-
-
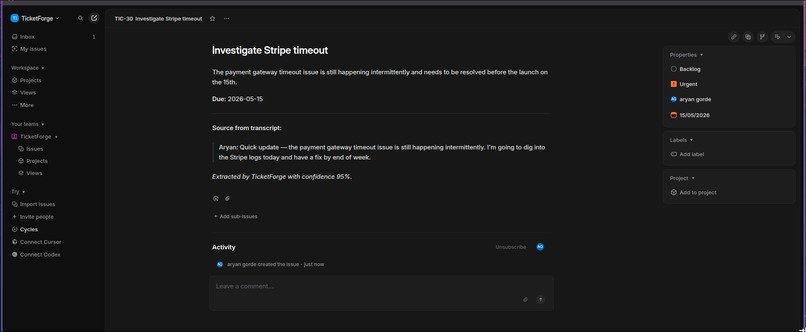
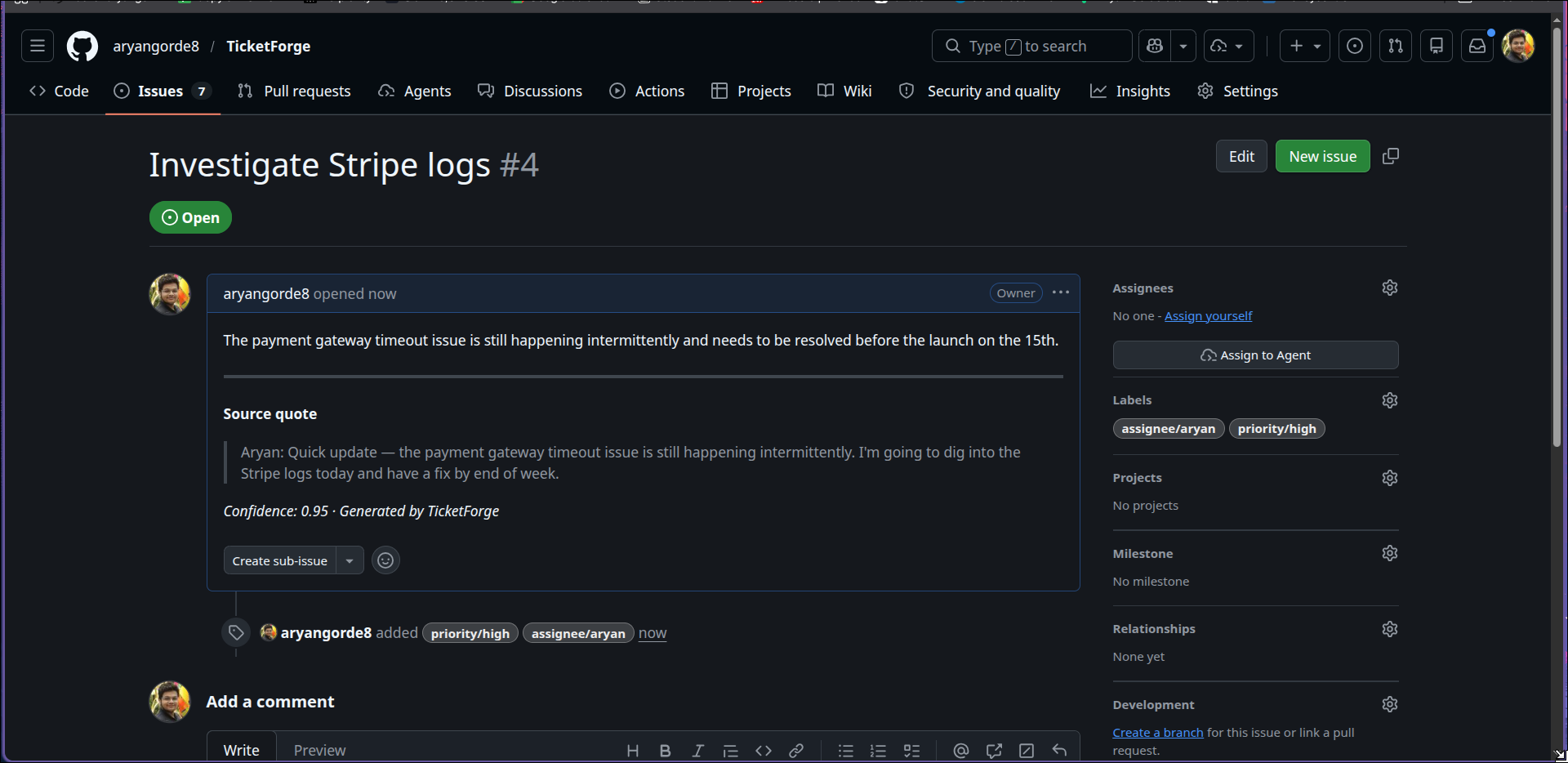
check if it's pushed to linear
-
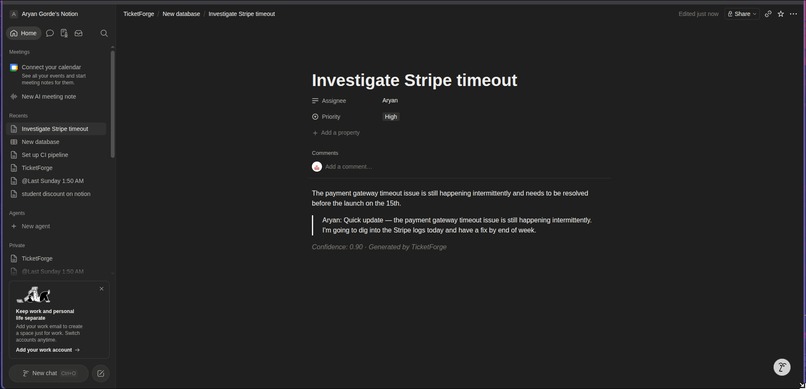
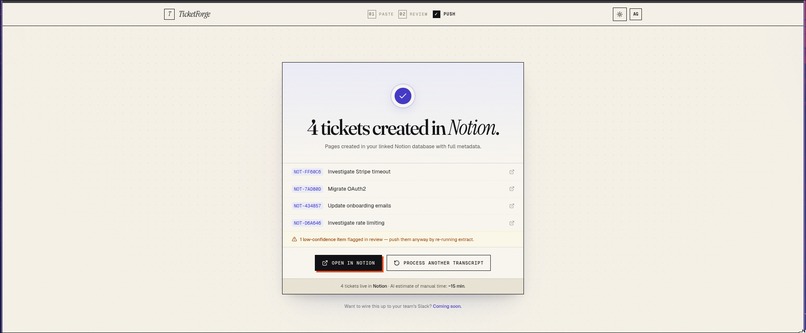
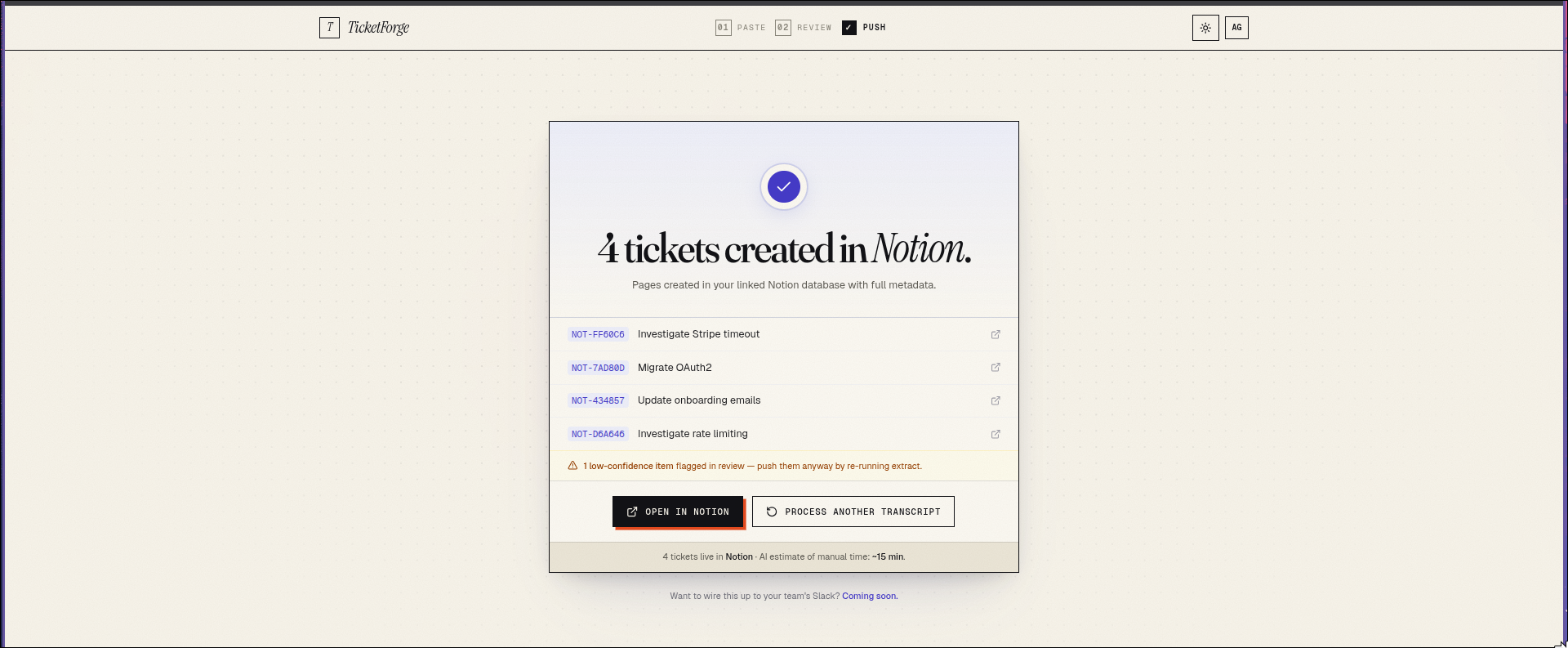
notion page , check if its pushed
-
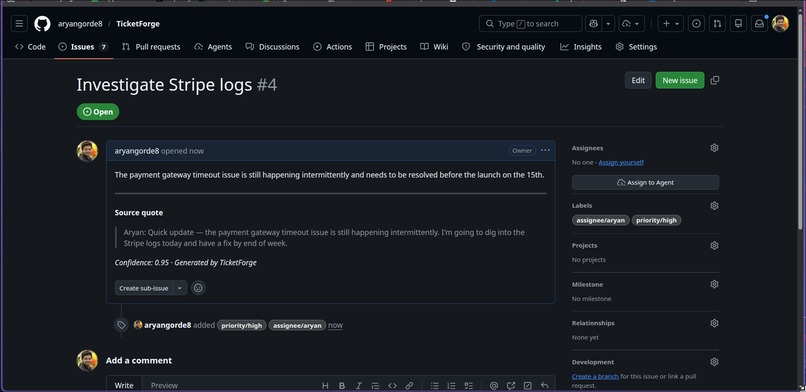
