-
-

-
-
-
https://youtu.be/cW-q2XHA3Ng
-

Inspiration
Large language models are powerful, but they still struggle to understand webpages in the way humans do.
When reading complex discussions on sites like Hacker News or Reddit, users naturally follow nested replies, track relationships between comments, and move across pages to understand context. However, when an AI agent receives the same page, it usually only sees flattened DOM text. Much of the page’s relational structure is lost.
This highlighted a practical limitation: when webpage structure is flattened into raw text, the model loses much of the page’s relational context.
We started wondering whether an agent could work better if it received a structured representation of the current page instead of raw DOM text.
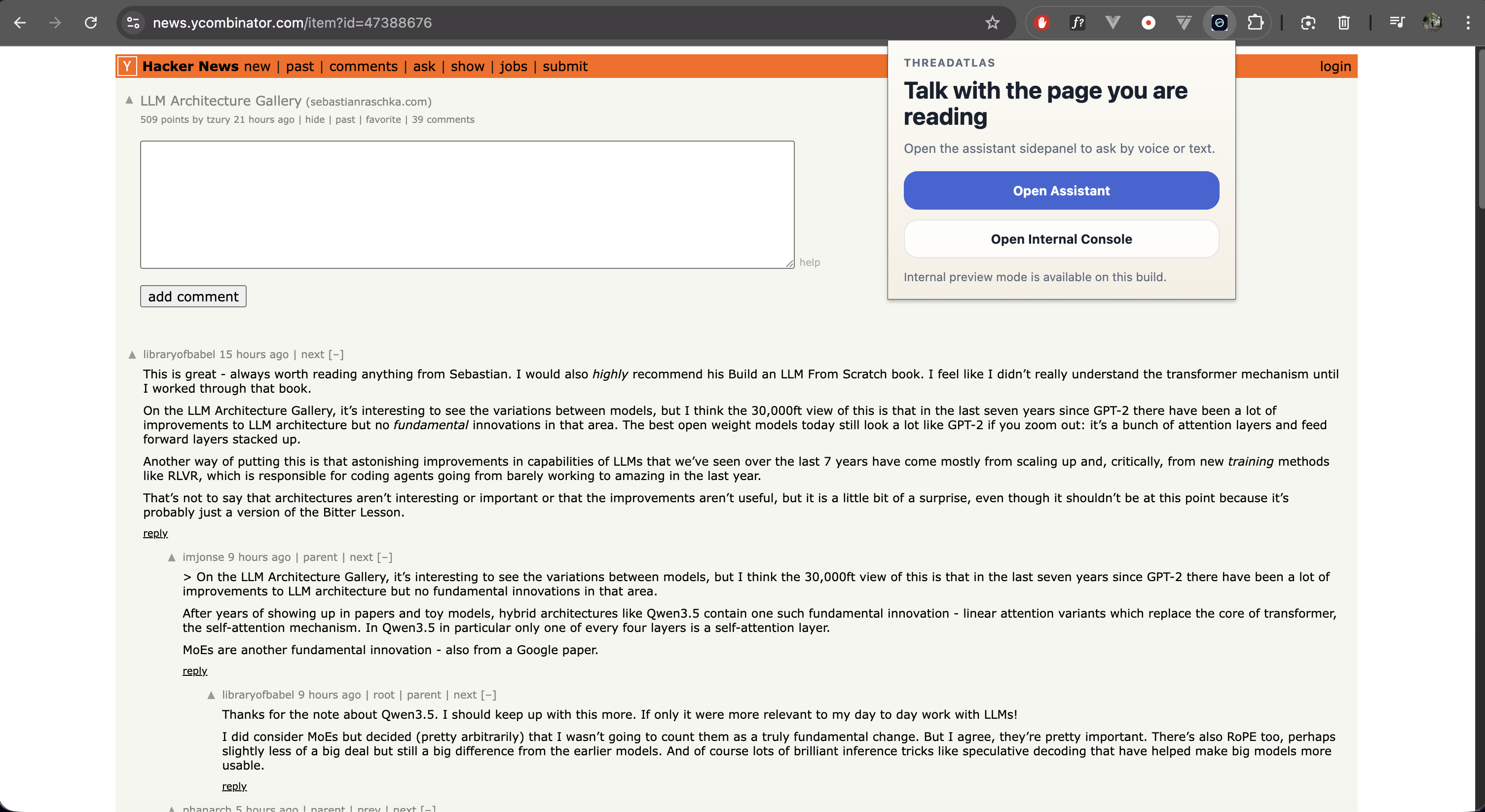
ThreadAtlas was built to explore that idea — allowing an AI agent to reason about the current webpage with better grounding and interaction.
