-
-
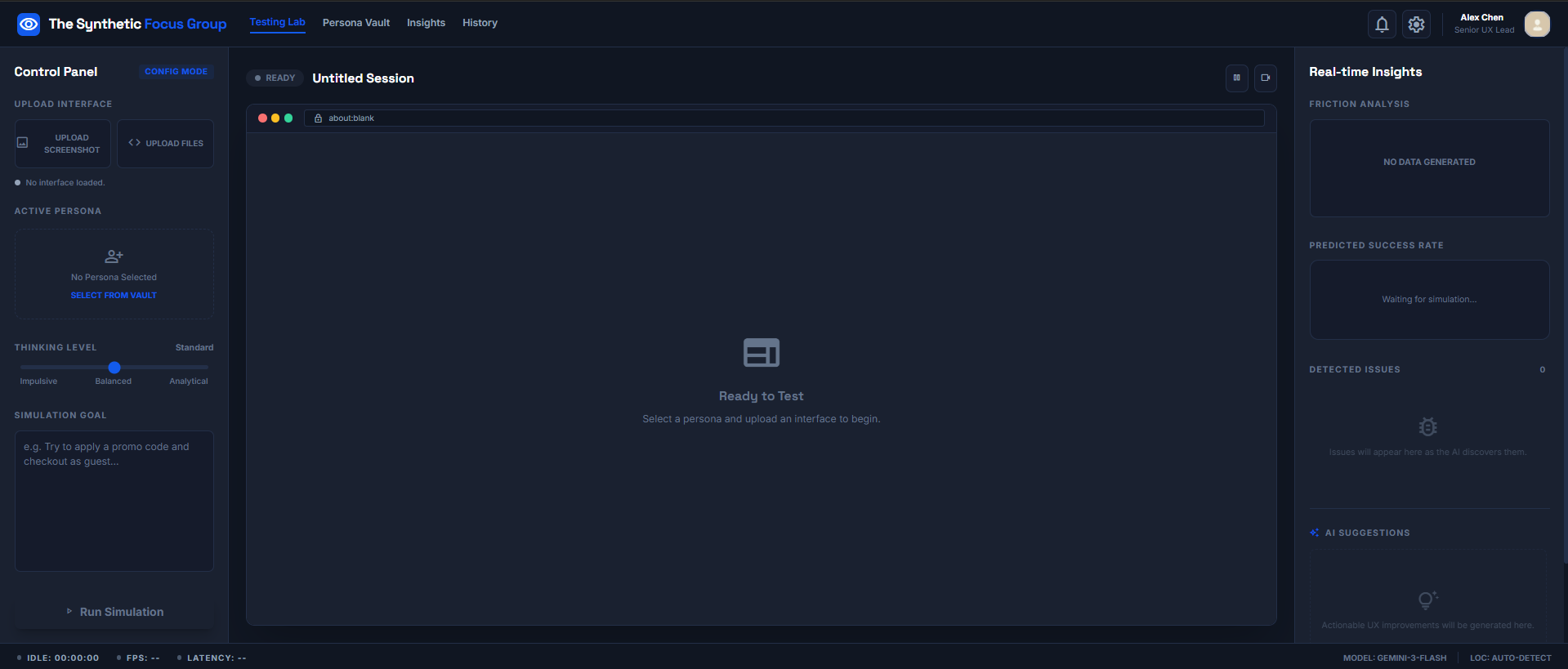
Samulation/Testing Tab.
