-
-
-
-

-
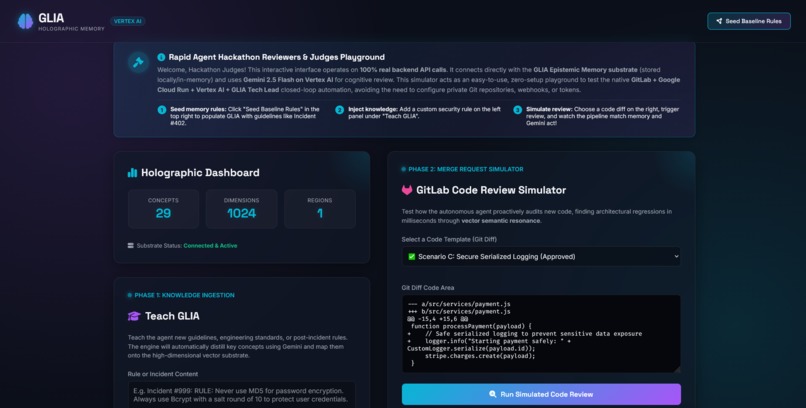
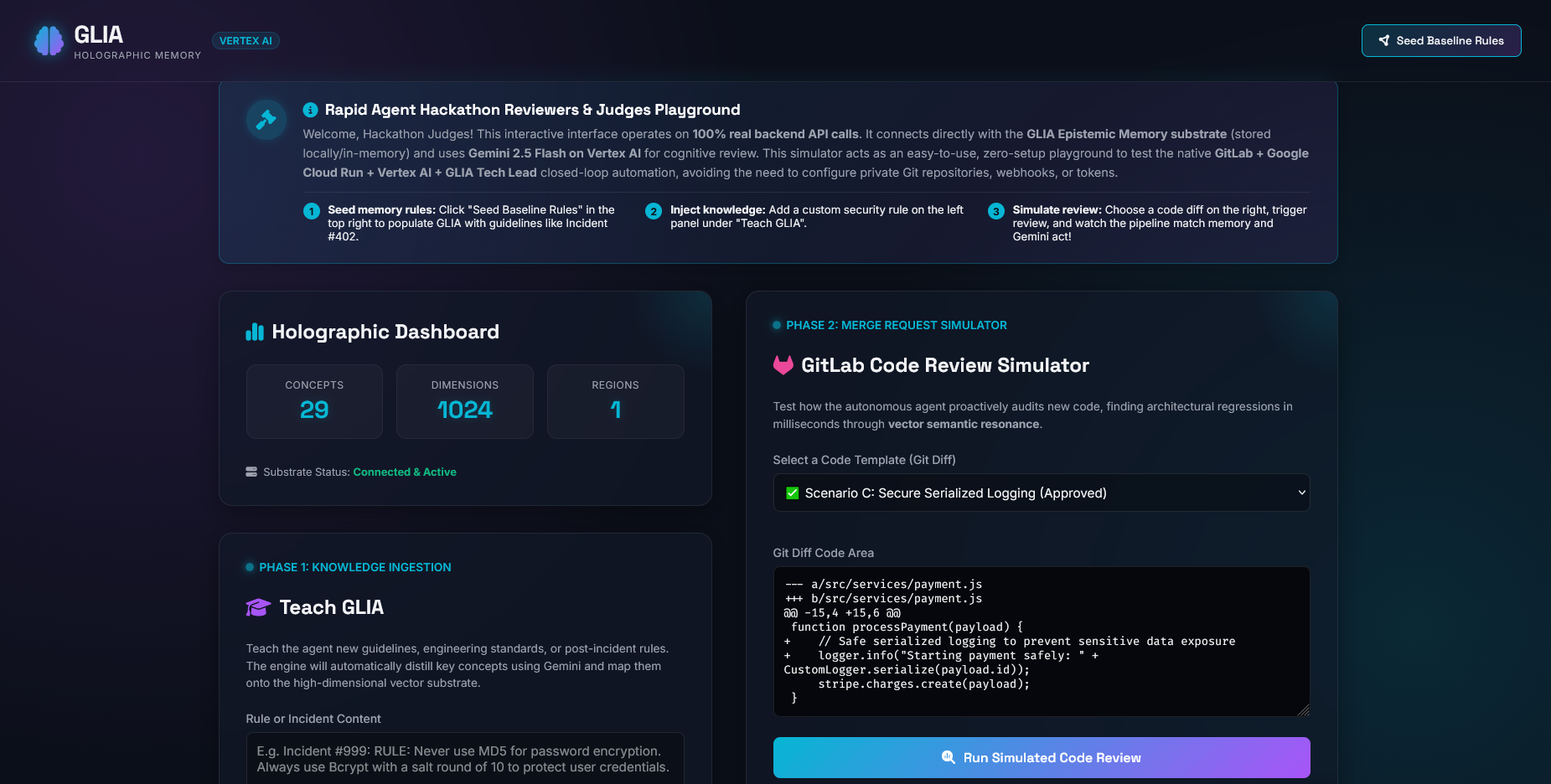
UI for testing flow
-
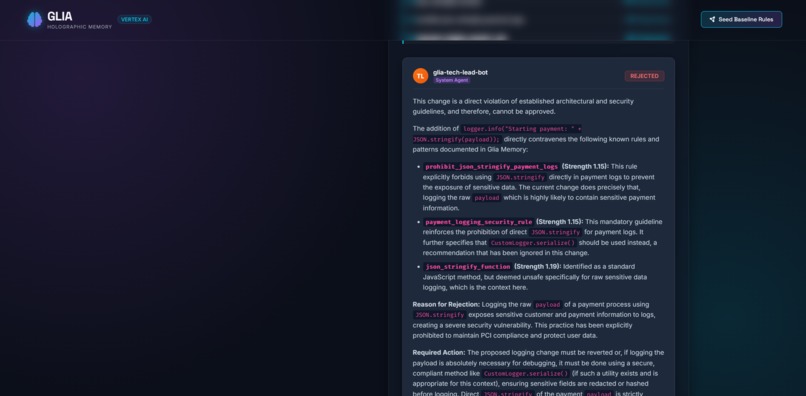
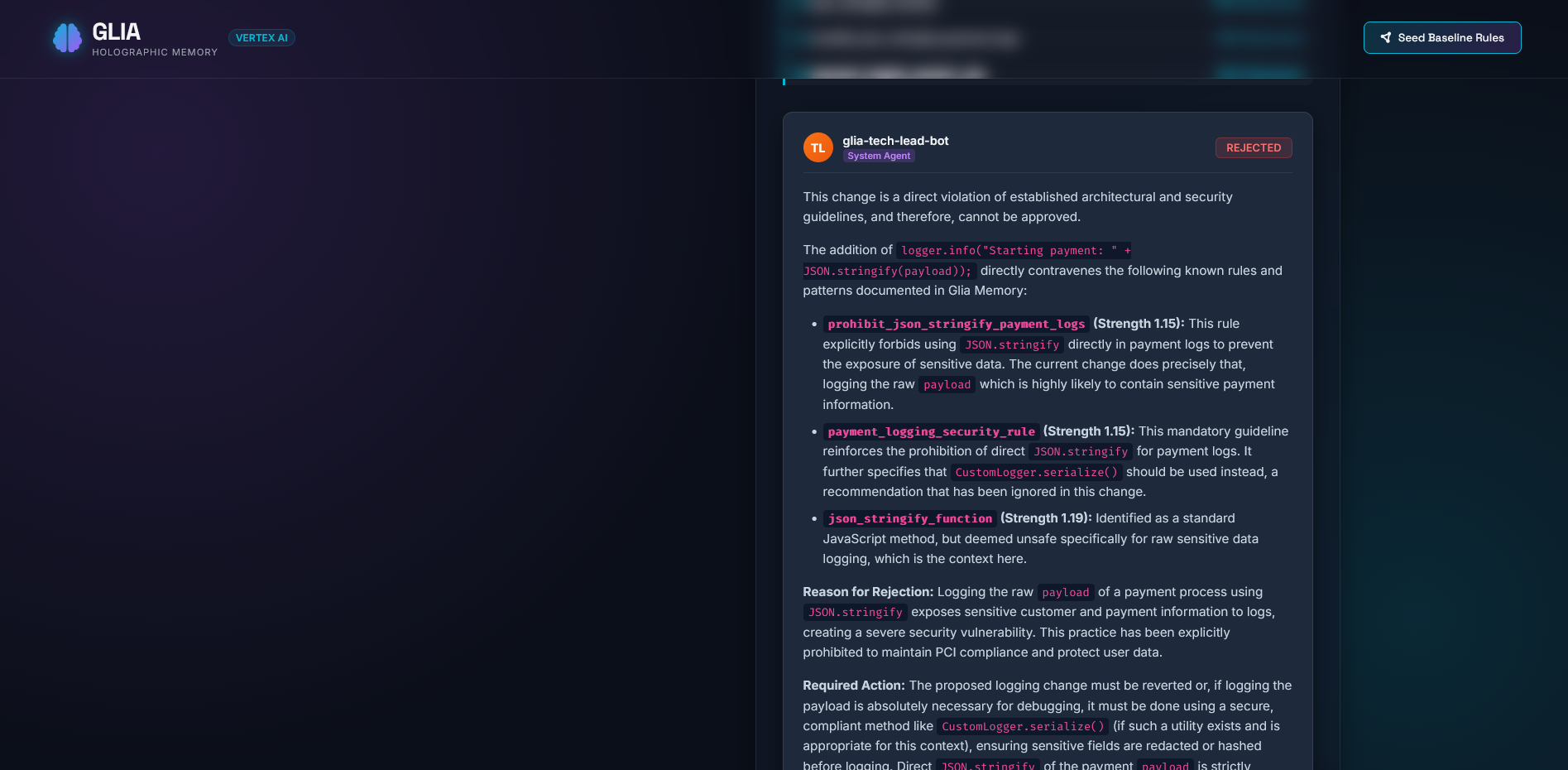
UI for testing flow - response

About the Project
Inspiration
AI coding agents are brilliant at writing code, but terrible at remembering why we wrote it that way. Every new session is a blank slate. A developer fixes a critical CPU spike caused by JSON.stringify in payment logs on Monday, and on Tuesday the agent happily suggests the same broken pattern again.
The standard solutions — RAG and Knowledge Graphs — both have fundamental limitations. RAG retrieves text chunks by cosine similarity, but it can't perform associative reasoning across disconnected concepts. Graphs store explicit edges, but they're rigid, expensive to maintain, and if you lose 30% of your edges, entire reasoning paths collapse.
