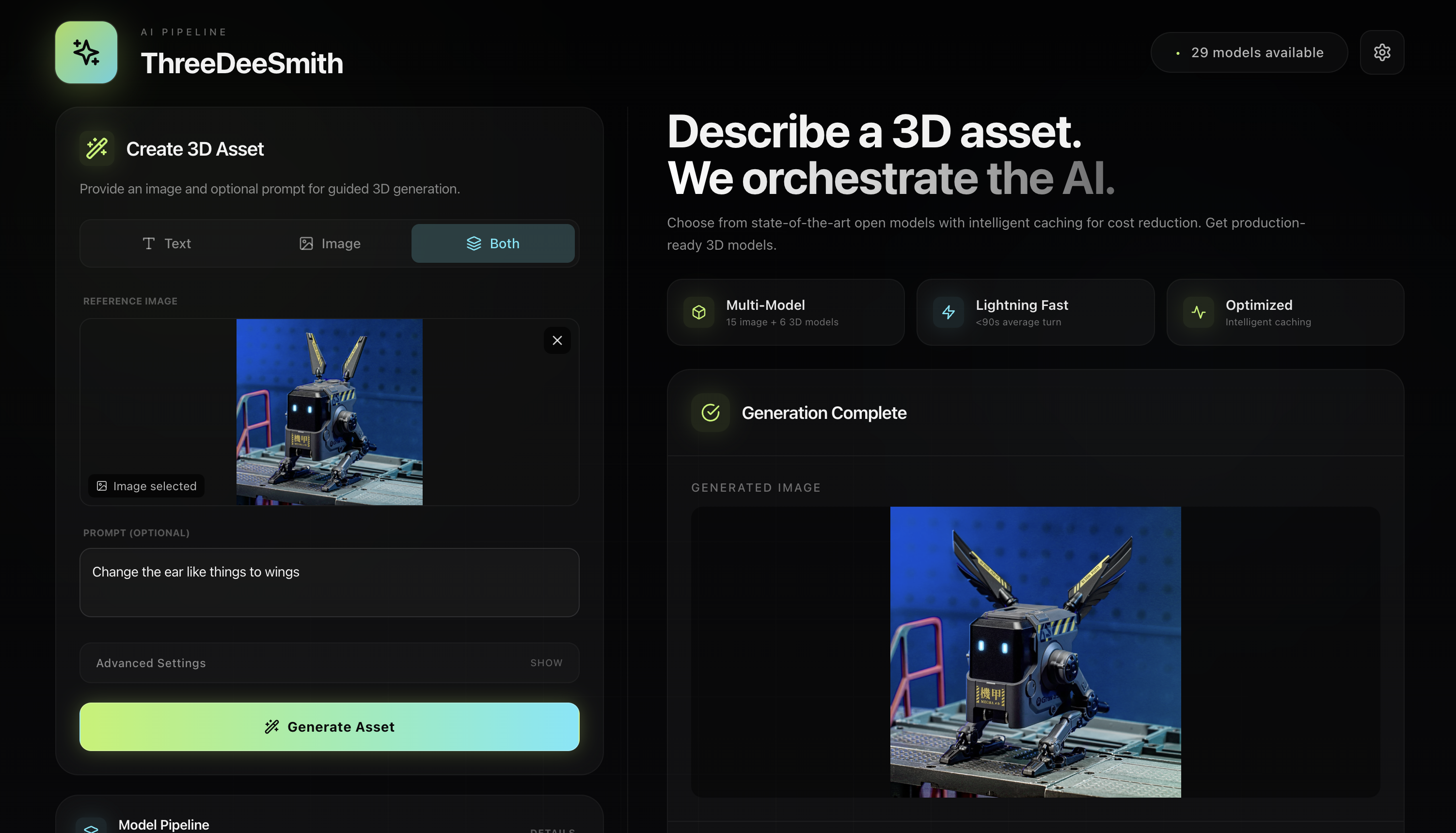
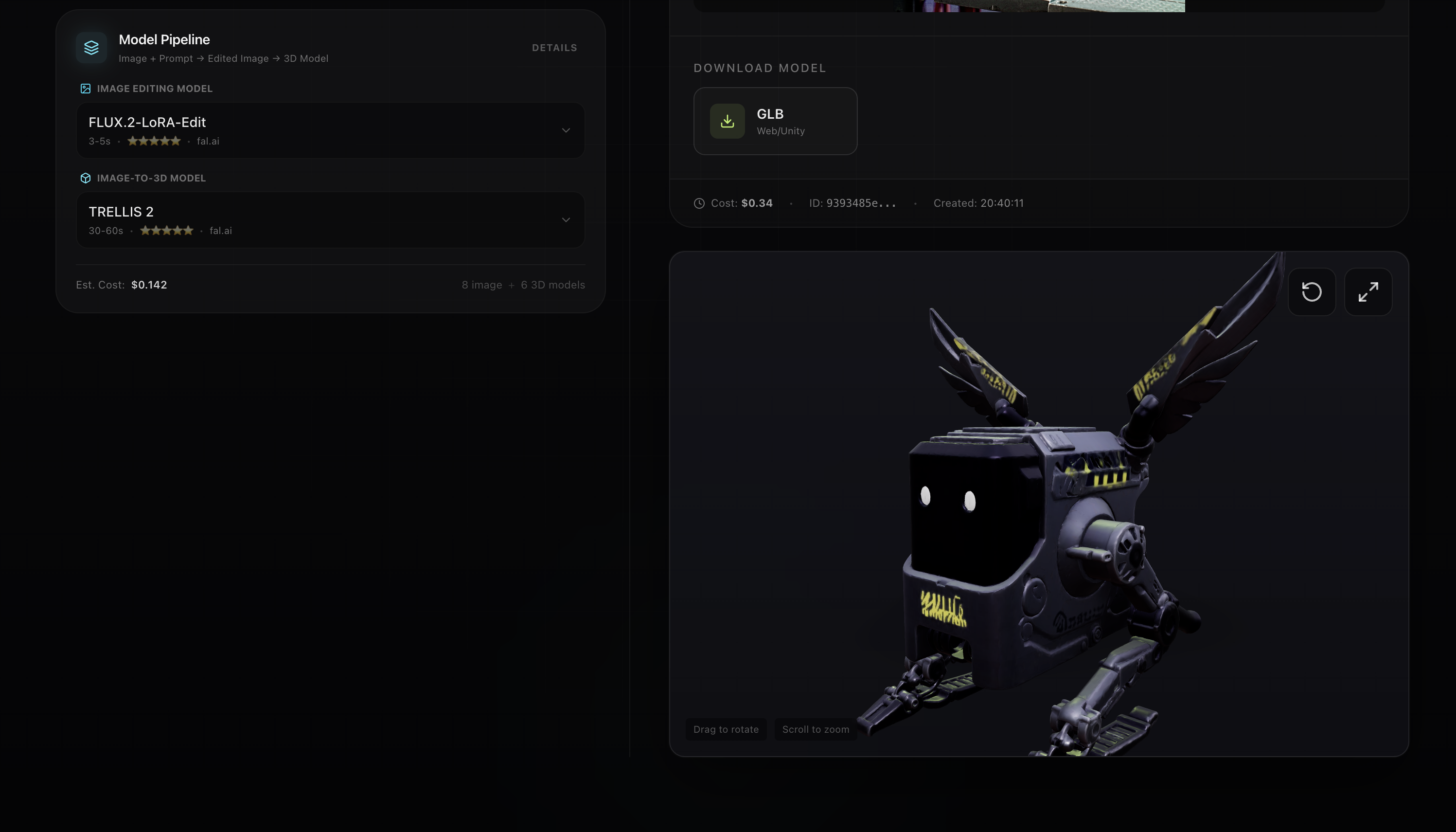
Here's the thing about text-to-3D right now: you're stuck.
Use fal.ai directly? You get one model, their interface, their way. HuggingFace? Great if you want to write Python scripts for every generation. The closed APIs? Cool until they change pricing or shut down.
ThreeDeeSmith is different. Think of it like Perplexity, but for 3D generation.
Just like Perplexity lets you switch between Claude, GPT, and Gemini for answers—we let you switch between Trellis 2, Hunyuan3D, FLUX, Qwen, and 29 other models right in the UI. One click. No code.
And here's where it gets interesting: you're not tied to any provider. Run it on fal.ai for speed. Use HuggingFace for cost. Or flip to local GPU mode—the models download automatically and run on your own hardware. Zero API costs. Complete privacy.
It's also ridiculously instruction-following. Type "a minimalist wooden chair with thin metal legs and a curved backrest"—and that's what you get. Not "a chair, but we interpreted it creatively." Actual instruction-following.
One interface. 29 open models. Three hosting modes. Full control.
Inspiration
I've tried them all. Seriously.
fal.ai is fast, but you're locked into whatever model they've surfaced that week. HuggingFace has amazing model variety, but running inference means spinning up scripts, managing dependencies, praying your venv doesn't explode. The closed APIs—Meshy, Rodin—are convenient until you see the invoice.
And none of them feel flexible. Want to try Trellis 2 on Monday and Hunyuan3D on Tuesday? Different platforms, different APIs, different UIs. It's exhausting.
I wanted something simpler: one place to access all the best open models, with the freedom to run them however I want.
Not someone else's choice of model. My choice.
So we built it. A unified interface that sits above the models and providers, giving you the control that power users actually want—while keeping it simple enough that anyone can use it.
What It Does
Text → Image → 3D. Three steps, one button.
- You describe what you want: "A wooden chair with curved armrests"
- An AI image model generates a high-quality reference image
- A 3D generation model converts that into a textured GLB mesh
You get a downloadable 3D model that works everywhere—Unity, Unreal, Blender, the web.
