-
-
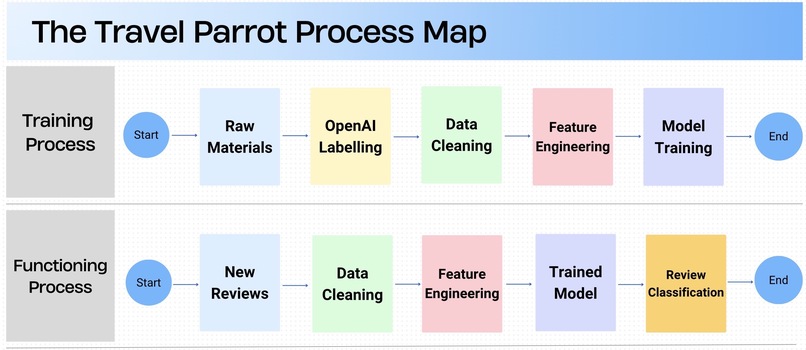
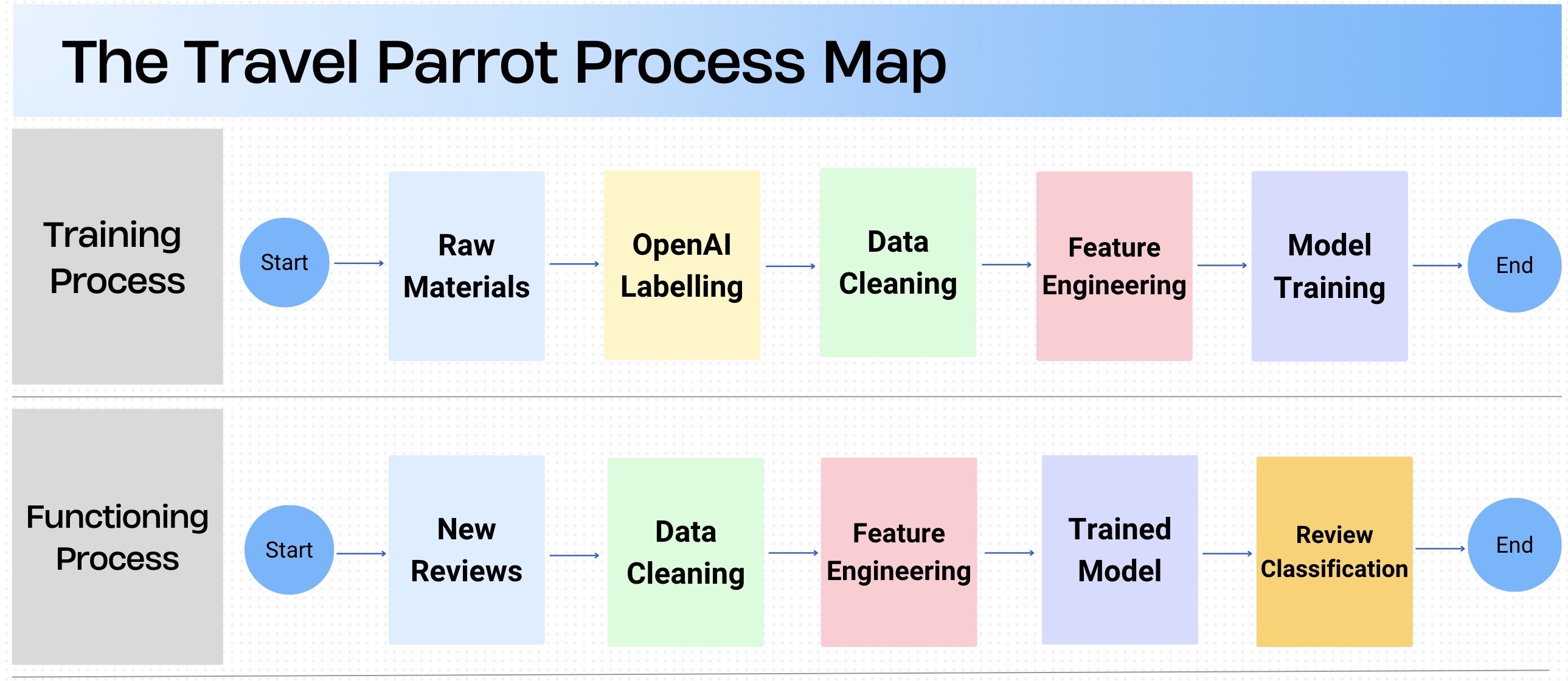
Project_Workflow
-
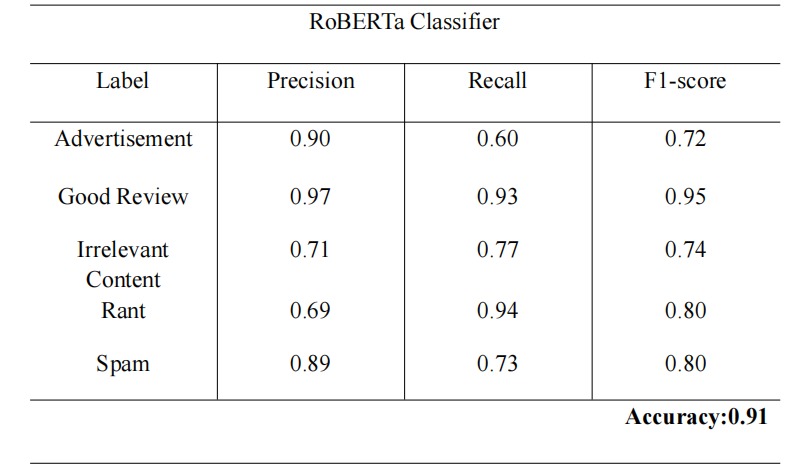
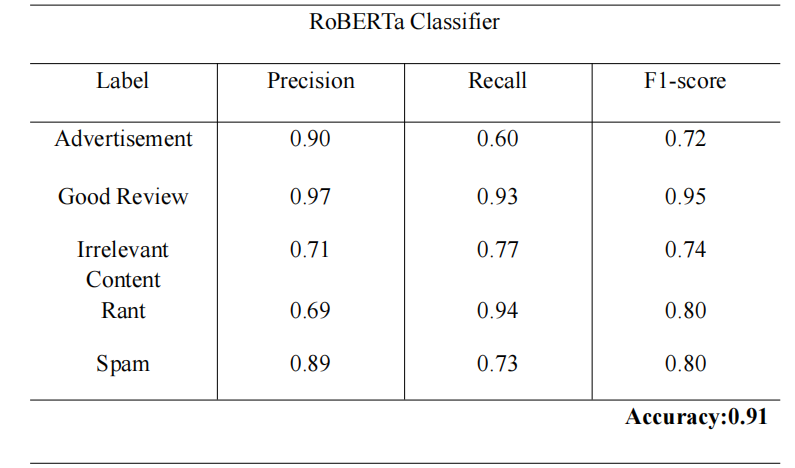
RoBERTa_Classifier
-
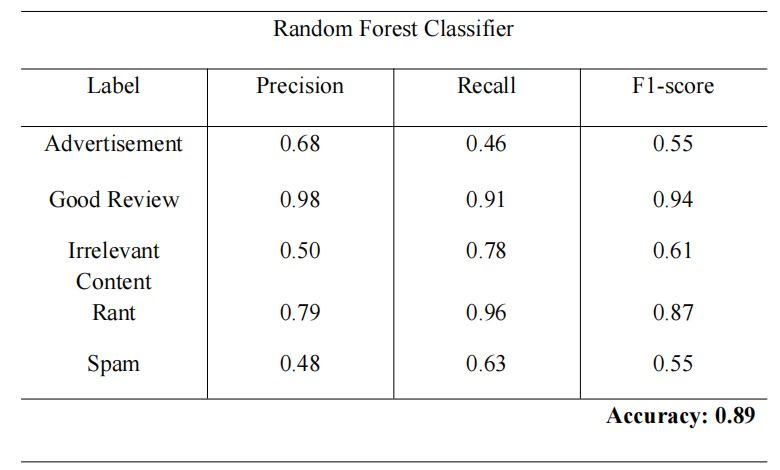
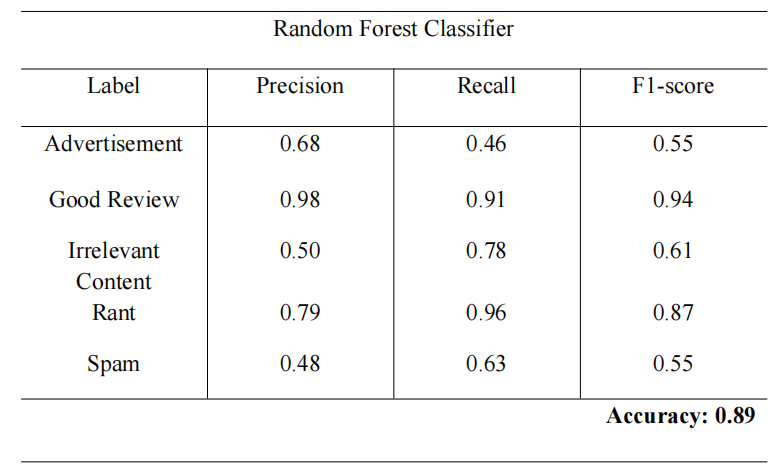
