-
-
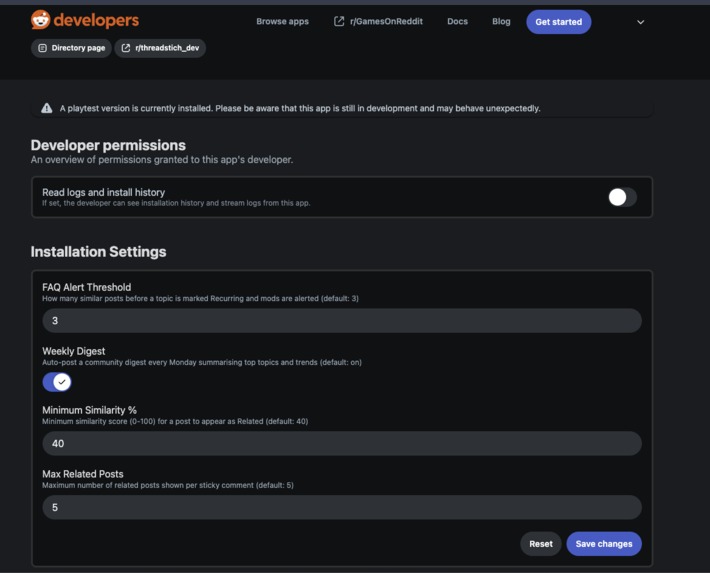
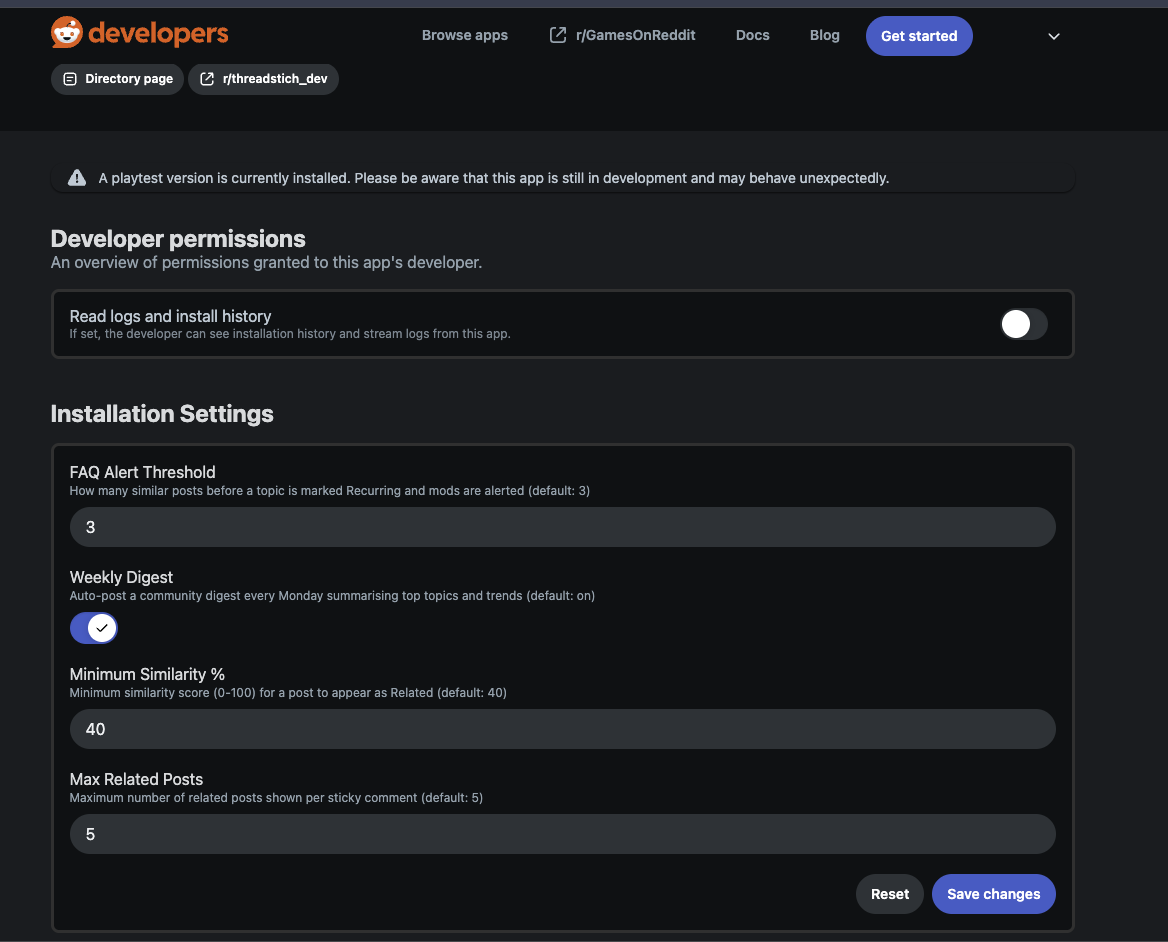
Settings Dashboard
-
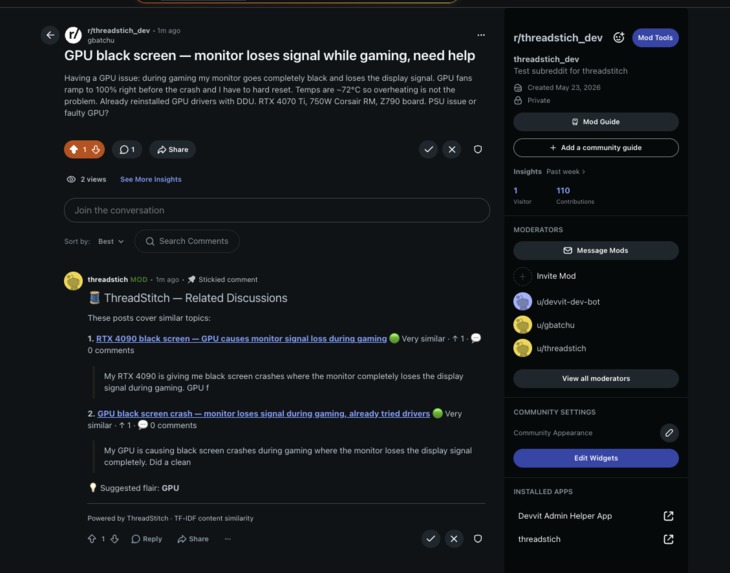
Instance of Related Discussion Auto-Comment
-
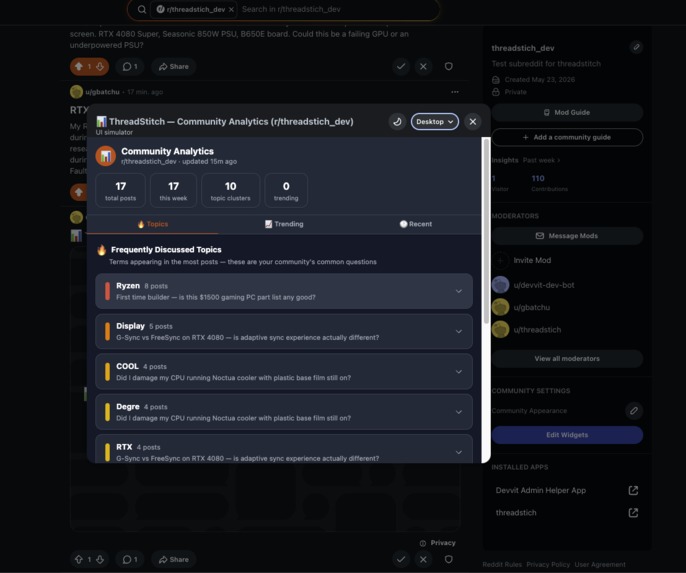
Mod Dashboard - Used to create mega-threads instantaneously
The Problem Every active subreddit has the same invisible tax: moderators answering the same question for the hundredth time. "What GPU should I buy?" "Why does my game keep crashing?" "Is this deal worth it?" — asked fresh every week by new community members who had no way to know the answer was already buried three pages back.
The existing tools don't help. Reddit's native search requires users to think to use it. AutoModerator catches keyword patterns but can't understand meaning. The result: mods copy-paste the same wiki link dozens of times a month, FAQ floods arrive with no warning, and the institutional knowledge of a community stays invisible to the people who need it most.
ThreadStitch fixes this automatically, at post submission time, with zero moderator effort.
How It Works When any post is submitted, ThreadStitch fires an onPostSubmit trigger and runs the title and body through a custom TF-IDF vectorization pipeline — entirely in TypeScript with no external NLP dependencies. Each post becomes a sparse weighted vector of its most distinctive terms, stored in Redis as a hash.
