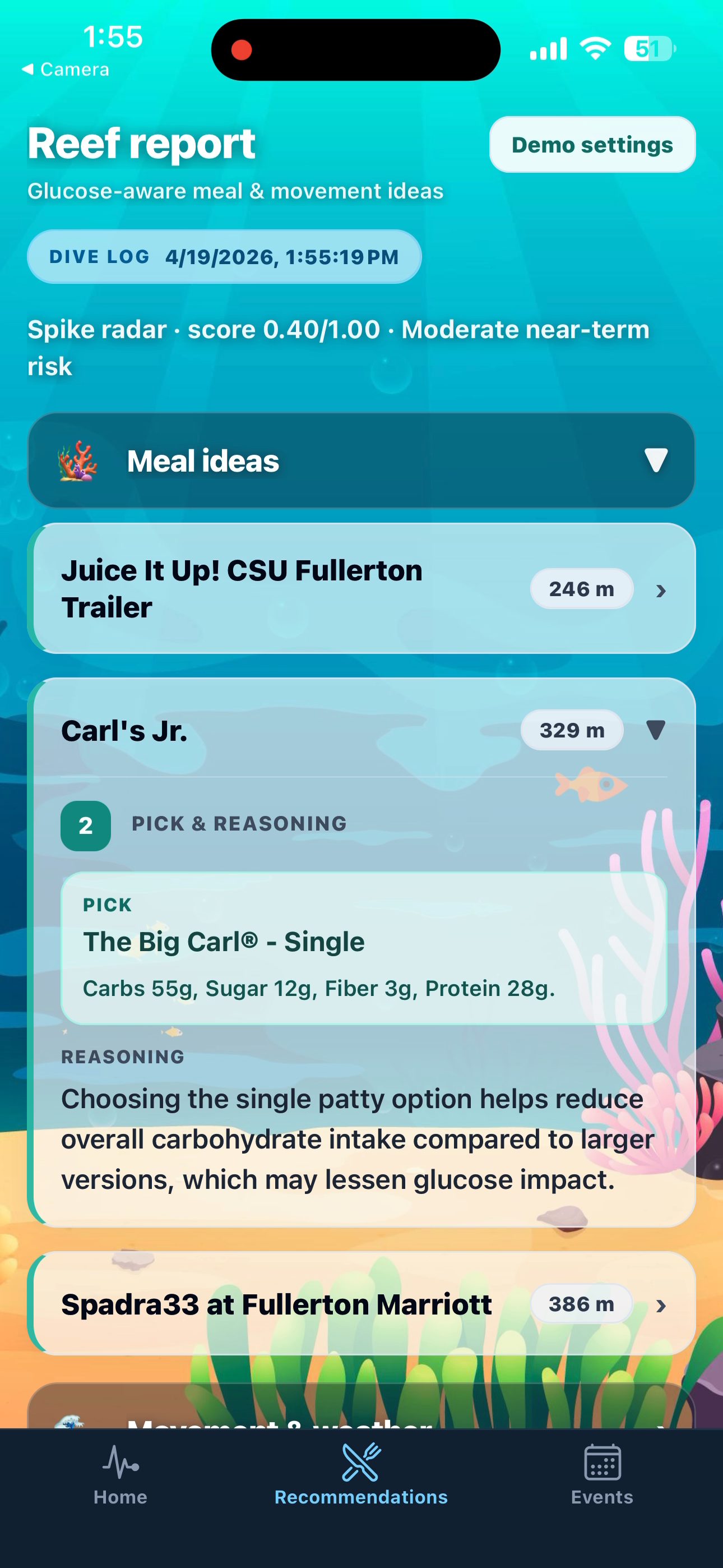
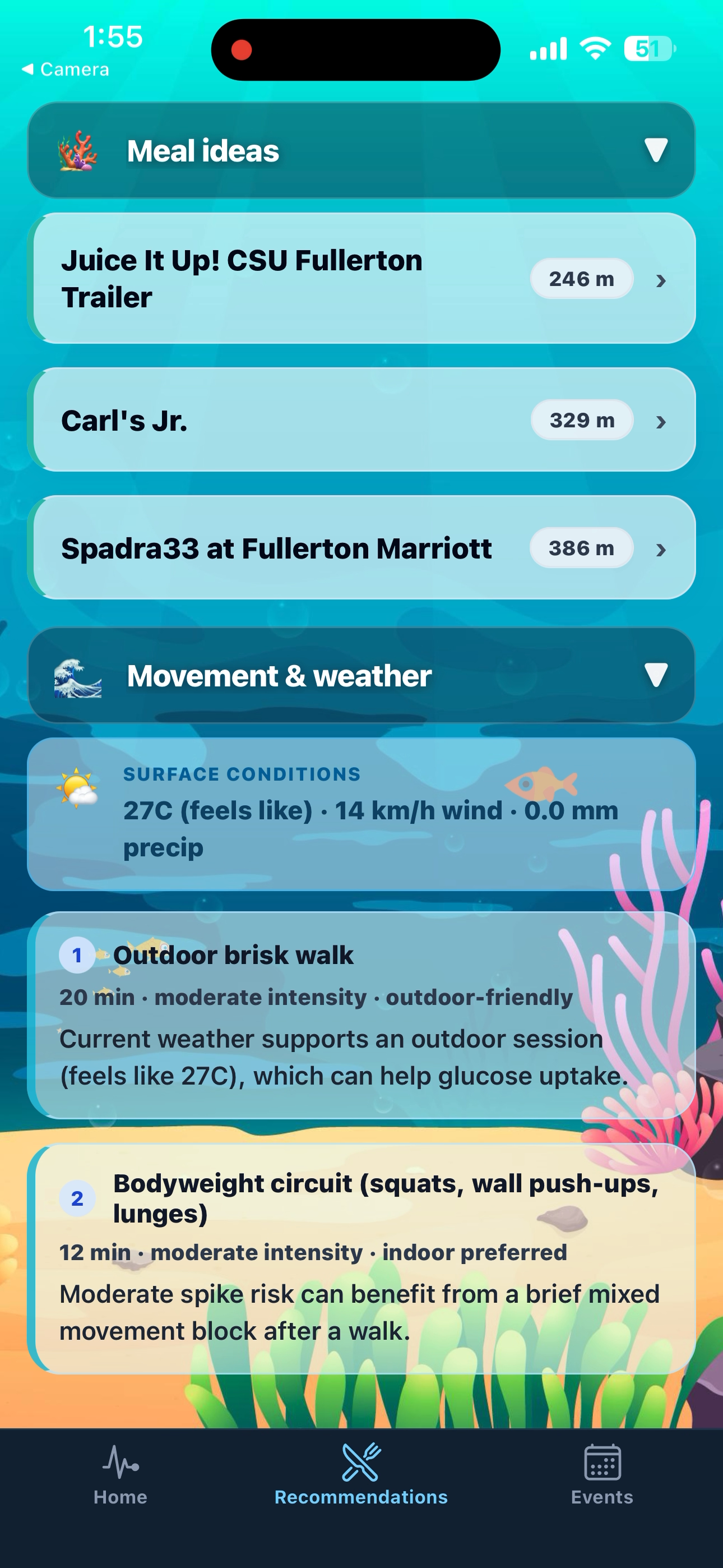


Inspiration
Many diabetes and CGM companion apps are built around logging, thresholds, and hindsight. They are excellent at showing what already happened, but they rarely surface credible near-term risk in a way that leaves room for predictive intervention—a timely nudge before a post-meal spike or a regrettable food choice fully materializes. They are also often not context-aware in the moment: symptoms, mood, activity, and location rarely feed one combined decision.
Tide Together started as a small experiment in providing risk-predictive, context-rich support: helping someone who may be heading toward a spike make a better nearby food choice with clear, grounded explanations—and optionally loop in a trusted contact via SMS when they want to share how they are doing (including symptoms), enabling accountability and camaraderie. We wanted a hackathon-friendly slice of that vision: practical, demo-able.
What it does
Risk and spike signals: The backend applies rules-based risk assessment and calls a Python spike regression path when configured, so the experience can blend interpretable rules with learned patterns.
Place-aware meal help: Uses Google Places API (New) to find nearby restaurants from the user’s location. App asks for permission and only queries only when asked, or when risk is predicted, in order to mitigate invasion of privacy.
Retrieval-backed guidance: Human Delta (
POST /v1/search) retrieves indexed menus, nutrition snippets, and education pages so meal suggestions reference healthier food options from real content instead of generic guesses.Symptom-aware check-ins (grounded, not guessed): For SMS check-ins, we query Human Delta using the user’s selected symptoms plus trusted-index terms (for example, hypoglycemia / hyperglycemia / when to seek help). Gemini only drafts the message after those passages are retrieved, so the model is steered by indexed education and reference material—reducing “confident nonsense” about what a symptom might mean.
Readable explanations: Google Gemini (Vertex AI or AI Studio) turns that retrieved material into meal guidance and SMS check-in copy the user can send to a contact, with presets in the Expo app.
Clear boundaries: Prediction, safety rules, ranking, and escalation stay on our server; the mobile app is the interface for location, SMS presets, and calling the API. The project is explicitly a prototype—not a replacement for a care team.
