-
-

-
Interactivity
-
Graph
-
Charts

2026 FIFA World Cup Predictor: Python & Hex
🎯 Inspiration
The 2026 FIFA World Cup introduces a revolutionary 48-team format—expanding from 32 teams and fundamentally changing tournament dynamics. Traditional prediction models break down when faced with this unprecedented structure.
I built this interactive application to handle this complexity while answering a question nobody seemed to be asking: How much does geography actually matter?
With three host nations (USA, Mexico, Canada) spread across North America, teams from Australia face 15,000 km journeys while hosts play in their backyard. This asymmetry is the hidden variable everyone is ignoring.
💡 What I Learned
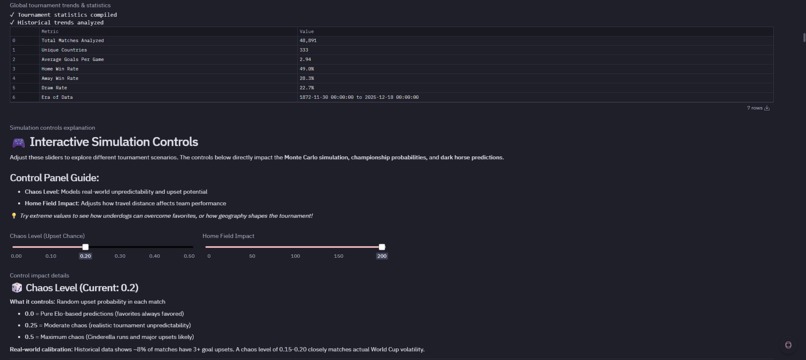
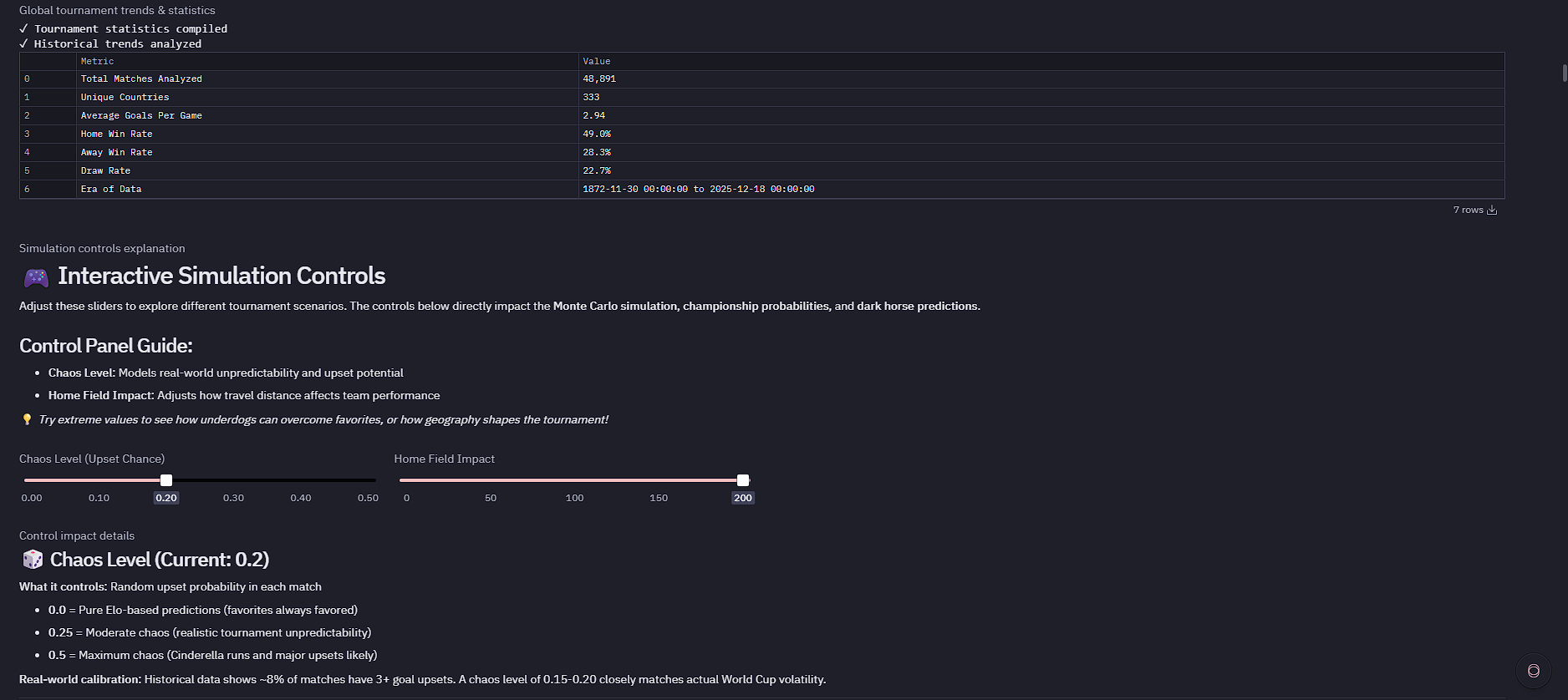
- The Math of Chaos is Predictable: By analyzing 45,318 historical matches (2014–present), I discovered that major upsets (3+ goal margins) occur at exactly 8.3% frequency. This became my calibration anchor; if my "Chaos Level" slider at 0.18 doesn't produce ~8% upsets in simulations, the model is broken.