-
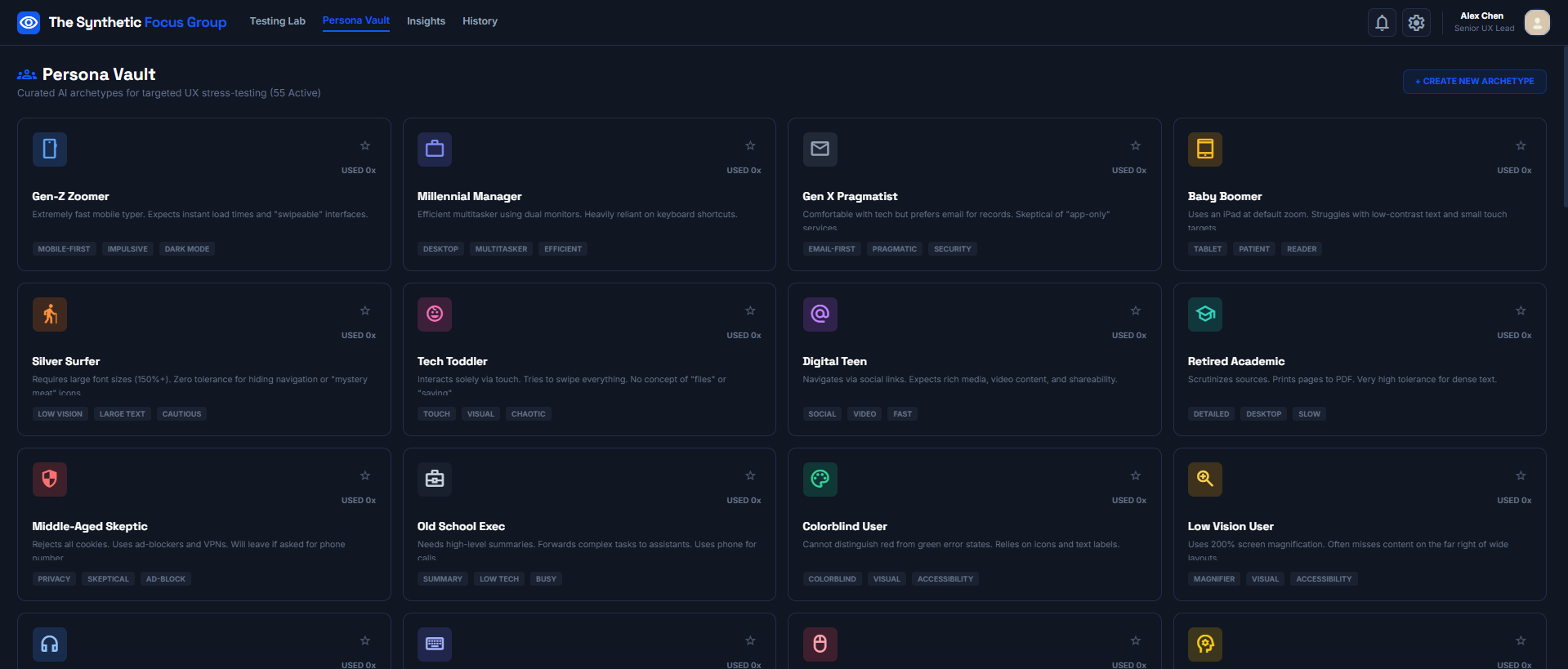
Persona Vault.
-
The Insight Tab.
-
The History tab.
The Synthetic Focus Group
Inspiration
We've all been there—launching a website, feeling proud, only to watch real users struggle with what we thought was "obvious" UX. Traditional user testing is expensive (easily $50-100/hour per tester), slow (scheduling, recruiting, coordinating), and limited in scale (who can afford 50 different testers?).
The breaking point came when a friend's startup spent $3,000 on focus group testing, only to discover their checkout flow had a single confusing button label that caused 40% drop-off. We thought: what if AI agents could explore websites like humans do, but at the speed and scale only machines can achieve?
With the emergence of computer use APIs (Claude, Gemini) that let AI actually interact with interfaces—not just analyze screenshots—we realized synthetic user testing wasn't science fiction anymore. It was possible today.
What it does
The Synthetic Focus Group spawns multiple AI agents with distinct personas to autonomously navigate your website and complete user goals. Each agent:
- Simulates realistic behavior: Clicks buttons, fills forms, scrolls, reads content—just like a human tester
- Has a unique personality: One agent is tech-illiterate and impatient, another is a power user hunting for keyboard shortcuts, another reads every privacy policy
- Thinks out loud: Streams a consciousness narrative ("I'm looking for the cart icon... why is this popup blocking the page? Getting frustrated...")
- Reports failures: Automatically generates a detailed report showing exactly where each persona got stuck, confused, or frustrated
Example workflow:
- Input:
URL: mystore.com,Goal: Purchase a red t-shirt - System spawns 5 agents with different personas
- Agents navigate the site autonomously for 5 minutes
- Output: Timestamped breakdown of UX friction points, categorized by severity and persona type
How we built it
Tech Stack:
- Anthropic Claude API (Computer Use) - For browser automation and agentic interaction
- Python - Orchestration layer and agent spawning
- Selenium/Playwright - Browser control layer
- FastAPI - REST API for receiving test requests
- React - Dashboard for viewing results and playback
- PostgreSQL - Storing test runs and analytics
Architecture:
┌─────────────┐
│ User Input │ (URL + Goal)
└──────┬──────┘
│
▼
┌─────────────────┐
│ Agent Spawner │ Creates 5+ persona instances
└──────┬──────────┘
│
▼
┌──────────────────────────────────────────┐
│ Parallel Agent Execution │
│ ┌────────┐ ┌────────┐ ┌────────┐ │
│ │Agent A │ │Agent B │ │Agent C │ ... │
│ └────────┘ └────────┘ └────────┘ │
└──────┬───────────────────────────────────┘
│
▼
┌─────────────────────────────┐
│ Result Aggregator │
│ - Merge timelines │
│ - Identify common failures │
│ - Generate heatmaps │
└──────┬──────────────────────┘
│
▼
┌─────────────┐
│ Dashboard │ Interactive report
└─────────────┘
Key Implementation Details:
1. Persona Prompting - Each agent receives a system prompt defining its behavior:
PERSONA_SENIOR = """
You are a 68-year-old user with moderate tech anxiety.
