-
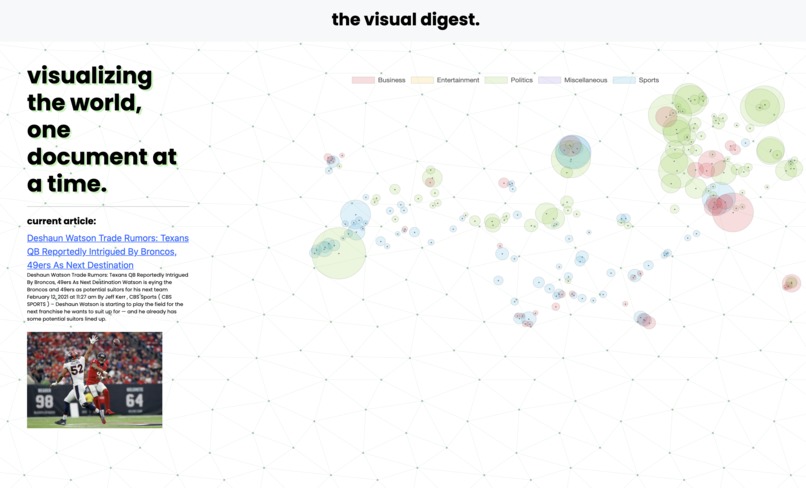
Demo of TVD in action
-

Our DevOps repo
-

the visual digest logo
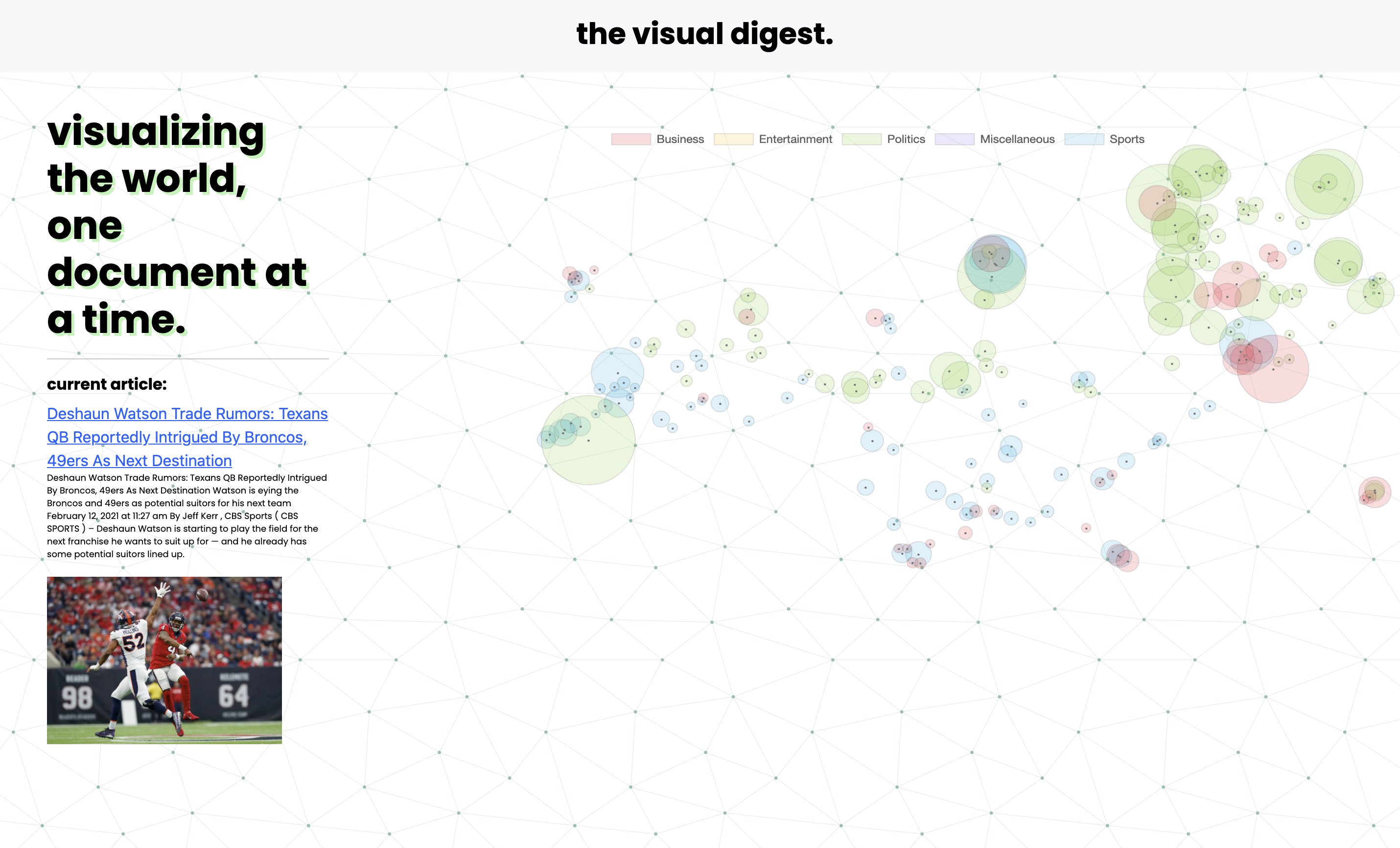


Inspiration
Our team tackled the problem of newsfeed clutter.
Our world is multifaceted with thousands of events happening each day. To keep up-to-date, we browse the news. Yet in direct contrast to the complexity of the world, most newsfeeds use a single-column format. This leads to two distinct problems.
First, a single-column format reduces the space of one’s newsfeed. Articles in a diverse range of topics must all jostle for the same, cramped space. Sports articles are placed next to articles about political turmoil, cooking recipes next to international crises. This ‘topic whiplash’ causes a viewer to disengage: how could I care about pumpkin pie when the capitol is being stormed? (Or alternatively, why would I worry about politics when I can enjoy pumpkin pie?)
Second, a single-column format loses the forest for the trees—it fails to illustrate the bigger picture. Because an article has no relationship with its neighbors, it is difficult for news sources to convey a message bigger than a single article. For the user, it is difficult to grasp broad themes as well—that would require sifting through the newsfeed to see what is most pertinent and what is not.
What it does
The Visual Digest (TVD) solves the problem of newsfeed clutter. It visualizes the news using semantic similarity, giving rise to a landscape of articles for ease of browsing. Similar articles are located in similar positions, letting a user jump from topic to topic rather than article to article. A user chooses their own pace of news consumption and can find relevant articles much easier—eliminating the spatial problem of newsfeeds.
Moreover, the landscape itself tells a story: with a glance a user can see which events are receiving attention, which ideas are being discussed. Additionally, our live updates mean that a user can see the landscape shift in real-time as new trends or patterns emerge. In total, TVD seeks to revolutionize the way society consumes news.
How we built it
Our application pulls news articles from multiple APIs and datasets and stores their text and corresponding metadata. If metadata is missing (summary, keywords), the application uses OpenAI’s API to fill in these fields. Then, the application represents the textual corpus using a modified word count matrix known as TFIDF, before embedding this matrix to two dimensions using the UMAP or t-SNE algorithms. This serves to cluster articles by content.