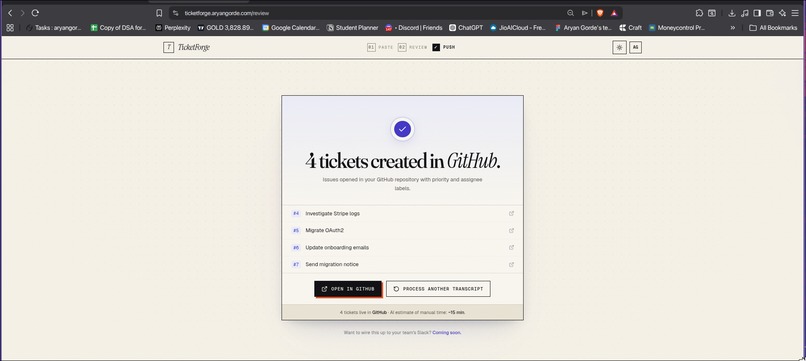
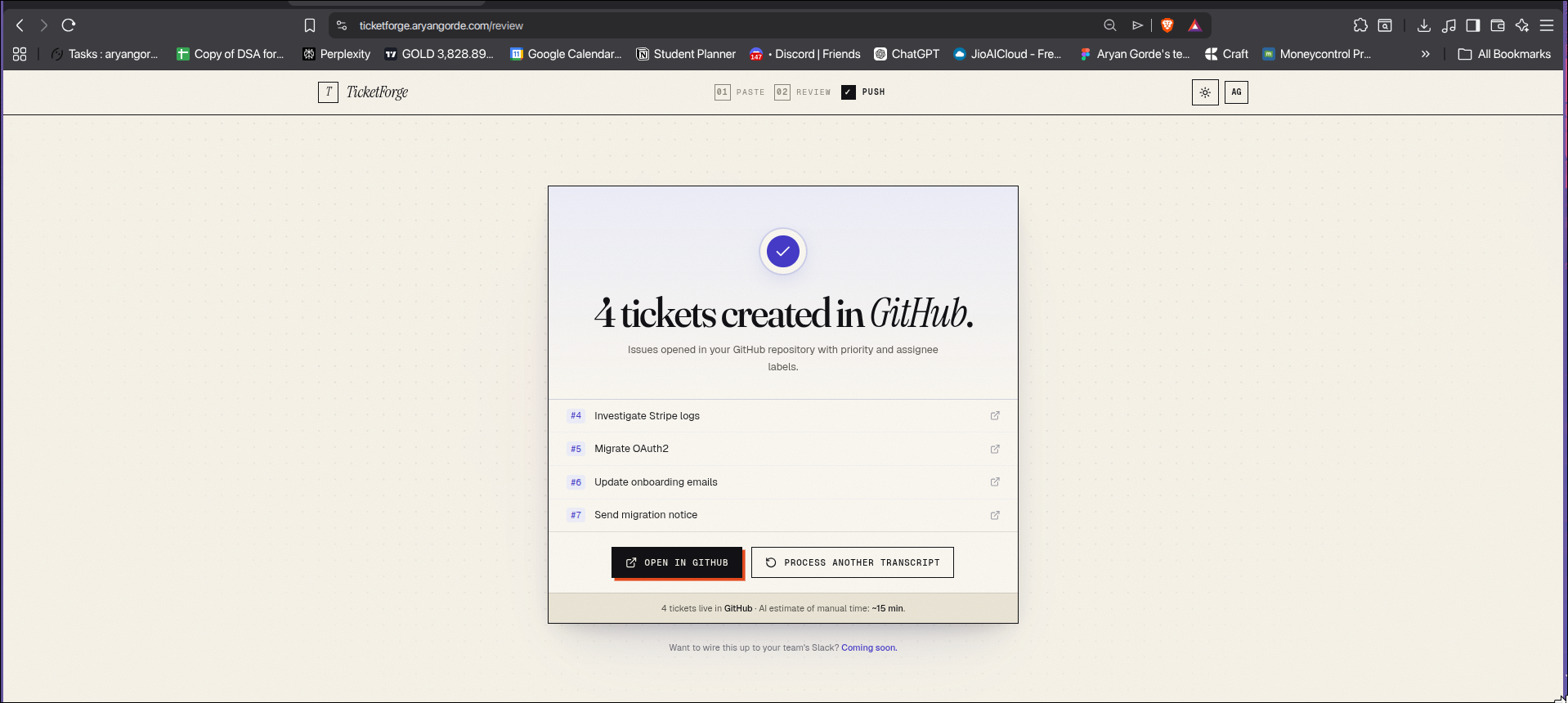
github issues page
-
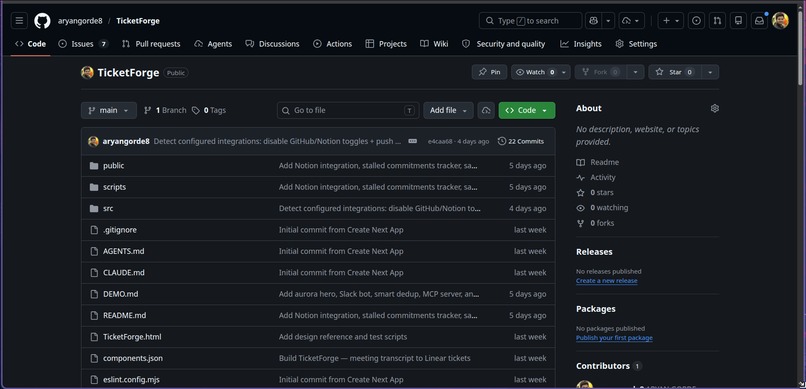
github repo page , already given the github link in try it section
-

footer and TicketForge Logo
-
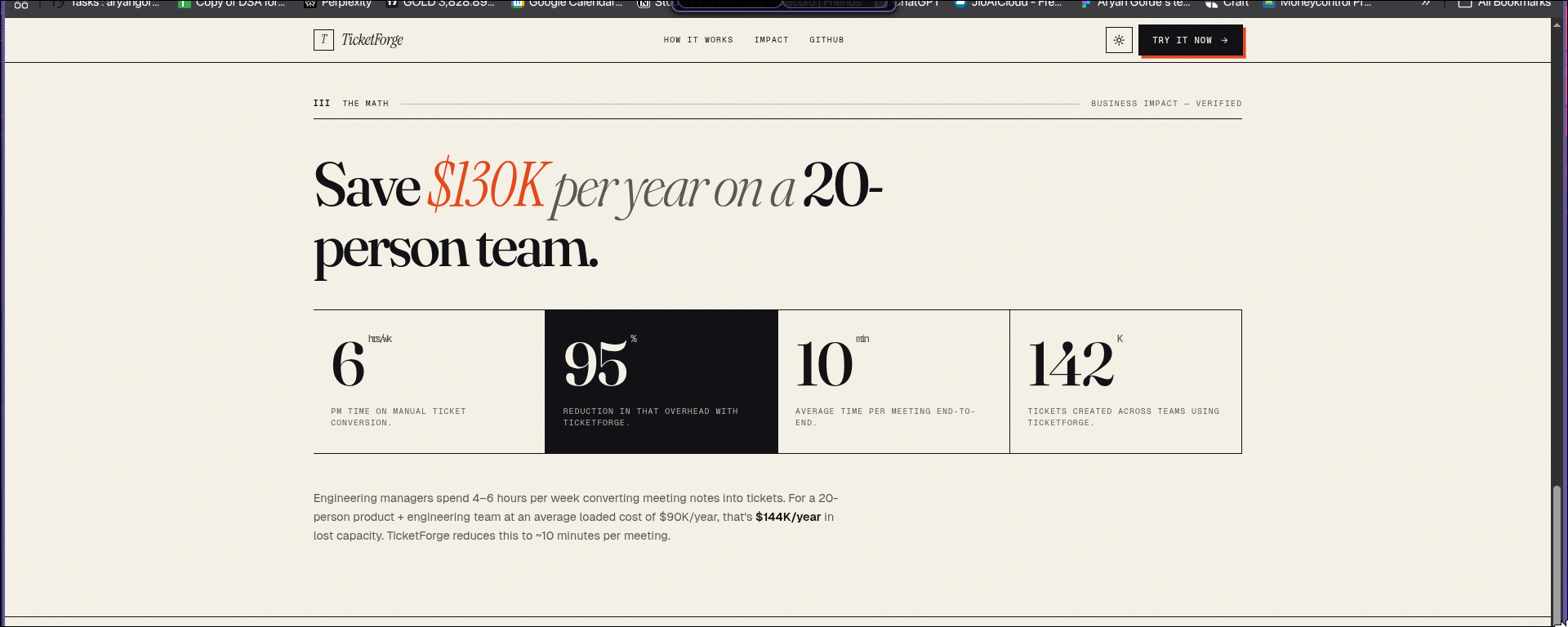
impact
-
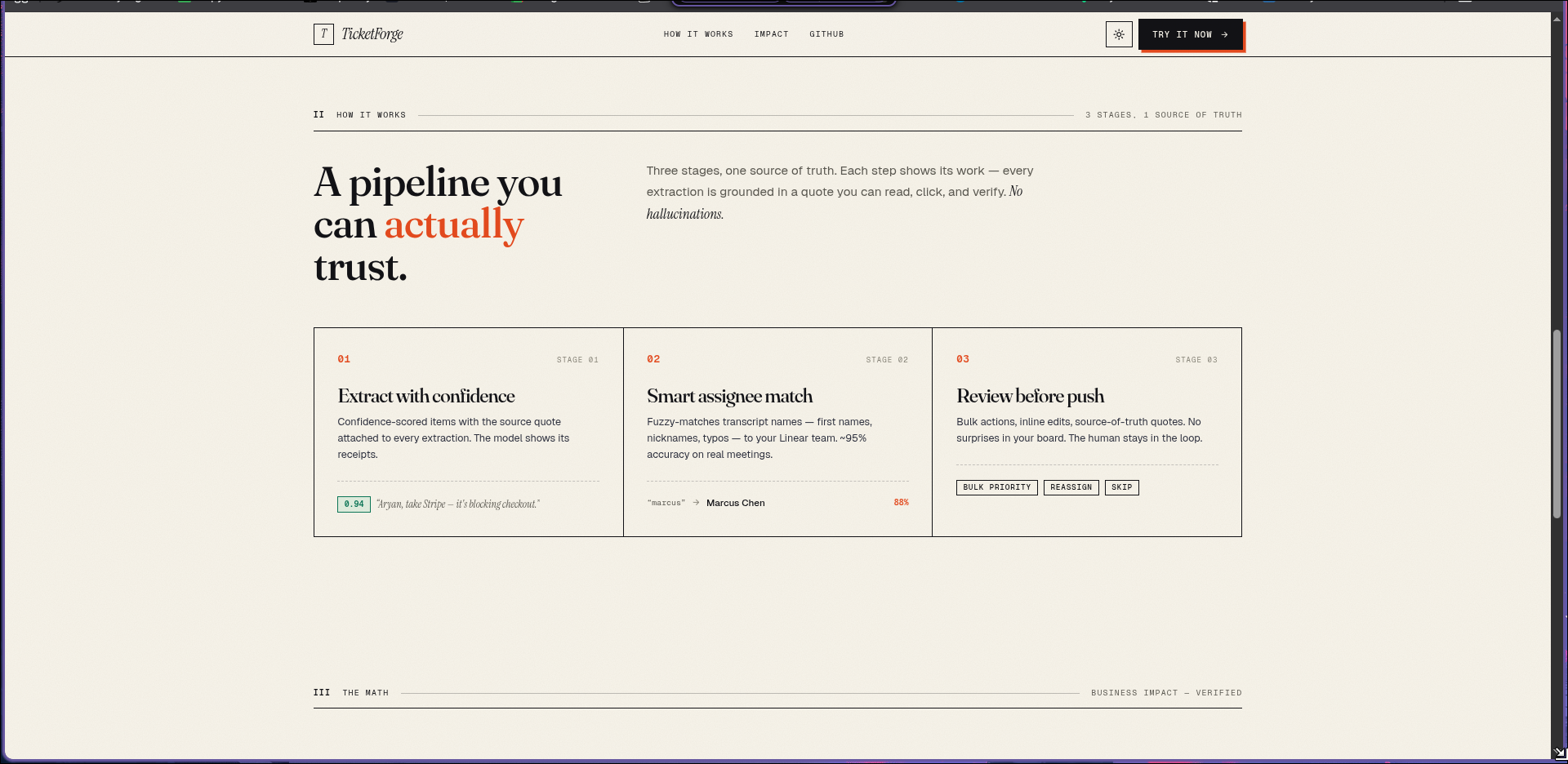