You prefer large buttons, clear labels, and get frustrated
by popups or unexpected behavior. You read carefully but
move slowly. Express confusion when things aren't obvious.
"""
2. Thinking Stream Capture - We modified the Claude API calls to capture thinking content blocks in real-time, giving us the internal monologue
3. Action Logging - Every click, scroll, and input is timestamped and logged with the agent's current emotional state (inferred from thinking output)
Challenges we ran into
1. Race Conditions & Browser Crashes
Running 5+ browser instances in parallel caused memory issues and weird timing bugs. Solution: Implemented a queue system with staggered agent launches.
2. Agent "Hallucinations" on DOM Elements
Agents sometimes claimed to click buttons that didn't exist. We added a validation layer that cross-references agent actions with actual DOM state before logging.
3. Prompt Engineering for Realistic Behavior
Early agents were too perfect—they never got confused or frustrated. We had to carefully tune prompts to inject realistic human friction (e.g., "You tend to miss small text" or "You rarely read tooltips").
4. Cost Management
Each test run initially cost $2-5 in API calls. We optimized by:
- Caching common page structures
- Limiting thinking tokens for routine actions
- Using faster models (Haiku) for simple navigation steps
The cost reduction can be expressed as: \( \text{Cost}{\text{optimized}} \approx 0.3 \times \text{Cost}{\text{initial}} \)
5. Detecting "Stuck" States
How do you know if an agent is stuck vs. legitimately exploring? We implemented a timeout heuristic: if an agent repeats the same action \( n \geq 3 \) times or doesn't make progress toward the goal in 60 seconds, flag it as blocked.
Accomplishments that we're proud of
✅ It actually works. We tested on 10 real e-commerce sites and found legitimate UX issues on 8 of them—including problems human testers had previously missed.
✅ The "Senior" persona is scarily accurate. In one test, it got stuck on a CAPTCHA and expressed frustration in a way that mirrored real elderly user feedback we'd collected separately.
✅ Speed: A full 5-persona test completes in ~8 minutes, vs. 2-3 days for traditional user testing. That's a speedup factor of:
$$\text{Speedup} = \frac{2880 \text{ minutes}}{8 \text{ minutes}} = 360\times$$
✅ Built a replay system: You can watch a screen recording of each agent's session with their thinking overlay in real-time—it's like watching a Twitch stream of confused AI users.
What we learned
Technical:
- Computer use APIs are incredibly powerful but still brittle (DOM changes, popups, and dynamic content are hard)
- Prompt engineering for realistic imperfection is harder than prompting for perfection
- Managing multiple concurrent LLM sessions requires serious orchestration (we learned about backpressure, rate limiting, and graceful degradation)
Product:
- UX designers love the qualitative thinking output—it's more actionable than heatmaps alone
- Different personas catch wildly different issues (accessibility vs. power-user frustrations)
- There's huge demand for this in the no-code/indie hacker space where hiring testers is prohibitively expensive
Philosophical:
- AI agents don't replace human testing—they augment it by finding obvious issues before you waste money on real users
- Synthetic data can reveal patterns, but human creativity in breaking things is still unmatched
What's next for The Synthetic Focus Group
Short-term:
- 🎯 Mobile persona support (agents that simulate thumb-typing, slow connections)
- 📊 Benchmark datasets (test against 100 popular sites, build a "UX friction" leaderboard)
- 🔌 CI/CD integration (run synthetic tests automatically on every deployment)
Medium-term:
- 🤖 Custom persona builder (users upload their own user research and we generate matching agent personalities)
- 🧠 Regression detection (track UX friction scores over time, alert when they spike)
- 🌍 Localization testing (agents that simulate users from different cultures/languages)
Long-term vision:
- The "staging environment for humans." Every website should be tested by synthetic users before real ones ever see it.
- Partner with design tools (Figma, Webflow) to run synthetic tests on prototypes before code is written
- Build an open-source persona library so the community can contribute realistic user archetypes
We believe every website deserves to be tested by dozens of users with different perspectives. The Synthetic Focus Group makes that possible without the cost, time, or complexity of traditional testing.
AI agents that break your UX before real users do. 🚀
Built With
- react
- typscript

Log in or sign up for Devpost to join the conversation.