-
-
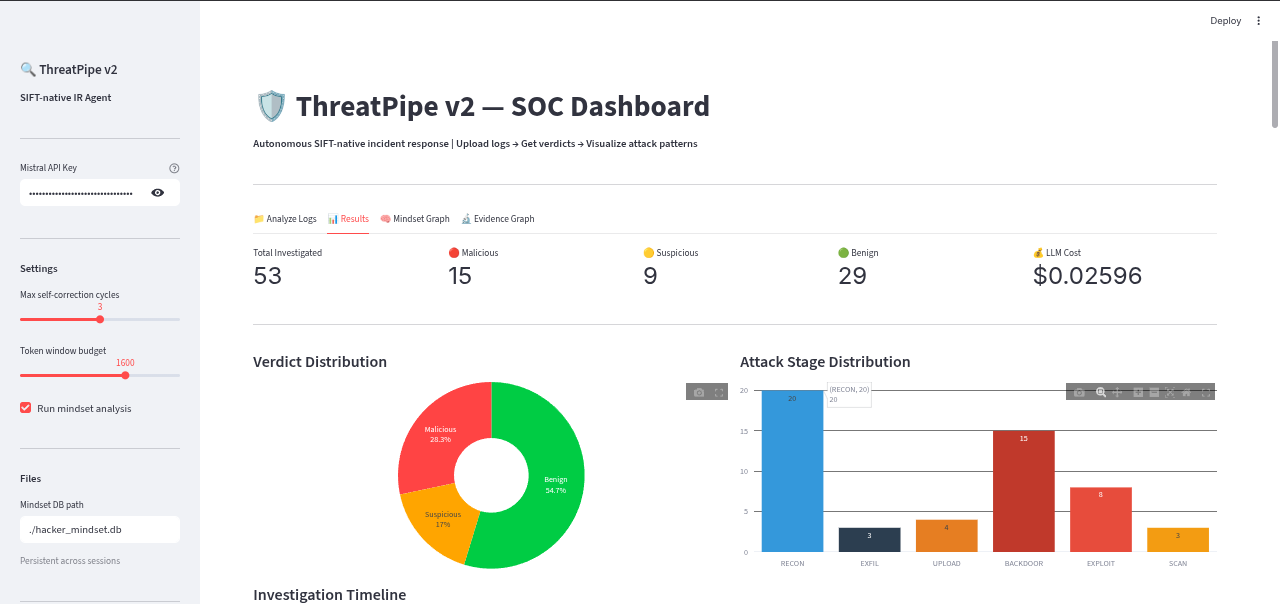
Main page
-
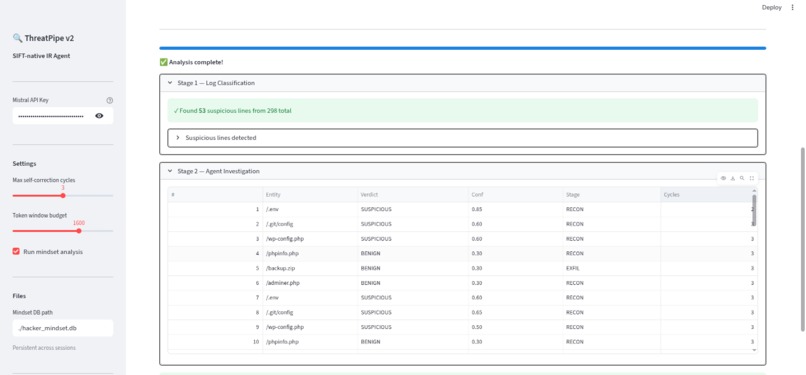
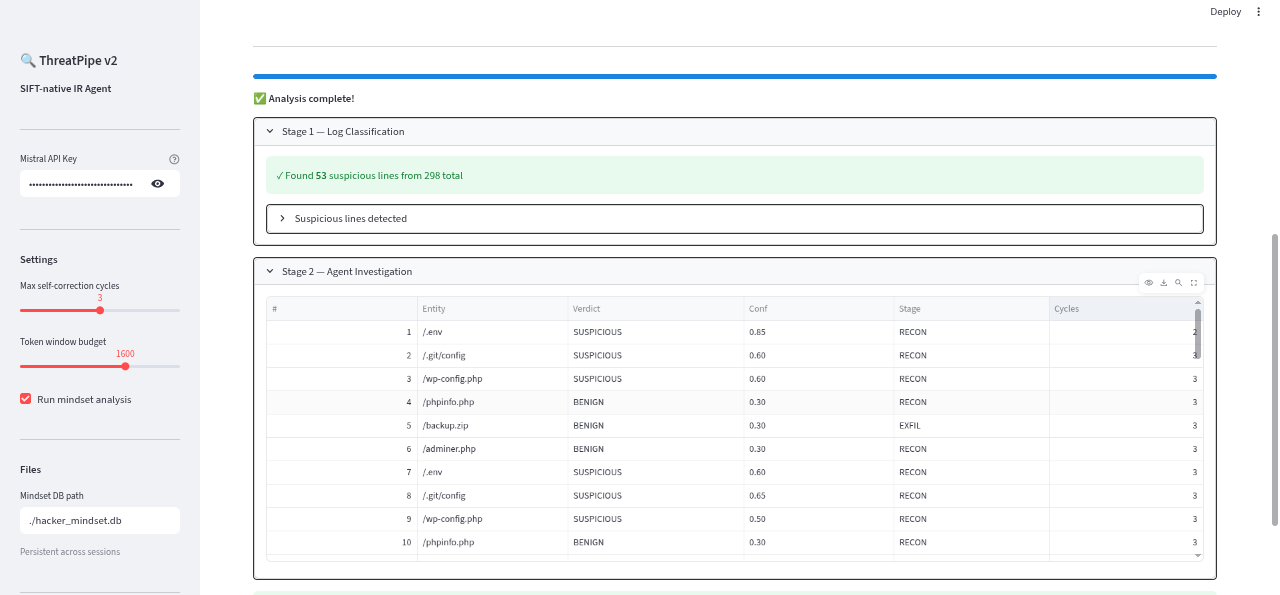
Classified and verdicted logs. final analysi done here.
