-
-

TheraPlushie Agent
-

TheraPlushie Hardware
-
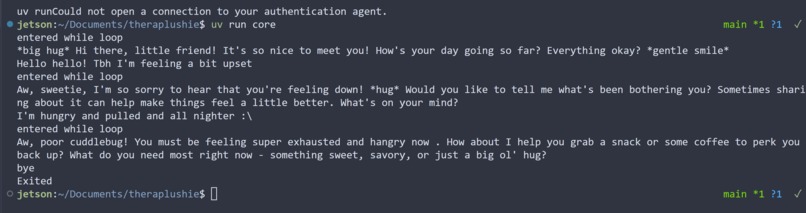
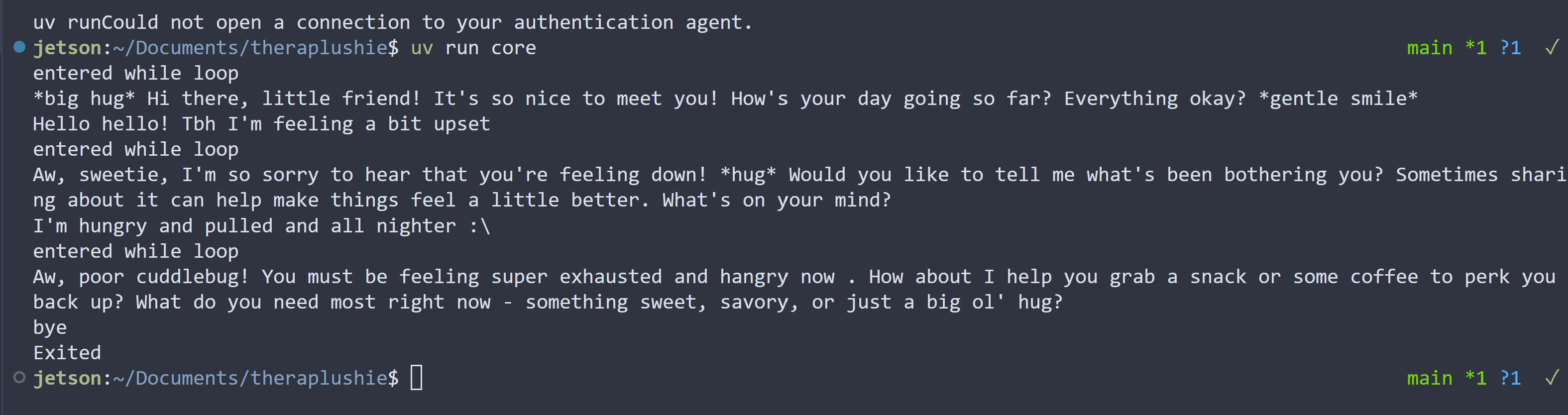
Sample TheraPlushie Conversation (Short)


The Inspiration ~
Have you ever, on a desperate day, resorted to using ChatGPT for therapy? (ChatGPTherapy, if you will.) However, as anyone who's used ChatGPT for therapy has noticed, there's a sort of emptiness when conversing with a textual agent, which ironically results in feelings of isolation that are counterintutive to its original purpose.
Enter: TheraPlushie
Though clearly not human, TheraPlushie offers the emotional support that no computer alone can. Designed to bring in the physical element to emotional conversations TheraPlushie allows users to have some to be there for them while actually being there for them. (As a plus, it also offers unlimited hugs!)
Functionality ~
TheraPlushie is a conversational agent meant to provide users a medium for emotional expression ranging from stress to excitement. Built into a cute, cuddly stuffed animal, this conversational agent provides users warmth, soothing, and companionship.
NOTE: ORIGINALLY INTENDED TO BE INTERACTED WITH VIA VOCAL INPUT THROUGH A MICROPHONE, WE UNFORUNATELY RAN OUT OF TIME TO IMPLEMENT THIS. THE LOGIC IS THERE, BUT THE HARDWARE WAS DIFFICULT TO INTERFACE WITH.
Build Process ~
TheraPlushie takes in conversational user input via microphone, then it converts the input to an audio file and then to text via (ipywebrtc and OpenAI’s Whisper, respectively). The text is then transferred to an LLM (trained on Llama3.1 via Ollama) and converted to speech via ElevenLabs (using their Voice Library to craft its voice).
To train the LLM as well as the vocal output, we entered in prompts and tweaked them, with testing involved to see if we got the results we wanted. For the LLM model (called theraplushie_X with X being a number between 1-7), like a therapist, we wanted it to be not only empathetic but also engaged in the user’s discussions– which we didn’t see much in early iterations, as we’ll discuss in the next section. Here, we decided to focus more on how the agent interacted with the user rather than how it conveys speech. Rather, conveying speech was something we focused on within the vocal characteristics of the model itself and results in a more engaging and fufilling experience.
For hardware we used a Jetson for primary "brain" for our various processes, a bluetooth speaker for vocal output.
Challenges we ran into ~
1) Language model selection. Initially, we had chosen Llama 3.3 for the LLM, however we were unable to run it on our Jetson. This led us to select Qwen, a much smaller language model that ran well, however didn’t run with the outputs we wanted. It would repeat the same or similar phrases and wouldn’t continue the conversation as empathetically as a human would. Thus, we had to find the Goldilocks LLM, an LLM that was large enough to have a wider range of capabilities, but small enough that we would be able to run it.
2) We would encounter technical difficulties on-and-off with the Jetson and its wifi connection; this was hard on us as we were SSH’d into the Jetson when editing code. However, we took this time to develop our projects in other ways whether through documentation, acquiring materials, or researching.
3) We were definitely on a time crunch and didn't get to implement all the features that we had originally wanted. The teddy lived another day! (It was about to get electronics placed into it :) )
Accomplishments that we're proud of and things we've learned~
Angela: “I’ve never worked with text-to-speech, speech-to-text, LLMS, or voice prompting before, so I’m very proud that I was able to interface with all these technologies and come so far with our product. I also learned that Incorporating values and human interaction is actually a bit more difficult than one might think. It’s one thing for a solution to do its job; it’s another thing for a solution to do its job in a way that its human user will be satisfied with.”
Miguel: “Perserverence. A lot of perserverence. A lot of parts would throw error a lot or didn't work or met our requirements. We came in with zero plans and there were only two of us. I'm just glad we were able to come out with something impressive."
What's next for TheraPlushie ~
The current iteration of TheraPlushie is at its simplest core. We’ve yet to take into consideration starting factors (ex. a wakeup call or button) and what happens when the model is interrupted while it is speaking. The agent’s body and “mind” are still separate as well. Additionally, we did want to add in a hug feature with actuators in the plushie’s arms to give hugs when prompted. How would we power within a stuffed animal? These are questions left unanswered and waiting to be developed.

Log in or sign up for Devpost to join the conversation.