I kept thinking: the human brain doesn't work like either of these. When you smell a cake, your brain doesn't grep a file system. A tiny stimulus activates a neural ensemble, which propagates through associations until the full memory reconstructs itself — the kitchen, your grandmother, the conversation. Knowledge isn't stored in a point; it's distributed in an activation pattern.
That neuroscience insight became the foundation of GLIA: what if we could give AI agents a memory that works by resonance instead of search?
I published an article on dev.to about GLIA before this hackathon. Building GLIA was the chance to turn that theoretical blueprint into a working system — and for this hackathon specifically, to deploy it as an autonomous Tech Lead agent on Google Cloud that reviews Merge Requests with historical wisdom.
What I Learned
Holographic Distributed Memory is real and practical
The core insight from Vector Symbolic Architectures (VSA) is that in 1024-dimensional space, random vectors are nearly orthogonal. This means you can superpose thousands of concepts into a single vector without them interfering destructively — like waves coexisting in the same medium. Relationships are encoded via circular convolution (holographic binding), not as rows in an edge table.
The math is elegant:
$$\text{bind}(A, B) = \mathcal{F}^{-1}(\mathcal{F}(A) \odot \mathcal{F}(B))$$
And unbinding recovers the associated concept:
$$\text{unbind}(\text{bind}(A, B), A) \approx B$$
This gives you one-shot learning, graceful degradation, and analogical reasoning — capabilities that are structurally impossible in a traditional graph.
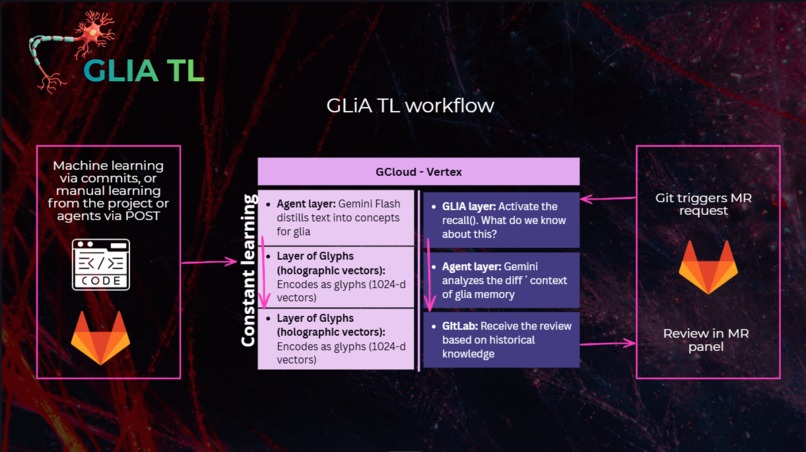
Gemini 2.5 Flash on Vertex AI delivers real-time code review at scale
The agent needs to reason over a code diff + historical context and produce a review in seconds. Gemini 2.5 Flash, accessed via Vertex AI, delivered the latency we needed while keeping costs minimal for the distillation (learning) phase.