-
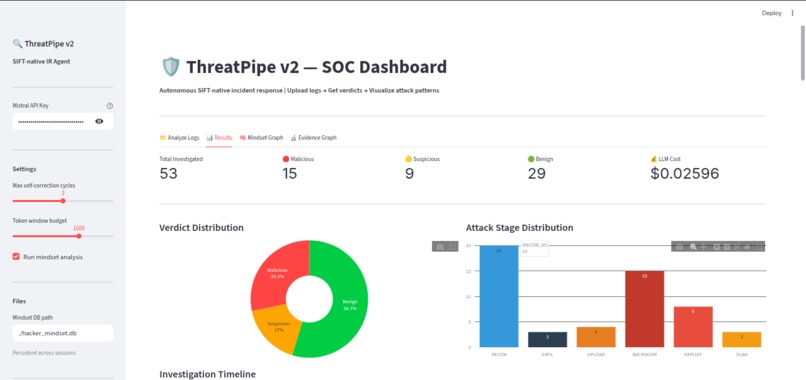
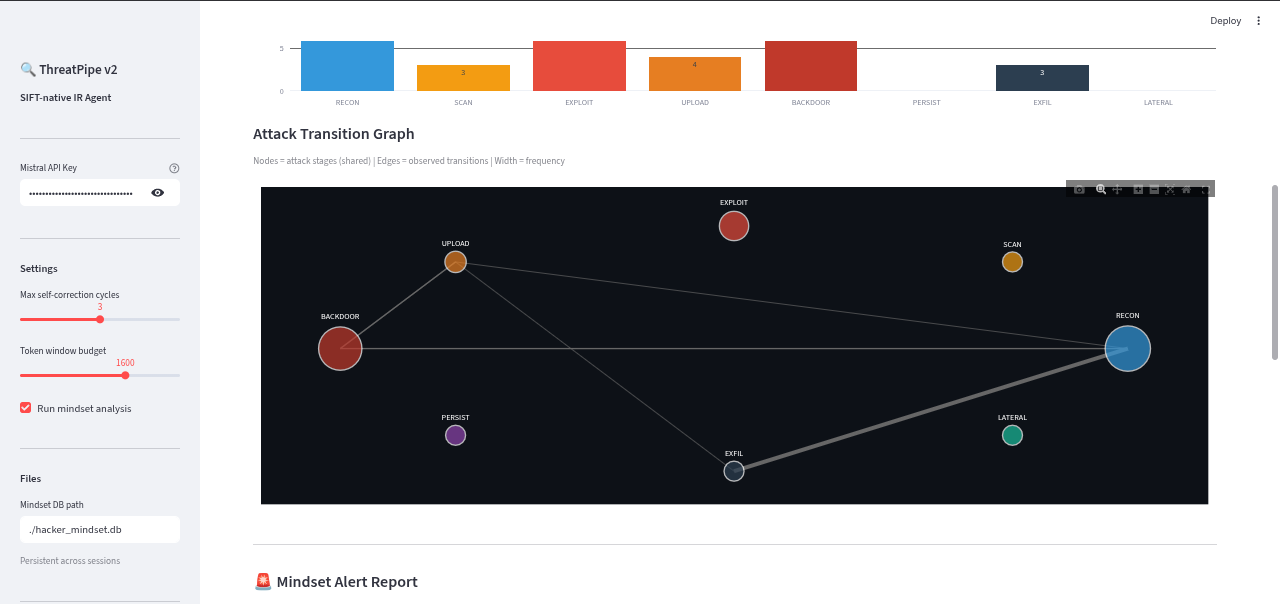
Graphical attack scenarios.