This representation is then passed to the frontend, for it to be displayed. We use Flask for both frontend and backend, and Chart.js to display interactive and elegant visuals. Finally, our website is deployed using an Azure Web App through an automated build and deploy pipeline from DevOps.
Challenges we ran into
As with any project, we encountered some insightful difficulties as we were building TVD. Our main challenge was determining how we would display the data we collected from news articles and generated from the OpenAI API. Would we display the data in a web? Or did we want to illustrate it as icons?
The next difficult endeavor was determining the visualization technique and designing the backend and server architecture around that. Learning how to create a data pipeline, choosing which APIs and softwares to work with, and creating a successful product were all surely challenging, but the skills and connections we cultivated made it worth the 36 hours of hacking.
Accomplishments that we're proud of
We are proud of ourselves for building a fully functioning application that simply started as a thought! Also, having not known each other before TreeHacks and being remote during these past few days, collaboration and communication was key, and we believe our team couldn’t have done a better job.
What's next for The Visual Digest
The Visual Digest current visualizes news, yet these ideas can be extended to so much more. TVD can be applied to any document-based dataset, from legal documents to social media posts to research papers. (Actually, we’ve already begun experimenting with visualizing ArXiv papers.) Because the opportunities for expansion and improvement are huge, the first next step is streamlining the data visualization and adding more customization and filters for the user. Next, it would be to expand the storage and data collection capabilities of the app such as database support and a more efficient web server to keep up with the backend and large volume of incoming information.
Note: For privacy reasons (API keys and passwords), we cannot put our repo here! Please check out the rest of this DevPost or our site!
Built With
- azure
- css
- flask
- highcharts
- html
- javascript
- newsapi
- numpy
- openai
- python
- scikit-learn
- t-sne
- tfidf
- umap
- webhoseio







Log in or sign up for Devpost to join the conversation.