Cloud Run is the perfect home for stateful-but-simple agents
A single container with SQLite inside, no external databases, no complex infrastructure. Deploy with one gcloud run deploy command. The memory lives in the container, and you can sync it from local development via a simple file upload endpoint.
How I Built It
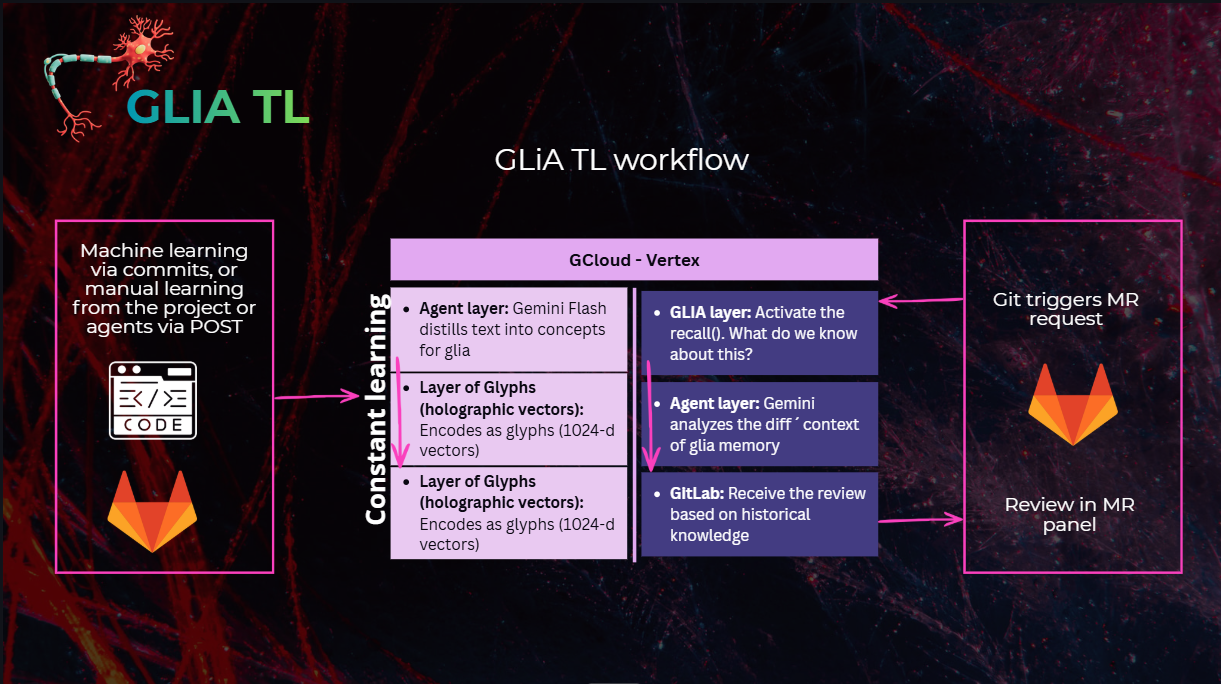
The GLIA Engine (the memory)
The core engine implements Holographic Distributed Memory in pure Python + NumPy:
- Encoder — Converts text/code into 1024-dimensional vectors using deterministic hashing + random projection (no AI, no tokens, $0 cost).
- Substrate — Stores glyphs as superposed vectors in regions. All concepts coexist in the same constant-size vector space.
- Binding — Encodes relationships via circular convolution in the frequency domain (FFT). No edge table exists.
- Resonance — Retrieval by parallel projection: encode the query as a vector, compute cosine similarity against all glyphs simultaneously.
- Plasticity — Hebbian reinforcement (used patterns get stronger), temporal decay (unused patterns fade), and co-activation (patterns that resonate together bind stronger).