-
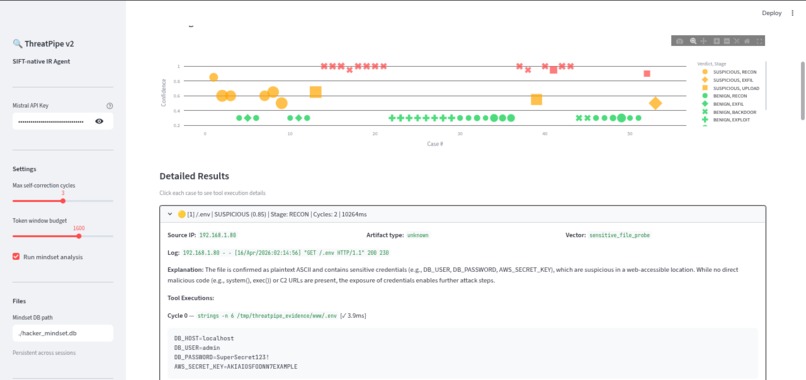
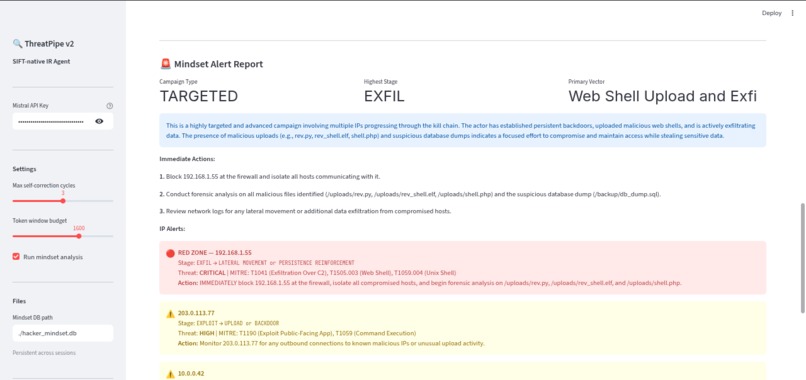
Attack type with description of logs, verdict, reason path .
-
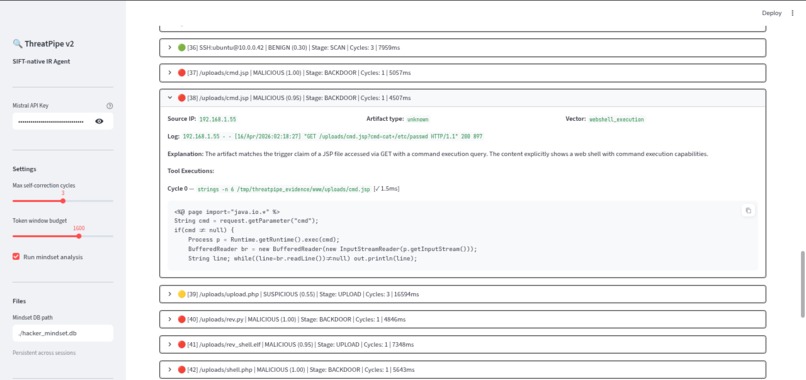
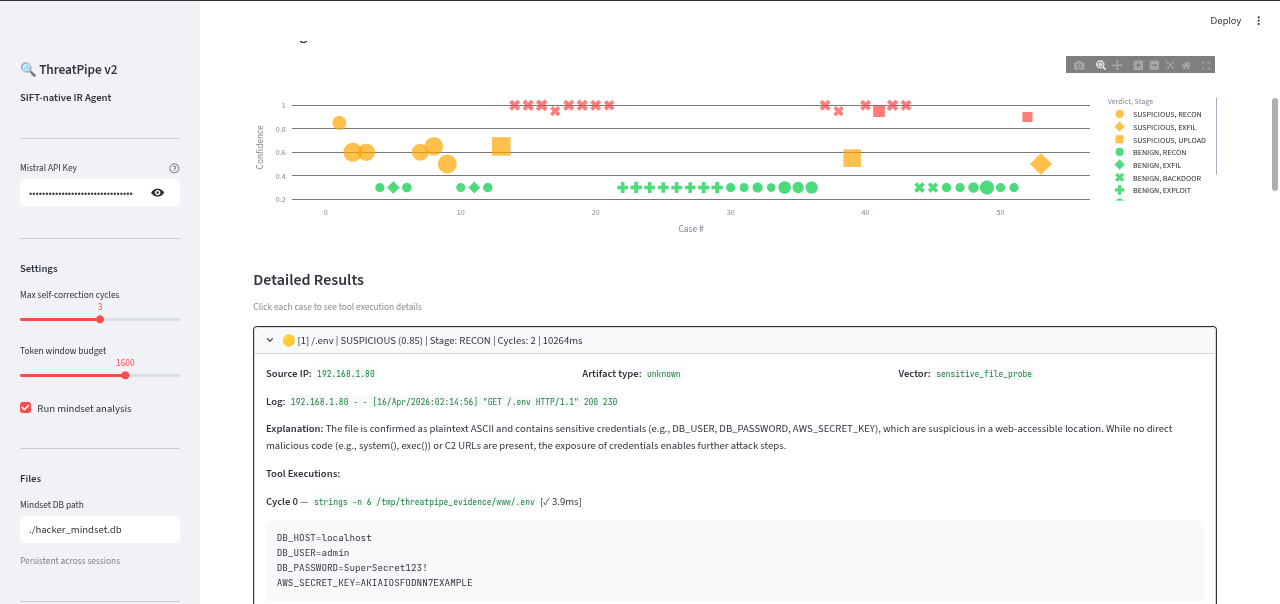
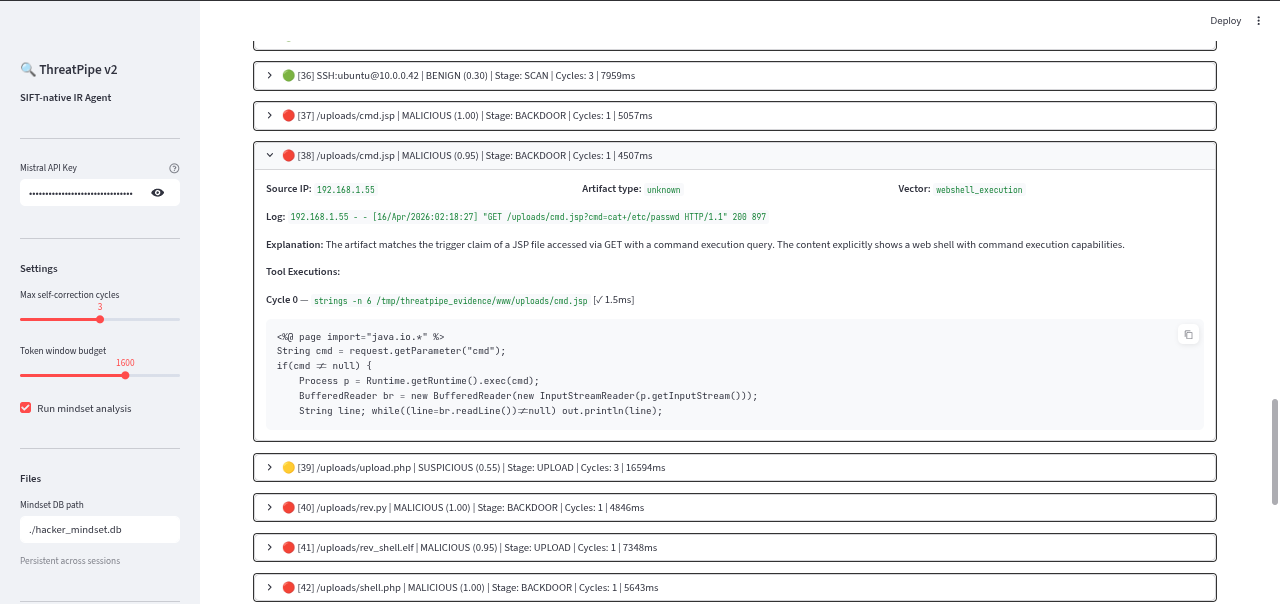
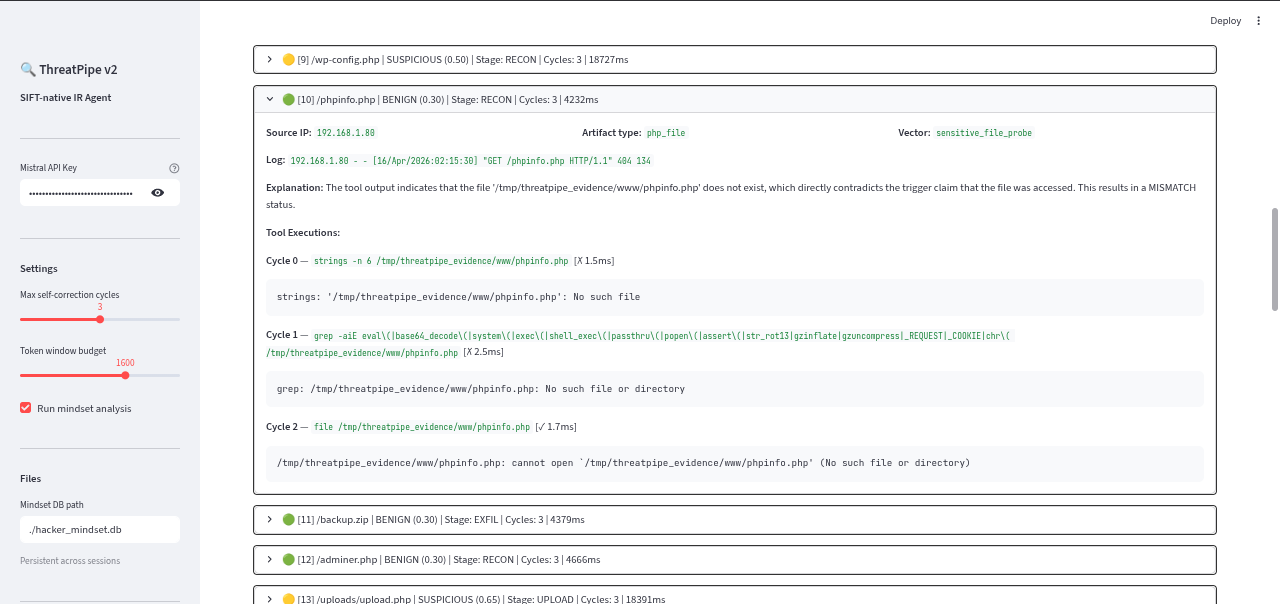
All logs details
-
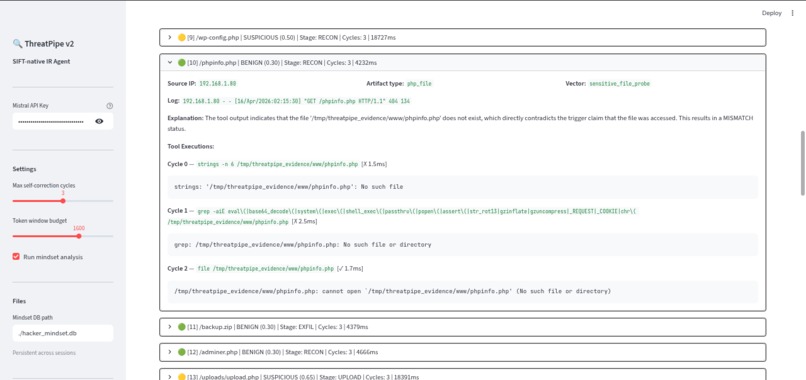
all logs details
-
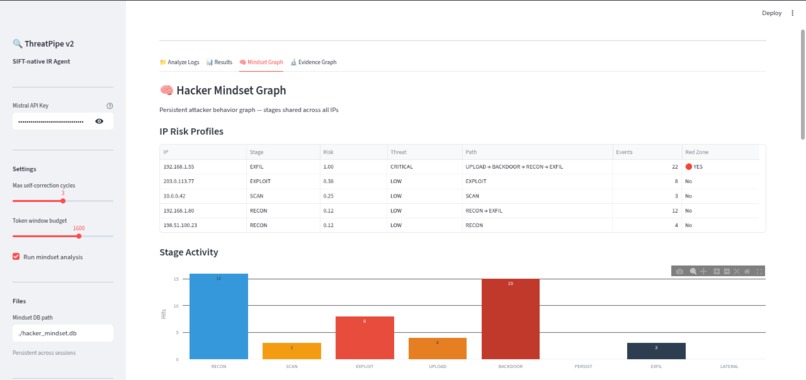
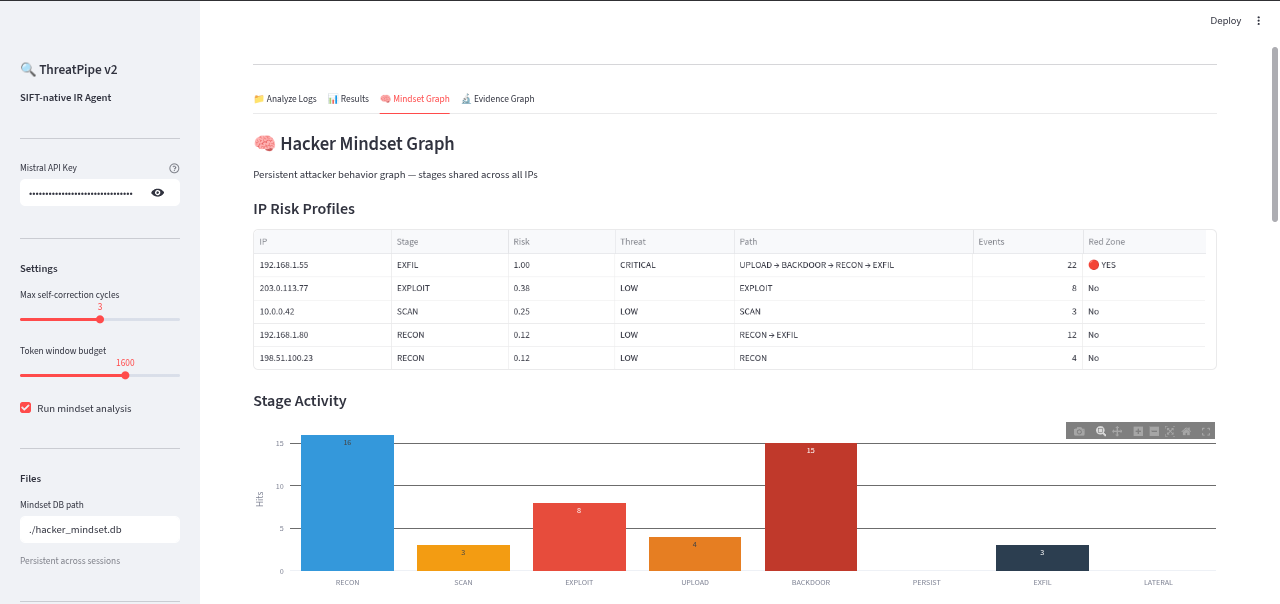
Hacker mindset graph classificatoin
-
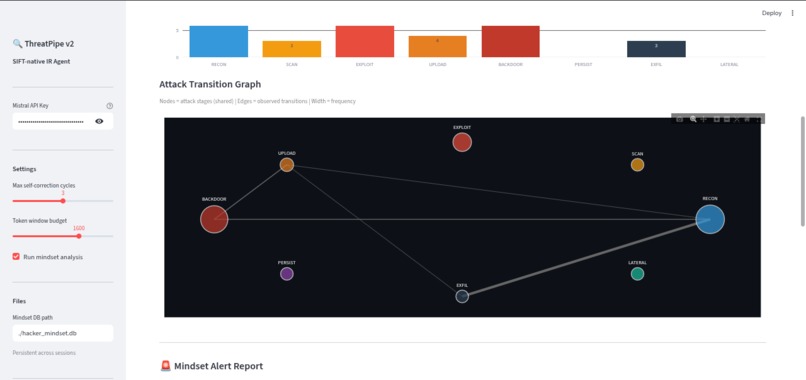
visual Hacker mindset graph
-