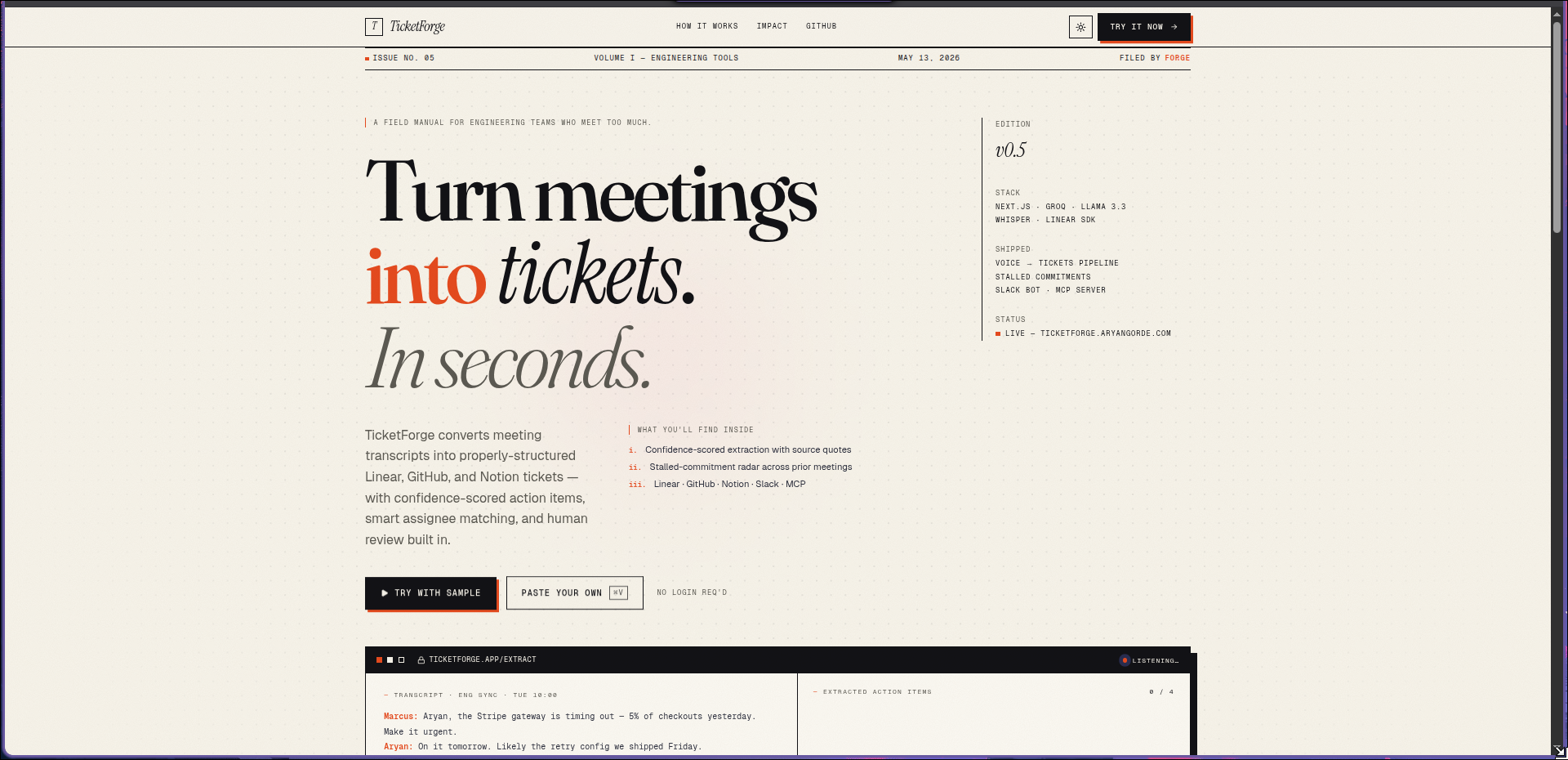
how it works
-
push to github
-
checking notion
-
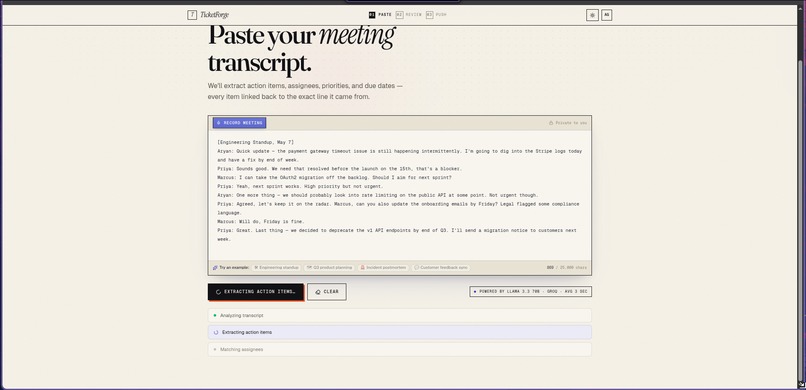
script
-

light mode
-
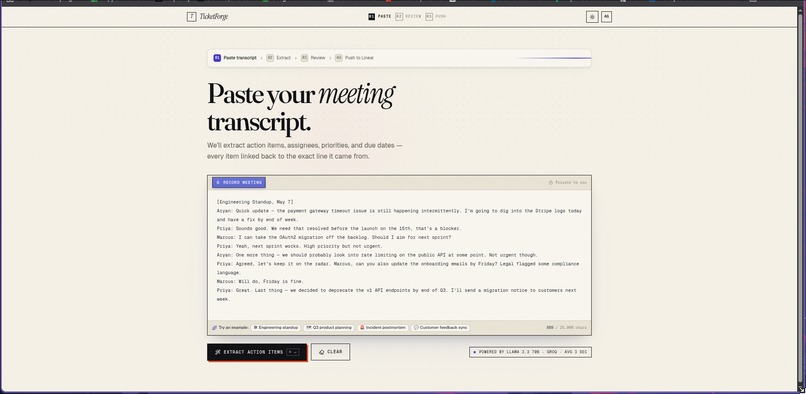
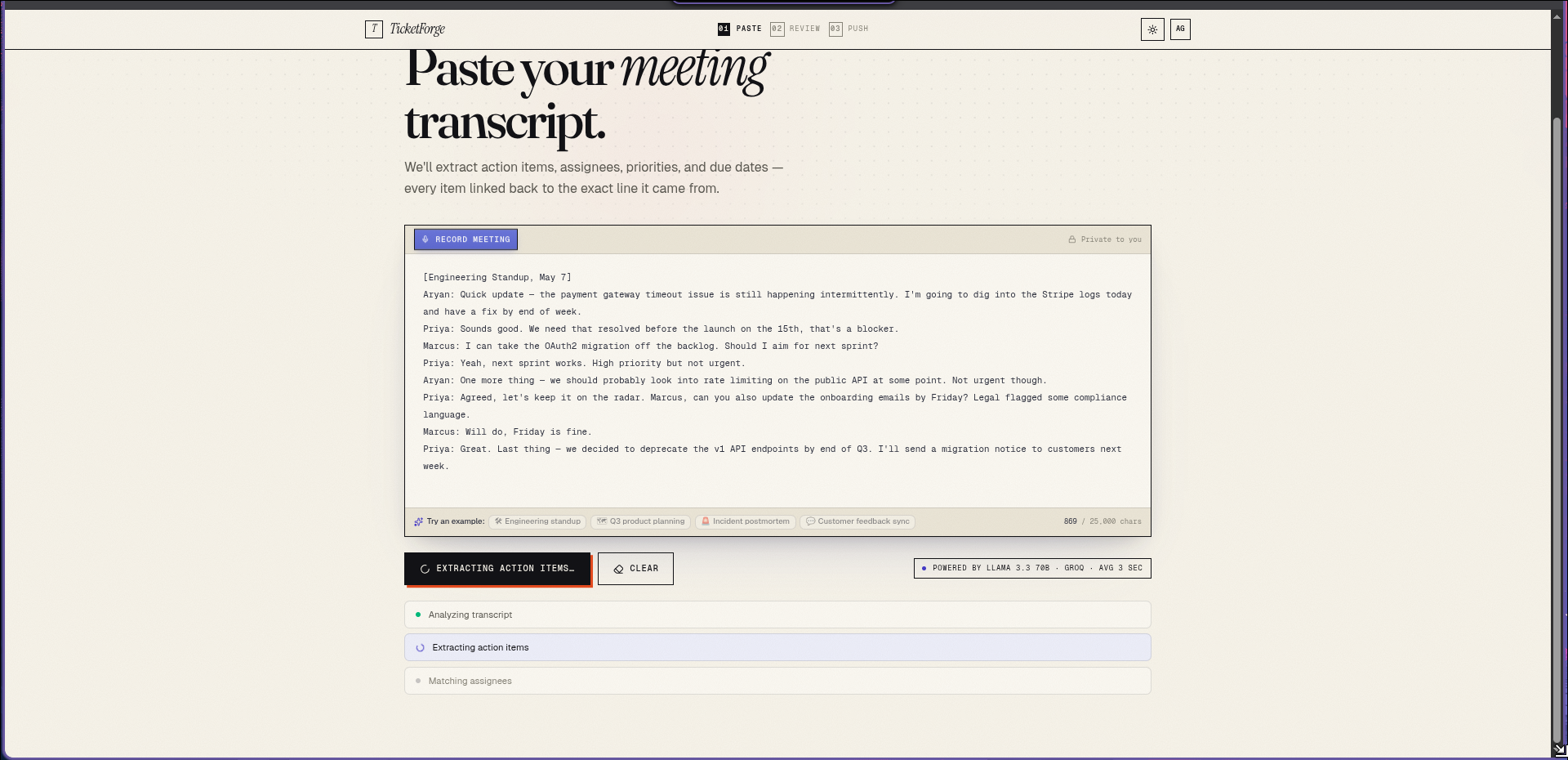
processing sample transcript , also can use voice feature for live voice to transcript