What it does
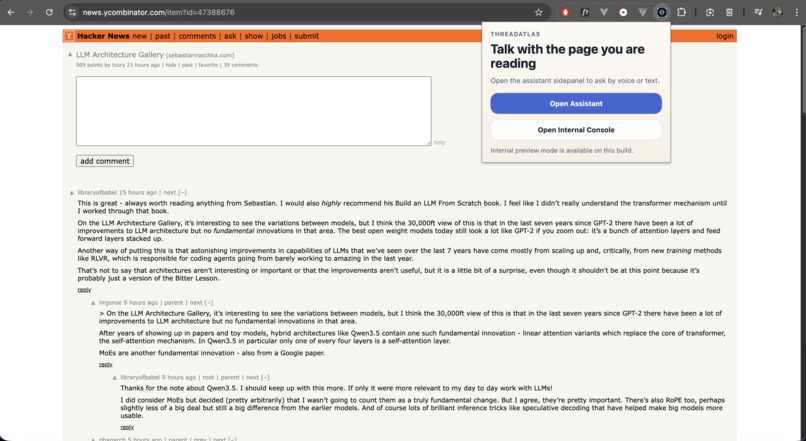
ThreadAtlas is a browser-based AI agent that captures a semantic snapshot of the current webpage so a language model can reason about the page with stronger grounding.
Instead of sending only raw DOM text, ThreadAtlas preserves meaningful page structure from the current tab. On threaded discussion pages, this can include