Inspiration
Every website with valuable data faces the same arms race: bots want to scrape it, and traditional defenses either block real users or let clever bots slip through. Hard rate-limits and CAPTCHAs are blunt instruments — they annoy humans and barely slow down sophisticated scrapers.
We asked: what if the defense was invisible to humans but lethal to bots? Instead of just blocking, what if confirmed bots were silently fed fake data — poisoning their databases without them ever knowing? This "decoy data" idea, borrowed from military counter-intelligence, became the core of this1.
this1 is a three-layer adaptive bot defense system that doesn't just detect scrapers — it deceives them.
What it does
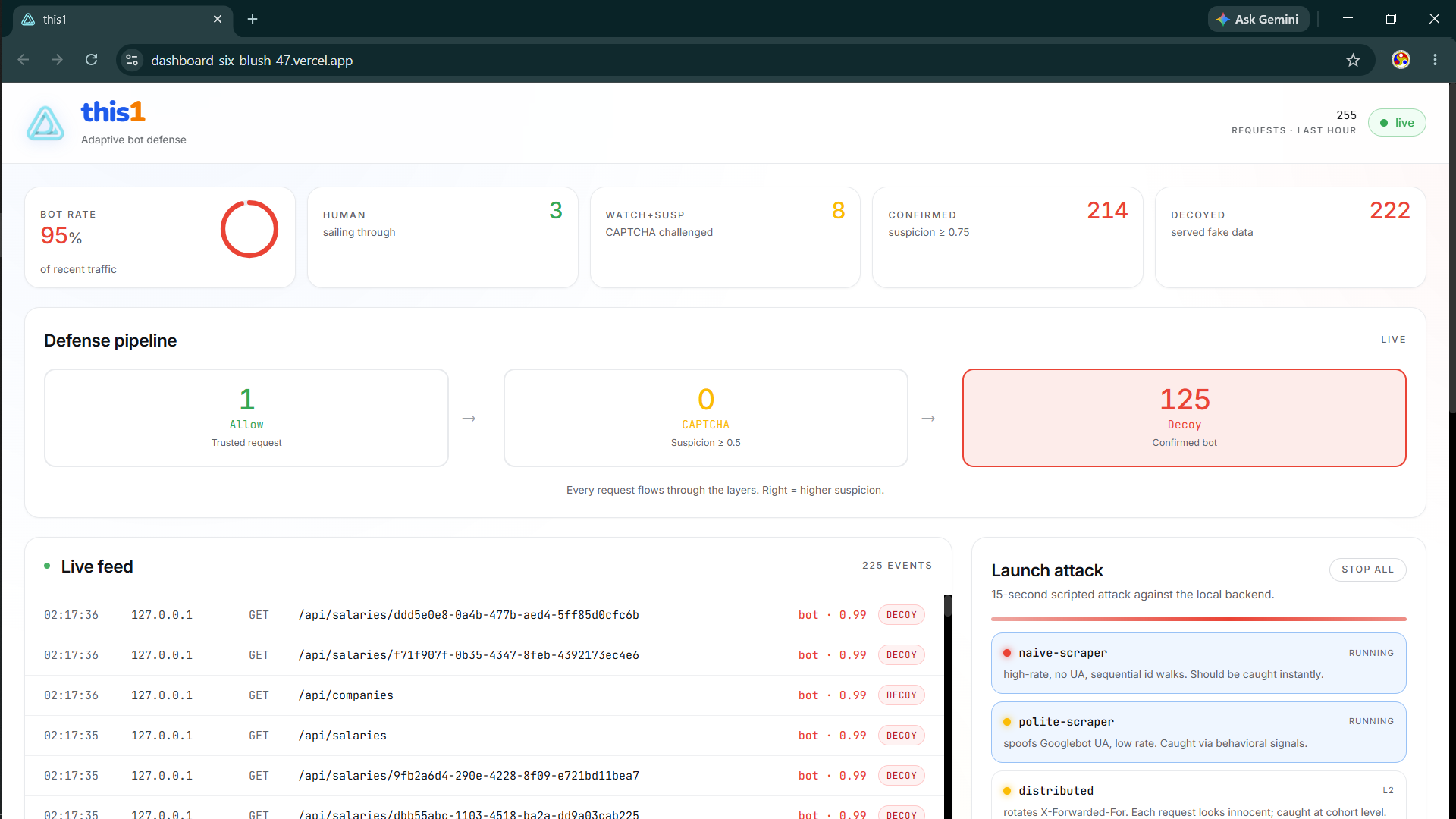
this1 sits between your users and your data, scoring every request in real time and escalating through three defense layers:
- Layer 1 — Invisible Proof-of-Work: Every page silently runs a 50ms SHA-256 puzzle in the browser. Humans never notice. Headless bots without JS can't solve it.