-
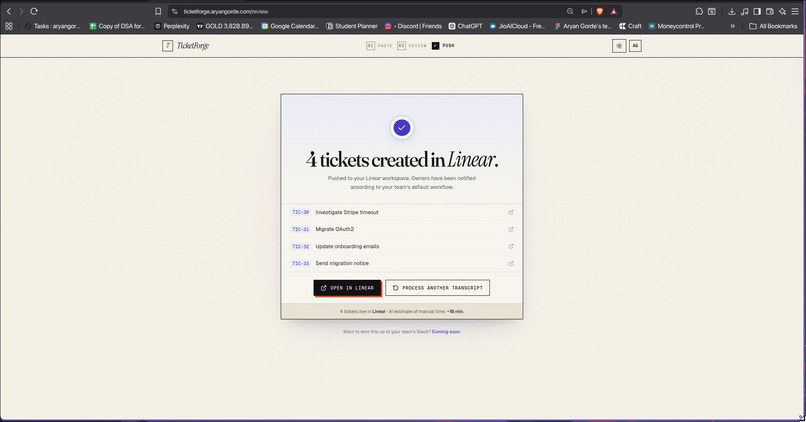
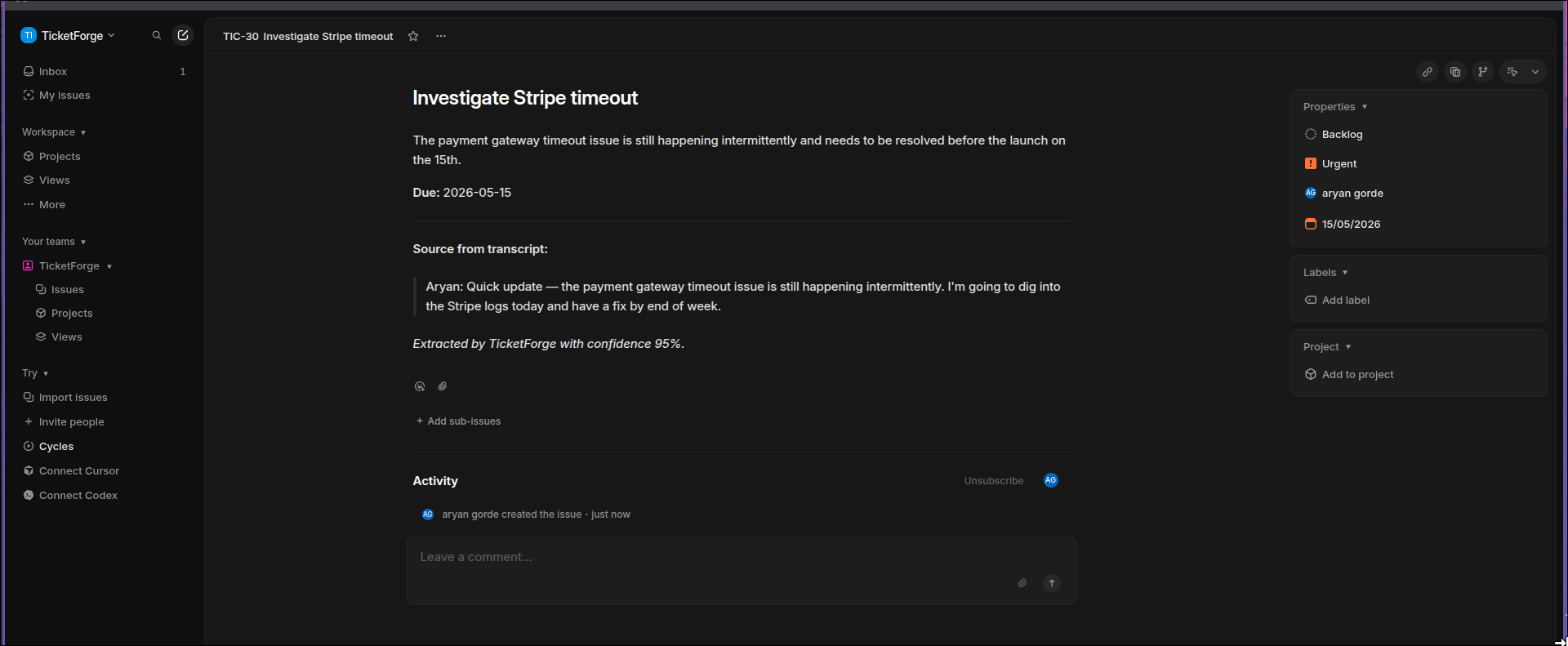
pushing to linear
-
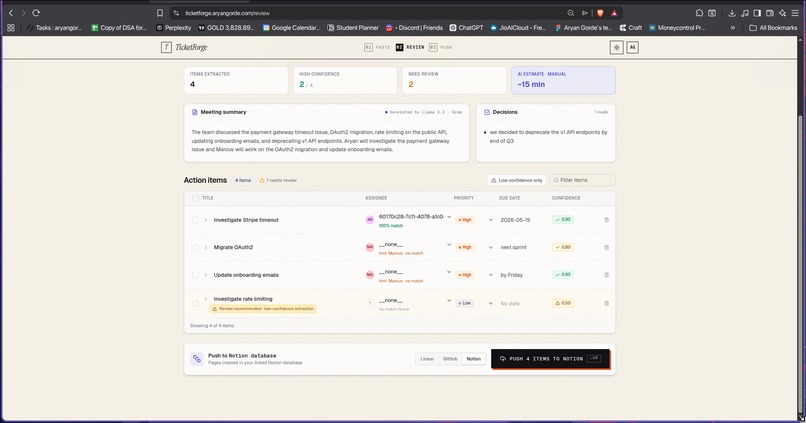
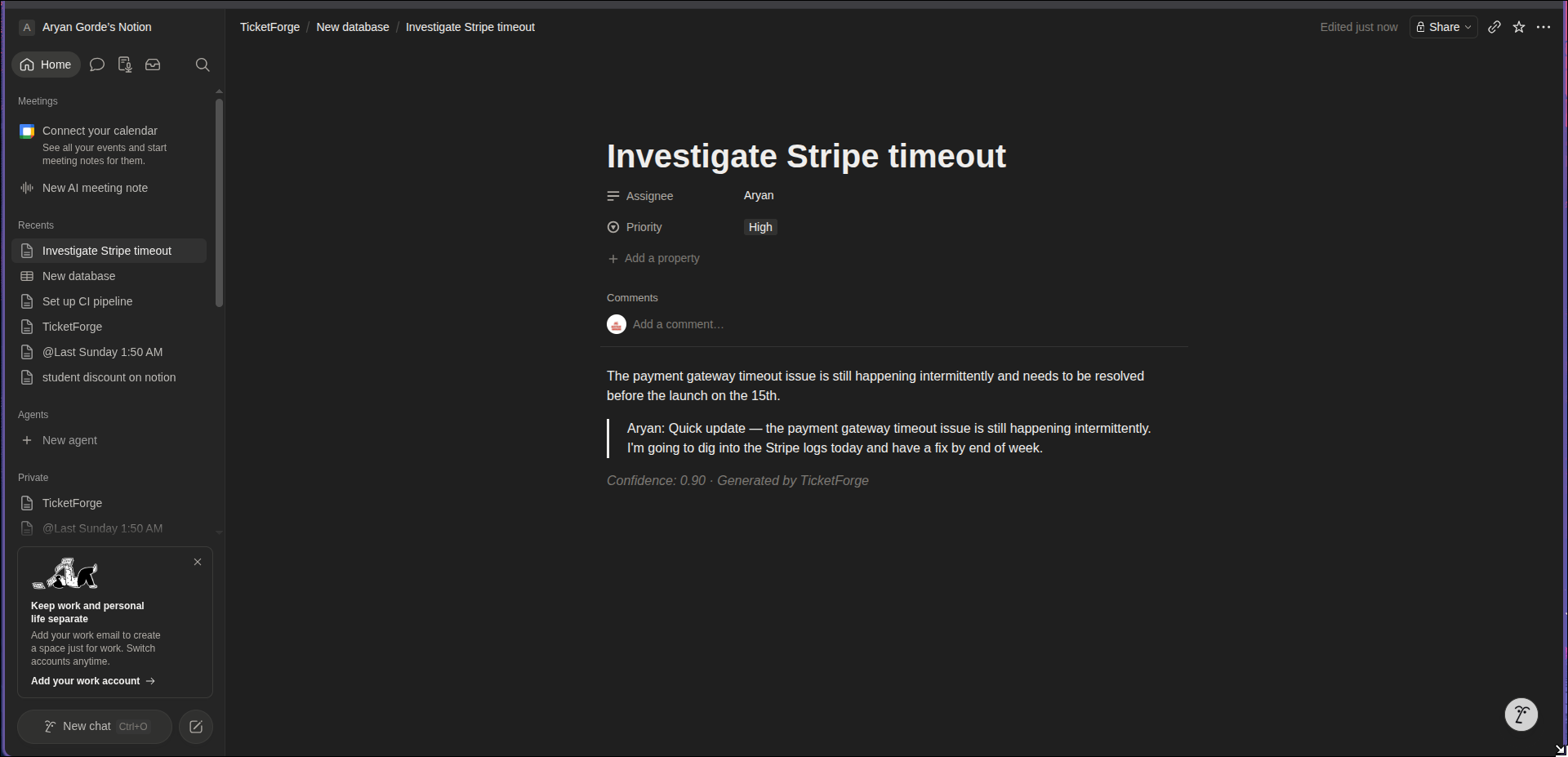
push to notion
-
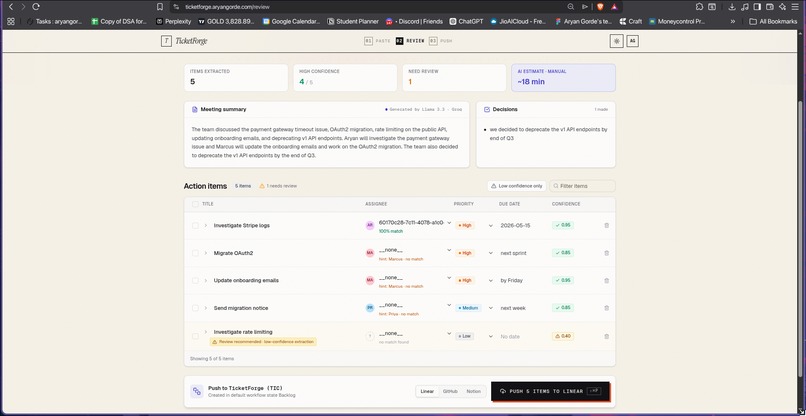
analyzing with ai
-
dark mode

Inspiration
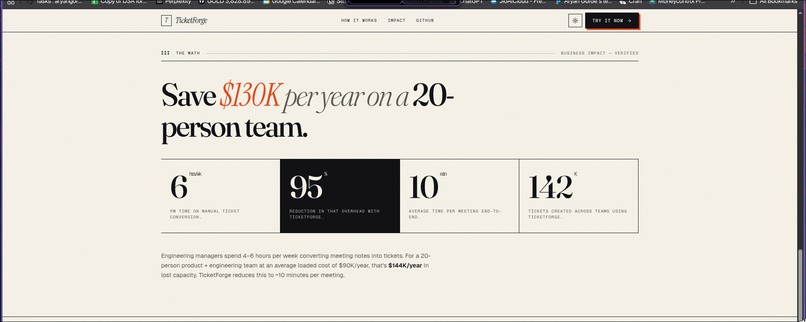
Every engineering manager I know has the same Friday afternoon ritual: open the meeting transcript, copy-paste fragments into Linear, fix the assignee names the AI got wrong, set priorities by hand, and lose an hour. For a 20-person team, this adds up to $130K/year in lost capacity. I wanted to fix it.
