-
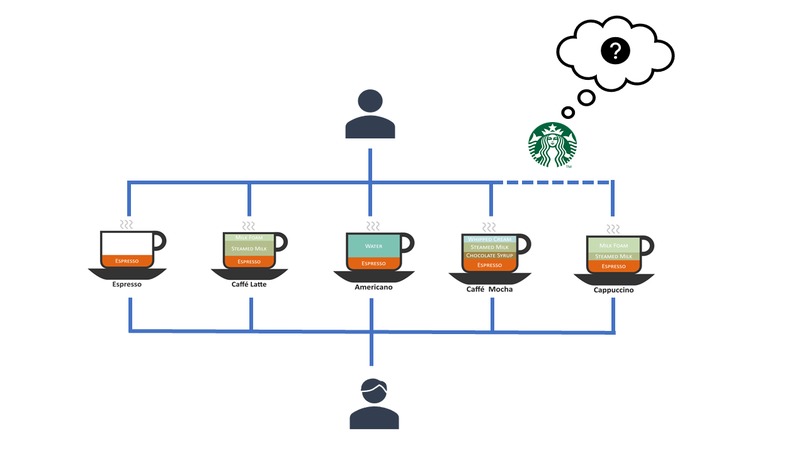
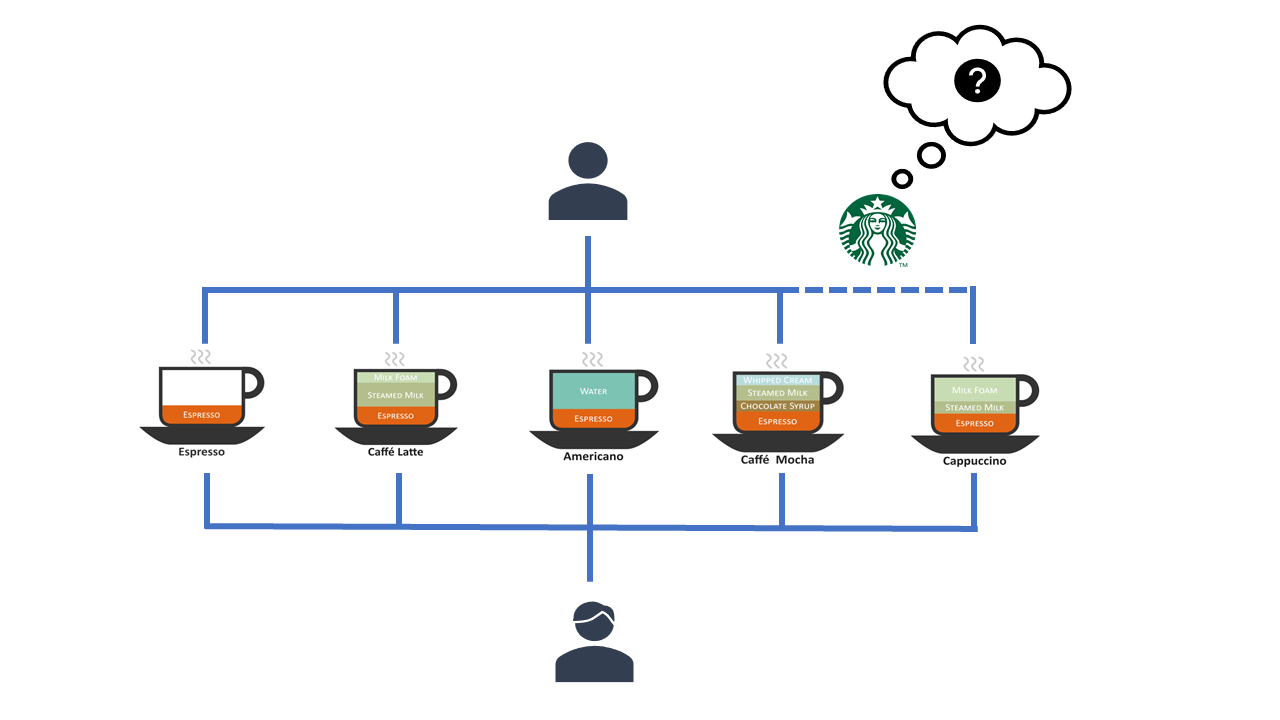
hmm... What to recommend?