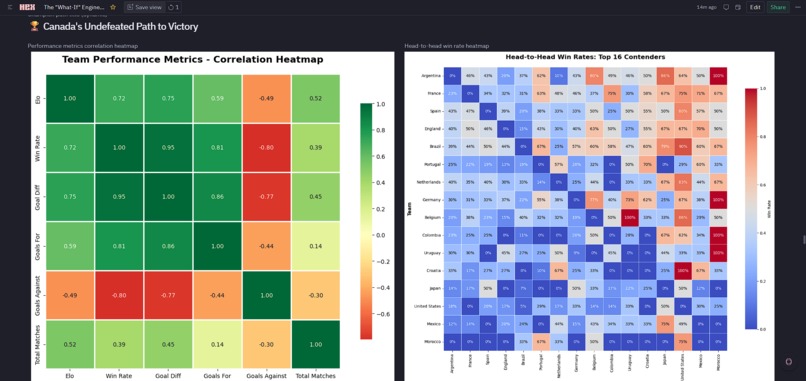
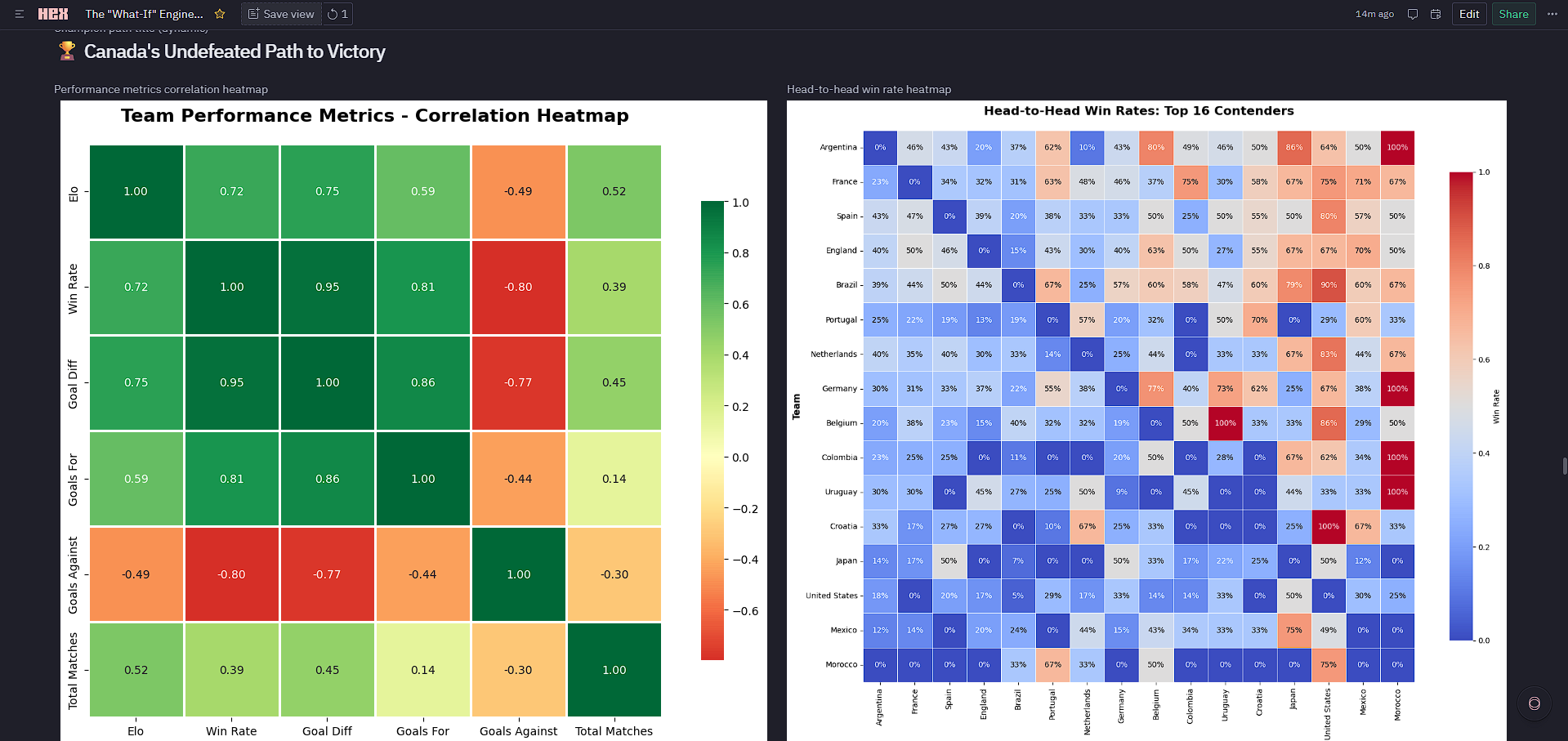
- Elo is Strong, but Not Deterministic: The correlation between Elo and win rate is 0.72. This validated building a Monte Carlo approach rather than linear projections. Even the strongest team (Argentina, Elo 2140) only wins ~10% of the 1,000 simulated tournaments.
