-
-
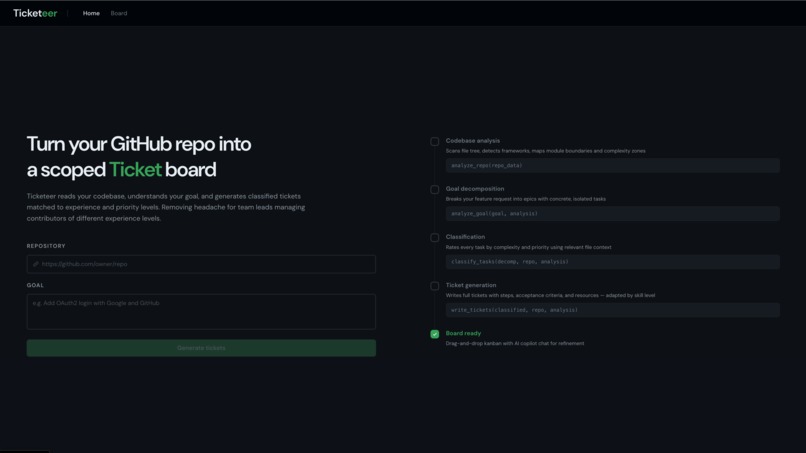
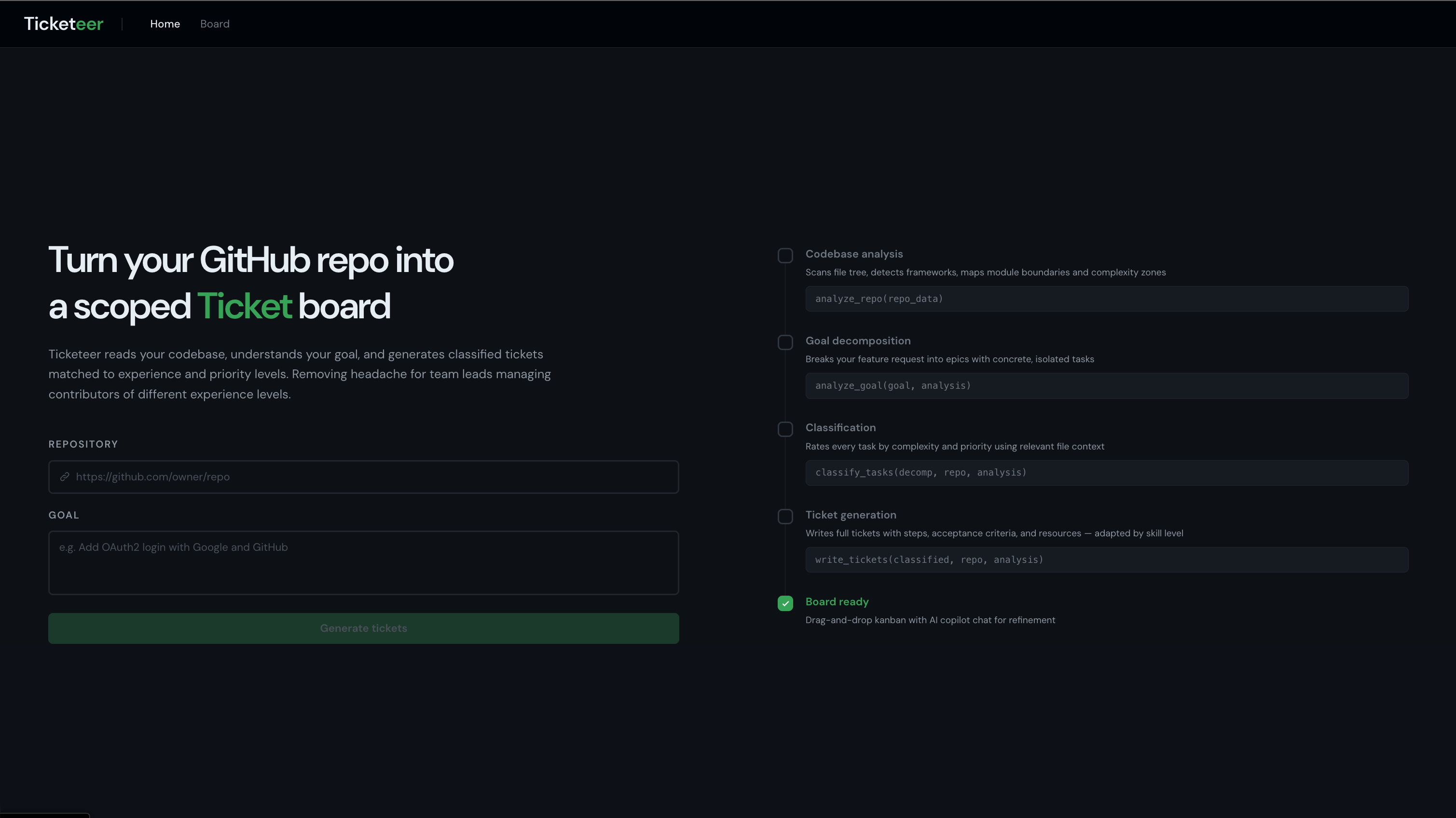
Home Page
-
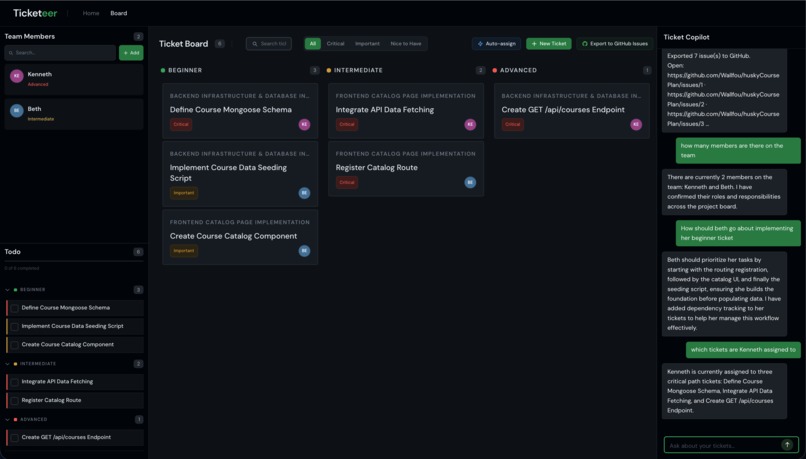
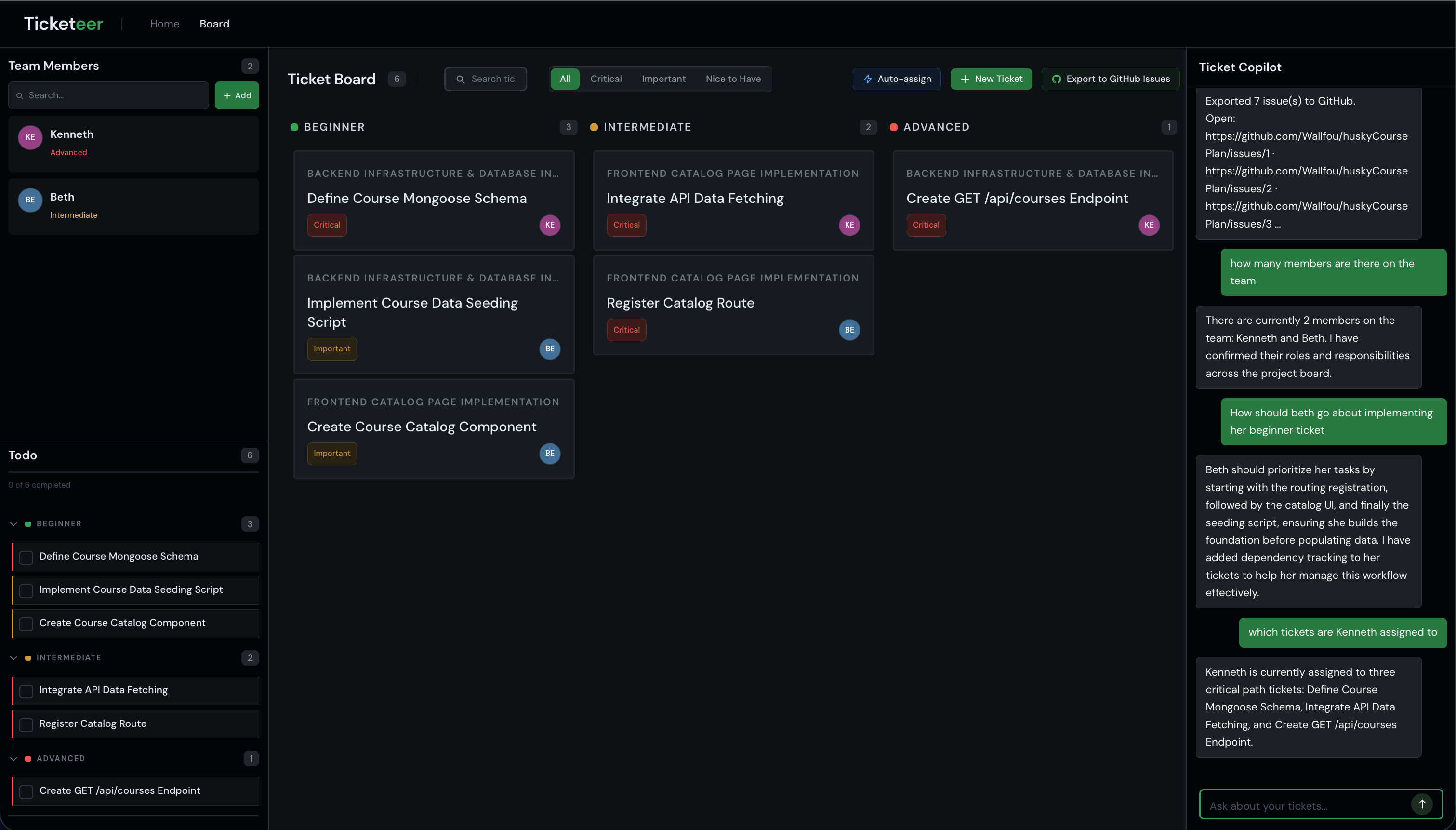
Kanban Board
Inspiration
Engineering clubs, open-source maintainers, and bootstrapped product teams often have one or two people who know the codebase well and many contributors who do not. Turning a feature idea into actionable, right-sized tasks usually falls on those leads, and writing tickets that match junior, mid, and senior expectations is repetitive and easy to get wrong. I wanted to streamline that planning process without replacing human judgment—so leads spend less time scoping and contributors spend less time guessing what “done” means.
