-
-
Condense entire sessions into one shareable context card—locally, instantly, with your own key.
-
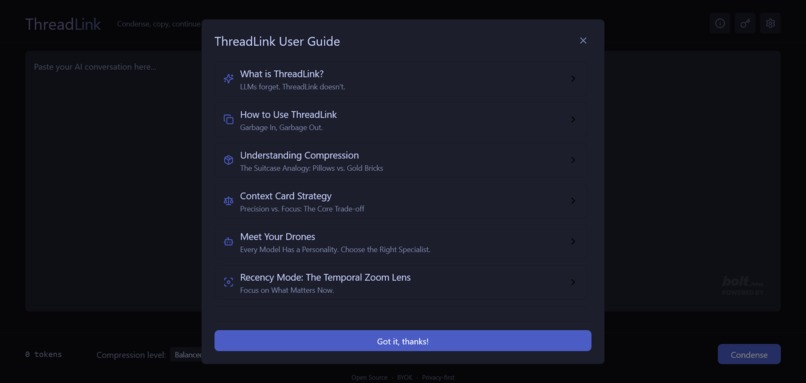
No fluff. Just clear steps for importing, condensing, and continuing where you left off.
-
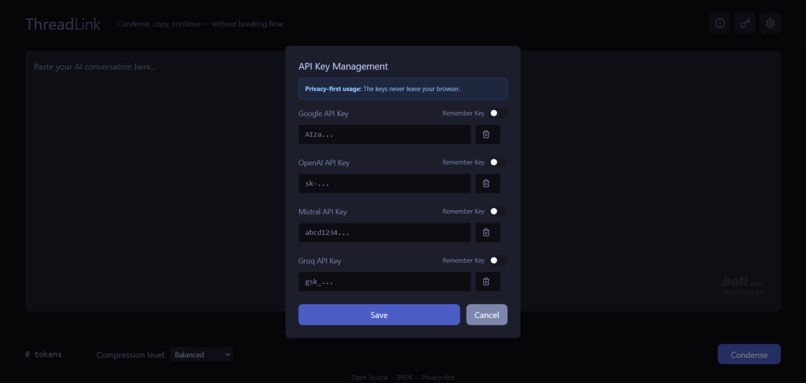
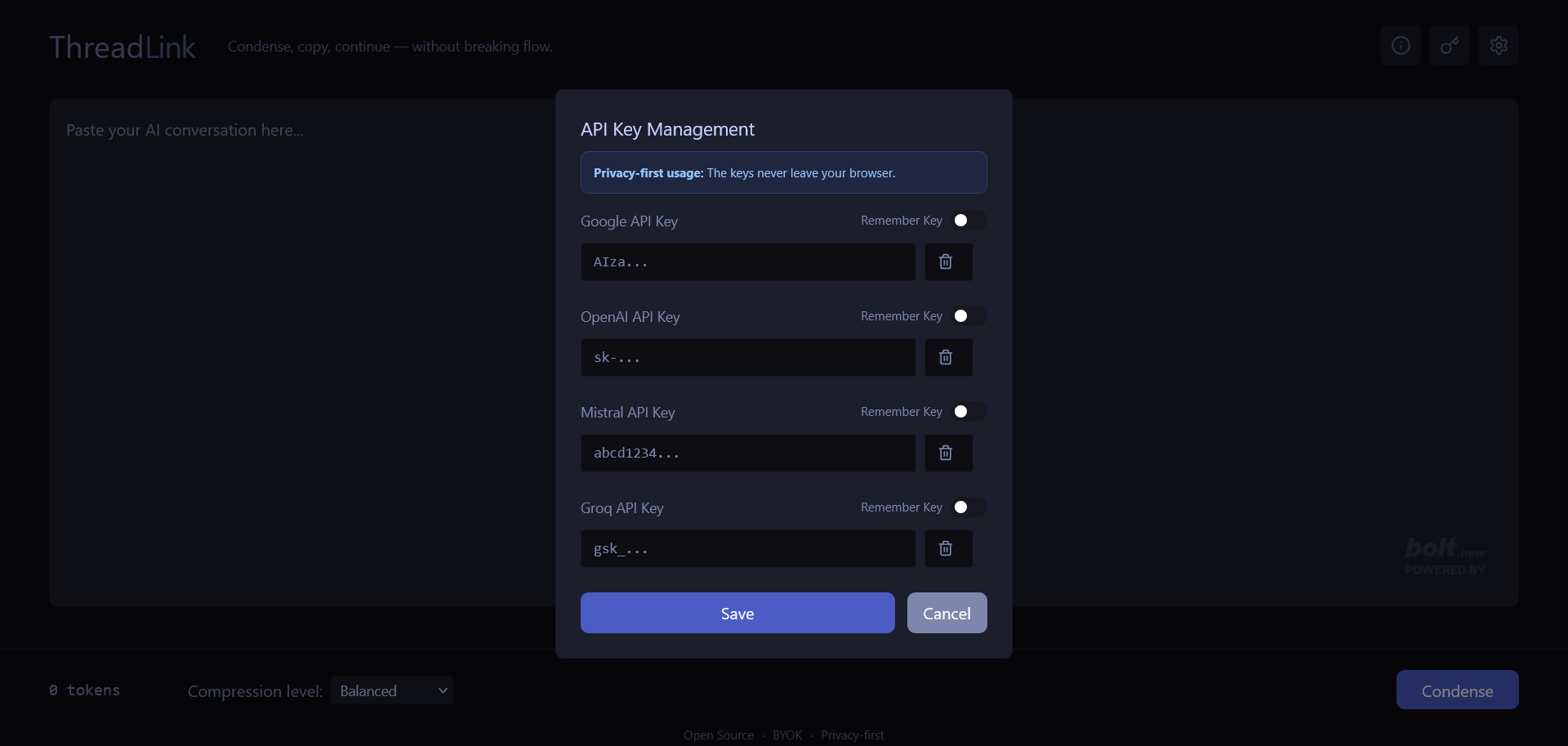
Bring your own key. We never touch it—your models, your memory, your rules.
-
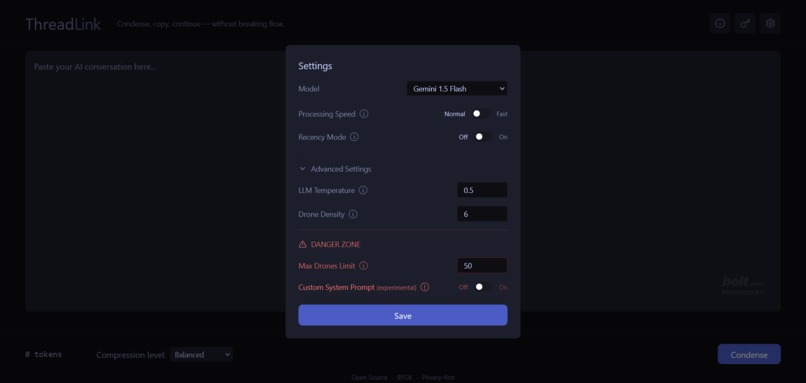
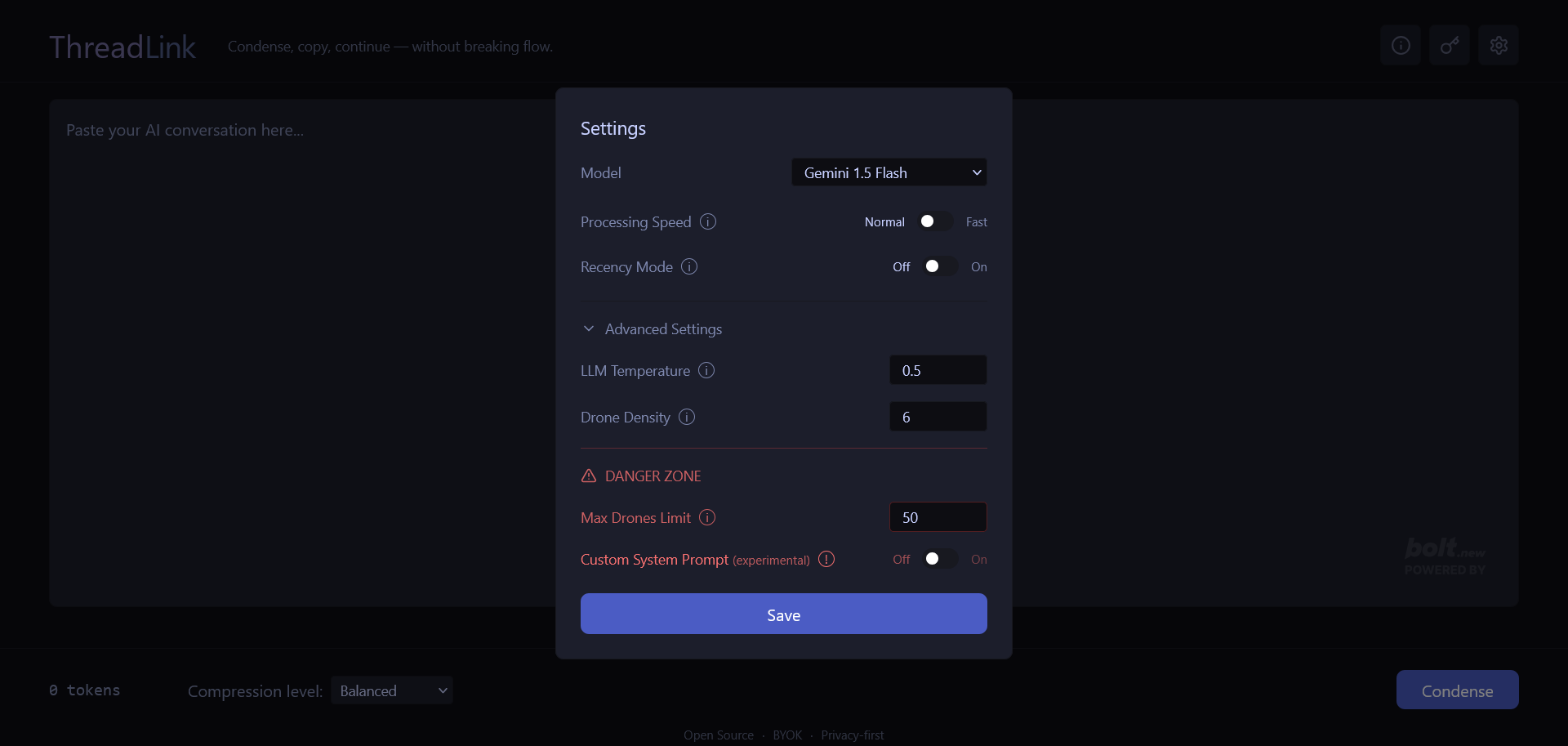
Tune how Threadlink thinks: speed level, recency bias, drone density, and model choice.
Inspiration
LLMs forget. Every new chat, every platform switch—it’s like talking to someone with amnesia. We built Threadlink out of that frustration: a lightweight, local-first memory layer that lets you carry the context. No repetition. No leaks. Just seamless continuity across sessions and tools—because your history shouldn’t reset every time the screen does.
What it does
ThreadLink is a client-side web app that transforms long, chaotic AI conversations into dense, portable context cards. Users paste in a raw transcript, and the tool uses a parallel "drone" pipeline to summarize the entire session using the user's own API key. The resulting context card can be used to kickstart a new session on any platform, instantly restoring the AI's memory. Can also be used to refresh a ongoing sessions memory.