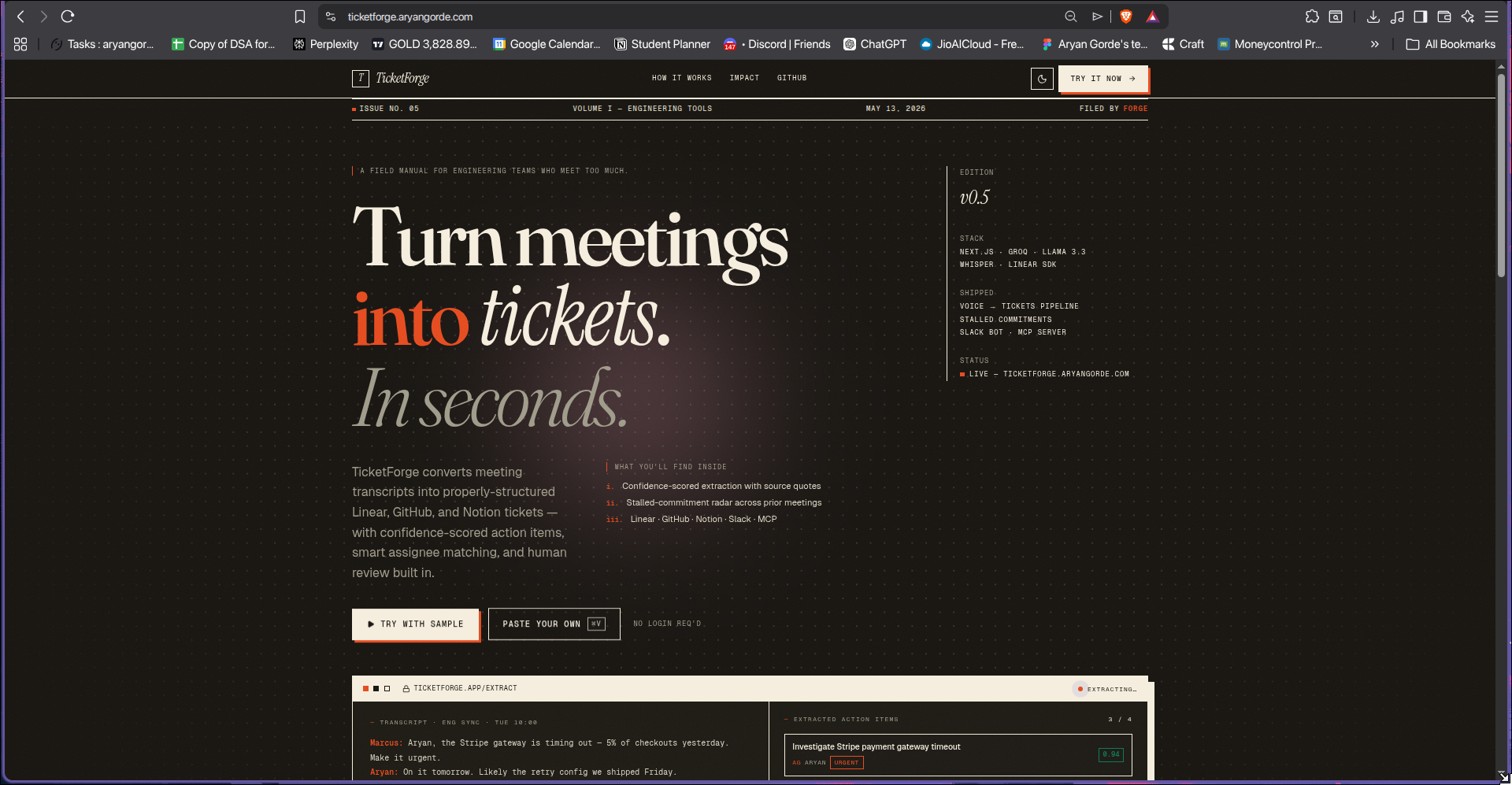
What it does
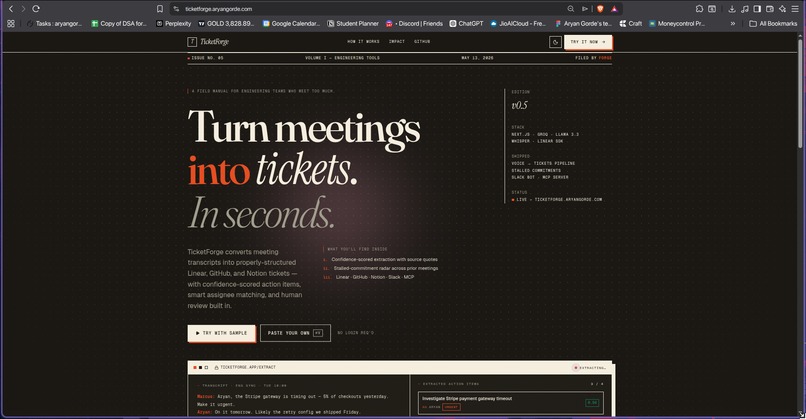
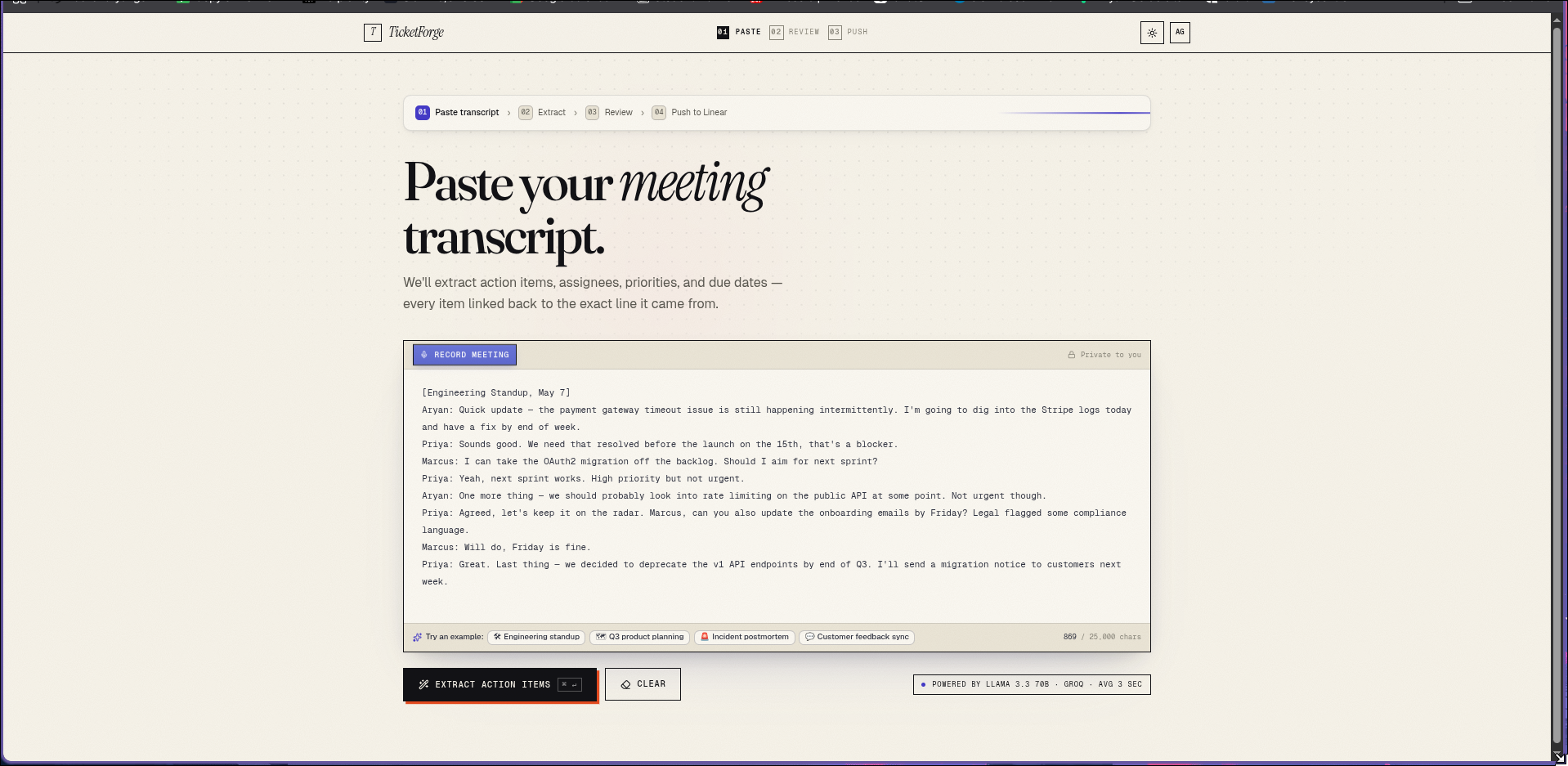
TicketForge converts meeting transcripts into properly-structured Linear tickets in 10 seconds.