What Makes ThreeDeeSmith Different
🔀 Model Switching (Like Perplexity for 3D)
- 29 models available: 11 for image generation, 6 for 3D
- Switch between them with a dropdown—no code, no API changes
- Each model has different strengths: speed, quality, style
🏠 True Local GPU Support
- Select "Local GPU" as your provider
- Models download automatically (one-time, cached)
- Run entirely offline after that—no API keys, no per-generation costs
- Your data never leaves your machine
☁️ Multi-Provider Flexibility
- fal.ai: Fastest inference, pay-per-generation
- HuggingFace: Wide model selection, flexible pricing
- Local: Free after download, complete privacy
- Switch providers anytime without changing your workflow
📝 Actually Instruction-Following
- "Minimalist wooden chair with thin metal legs" → exactly that
- "Futuristic sports car with gull-wing doors" → exactly that
- We tuned prompting and model selection for precision, not "creative interpretation"
🔐 Your Keys, Your Data
- API keys stored only in your browser's localStorage
- Never synced. Never uploaded. Never logged.
- Backend only uses what you explicitly send it
🔧 Extend It Yourself
- New model dropped on HuggingFace? Add it to the registry in minutes
- The architecture is model-agnostic—same interface for text-to-image, image-to-3D, or any future pipeline
- Built for extensibility: add new providers, new models, new modalities without rewriting the stack
How We Built It
Frontend: React + TypeScript + Vite + TailwindCSS
- Three.js (via @react-three/fiber) for the interactive 3D viewer
- Full 360° rotation, zoom, environment lighting
- Dark glassmorphic UI that's easy on the eyes
Backend: Python + FastAPI
- Orchestrates the text → image → 3D pipeline
- Talks to fal.ai, HuggingFace, or local GPU—based on your settings
- Intelligent caching: generate something twice, second time is instant
The AI Models (all open-source): | Type | Models | |------|--------| | Image | Qwen-Image-2512, FLUX.1-schnell, FLUX.1-dev, FLUX.2-turbo, Stable Diffusion 3.5, SD-XL, Hyper-SD, and more | | 3D | Trellis 2 (Microsoft), TripoSR (Stability), Hunyuan3D (Tencent), InstantMesh, SPAR3D, PartCrafter |
Every single model is open. You can host them yourself, fine-tune them, or run them air-gapped in a secure environment.
Challenges We Ran Into
Building provider abstraction. Making fal.ai, HuggingFace, and local GPU feel identical from the UI was harder than expected. Each has different auth, different response formats, different error handling.
Local model management. Auto-downloading multi-gigabyte models, caching them properly, and handling partial downloads gracefully took real engineering.
Instruction-following quality. Default prompting doesn't cut it. We had to experiment with prompt templates and negative prompts to get consistent, faithful outputs.
3D viewer in dark mode. Assets looked washed out initially. Environment maps, directional lighting, and contact shadows fixed it without breaking the aesthetic.
Accomplishments We're Proud Of
The model-switching UX. It actually feels like Perplexity. Pick a model, generate, switch, compare. The workflow just works.
True local-first support. Not "local with an asterisk." Actual local. Models download automatically, run on your GPU, and don't phone home.
Open-source everything. Not just open-source friendly—open-source first. Every model can be self-hosted. There's no proprietary core.
It's fast and it's accurate. Under two minutes end-to-end. And the output matches the prompt, not some vague interpretation.
What We Learned
Orchestration is the product. The models exist. The APIs exist. The value is in making them work together seamlessly—choosing the right model for the task, handling failures, presenting progress.
Open models are production-ready. Trellis 2 competes with closed services. FLUX matches or beats Midjourney for many use cases. The gap is closed.
Flexibility beats features. Users don't want 50 features. They want to use the model they want, on the provider they want, without friction. We focused on that.
What's Next for ThreeDeeSmith
Multi-view generation. Generate and Accept multiple angles before 3D reconstruction. Models like Hunyuan3D support this—better input, better output.
Real-time preview. Show the 3D mesh as it's being generated, not just at the end.
Batch generation. Queue 20 variations, get them all. Perfect for asset libraries.
PBR materials. Some models output roughness, metallic, opacity. We should surface those properly.
New models as they drop. The architecture is ready—when a better image or 3D model releases, plugging it in takes minutes, not days.
Quick Start
# Clone the repo
git clone https://github.com/your-username/threedeesmith.git
cd threedeesmith
# Backend
cd backend
python -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
python main.py
# Frontend (new terminal)
cd frontend
npm install && npm run dev
Open http://localhost:3000. Click Settings. Choose your provider and add API keys (or select Local GPU). Start generating.
Project Structure
threedeesmith/
├── backend/ # Python FastAPI service
│ ├── main.py # API endpoints
│ ├── models/ # Model registry
│ ├── cache/ # Caching layer
│ └── utils/ # fal.ai client, helpers
├── frontend/ # React + TypeScript app
│ ├── src/
│ │ ├── components/
│ │ ├── lib/
│ │ └── App.tsx
│ └── vite.config.ts
├── .env.example # Environment template
└── README.md
License
MIT. Use it, fork it, build products with it.
Built by Rohith Raghunathan Nair

Log in or sign up for Devpost to join the conversation.