Finding similar posts doesn't mean scanning every previous post. ThreadStitch maintains an inverted index in Redis sorted sets — one per subreddit term — so candidate retrieval is O(k · log n) regardless of subreddit size. Candidate vectors are then scored by cosine similarity, and the final ranking blends four signals:
[ \text{score} = 0.45 \cdot \text{similarity} + 0.25 \cdot \text{clicks} + 0.20 \cdot e^{-\text{age}/30} + 0.10 \cdot \frac{\ln(1 + s + 2c)}{10} ]
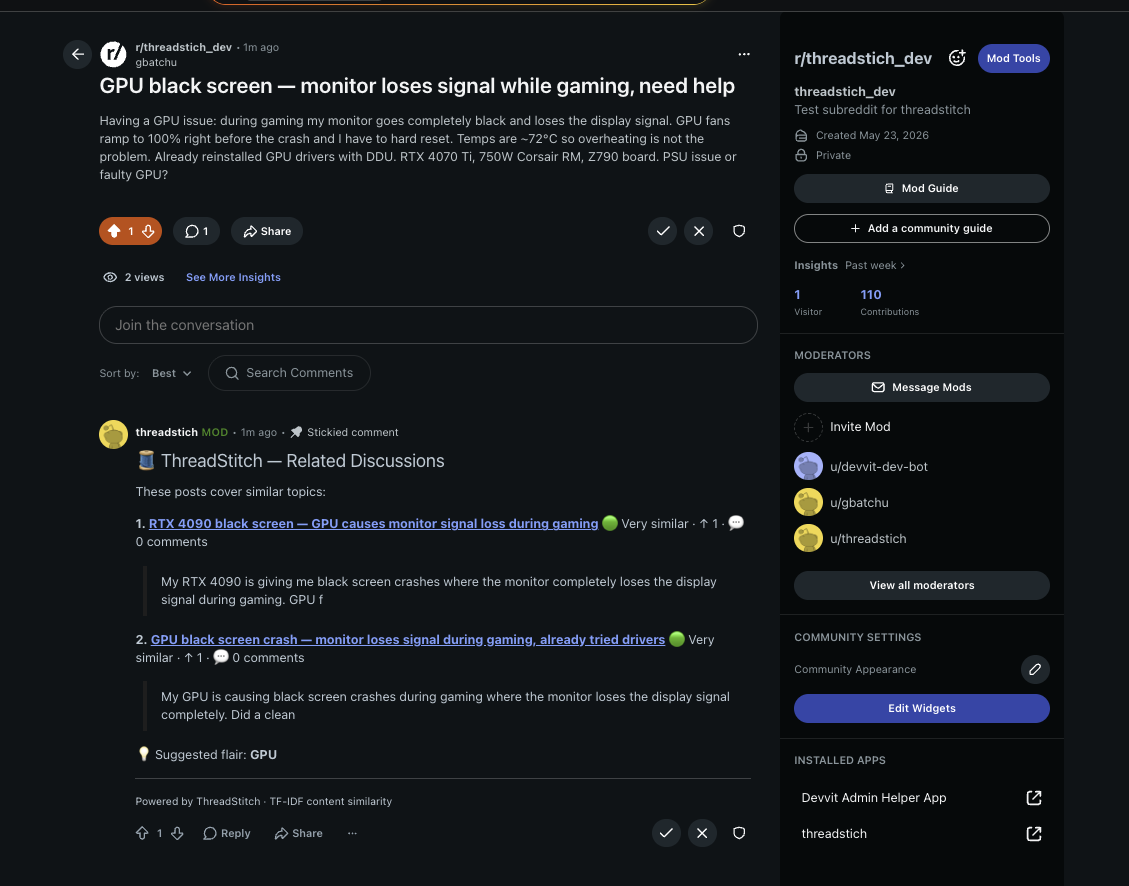
The result: a pinned sticky comment on every new post linking the most relevant past discussions, with similarity badges (🟢 Very similar / 🟡 Similar / 🟠 Related), scores, comment counts, and a suggested flair label derived from the highest-weighted non-generic term in the post's vector.
When a topic has appeared three or more times (configurable), the comment heading switches to 🔁 Recurring Topic and the mod team receives a mod mail alert — once per topic — with links to the cluster and a prompt to create a pinned megathread in one click.