comments, authors, reply structure, and relationships inside the page.
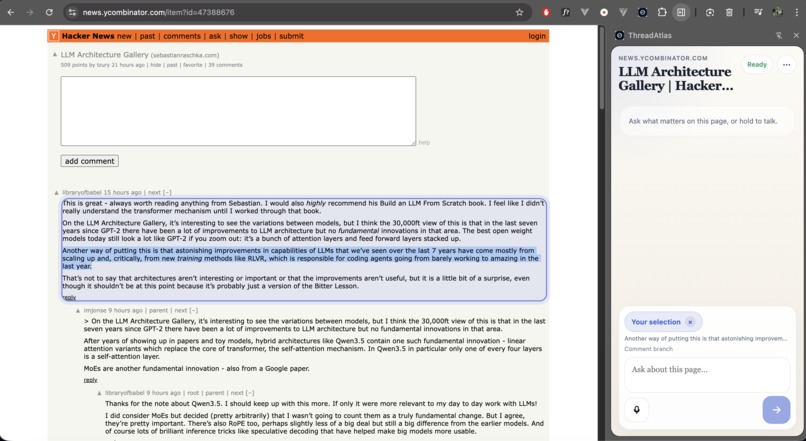
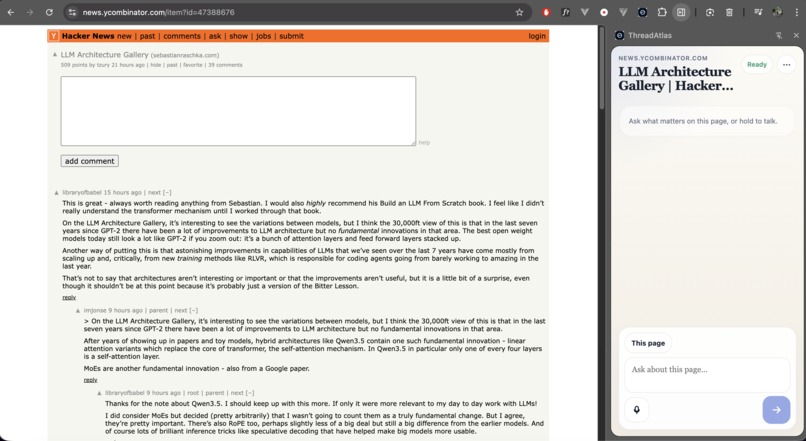
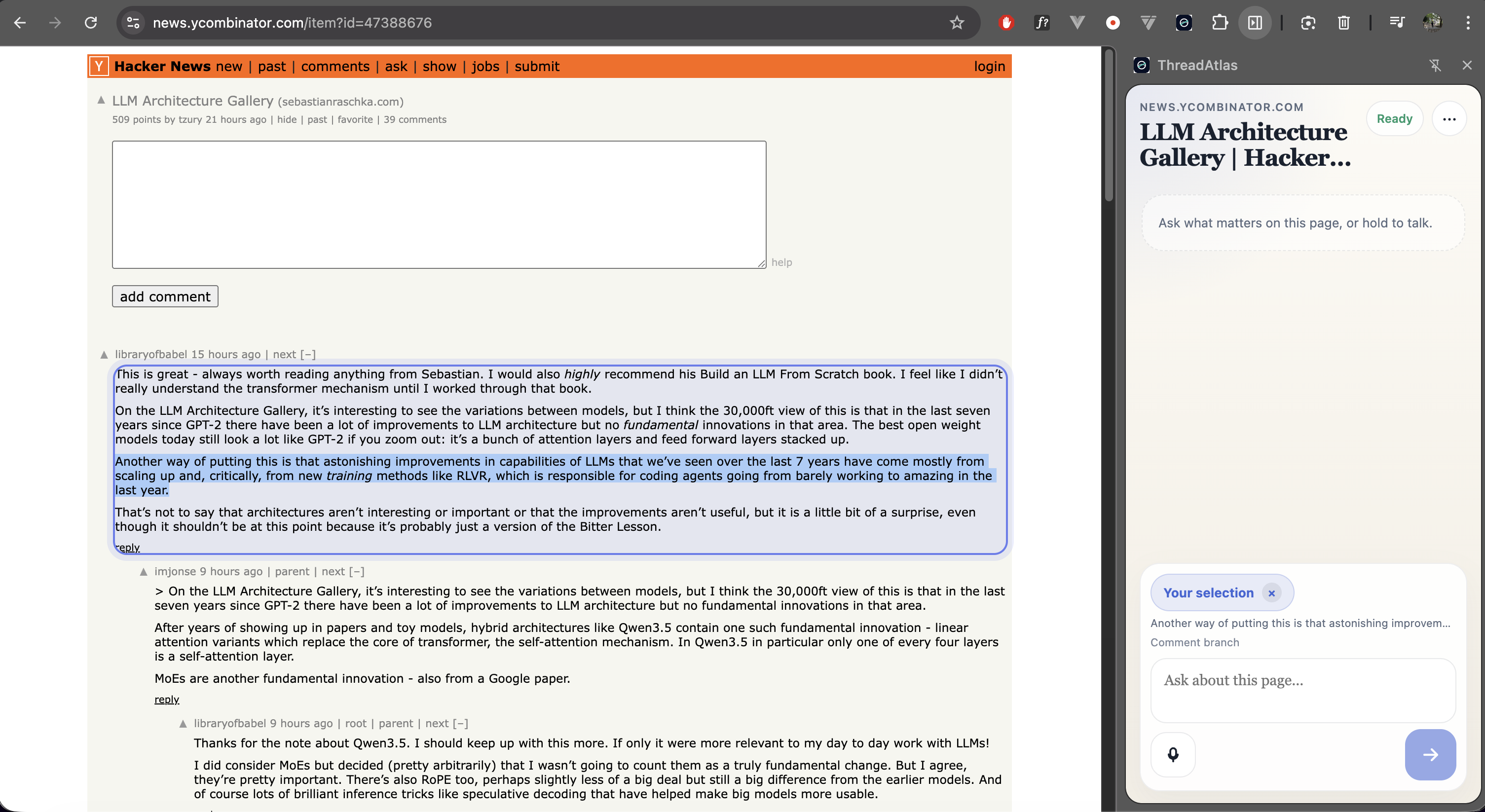
Users interact with the agent through a browser side panel. They can capture the current page, ask questions about it, and narrow the agent’s attention using semantic selection.
