
The Problem
Education is broken in a way we all felt personally.
One of us is a visual learner who never understood math from textbooks. One of us has a speech impediment and always learned better when someone showed them instead of told them. One of us grew up without access to tutors while classmates had private instruction every week. We came to this hackathon with different stories but the same frustration — the kids who need the most help are the ones with the least access to it.
Khan Academy gives you videos. ChatGPT gives you text. But a 7-year-old struggling with multiplication at 10pm doesn't need more text. They need someone to show them. To move, to gesture, to point at things, to adapt when they look confused.
They need a teacher. And teachers are expensive.
What We Built
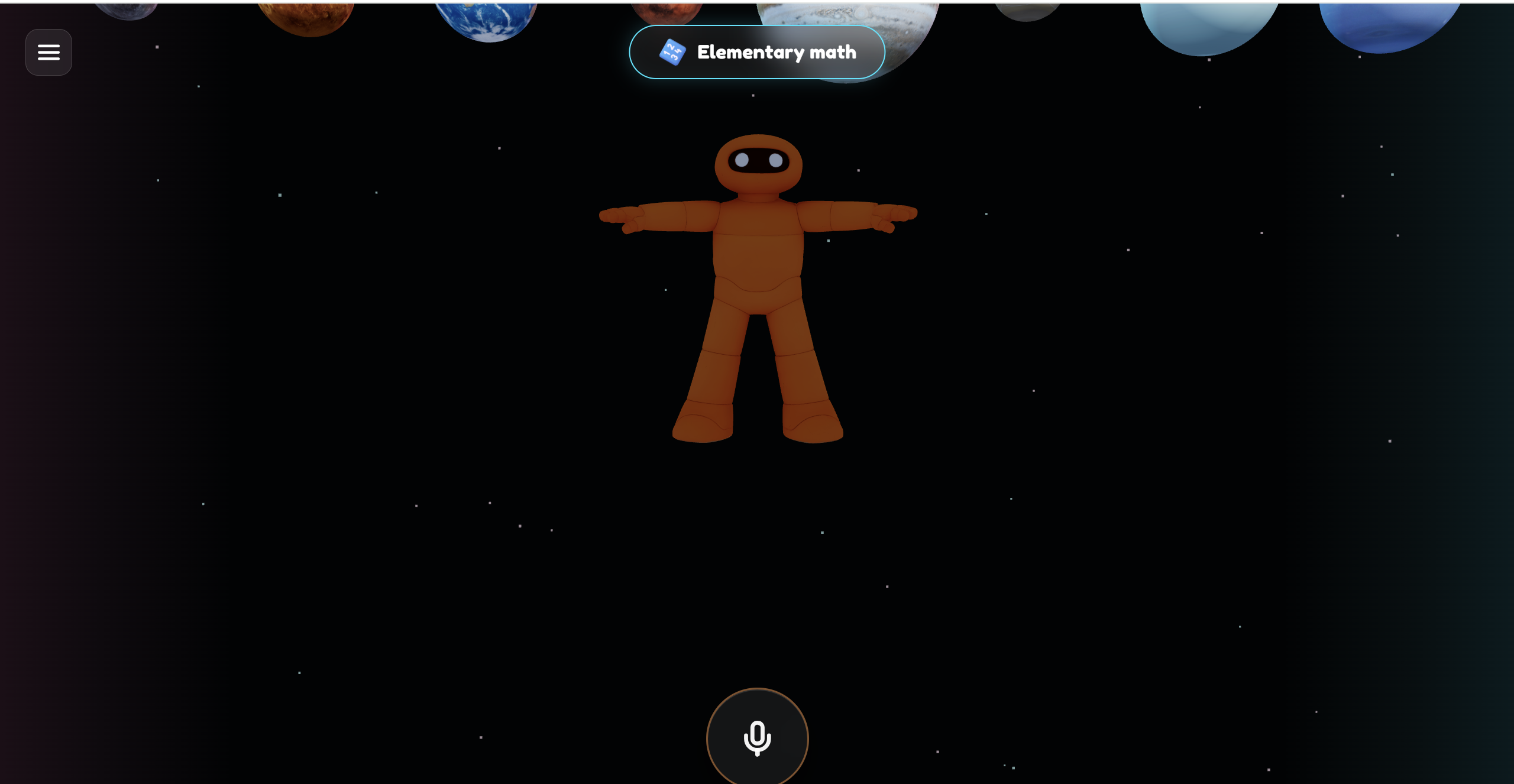
*ThinkPop * — an embodied AI tutor that teaches math the way a great human teacher would. You talk to it, it talks back. It moves naturally, gestures as it explains, and conjures 3D mathematical objects that appear in the space around it to illustrate concepts in real time.