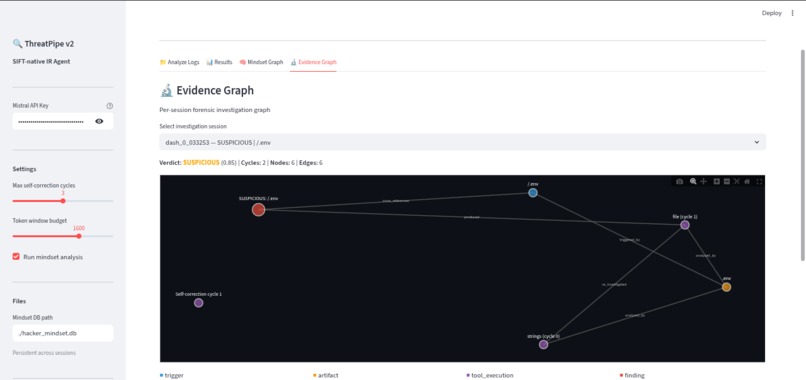
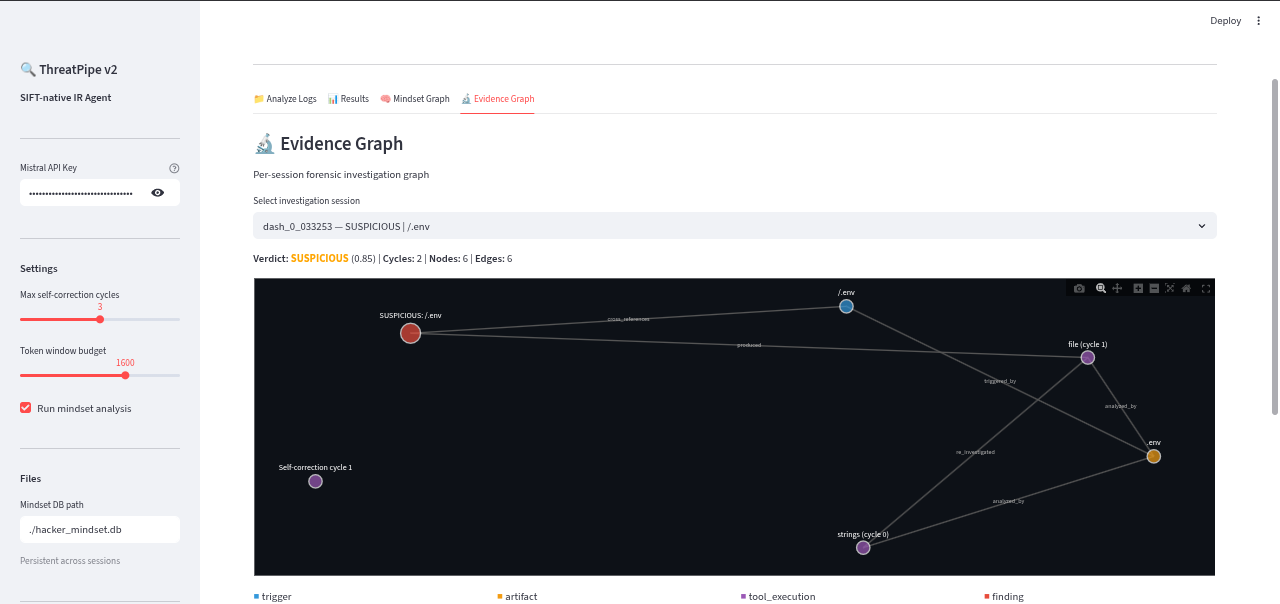
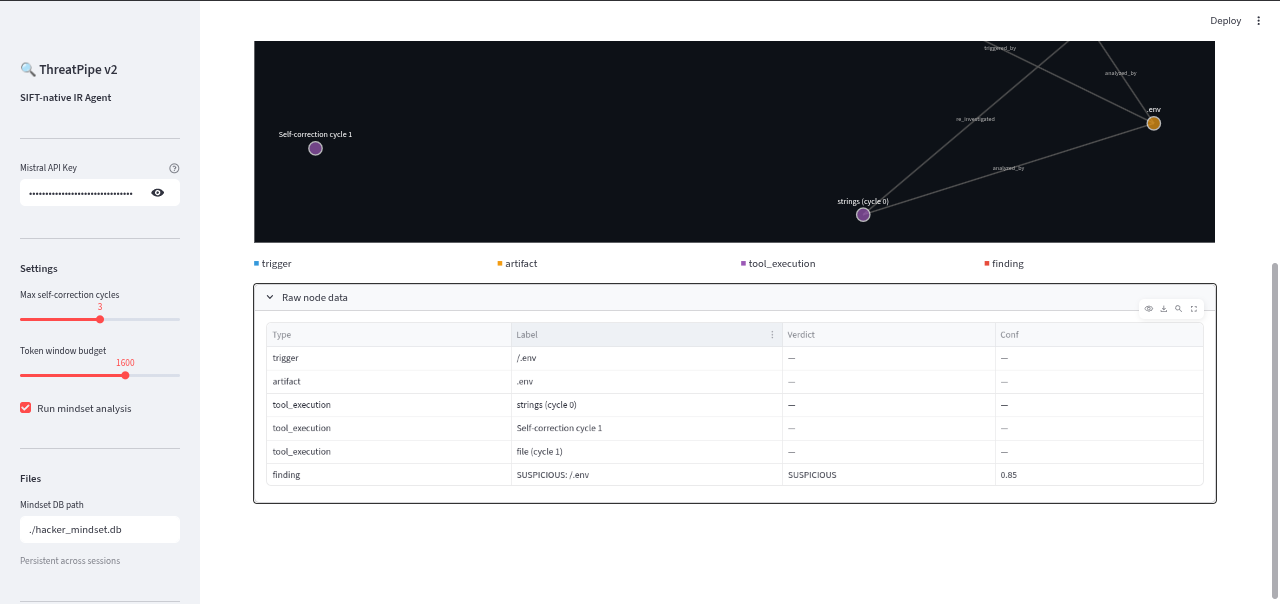
Evidence graph
-
Evidence graph visuls
-
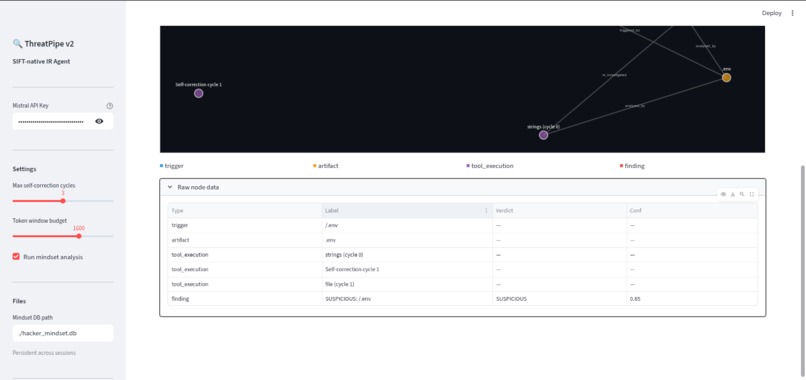
Evidence graph logs(actual evidence)
Inspiration
The inspiration for ThreatPipe v2 came directly from the terrifying math of modern cyber attacks. CrowdStrike's fastest observed breakout time is 7 minutes. Horizon3's autonomous agent goes from initial access to full privilege escalation in 60 seconds. AI-driven attack workflows are running 47 times faster than human operators. Meanwhile, a human incident