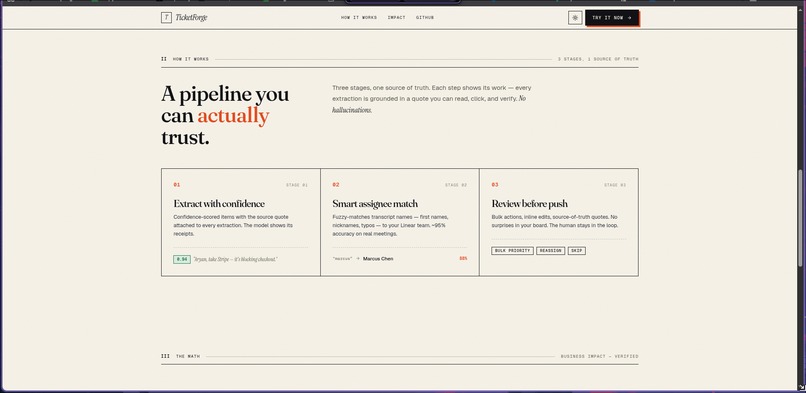
You can paste a transcript, upload a .vtt file, or record live in the browser. The AI extracts action items with:
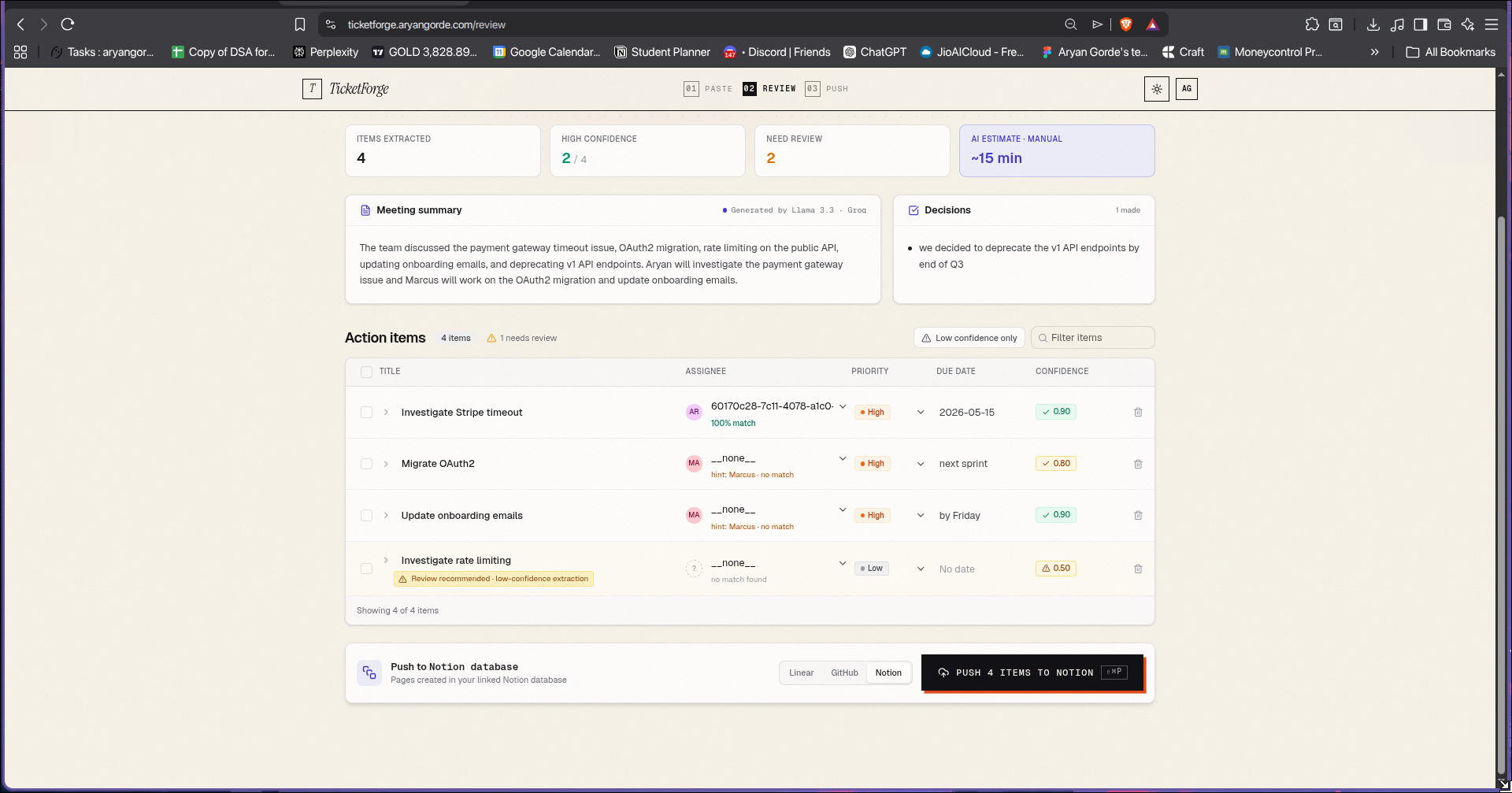
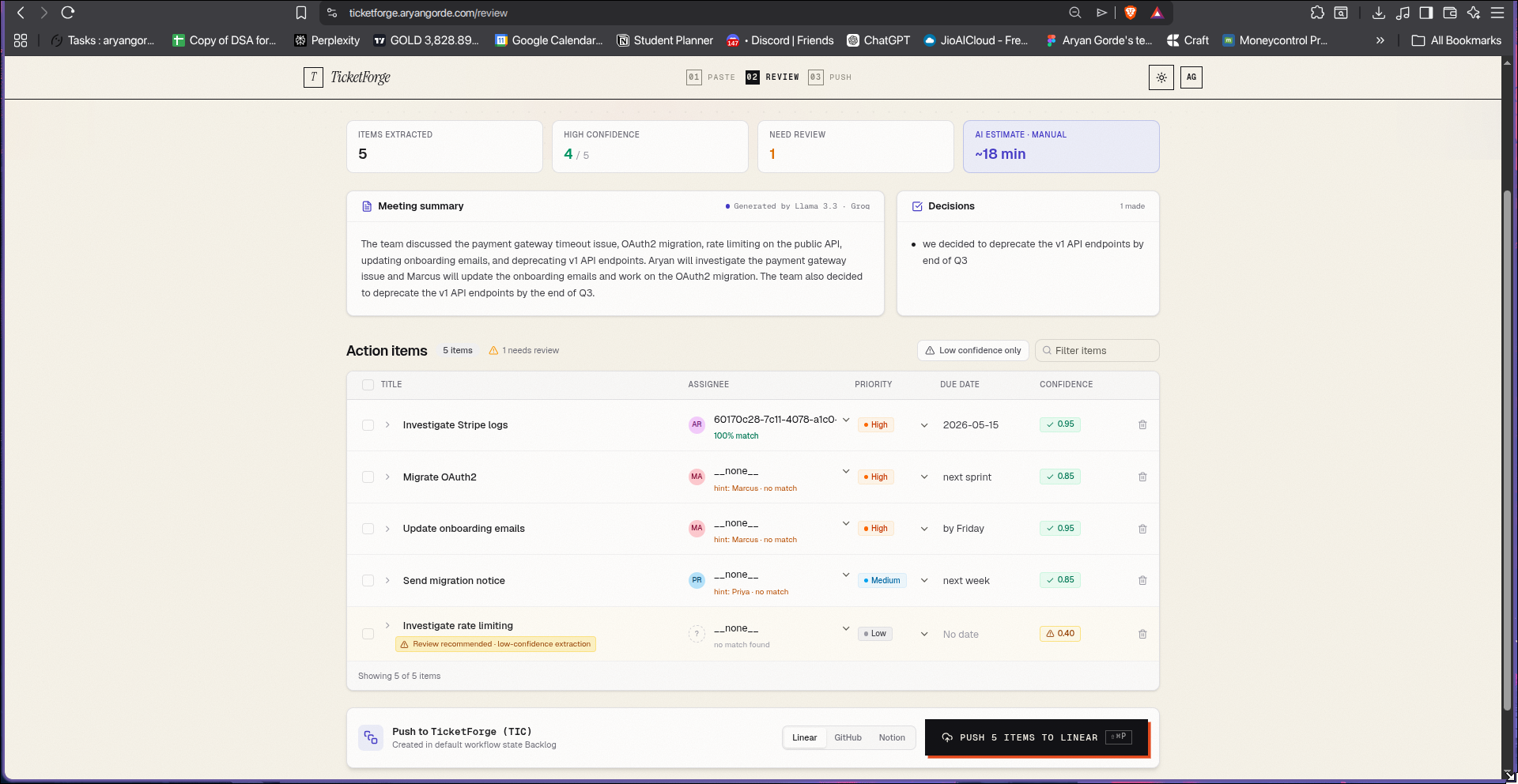
- Confidence scores so you review what needs review, not everything
- Source quotes — every ticket links back to the exact line it came from
- Smart assignee matching that handles first names, nicknames, and typos
- Priority and due date inference from natural language
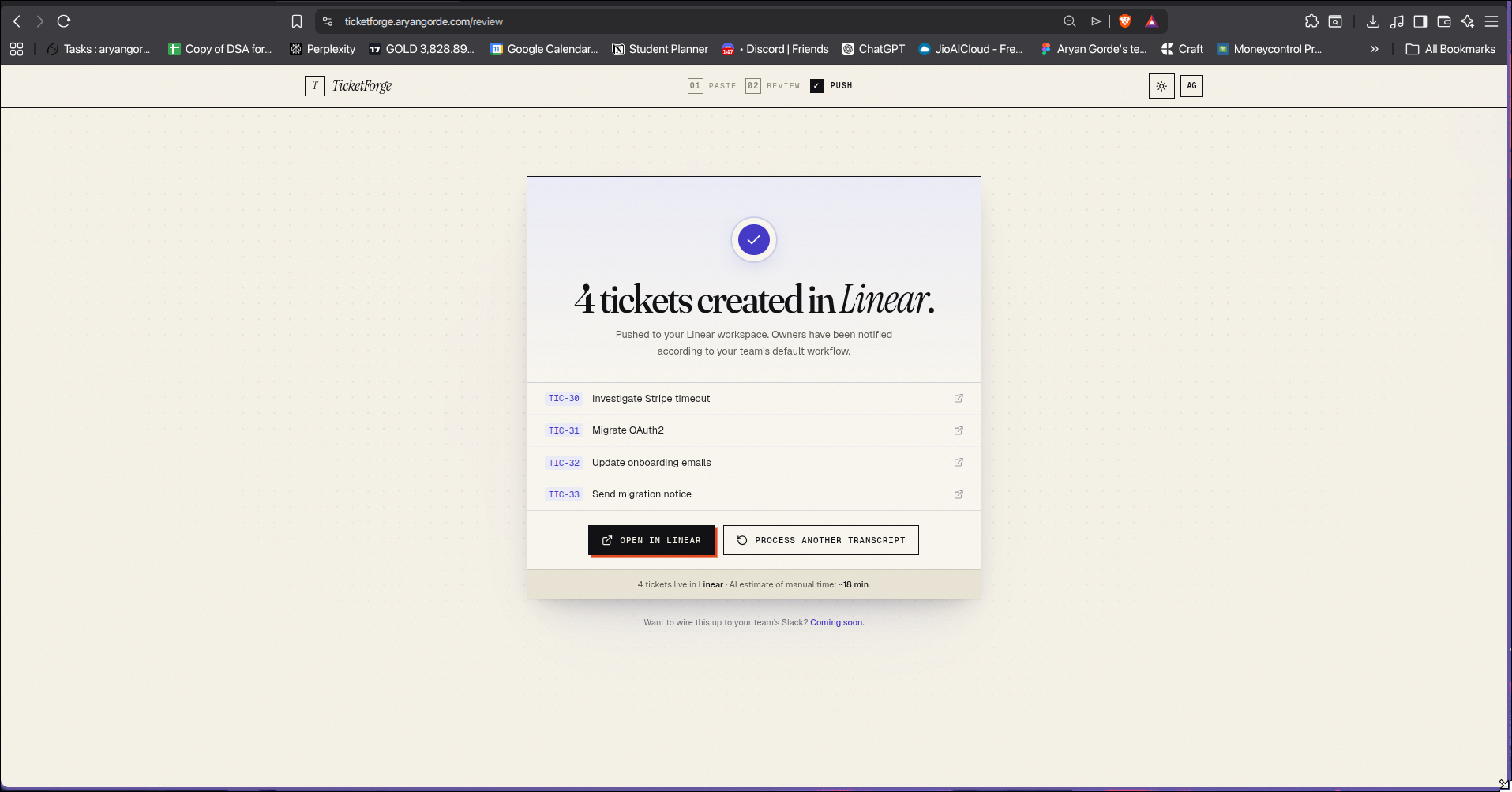
You review in a clean human-in-the-loop UI, then push to Linear, GitHub Issues, or Notion. There's also a Slack bot so your team can trigger extraction directly from any channel.
How I built it
- Frontend: Next.js 16 (Pages Router) + TypeScript + Tailwind CSS v4
- AI: Groq (Llama 3.3 70B for extraction + time estimation, Whisper Large V3 Turbo for transcription) with Zod schema validation and auto-retry on invalid JSON
- Integrations: Linear SDK, GitHub REST API, Notion API, Slack Web API with HMAC signature verification
- Hosting: AWS EC2 (t3.small), Nginx reverse proxy, PM2, Let's Encrypt SSL
- Custom domain: ticketforge.aryangorde.com
Challenges I ran into
LLM output reliability. Groq's JSON mode guarantees valid JSON syntax but not schema adherence. Solved with Zod validation + automatic retry with a stricter instruction on the second attempt.