Ask it to explain multiplication and it doesn't send you a paragraph. It spawns glowing groups of cubes, points at each one, counts them out, and merges them together to show you the answer. Its hands move toward the objects as it explains them. The character and the math are one unified experience.
How We Built It
This project sits at the intersection of several frontier ML systems that have never been combined this way before.
Motion Diffusion Model (MDM) — We run a transformer-based diffusion model locally that takes any natural language motion description and generates 22 joint positions per frame in real time. "A person points forward enthusiastically" → joint positions → character moves. This runs at ~1.4 seconds per clip on an RTX 4070.
Real-time Retargeting Pipeline — This is the part that didn't exist before we built it. MDM outputs joint positions in HumanML3D format. Our character is an AccuRIG mesh with a UE5 skeleton. Getting from one to the other in a browser, in real time, with correct coordinate systems, pelvis facing, parent-child bone topology, and twist bone distribution — nobody had done this. We found a GitHub issue on the MDM repo asking exactly this question with zero answers. We figured it out from scratch using swing-quaternion retargeting with world-space rest direction capture.
Knowledge Tracing — We track which concepts each student has mastered using a probabilistic model. ThinkPop never re-teaches what you already know and never skips ahead too far.
Emotion Detection — face-api.js runs in the browser and detects student confusion, engagement, and frustration in real time. If you look confused, ThinkPop adapts before you even ask.
Gesture-Synchronized Math Visualizations — The 3D math objects respond to where ThinkPop 's hands are in world space. When he spreads his arms, the groups separate. When he brings them together, they merge. The character's body IS the UI.
The Technical Breakthrough
The core insight nobody had shipped before: text → real-time skinned character motion in a browser.
Every motion ThinkPop makes is generated live from a text prompt by a diffusion model. Every 3D object is generated or fetched dynamically. Nothing is pre-animated. The entire experience is generative.
We know this pipeline didn't exist before because we searched for it extensively. The closest thing we found was a GitHub issue asking if it was possible — with no solution.
Challenges
The retargeting math was brutal. MDM outputs positions in HumanML3D canonical space (Y-up, character facing +Z). Three.js is Y-up right-handed with -Z forward. The AccuRIG skeleton has different rest pose angles, bone lengths, and local axes than what MDM assumed during training. Getting these three coordinate systems to agree required debugging pelvis facing direction (180° flip causing every downstream bone to be wrong), parent index remapping for collar bones, twist bone distribution for skin deformation, and swing clamp tuning per bone.
The fundamental mathematical limitation: MDM gives us 2 degrees of freedom per joint (which direction the bone points). Recovering the 3rd DOF (twist/roll) from position-only data is provably impossible. We implemented everything we could — elbow hinge constraints, pole vector approximations, twist bone distribution — and accepted that some motion quality is permanently lost without rotation data.
What We Learned
You can build something that doesn't exist in 48 hours if you're willing to debug things that have no Stack Overflow answers.
And more importantly — the kids who learn differently, who can't afford tutors, who struggle with text-based education — they deserve better tools. We built this for them.
Built With
- concurrently
- cross-env
- dotenv
- elevenlabs-api
- fastapi
- fetch
- framer-motion
- glb
- javascript
- jsx
- localstorage
- mediapipe-tasks-vision
- node.js
- openai-api-(openai-sdk)
- python
- react
- react-dom
- react-three-drei
- react-three-fiber
- three.js
- uvicorn
- vite
- web-audio-api


Log in or sign up for Devpost to join the conversation.