-

Home Screen
-

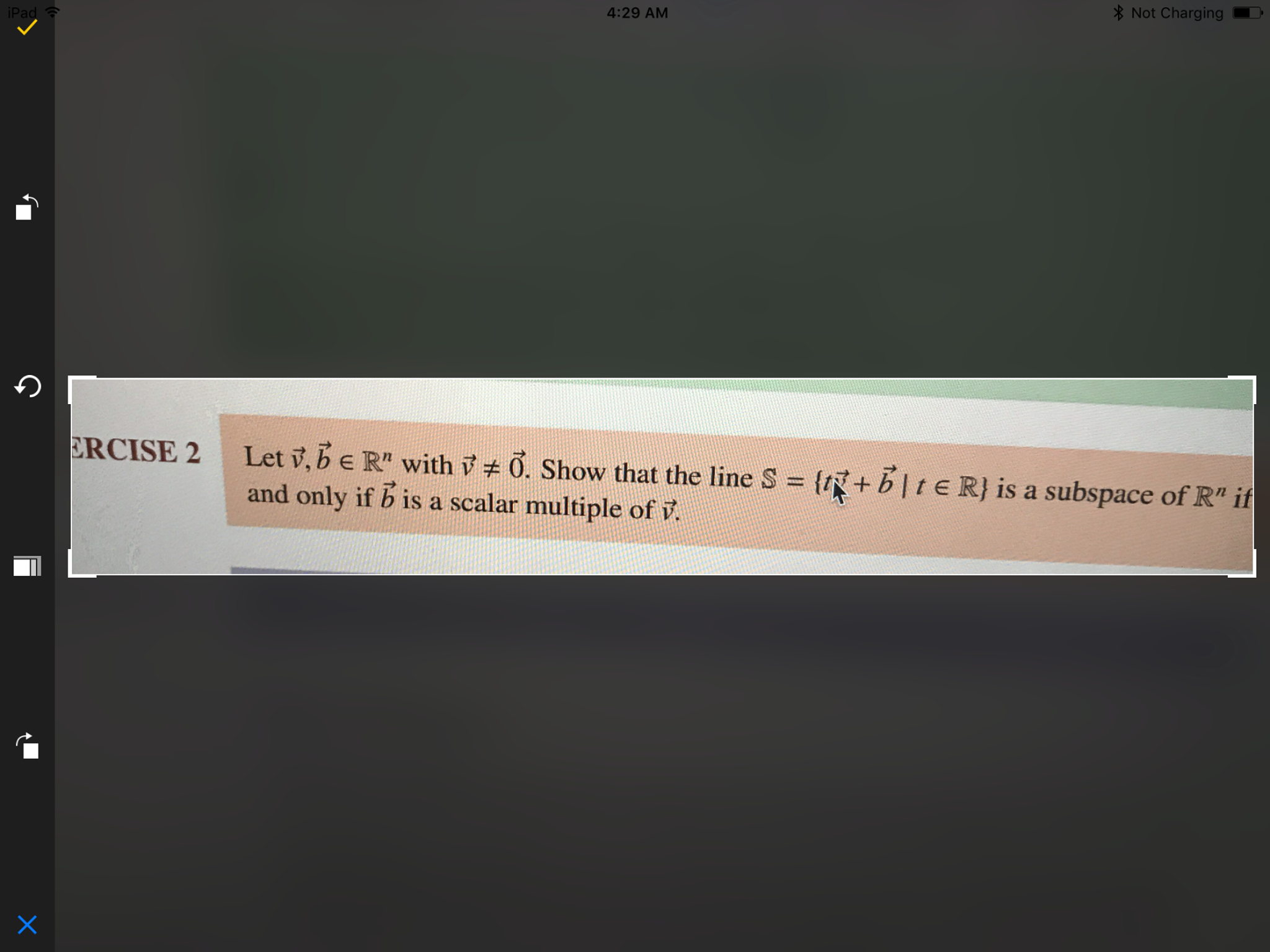
Example Question
-
Fetching from back end
-