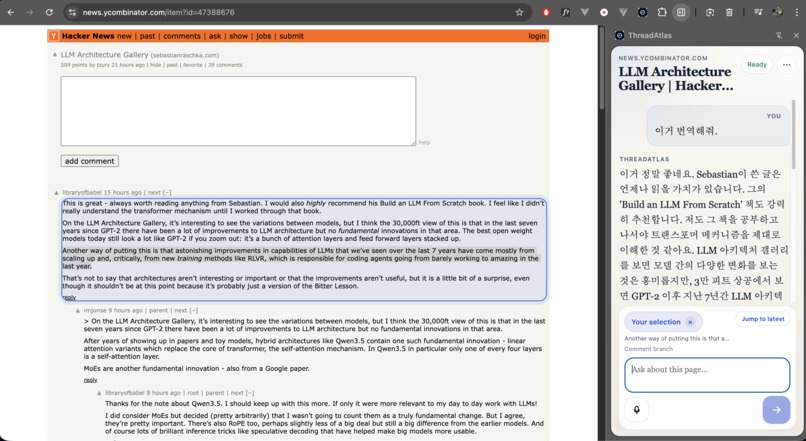
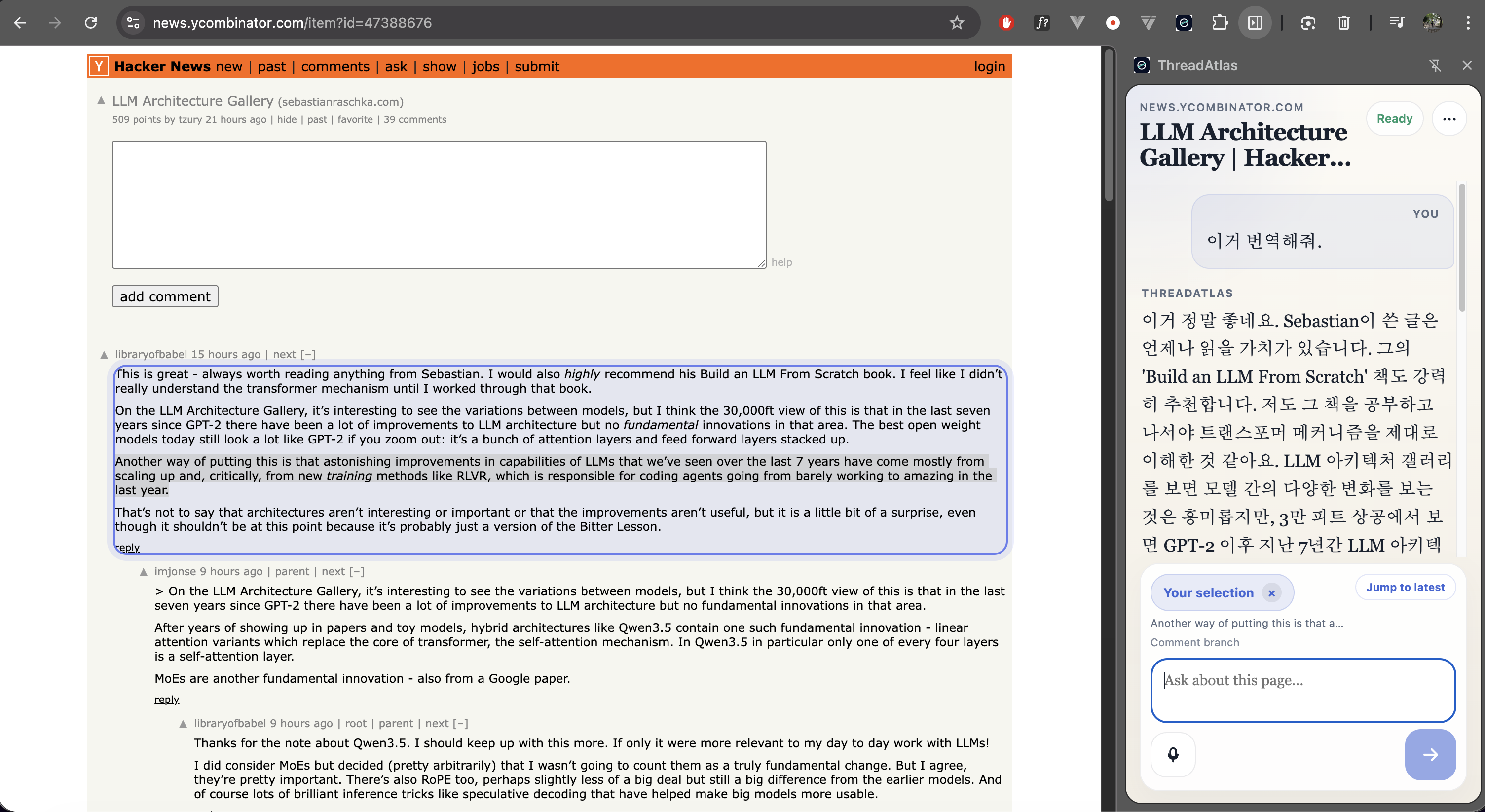
ThreadAtlas also supports live voice interaction, allowing users to speak naturally with the agent while it remains grounded in the current webpage context.
The result is an interaction where the user and the agent can discuss the same page while sharing a common view of the current content.
How we built it
ThreadAtlas consists of three main components.
Browser perception layer
A Chrome extension observes the current webpage and extracts a semantic snapshot from the DOM.
Instead of raw HTML, the extension attempts to preserve useful structural information from the page. On discussion pages this may include threads, comments, authors, and reply relationships.
Users can also activate semantic selection, allowing the agent’s reasoning to focus on a specific subtree of the page.
Agent runtime
A Node.js / Express backend manages the runtime session and tool orchestration.
During a turn, the backend can request additional browser-side evidence — such as screenshots or node-level details — when it needs more context to answer a question about the page.
Gemini Live integration
The agent uses Gemini through the Google GenAI SDK, including Gemini Live for real-time voice interaction.
The backend runs on Google Cloud Run, with Cloud SQL + pgvector used for storing session memory and Vertex AI embeddings used for retrieval.
Challenges we ran into
One major challenge was translating the DOM structure into meaningful semantic structures.
Webpages often contain deeply nested and inconsistent layouts. Designing a snapshot representation that preserved useful structure while remaining lightweight enough for real-time interaction required multiple iterations.
Another challenge was coordinating the browser perception layer with the backend runtime. When the model needed more information, the backend had to request additional context from the browser, such as screenshots or node details.