How we built it
Data: Real glucose level collected from myself and willing victims (my friends), all of which range from normal -> pre-diabetes -> T2D (type 2 diabetes) over the course of 2 weeks using Dexcom G7 CGM.
| Layer | Stack |
|---|---|
| Mobile | Expo (React Native), TypeScript, React Navigation, AsyncStorage; Expo Location, SMS, Notifications |
| Backend | Node.js, Express.js, TypeScript (tsx in dev) |
| Maps | Google Places API (New) — nearby search from the server |
| Retrieval | Human Delta — optional indexed search for menus / web / docs; same retrieval path supports symptom-grounded SMS check-in queries |
| LLM | Gemini — meal synthesis and SMS narrative generation |
Machine Learning:
Python + ml_model/infer_glucose_regression_json.py — scikit-learn Ridge time-series regression (glucose_regressor.joblib); predicts max glucose in a 30-minute horizon from rolling features; Express spawns the script for /api/spike-risk when configured Spike model training (Ridge bundle). The frozen glucose_regressor.joblib was fit on 5-minute CGM traces (Dexcom Clarity-style pipeline): rolling 60-minute mean / std / min / max, 15-minute lag and slope, and - time-of-day sin/cos features. The regression target is maximum glucose in the next 30 minutes on that grid (timeseries_model_meta.json documents columns and target). Held-out test metrics shipped with the bundle are approximately MAE 7.8 mg/dL, RMSE 12.9 mg/dL, R² 0.84 (see ml_model/timeseries_model_meta.json).
The repo’s spike_model_app/train_clarity_spikes.py shows the same feature recipe for experiments with LightGBM, using a person-level train / validation split (default ~20% of people held out so rows from one export do not leak into both splits)—not full k-fold in that script. For Ridge alpha and stable scores on longitudinal CGM, Group k-fold cross-validation by person_id (or blocked time splits) is the right follow-up so autocorrelated points from the same individual never appear in multiple folds during tuning.
App API
The API exposes endpoints such as /risk-assessment, /spike-risk, /nearby-restaurants, /menu-guidance, /recommendations (full ranked pipeline), and /sms-check-in-message. The Expo app calls {EXPO_PUBLIC_API_BASE_URL}/api/... and can run against LAN, simulator localhost, or Cloudflare quick tunnels when the phone cannot reach the dev machine.
Challenges we ran into
Solo Developer: Friends didn't want to come to hackathon :(
Lack of T2D Data: Initially explored using AI-READI for T2D data to train ml models on, ran out of azure credits and could not download data. Settled for hand-collected data (collected some weeks prior in preparation for the Hackathon).
Campus and guest Wi‑Fi: AP isolation and restrictive networks meant
localhoston the phone was wrong and LAN IPs often failed. We leaned on Cloudflare tunnels for Metro and a separate backend tunnel so physical devices could load the bundle and hit the API reliably.Google Cloud setup: Places API (New), billing, and key restrictions (server-side IP vs client-only keys) caused
PERMISSION_DENIEDuntil keys matched how the backend actually calls Google.Expo tunnel flakiness:
expo start --tunnelwas sometimes unreliable;start:cloudflareplus documented fallbacks reduced demo-day surprises.Fast Refresh through tunnels: Occasional need to reload the dev client after saves when proxying through cloudflare URLs.
Grounding the LLM: Balancing helpful copy with retrieval-backed answers—especially for symptoms, where we did not want the model to invent explanations. Pulling passages first and clear non-medical framing kept the hackathon scope honest.
Accomplishments that we're proud of
An end-to-end pipeline from location → places → retrieval → ranking → Gemini-written guidance and SMS check-in text, wired through a real mobile client.
Human Delta integration so meal ideas cite indexed menus and check-in copy about symptoms is anchored in retrieved education text, not free-associated by the LLM alone.
Operational detail in the repo: env templates, smoke
curlexamples, networking matrix (simulator vs device vs tunnel), and troubleshooting for common hackathon pain points (EADDRINUSE, 403s, timeouts).A product narrative that is ambitious but honest: predictive, context-rich support without claiming to be a regulated medical product.
What we learned
Health UX is a systems problem: Models, maps, retrieval, and policy-style rules have to agree before the user sees a single recommendation.
Demos are infrastructure demos: The hardest part of a phone-first hackathon app is often networking and keys, not the React components.
Retrieval + LLM is a strong combo for explanations when you need both structure (ranking, safety) and natural language (why this option, what to tell a friend)—and for symptoms, retrieval is how you keep the fluent text from outrunning the facts.
Scope control matters: Saying “prototype / not medical advice” early keeps the team focused on trustworthy behavior within a weekend-sized build.
What's next for Tide Together
Better predictive capabilities: richer time-series models (CGM traces, meals, sleep, activity) with calibrated uncertainty and clearer “why we think this” signals—not just a single score, but horizons (next hour vs rest of day) and confidence bands the user can sanity-check.
More biometrics in one picture: bring in resting heart rate, HRV, steps / active minutes, weight or body-composition trends (where the user opts in), and blood pressure when available from cuffs or watches—so risk and guidance reflect the whole day, not glucose alone.
Heart and metabolic health together: diabetes and cardiovascular disease share many pathways (blood pressure, lipids, chronic inflammation, fitness). The next step is to surface that joint risk responsibly: education and retrieval grounded in cardio-metabolic sources, gentle prompts when patterns suggest talking to a clinician, and never diagnosing from a hackathon stack—only structuring context the user and their care team already care about.
FullyHacks 2026 — Tide Together (Expo + Express). See the main README.md for run instructions and API reference.



Log in or sign up for Devpost to join the conversation.