Random_Forest_Classifier
-
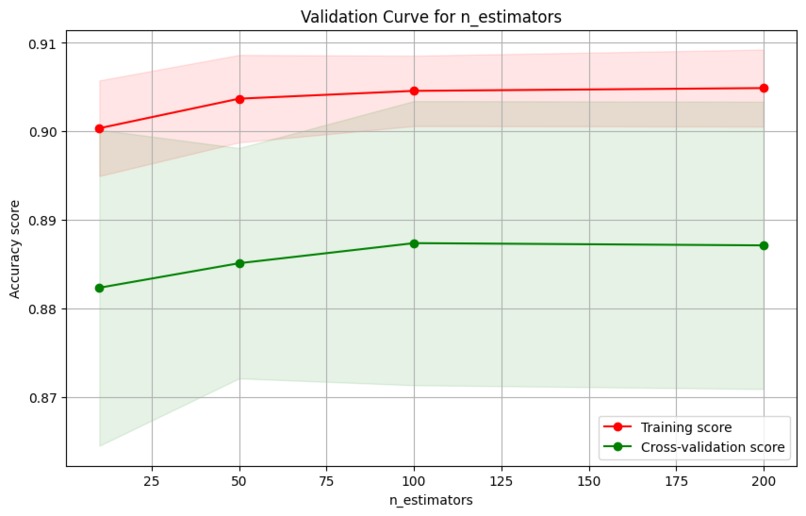
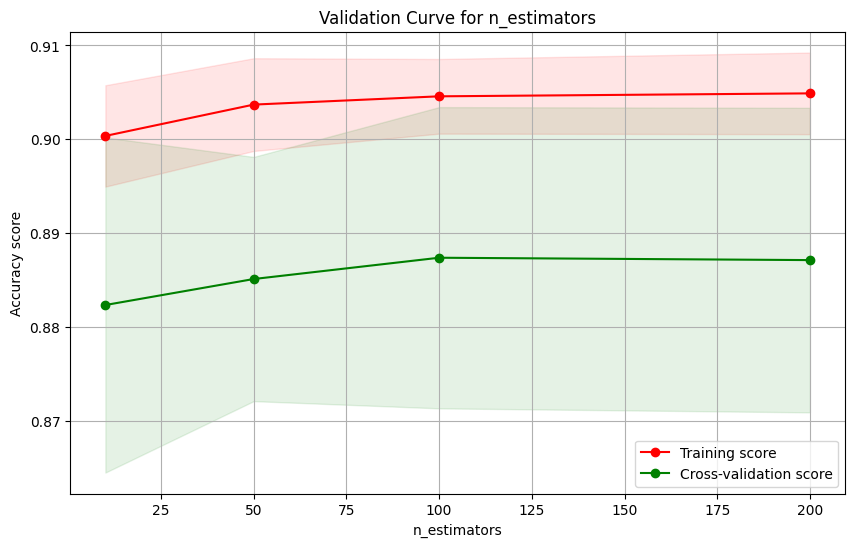
Random_Forest_Validation_Curve_for_n_estimators
Google Local Review Quality & Relevancy Classification
Overview
Our project addresses the challenge of automatically assessing the quality and relevancy of Google location reviews using Machine Learning (ML) and Natural Language Processing (NLP). Online reviews play a vital role in shaping perceptions of businesses, but irrelevant, spammy, or misleading reviews can distort reputation.