What it does
- Connects a GitHub repository and pulls structure plus file contents (with sensible limits and emphasis on important paths).
- Analyzes the codebase into a structured summary: frameworks, languages, modules, and a rough complexity map.
- Decomposes a natural-language goal into epics and tasks with file hints grounded in the real tree.
- Classifies each task by complexity (beginner → advanced) and priority (critical path → nice-to-have), with short reasons tied to relevant code.
- Generates full tickets—steps, acceptance criteria, file references, and resources—with detail scaled to skill level.
- Presents work on a drag-and-drop kanban by complexity column, with an AI chat that can create, update, or delete tickets from conversation, plus optional team roster and AI-assisted assignment to balance skills and workload.
- Can push tickets to GitHub Issues (labels, bodies, ordering, and dependency links) when you want the board to live in the repo.
How we built it
- Frontend: React, TypeScript, Tailwind, and React Router. The home flow orchestrates staged API calls (analyze repo → AI pipeline → navigate to the dashboard). The dashboard holds board state, sidebar navigation, team panel, and a copilot chat that applies structured ticket mutations returned from the server.
- Backend: FastAPI routes for GitHub fetch/analyze and a multi-step AI pipeline implemented with Google Gemini (async calls with rate limiting and retries). Prompts return strict JSON for analysis, decomposition, classification, ticket bodies, chat actions, and batch assignment.
- Context: Repository context is built from the file tree and file contents (capped in size); per-task relevant file retrieval scores paths against titles, descriptions, and hints before classification and ticket writing.
- Integrations: GitHub REST API for repo contents; optional flow to create Issues from generated tickets.
Challenges we ran into
- Model output reliability: Getting consistently valid JSON across long prompts required stripping markdown fences, careful schemas, and retries when the API wrapped or truncated responses.
- Context limits: Large repos exceed what we can send at once, so we prioritize certain files, cap total characters, and lean on retrieval for per-task snippets instead of repeating the whole repo every time.
- Rate limits: Concurrent classification of many tasks is powerful but can hit quotas; we added throttling and backoff to stay within limits.
- UX for long runs: Multi-step generation feels like a pipeline; we surfaced progress steps and clear errors when analysis or generation fails.
Accomplishments that we're proud of
- An end-to-end path from “paste a repo + goal” to a populated board with epics and tickets—not a single generic dump, but per-task classification and skill-aware ticket text.
- A copilot that reasons over the live ticket list (and optional team roster) and returns explicit create/update/delete actions, so refinement stays structured and reviewable.
- Assignment that considers complexity, tags, workload, and critical path—useful for real student or OSS teams.
What we learned
- Grounding matters: Tickets are far more useful when titles, hints, and snippets come from the actual repository rather than generic advice.
- Structured outputs beat freeform: Defining JSON shapes for each stage makes the UI and board logic predictable and easier to debug.
- Product shape: Planning tools need to feel fast and transparent; showing pipeline progress and preserving chat/board state carefully improves trust during long AI operations.
What's next for Ticketeer
- Smarter retrieval (e.g. embeddings) for huge monorepos where keyword scoring is not enough.
- Deeper GitHub integration: sync status with Issues, PR links, and CI signals on the board.
- Templates and constraints: let leads lock epics, dependencies, or “out of scope” areas before generation.
- Collaboration: shared sessions, comments on tickets, and export to other trackers (Jira, Linear).
Built With
- api
- fastapi
- gemini
- github
- react
- tailwind
- typescript

Log in or sign up for Devpost to join the conversation.