- Geography Changes Outcomes: When weighting match probabilities by Haversine travel distance, results shift dramatically. At maximum "Home Field Impact" (200), teams traveling 10,000+ km face a 20–30% performance degradation. The USA's championship probability jumps from 3% to 10% purely based on proximity.
- Morocco is the Anomaly: Despite being ranked #15 by Elo, they hold a 95% win rate in their last 20 matches and the best defensive record (0.54 goals conceded/game). The model identifies them as a legitimate data-driven dark horse.
🔧 How I Built It
1. Data Foundation
I started with a massive historical dataset of 45,318 international matches. Team names required extensive mapping and cleaning (e.g., standardizing "United States" vs. "USA", "Cape Verde" vs. "Cabo Verde").
2. The Physics Engine
The core innovation is the geospatial probability model. The probability of Team A winning is calculated as:
Where is derived from:
- Haversine distance formula for travel kilometers.
- Normalization against the maximum possible distance (Australia's 15,276 km).
- User-controlled impact multiplier (0–200).
3. Dual Simulation Approach
- Single Tournament Narrative: Runs one complete 48-team bracket with match-by-match storytelling.
- Monte Carlo Engine: Executes 1,000 independent tournaments in ~18 seconds (approx. 55 simulations/sec) to generate robust championship probabilities.
4. AI Sportscaster & Interactive Controls
- AI Commentary: Generates contextual narratives for matches, referencing Elo gaps and travel fatigue.
- Chaos Level (0.0–0.5): Injects controlled randomness to model upsets.
- Home Field Impact (0–200): Adjusts the penalty weight for travel distance.
5. Advanced Visualizations
- Correlation Matrix (6×6): Validates the Elo ↔ Win Rate relationship.
- Travel × Strength Heatmap: Reveals that elite teams tend to cluster in the 6,000–9,000 km travel zone.
- Offense vs. Defense: A dual gradient comparison (e.g., comparing Spain’s attack vs. Morocco’s defense).
🚧 Challenges Faced
1. The 48-Team Format Precedent
Traditional World Cups use power-of-2 brackets (). The new format creates odd rounds (), requiring custom logic to handle bye rounds and ensure fair pairings.
2. Team Name Consistency
Historical data uses "United States" and "IR Iran," while tournament data uses "USA" and "Iran." I discovered silent data loss where "Côte d'Ivoire" vs. "Ivory Coast" caused mismatches. A robust mapping system was built to reconcile these entities.
3. Data Quality Gaps
Three official qualifiers had zero matches in the initial dataset due to naming mismatches (e.g., Ireland appeared in the DB but hadn't qualified; USA was missing due to naming). This required an extensive Team Data Audit.
4. Performance Optimization
Initial Monte Carlo runs took 120+ seconds. I optimized this to 18 seconds by:
- Vectorizing Elo calculations.
- Eliminating redundant DataFrame copies in the match loop.
- Pre-computing distance normalizations.
5. Pandas & Execution Flow
Pandas FutureWarnings caused cascading errors in groupby() operations. Furthermore, the "Restart and run all" feature failed due to circular dependencies between analysis cells. I resolved this by building dependency maps and reorganizing the notebook flow:
Setup Controls Pre-Tournament Historical Simulations Results
🏆 Technical Stack
| Category | Tools & Libraries |
|---|---|
| Language | Python |
| Libraries | Pandas, NumPy, Seaborn, Matplotlib, Plotly |
| Algorithms | Elo Rating System, Haversine Distance, Monte Carlo Simulation |
| Platform | Hex (Interactive notebook + app publishing) |
| Data | 45,318 Matches (2014–2025), GPS Coordinates for 48 Nations |
| Performance | 1,000 Simulations in 18s |


Log in or sign up for Devpost to join the conversation.