Real-time voice interaction also introduced latency and session management challenges when coordinating browser audio streams with Gemini Live sessions.
Accomplishments that we're proud of
We are proud that ThreadAtlas demonstrates a working current-page perception layer for a browser-based AI agent.
Instead of treating webpages as unstructured text, the system allows the model to reason over a structured representation of the current page.
Semantic selection and live voice interaction also create a surprisingly natural experience, where it feels less like querying a chatbot and more like discussing a webpage together with an AI assistant.
What we learned
Building ThreadAtlas showed us that many limitations of current AI agents are not only model problems, but also environment modeling problems.
When the agent receives only flattened text, it often loses important context from the environment it is supposed to reason about.
Providing structured perception of the current page helps the model stay better grounded in the content the user is actually viewing.
What's next for Thread Atlas
ThreadAtlas currently focuses on reasoning about the current webpage.
Next, we plan to extend the system with stronger cross-page context, richer UI interaction, and deeper multimodal grounding.
Our goal is to explore how browser-based AI agents can better perceive and interact with the web as a structured environment rather than only processing text.
Data Sources Used
The prototype uses the following data sources:
- The live DOM of the current webpage
- Semantic snapshots derived from the page structure
- Optional screenshots or node-level details captured by the browser
- Stored session memory retrieved from Cloud SQL / pgvector
Built With
- chrome
- express.js
- extension
- gemini-live-api
- google-ai-sdk
- node.js
- pgvector
- typescript
- vertex-ai



Log in or sign up for Devpost to join the conversation.