Inspiration
As vision models become more common in everyday AI applications, we noticed that understanding images often requires sending large amounts of tokens to language models, which is expensive and inefficient. Most systems rely on long, descriptive captions that include a lot of redundant or unnecessary details. Since this hackathon focused on compression using The Token Company’s bear-1 model, we were inspired to explore how we could reduce token usage for visual data by extracting only the most meaningful information from images before sending anything to an LLM.
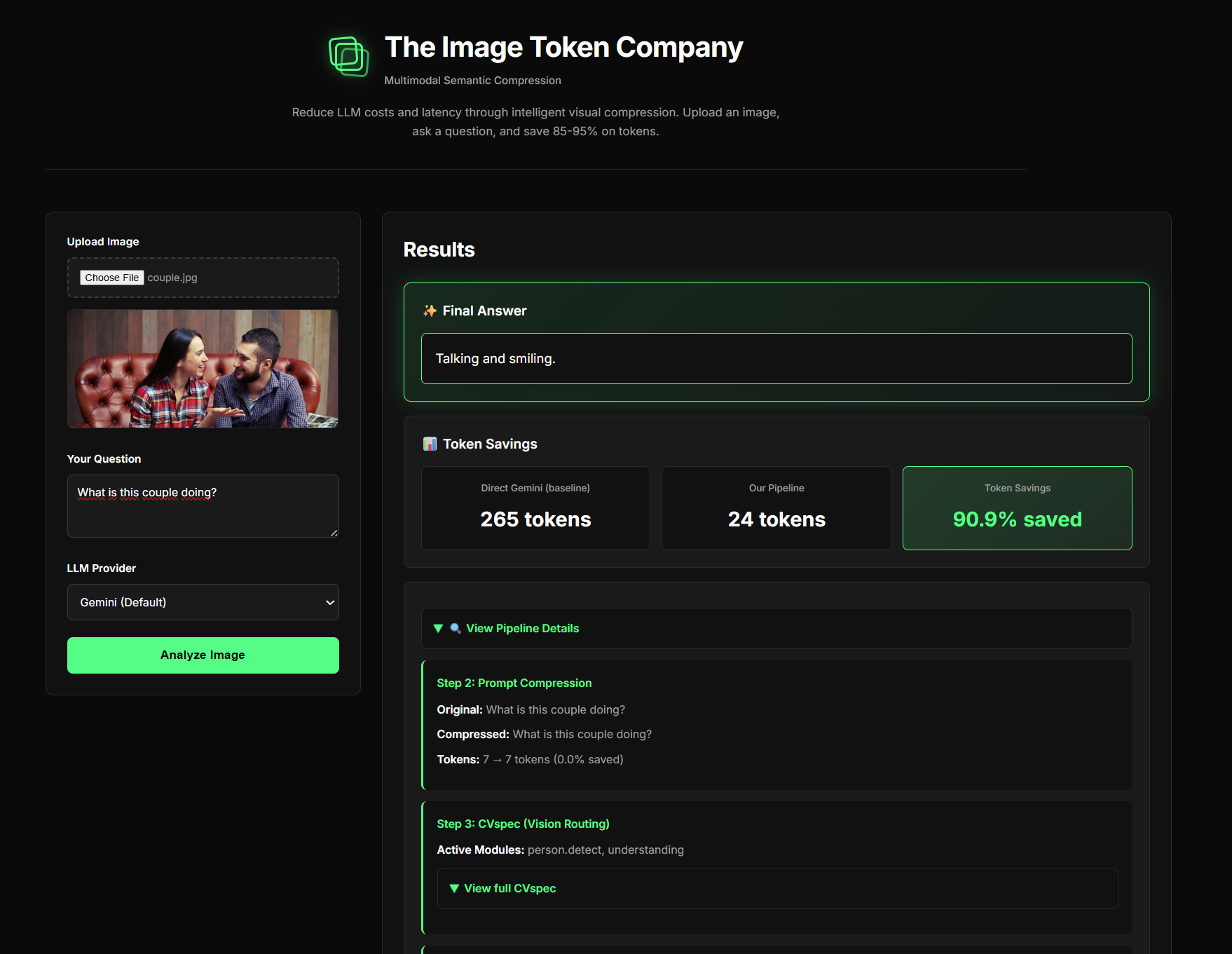
What it does
Our app takes an image and converts it into structured semantic information instead of a long natural-language description. It first determines whether the image is mainly a document, a scene, or a mix of both. Then it extracts key details like detected objects, basic activities, important text, and layout signals. This information is converted into a compact schema with short keys, and finally compressed using bear-1. The app shows the original token count, compressed token count, and percent savings so users can clearly see how much cost and bandwidth is reduced.
How we built it
We built a macOS desktop app using Tauri with a React frontend and a Python sidecar for machine learning. The Python backend runs OCR with EasyOCR for documents and YOLOv8 for object detection in scenes, using Apple Metal GPU acceleration when available. After extracting semantics, we normalize everything into a compact JSON-style format and send it through The Token Company’s bear-1 compression API. The frontend handles drag-and-drop image uploads and displays the semantic output and compression statistics in real time.
Challenges we ran into
One major challenge was balancing how much information to keep versus how much to compress. If we removed too much structure, the LLM would lose useful context, but if we kept too much detail, token savings dropped. Another challenge was getting GPU acceleration working reliably on macOS with PyTorch MPS, especially alongside EasyOCR and YOLO models. We also had to make sure the Python sidecar and Tauri app communicated smoothly without slowing down the user experience.
Accomplishments that we're proud of
We’re proud that we built a fully working multimodal compression pipeline within a 24-hour hackathon. The system demonstrates real, measurable token savings while still preserving useful semantic information for reasoning tasks. We also successfully integrated multiple computer vision models, structured normalization, and bear-1 compression into a single desktop application with live statistics and visual feedback, making the results easy for judges to understand.
What we learned
Through this project, we learned that compression is not just about removing words, but about choosing the right representation of information before compression even happens. Structured semantic extraction can significantly improve both efficiency and clarity for downstream AI tasks. We also learned more about deploying ML pipelines locally, managing GPU acceleration on consumer hardware, and coordinating frontend and backend systems in a desktop environment.
What's next for TheImageTokenCompany
Next, we want to expand support for more document types, add batch image processing, and explore video frame compression for multimodal RAG pipelines. We also want to experiment with learning-based semantic selection instead of rule-based heuristics, so the system can adapt to different downstream tasks. Ultimately, we see this approach being useful for any AI system that needs to understand large amounts of visual data while keeping LLM costs low.

Log in or sign up for Devpost to join the conversation.