results returned
-

-

-

-

-








Theorem-eter
Hanyu Qu, Mike Chen, Brandon Weng, Ziyin(Cody) Wang
University of Waterloo
Hack the North 2017
Introduction:
Do you ever find yourself stuck when doing a math problem? Unfortunately, the members of our team do and constantly encounter that sad feeling of not knowing what to think, not even knowing where to turn the textbook. Fortunately, as technology loving students, we turned to the obvious solution of using our skills and data to help address the issue (instead of maybe study harder?). With the idea of developing a tool that can help you get unstuck, by providing “smart” insights and inspirations in the form of pictures of useful definitions and theorems to help you solve a problem. Of course, ease of use and convenience was the major theme and goal for us to focus on.
Application & Technical Breakdown: The Theorem-eter is an iOS mobile application utilizing Optical Character Recognition (OCR) and Statistical Learning, that takes in and process text of whatever math problem and provides the user with dynamic suggestions of key concepts and definitions relating to the nature of the problem. With a single snap of your phone camera, an image of your problem will be encoded into formats to be analyzed and characterized with the database containing an extensive libraries of mathematical formulas and definitions. With that transformed information, our algorithms will identify and classify the contents of the question, and suggest real-time, relatable definitions and theorems. This suggestion process uses statistical learning based on the relative frequency and distribution of the specific mathematical topics across the span of categorical hierarchies. The question and keywords identified from the image will be assigned and computed relative values and compared against entries in the database of theorems and definitions. Various statistical calculations and transformation are done, to find the best matched potentially relatable definitions. This is done through the OCR recognition of keywords and the aforementioned statistical prediction model. We have tested a vast range of samples and adapted our processes to self-learn through Machine Learning concepts to continuously alter frequency distributions and therefore enhance the graphical relation between DBMS systems.
Through the iOS application interface, we enable users to take pictures of the problem. The App then makes requests and sends the encoded information to the back-end of Cockroach DB database. The front-end and transmission of visual data is done through Swift using an extensive suite of packages and interface modules, ensuring smoothness in usage and a pleasant user experience. Our database is hosted on Cockroach DB and coded in Python with Flask frameworks. The information contained in the database is scanned and processed using OpenCV, and analyzed. The API calls and statistical modelling are also done in Python, using packages including numPy, Pickle. We utilized the OCR API provides a simple way of parsing images and even multi-page PDF documents and getting the extracted text results returned in a JSON format. The JSON file is parsed and actual words and mathematical concepts are clarified. The keywords are then measured by statistical processes which would assign a relativity value, in relation to the definitions and theorems based on the frequencies and coverage weighting based on the contents of textbooks in which definitions were taken from. The algorithm identifies suggested information and will access the database queries and retract the information instantly to the user. The suggestion and list of suggested sources is done both by the statistical algo and based on keywords identified in the question itself. The images of definitions and theorems then are presented to the user providing the viewing option for all, in a minimal and clean layout.
Originality & Practicality: While both OCR-empowered applications and mathematical definition and help app and websites are in abundance. It’s actually quite difficult to find an easy to use application that can combine the both in layman's term. The majority of OCR are cloud-based services more geared towards pdfs, which would require the user to scan or upload the question only in PDF concept, to convert to text. Mathematical references apps, also usually require direct typecast and are often broad. Existing conveyors of text to math references often require LaTex and have very few low-cost and easily accessible options.
The motivation behind our idea, was to truly identify something of our dire need. Combined with our technical forte of statistics and computer science, it made perfect sense to give it a try and make something that can make our and our peer’s lives easier. The demo, which will done using Math136: Linear Algebra I, a class offered at uWaterloo as the contents and course for the initial prototype. The demo will allow users to scan related questions and provide suggested theorems all can be done on your cell phone. This is an unique demo, which we are truly proud to present! In terms of practicability, this can be immediate for a lot of Waterloo students and can be extended easily to more subjects and courses as the algorithm are easily extendable and apply to virtually every discipline.
Design & WoW Factor: The design process of our project was a very extensive process. The goal of the application is to provide help in the research and learning process, so convenience and reliability was our top priority. We designed our application interface using the popular and well-perceived UI templates and modules. We kept the screens to a minimalist design with moderate colors, aiming for classy and sleek design.
The database is done on a relational basis with minimal fields and high cohesion. We designed all interactions between components to be based on the user’s request and fast and efficient with minimal callbacks and noises. The combination of the design and our focus on efficiency is our Wow Factor. We believe we are truly doing something that not a lot people are doing but would likely use. So we hope to wow them, with a great user experience!
Challenges & What we learned: As it goes with everything in life, nothing is ever a perfectly smooth sailing. We had some technical challenges and stressful moments along the way.
For example, we experienced a few issues setting up communications with the OCR API calls. Processing large textbooks and images take a lot of experience and adjusting, and we had exceeded our free API limit, resulting us to optimize our code and think of better solutions. Another issue we encountered was the image sizes which had to be high resolution and easily and fast to transfer by database connections. This is something we will consider and be more careful in the future, as the OpenCV prompted sizing are random in some cases.
What we had a lot of fun with, despite being a little hard at first, was quantifying and developing the Statistical Machine Learning-isque algorithm of smart suggestions, which is our core technology. It was our first time of thinking of statistical models on our own and applying it, which was a lot of fun and taught us a lot.

Log in or sign up for Devpost to join the conversation.