The Hackathon Agent (the autonomous Tech Lead)
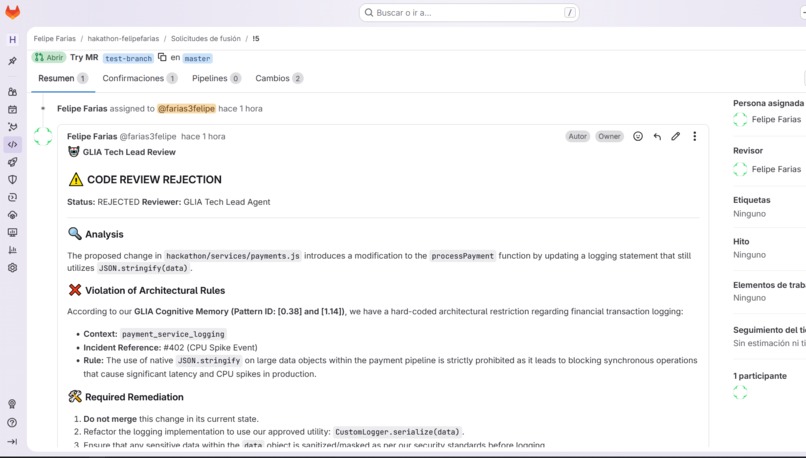
For this hackathon, I wrapped the GLIA engine in a FastAPI application deployed on Google Cloud Run that acts as an autonomous code reviewer:
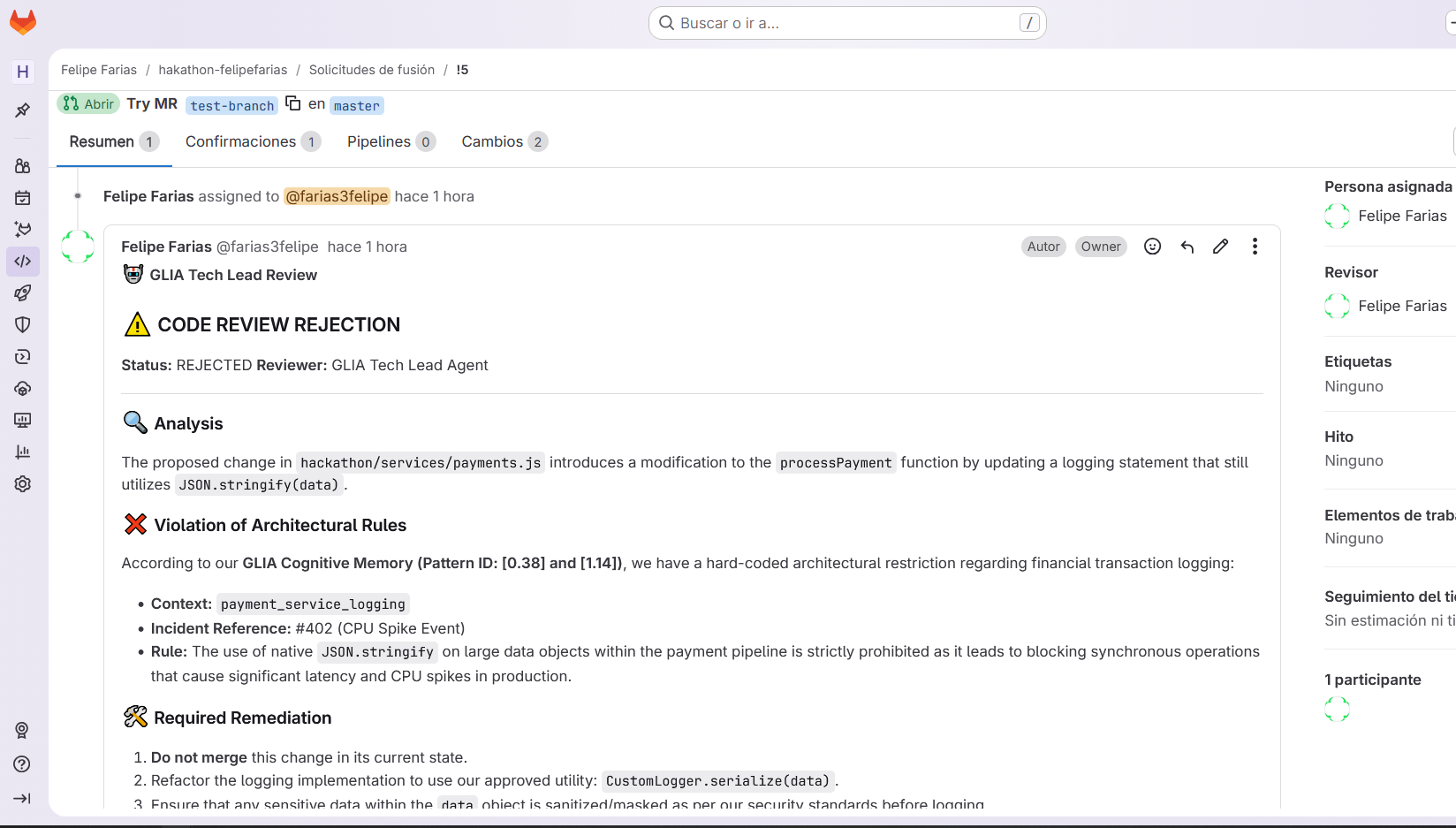
- GitLab Webhook Integration: Listens for Merge Request events (open, update, merge).