How we built it
We built it on a 100% client-side, serverless architecture using React, TypeScript, and Vite to guarantee absolute user privacy—no data ever touches our servers. The UI was built using bolt.new and the more complex logic was built using cursor.
The core of the application is a custom-built, multi-stage processing pipeline that handles semantic chunking, parallel batching, and resilient orchestration of API calls to multiple providers (OpenAI, Google, Mistral, Groq). All of this complex logic runs entirely in the browser.
Challenges we ran into
The primary challenge was architectural: building a truly provider-agnostic system that could handle the inconsistent rate limits, error messages, and security filters of different LLMs. This forced us to design a fault-tolerant orchestrator that can gracefully handle partial failures—like a single drone being rate-limited or rejecting a piece of content—without crashing the entire process. Debugging these real-world API inconsistencies was the most significant challenge.
Accomplishments that we're proud of
We are most proud of the performance and resilience. The final pipeline, especially when paired with Groq's LPU inference engine, can process over 250,000 tokens of text and return a complete summary in under 20 seconds. We're also proud of achieving this within a purely client-side architecture, proving that powerful, privacy-first AI tools are not only possible but highly effective.
What we learned
You don’t need to cram a massive prompt into a single LLM. Threadlink taught us that swarms of lightweight models, running in parallel with focused roles, can outperform brute force. It’s faster, cheaper, and more controllable. Building this made it clear: decentralizing the task isn’t just more efficient—it’s the future of working with AI.
What's next for ThreadLink
Threadlink is feature-complete as a focused, single-shot utility. The core goal was never to bloat it—it was to solve one problem cleanly. Going forward, we’ll maintain compatibility with the fastest, cheapest, and smartest models available.
Built With
- bolt
- gemini
- groq
- minstral
- netlify
- openai
- playwright
- react
- tailwind
- typescript
- vite

Log in or sign up for Devpost to join the conversation.