-
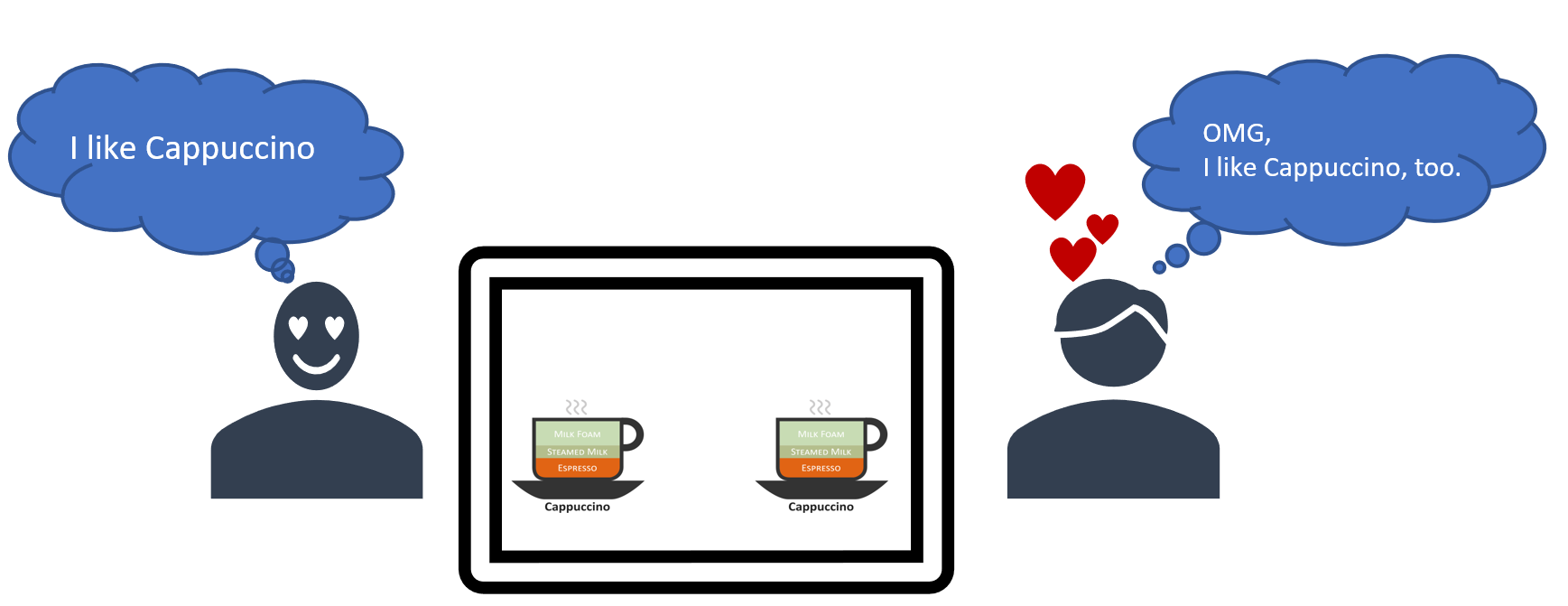
Perfect recommendion!
-
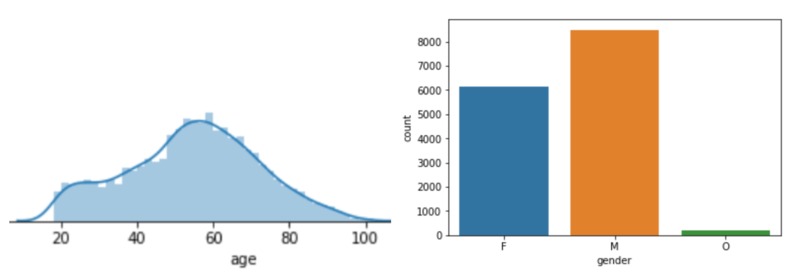
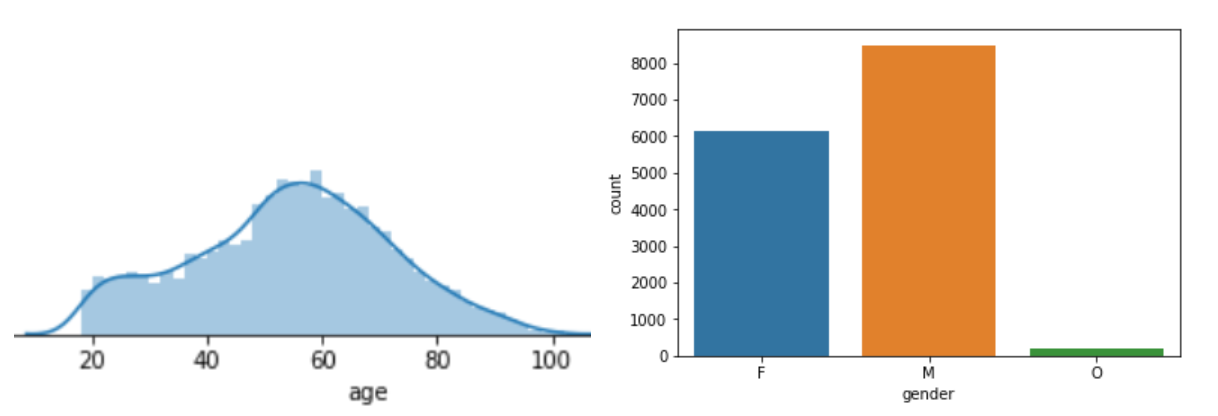
exploratory data analysis
-
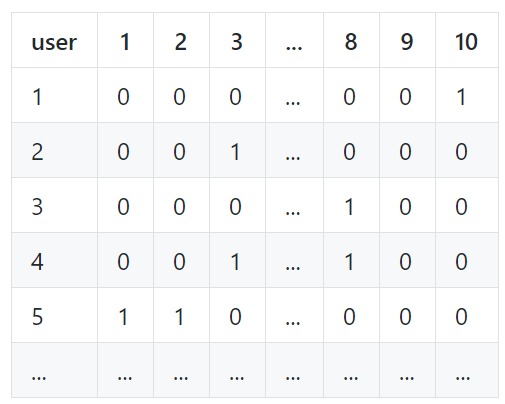
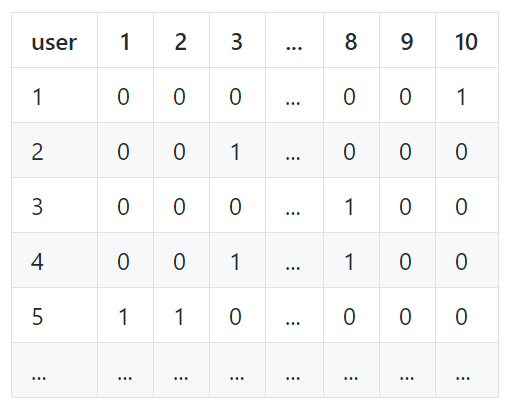
Essentially we ended up learning the components of the following matrix (more in the Readme)
-
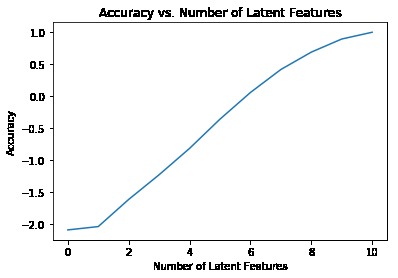
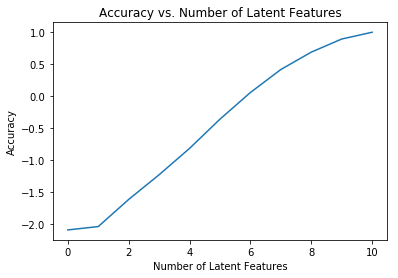
Minimize the prediction error and increasing the accuracy of SVD
-

Final output (more in the Readme)

Inspiration
The inspiration came from the booming industry of recommender systems that have the customer in the center of the business.
What it does
The goal of the project is to build a user-based recommendation system that identifies users that are similar to each other and makes recommendations, excluding the offers that have already been received or viewed without an interaction.
How I built it
I used singular value decomposition (SVD), the most common method in collaborative filtering where it relies on the past user-item data. In the case of missing recommendations for certain users, I found similar users based on their dot product and recommend the offers accordingly. The expected solution is to recommend at least one offer to the 1700 users that we have in the dataset, as well as evaluate how well the model works.
Challenges I ran into
Data cleaning was the main challenge in the project. I have started the cleaning process by mapping the cyphered ID's and broke down certain columns into multiple columns based on the information they contain.
Gaining a deep understanding of what SVD does under the hood was another interesting challenge that made me go deeper into math and have a lot of fun.
Accomplishments that I'm proud of
After cleaning the dataset and doing some exploratory data analysis, I have used SVD to make recommendations for the 1700 customers.
I'm proud that I built a model that can be used as a base for similar recommendation systems.
What I learned
I have learned a lot about how different recommender systems work, as well as how to effectively clean and combine JSON data from multiple sources.
What's next for The Starbucks Project
This is a good start that can be used for creating a recommendation engine and integrating it into the Starbucks app. To make the recommendations more relevant for the users, we might as well consider more demographic data about the customers to build a more complex engine. It is also essential to consider factors such as relevance, novelty, serendipity, and increased diversity to increase the quality of the recommendations. Since the dataset includes only 10 offers, it would be interesting to see how the model behaves when a larger dataset is provided.
For a company like Starbucks, it's also crucial to have a scalable solution, and as such, the cleaning process of the dataset should be optimized, and the number of k latent factors might be reduced to decrease the computational complexity.
A logical next step should be A/B testing to see how successful the model behaves in reality.

Log in or sign up for Devpost to join the conversation.