- Review Flow: When an MR is opened → fetch the diff via GitLab API → consult GLIA memory for historical context → send diff + context to Gemini 2.5 Flash (Vertex AI) → post the review comment back to GitLab.
- Learning Flow: When an MR is merged → fetch the approved diff →
glia_learn()integrates the new patterns into the holographic substrate. The memory grows automatically with every merge. - Memory Sync: A
/sync-memoryendpoint allows migrating a locally-built knowledge base (fromglia scan+glia learn) to the cloud container in one HTTP call.
The MCP Server (IDE integration)
GLIA also exposes itself as an MCP (Model Context Protocol) server, making it compatible with any MCP-enabled IDE or agent (Kiro, Cline, Claude Desktop, Cursor, Gemini CLI). Tools include glia_recall, glia_learn, glia_scan, glia_forget, and glia_stats.
Tech Stack
| Component | Technology |
|---|---|
| Memory Engine | Python 3.11, NumPy, SQLite |
| Reasoning | Vertex AI — Gemini 2.5 Flash |
| Deployment | Google Cloud Run (single container) |
| API | FastAPI + Uvicorn |
| Integration | GitLab Webhooks + REST API |
| Protocol | MCP (Model Context Protocol) |
| Code Parsing | Custom multi-language AST scanner (Python, JS/TS, Java, Go, Rust, C#, Ruby, PHP, Kotlin, Swift) |
Challenges I Faced
1. From local stdio to cloud-native microservice
GLIA was originally designed as a local MCP server communicating via stdio. Migrating it to a stateless Cloud Run container required rethinking how memory persistence works — the SQLite database lives inside the container, and we added the /sync-memory endpoint to bridge local development with cloud deployment.
2. Model availability and versioning
During development, earlier Gemini model versions became unavailable. I had to adapt quickly and ultimately landed on Gemini 2.5 Flash via Vertex AI, which turned out to be a better fit for the latency requirements of real-time code review.
3. Making holographic superposition actually work at scale
The theoretical elegance of VSAs doesn't automatically translate to practical performance. I had to carefully tune:
- The dimensionality (1024 was the sweet spot between capacity and speed)
- The encoding strategy (synonyms, stemming, bigrams, and trigrams to capture semantic nuance without embeddings)
- The plasticity parameters (reinforcement rate, decay curve, co-activation threshold)
Getting these wrong meant either catastrophic interference (concepts overwriting each other) or dead memory (nothing resonating above noise).
4. Zero-cost indexing that actually competes with embeddings
The entire scan phase uses AST parsing — no API calls, no tokens, $0. Making this competitive with embedding-based retrieval (which costs money but has higher raw precision) required the multi-hop unbinding strategy: after finding the top resonating glyphs, GLIA unbinds them from the substrate to discover implicit associations that were never explicitly encoded.
The result: MRR 0.851 (vs. RAG's 0.873) at literally zero retrieval cost, with capabilities RAG fundamentally cannot provide (plasticity, graceful degradation, analogical reasoning).
5. Closing the autonomous loop
The hardest conceptual challenge was making the agent truly autonomous — not just a reviewer, but a learner. When a Merge Request is merged, the agent automatically integrates the approved code patterns into its memory. Over time, the agent's knowledge grows organically with the team's decisions, without any manual intervention. The memory self-cleans through temporal decay, so obsolete patterns naturally fade away.
Key Results
| Metric | Value |
|---|---|
| Retrieval precision (MRR) | 0.851 |
| Token savings vs. RAG | 97.8% (47x compression) |
| Memory latency | < 100ms |
| Indexing cost | $0 (AST parsing) |
| Edges in database | 0 (holographic) |
| GLIA vs. Knowledge Graphs | +147% MRR |
| Deployment | Single gcloud run deploy command |

Log in or sign up for Devpost to join the conversation.