To solve this, we developed and compared two ML-based approaches:
- RoBERTa-based Transformer Model for deep contextual text classification.
- Random Forest Classifier leveraging engineered linguistic and semantic features.
Together, these models aim to detect low-quality reviews, enforce content policies, and improve review reliability.
Problem Statement Tackled
We specifically address the hackathon’s requirement to:
- Gauge review quality: Detect spam, ads, irrelevant content, and rants from non-visitors.
- Assess relevancy: Ensure review text is genuinely tied to the location being reviewed.
- Enforce policies: Automatically flag reviews with:
- Advertisements
- Irrelevant
- Rants
- Span
- Good Content
Solution Approach
1. RoBERTa Transformer Model
- Architecture: Built on Hugging Face’s
roberta-basewith a custom classification head. - Key Features:
- Tokenization and contextual embeddings via RoBERTa.
- Class-weighted loss to address label imbalance.
- Early stopping for efficient training.
- Tokenization and contextual embeddings via RoBERTa.
- Training:
- Dataset cleaned (drop missing values, irrelevant columns).
- Train/val/test split with label encoding.
- Metrics: Accuracy and Macro F1-score.
- Dataset cleaned (drop missing values, irrelevant columns).
- Output: Predicts review categories (e.g., Good Review, Spam, Advertisement, Irrelevant Content).
This model excels in capturing nuanced semantics and context, making it powerful for detecting subtle irrelevance or disguised promotional language.
2. Random Forest Classifier
- Architecture: Traditional ensemble method using engineered features.
- Feature Engineering:
- Linguistic indicators: word count, sentiment words, sensory words, superlatives.
- Behavioral cues: business-related terms, promotional language, authenticity score.
- Linguistic indicators: word count, sentiment words, sensory words, superlatives.
- Training & Validation:
- Label encoding + feature scaling.
- Trained with balanced class weights to handle skew.
- Comprehensive validation: cross-validation, learning curves, feature importance analysis.
- Label encoding + feature scaling.
- Output: Multi-class classification into review categories.
This approach offers interpretability through feature importance, helping explain why a review is flagged.
Tools & Technologies Used
Development Tools
Google Colab
Jupyter Notebooks
VS Code
APIs Used
OpenAI GPT-4o-mini (for exploratory data analysis & augmentation)
Google Maps API (for location-based review metadata, if needed)
Libraries & Frameworks
Hugging Face Transformers
PyTorch
scikit-learn
pandas
numpy
seaborn
matplotlib
openai
Datasets
Google Local Reviews Dataset (cleaned & preprocessed)
Manually labeled reviews:
- Spam
- Ad
- Rant
- Irrelevant
- Good review
Results & Insights
- RoBERTa: Achieved higher accuracy and macro-F1, particularly effective for nuanced semantic detection (e.g., disguised ads, off-topic rants).
- Random Forest: Provided strong interpretability and decent accuracy, highlighting which textual features most influenced classification.
- Combined Value: While RoBERTa outperforms on raw text understanding, Random Forest aids in explainability and quick validation, making the two complementary.
Future Improvements
- Integrate both models in a hybrid pipeline (RoBERTa for semantic analysis + Random Forest for interpretable signals).
- Expand dataset with active learning to capture more edge cases.
- Deploy as an API endpoint for real-time review moderation.
Built With
- csv-data-processing
- google-colab-cloud-services:-openai-api-(gpt-4o)-apis:-openai-gpt-4-api-other-technologies:-regular-expressions-(regex)
- googlecolab
- json
- jupyter
- numpy
- numpy-platforms:-jupyter-notebook
- openai-api
- pandas
- python
- regex
- scikit-learn





Log in or sign up for Devpost to join the conversation.