responder at 3 AM is still pulling up their toolkit and looking up command-line flags. That gap—the gap between machine-speed attacks and human-speed defense—is the most dangerous problem in cybersecurity. We built ThreatPipe to close it. We didn't want to build another chatbot that suggests commands; we wanted to build an autonomous digital analyst that actually executes the forensic workflow safely, at machine speed, without hallucinating or destroying evidence.
What it does
ThreatPipe v2 is an autonomous incident response agent that takes raw security logs and turns them into actionable threat intelligence with zero human intervention. It operates in four stages:
- LLM Log Triage: It ingests messy, multi-format log files (Apache, SSH, FTP, MFT, memory dumps) and uses a sliding window LLM to instantly identify the suspicious needles in the haystack.
- Autonomous SIFT Investigation: For every suspicious log line, a LangGraph agent pipeline takes over. It parses the log, locates the artifact on disk, and executes real SIFT forensic tools (
strings,file,grep,fls) via a custom MCP server. - 4-Lens Cross-Referencing & Self-Correction: Instead of blindly trusting the first tool output, ThreatPipe forces the LLM to analyze the evidence through four distinct lenses: Hacker, Temporal, Kill Chain, and Analyst. If the evidence is ambiguous or confidence is low, the agent self-corrects—looping back to run an alternate SIFT tool until it reaches a verifiable conclusion or hits a safety cap.
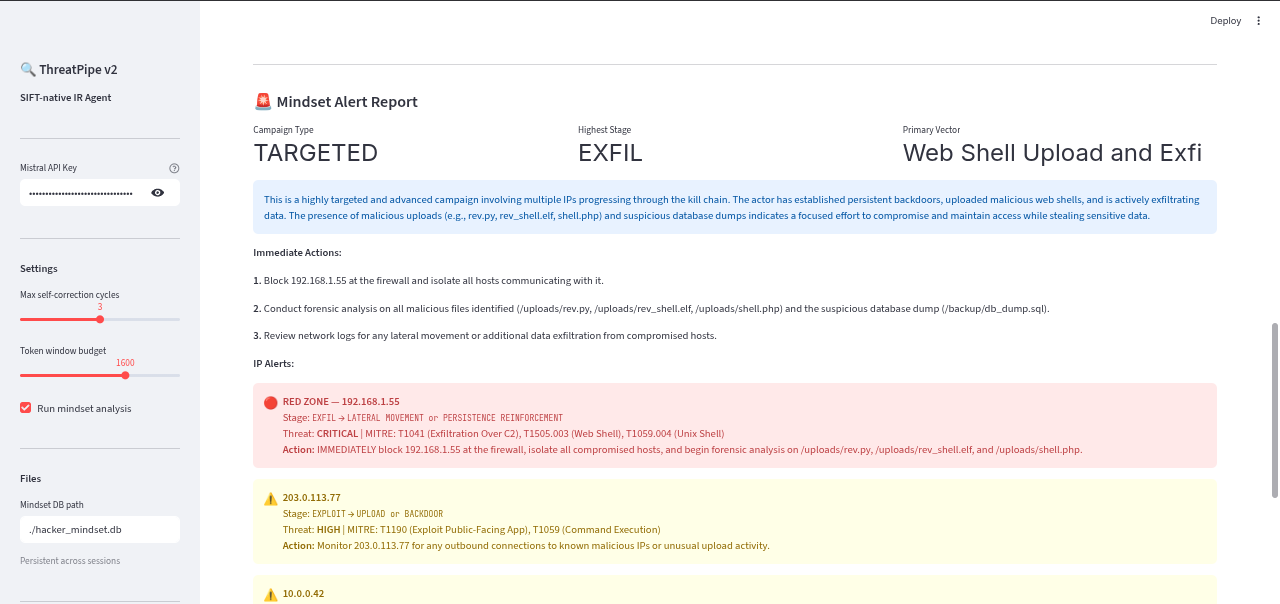
- Persistent Attacker Tracking: Verdicts are mapped to MITRE ATT&CK stages and fed into a persistent "Hacker Mindset Graph." This tracks attacker IPs across sessions, calculates risk scores, predicts their next move, and generates prioritized SOC alerts.