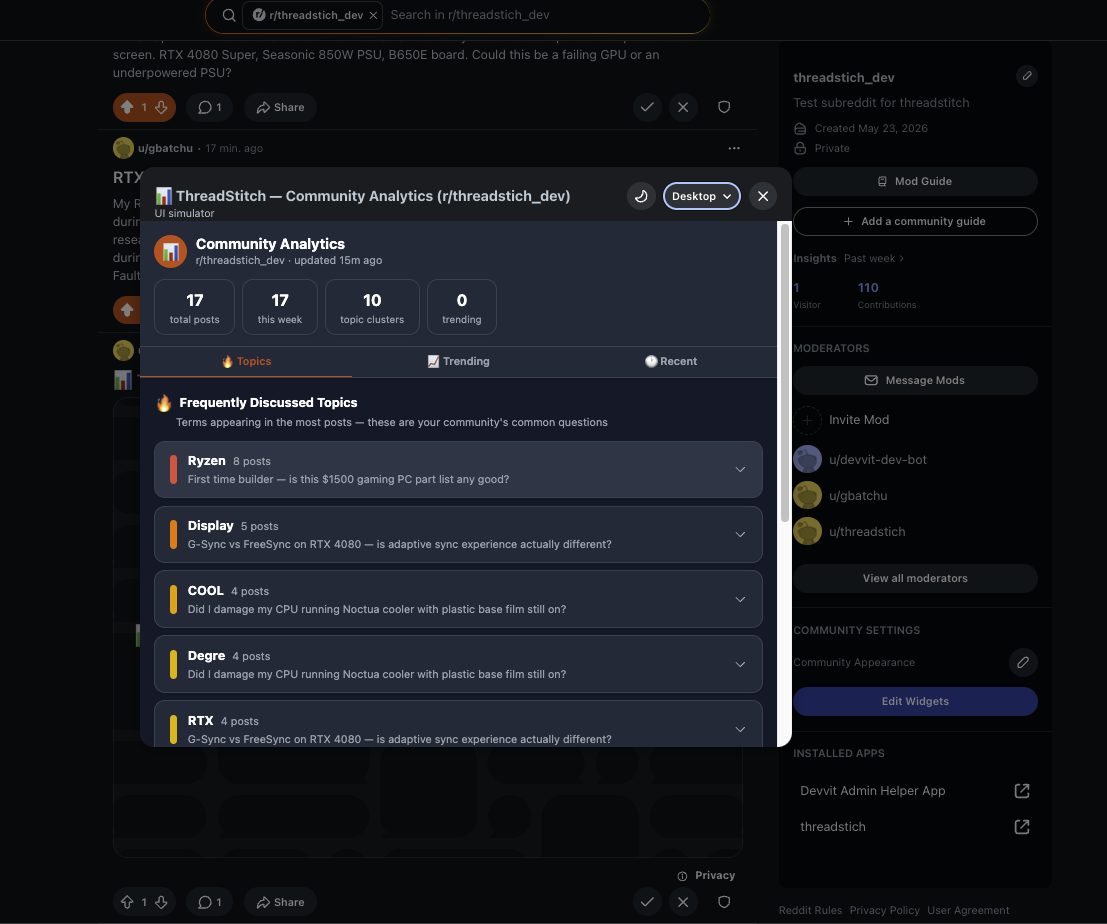
What Mods Get Mod Dashboard (mod menu → Open Mod Dashboard) — a pinnable custom post with three tabs:
🔥 Topics — top 10 term clusters by post count, expandable to representative posts, each with a 📌 Create Megathread button that generates a pre-populated pinned self-post in one click 📈 Trending — terms whose recent post rate exceeds the 7-day baseline by ≥ 1.3×, with growth multiplier badges and a clickable chip cloud 🕐 Recent — the last 10 indexed posts App Settings — four configurable knobs per subreddit: FAQ alert threshold, minimum similarity %, max related posts shown, and a weekly digest toggle.
Weekly Digest — every Monday at 09:00 UTC, ThreadStitch auto-posts a community summary with top topics, trending terms, and post volume. No effort required.
onPostDelete cleanup — when a post is deleted, its metadata, vector, cached results, click data, and every inverted index entry are removed immediately so future comments never surface dead links.
Challenges Devvit's Redis is a gRPC-backed cloud service, not a local instance. There's no SCAN or KEYS command, no external access, and score-based range queries with +inf/-inf return empty instead of erroring. Every analytics query had to be redesigned around rank-based ZSET reads and pre-maintained post ID sets. The inverted index architecture emerged directly from this constraint.
The t3_ prefix problem. The onPostSubmit PostV2 event sends post.id with the t3_ prefix already attached — unlike most other contexts. Stripping it for storage keys and re-adding it only for submitComment took careful handling to avoid broken links in bot comments.
Making the bot useful before the index has depth. On a brand-new subreddit, TF-IDF finds nothing. ThreadStitch falls back to Reddit's hot posts, filters out Devvit custom posts (which have "not supported on old Reddit" in their body), and shows a 🧵 Other Recent Posts header instead — so the sticky comment always has value, even on day one.
Zero external NLP, actually. Early builds pulled in compromise, natural, and stopword. Getting to true zero-dep NLP — a Porter-like stemmer, a 60-term stopword set, smooth IDF, and a blocklist for generic terms — took real iteration to make similarity results feel meaningful rather than matching on filler words.
Built With
- devvit
- hono
- node.js
- react
- redis
- tailwind
- typescript
- vite

Log in or sign up for Devpost to join the conversation.