- Layer 2 — In-house CAPTCHA: When suspicion reaches 0.45, an emoji-click challenge appears. No third-party dependency, no privacy leak.
- Layer 3 — Decoy Data Poisoning: Confirmed bots (suspicion ≥ 0.75) get served plausible-but-fake records. The bot writes garbage to its database and walks away thinking it succeeded.
A live dashboard lets operators watch every request flow through the kill-chain in real time, launch simulated attacks with one click, and see the ML model's confusion matrix — all from their browser.
How it is built
this1 is a full-stack system with four interconnected components built end-to-end in 24 hours.
The ML Engine: A blended scoring pipeline combining a rule-based scorer with a trained Random Forest + Isolation Forest classifier. 10 behavioral signals (request rate, URL entropy, UA quality, JS evidence, mouse/scroll interaction, honeypot hits, cohort fingerprinting) feed the model, achieving 99.06% accuracy and 0.60% false-positive rate on 10k held-out samples.
The Backend: FastAPI middleware intercepts every request, extracts signals, scores it, and decides the response — all in a single pass. WebSocket fan-out pushes every event to the dashboard in real time. SQLite stores salaries, request logs, and feedback.
The Frontend: Two React + Vite apps — a protected "site" (the target bots want to scrape) and a "dashboard" (the operator cockpit with live feed, bot-rate gauge, kill-chain visualization, and one-click attack launcher).
The Simulator: 5 scripted attack scenarios (naive scraper, spoofed Googlebot, distributed IP rotation, credential stuffer, slow-and-low) that can be fired from the dashboard or CLI to demonstrate each defense layer.
Challenges we ran into
False Positives vs. Catch Rate: The hardest engineering challenge was keeping the false-positive rate below 1% while catching 98%+ of bots. Intentional noise and persona crossovers in the synthetic training data were key — clean synthetic data gave a suspicious 100% accuracy that wouldn't generalize.
Real-time Everything: Pushing every scored request over WebSocket to a live dashboard without lag required careful async design — fan-out broadcasting, client-side event capping at 250 events, and polling the server for authoritative counts.
Decoy Plausibility: Fake data that's too obviously fake defeats the purpose. The decoy generator had to produce records with realistic salary distributions, plausible company names, and consistent metadata so bots can't trivially filter them out.
Accomplishments that make me proud
The Decoy Layer: Watching a bot happily scrape 50 fake salary records and walk away is deeply satisfying. It's defense through deception, not just denial.
One-Click Demo: Judges can open the dashboard, click "naive-scraper," and watch the entire kill-chain light up in real time — no terminal, no setup, no explanation needed.
Auto-Redemption: False-positive humans automatically clear their bot status when the JS beacon detects real mouse/keyboard activity. No support ticket, no friction. The system self-corrects.
What I learned
Layered Defense > Hard Walls: A single threshold can never handle the full spectrum from naive bots to sophisticated distributed scrapers. Tiered escalation (PoW → CAPTCHA → Decoy) lets each layer handle what it's best at.
Behavioral Signals Beat Fingerprints: Traditional bot detection relies on IP and UA. But signals like URL traversal entropy, interaction score, and cohort fingerprinting catch bots that spoof everything else perfectly.
What's next for this1
Browser Fingerprint Integration: Adding canvas/WebGL fingerprinting as an additional signal to catch bots using real browser engines.
Adaptive Difficulty: Dynamically adjusting PoW difficulty and CAPTCHA frequency based on real-time traffic patterns and attack intensity.
Decoy Feedback Loop: Tracking which decoy records get published by scrapers, so the system can identify which bot networks are active and adjust defenses accordingly.
Built With
- fastapi
- python
- react
- recharts
- scikit-learn
- sqlite
- tailwindcss
- uvicorn
- vite
- websocket

Log in or sign up for Devpost to join the conversation.