How we built it
We built ThreatPipe using a Multi-Agent Framework approach (LangGraph) orchestrated with a Custom MCP Server for secure tool execution.
- LangGraph State Machine: The core of Stage 2 is a 5-node directed graph:
Parse Trigger→Locate Artifact→Execute Tool→Cross Reference→Confirm Verdict. A conditional edge evaluates the LLM's confidence and loops back toExecute Toolwithcycle+1if the result is aMISMATCHorAMBIGUOUS, creating a self-correcting loop capped at 3 cycles. - Custom MCP Tool Layer: This was our most critical architectural decision. Instead of giving the LLM an open shell (
execute_shell_cmd), we built an MCP server with a strict tool allowlist. The agent can only call read-only forensic tools. Destructive commands likerm,dd, orshredare architecturally blocked. Furthermore, the MCP server automatically truncates tool output to 5KB before returning it to the LLM, preventing context window crashes during deep investigations. - Deterministic vs. LLM Split: We learned quickly that LLMs hallucinate tool flags. So, we made tool selection 100% deterministic via
tool_selector.pybased on artifact type, and stage classification deterministic viastage_classifier.py. The LLM is only used where it adds value: triage, multi-perspective reasoning, and campaign synthesis. - Dual Graph Architecture: We use an
EvidenceGraph(SQLite/NetworkX) for per-session chain of custody, ensuring every finding links back to the tool output that produced it. We also built aHackerMindsetGraphthat persists across sessions, tracking IP addresses as they progress fromRECONtoEXPLOITtoEXFIL. - Tech Stack: Python, LangGraph, Mistral Small (via LangChain), FastAPI (MCP Server), Streamlit (Dashboard), NetworkX, and SQLite.
Challenges we ran into
- LLM Hallucinations in Tool Execution: Early versions allowed the LLM to choose tools and construct arguments. It routinely invented non-existent flags or tried to call tools that didn't exist. We solved this by removing the LLM from tool selection entirely and relying on a deterministic rule map.
- Context Window Overload: SIFT tools like
stringscan easily dump megabytes of text from a binary, which instantly crashes the LLM's context window. We solved this by routing all tool executions through our MCP server, which enforces a hard 5KB truncation limit before the output ever reaches the agent. - Inconsistent Forensic Verdicts: An LLM might correctly flag a PHP web shell as
MALICIOUSon cycle 1, but if the self-correction loop runs, it might change its mind toBENIGNon cycle 2 due to token probability variance. We mitigated this with strict 4-lens prompt engineering and deterministic "fast-path" rules for obvious indicators (likesystem($_GET['cmd'])). - Evidence Spoliation Risks: How do we prove to a SOC team that the AI won't delete the evidence it's analyzing? Prompting "Do not delete files" isn't enough. We had to shift to architectural enforcement—building the MCP allowlist so the agent physically cannot execute write operations.
Accomplishments that we're proud of
- Zero Evidence Spoliation Risk: Our MCP server's architectural guardrails make it physically impossible for the agent to alter or delete the evidence it is analyzing. A judge can verify this by looking at our tool allowlist.
- The Self-Correction Loop Actually Works: Watching the agent say "MISMATCH, low confidence, retrying with
fileinstead ofstrings" and then successfully identifying a polyglot image on the second cycle is incredibly satisfying. It mimics the behavior of a senior analyst pivoting their investigation. - The Hacker Mindset Graph: Incident response shouldn't happen in a vacuum. By tracking attacker progression across sessions and predicting next moves, ThreatPipe acts not just as a forensic analyzer, but as a strategic threat intelligence tool.
- Cost Efficiency: By using Mistral Small only where necessary and relying on deterministic code for the rest, investigating 20 suspicious logs costs less than $0.05.
What we learned
- Architectural Guardrails > Prompt Guardrails: Telling an AI "do not run destructive commands" is a suggestion; removing
rmfrom the tool allowlist is a law. In cybersecurity tools, trust must be enforced by code, not prompts. - LLMs are Thinkers, not Doers: LLMs are excellent at reasoning about tool output, but terrible at choosing exact command-line flags. Separating the "thinking" (LLM cross-referencing) from the "doing" (deterministic Python tool selection) is the secret to reliable agentic AI in DFIR.
- Context is Everything: Garbage in, garbage out. If you feed an LLM 50KB of raw
stringsoutput, it will hallucinate. Truncating and structuring data in the MCP layer before it hits the LLM is mandatory for accurate forensic reasoning.
What's next for ThreatPipe v2: Autonomous SIFT IR Agent with MCP
- Deep Protocol SIFT Integration: We want to connect ThreatPipe's agent loop directly to the official Protocol SIFT MCP server for deep-dive disk image and memory capture analysis (Volatility 3, Plaso/Log2Timeline).
- Multi-Agent Parallelism: Decomposing the architecture so one agent handles disk forensics while another handles network captures, merging their findings to cross-reference disk timelines with network beacon traffic.
- Real-Time Ingestion: Swapping the static file upload for a live syslog/Zeek stream connector, allowing ThreatPipe to act as a real-time autonomous triage engine monitoring infrastructure as attacks happen.
Built With
- fastapi
- langraph
- python
- streamlit

Log in or sign up for Devpost to join the conversation.