Assignee matching accuracy. Pure Levenshtein matched "Sara" to "Sarah" but also matched "Marcus" to "Marc" at the same score. Built a hybrid scorer with first-name boost and substring containment that handles transcript-style names correctly ~95% of the time.
State between pages. No database, no auth — used sessionStorage to pass extraction results from /extract → /review. Survives refresh, doesn't leak across sessions.
Accomplishments I'm proud of
- Full end-to-end flow live on a custom domain with HTTPS in 4 days
- Voice → tickets pipeline that actually feels magical when you demo it
- Confidence scoring that makes the human-in-the-loop UX feel intentional, not like a workaround for unreliable AI
- AI-generated time estimate that shows exactly how many minutes the manual work would have taken
What I learned
- Whisper-Large-V3-Turbo via Groq is fast enough for live demos — sub-2-second transcription on a 30-second clip
- Slack's Block Kit is genuinely good for non-trivial bot UIs
- Keeping state in sessionStorage (no DB, no auth) is a legitimate architecture for hackathon tools
What's next for TicketForge
- Browser extension for one-click extraction from any Zoom/Meet/Otter page
- Calendar integration to auto-fetch transcripts when meetings end
- Recurring action item tracking — "Sarah, you said you'd ship the auth migration last week"
- Self-hostable Docker image for teams that can't send transcripts to a third party
Built With
- 3.3
- 70b
- amazon-web-services
- api
- css
- ec2
- github
- groq
- linear
- llama
- next.js
- nginx
- notion
- slack
- tailwind
- typescript
- whisper

Log in or sign up for Devpost to join the conversation.