-
-
Artifact Registry
-
Cloud Run
-
Firebase Auth
-
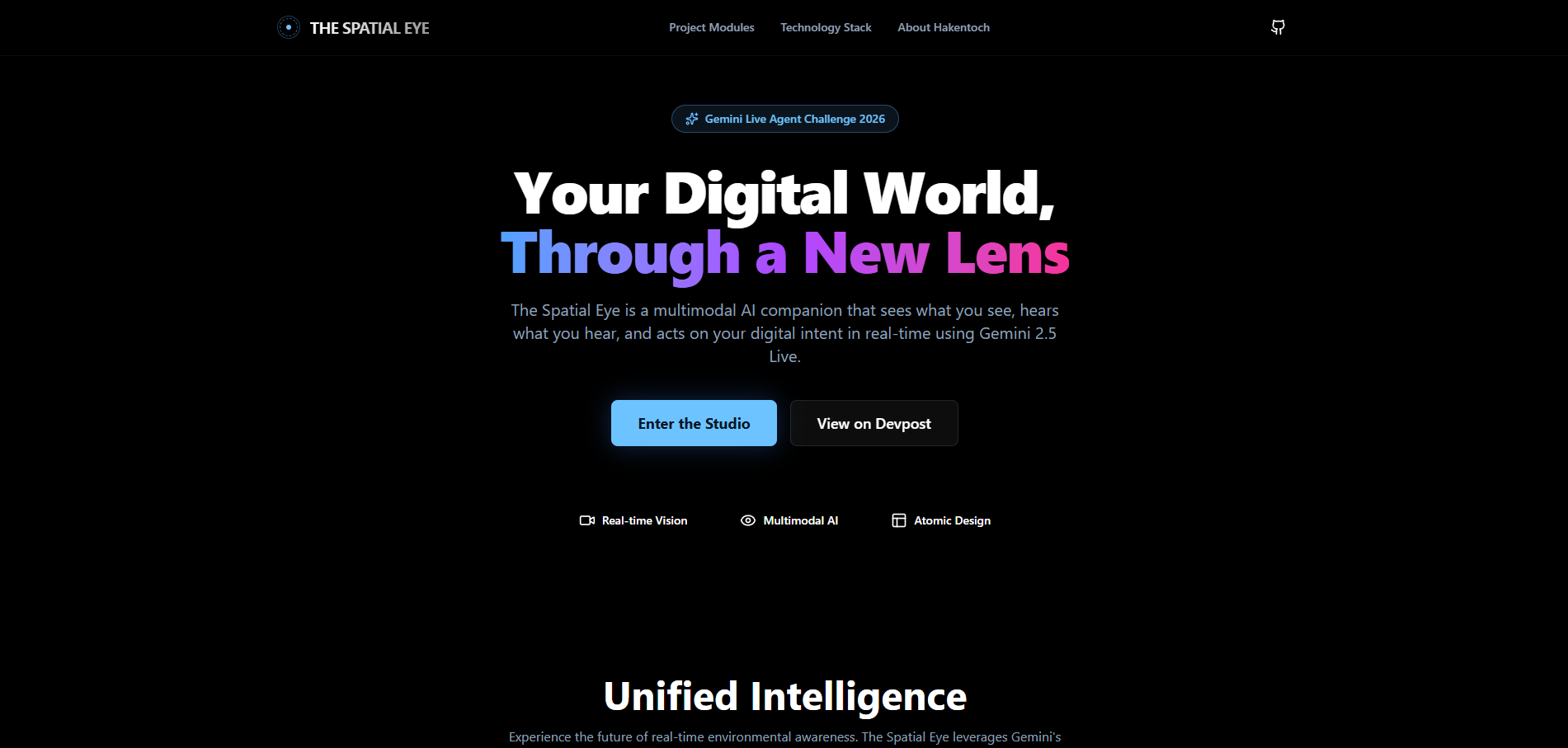
The landing page
Inspiration
Modern troubleshooting in complex environments like server racks or car engines often leaves users overwhelmed by purely verbal instructions. We wanted to build a "cognitive link" that allows an AI to not just hear you, but actually see your reality and visually interact with it in real-time. The release of the Gemini 2.5 Live API provided the perfect foundation to turn this vision into a tool that acts as a second pair of eyes for technical and hands-on tasks.
What it does
The Spatial Eye uses the Gemini 2.5 Live API to bridge the gap between physical reality and AI intelligence. Serving as an advanced visual and conversational agent, it provides a Spatial Live experience where the AI "looks" through your camera, visually identifies, and dynamically highlights real-world objects directly on the live feed using surgical precision, all while having a natural, interruptible voice conversation with you.
How we built it
The project is built as a high-performance Next.js 15 application backed by a Python FastAPI server, designed for sub-second multimodal loops.
- Live Core: We implemented a Secure WebSocket architecture (WSS) that streams audio and video frames directly from the frontend to securely route through our Python backend to the Gemini 2.5 Live API.
- Spatial Grounding: By instructing the AI to utilize a function-calling tool (
track_and_highlight) and parsing its normalized coordinate outputs (0-1000 range), the frontend dynamically renders animated SVG highlight circles over real-world objects in real-time. - Infrastructure: The backend is containerized and deployed on Google Cloud Run, leveraging Firebase for authentication and session management, using Terraform/Pulumi for Infrastructure as Code to ensure a scalable and secure (Bring-Your-Own-Key) environment.
Challenges we ran into
- Prompt Engineering & Grounding: Forcing the AI to reliably act as a spatial reasoning engine—outputting precise coordinate tool calls instead of just conversational text—required rigorous system instruction tuning.
- Multimodal Synchronization: Coordinating simultaneous streams of audio, video, and incoming tool-call responses required complex state management to prevent UI lag.
- Coordinate Mapping: Converting normalized AI coordinates into responsive, pixel-perfect SVG overlays across different device aspect ratios (mobile vs desktop) was a significant geometric challenge.
- Mitigating Spatial Hallucinations: As physical objects moved around the camera frame during a continuous live session, the AI would sometimes hallucinate based on stale context. We had to carefully manage session continuity and the flow of video frames to force the model to prioritize the most recent reality over past object positions.
- WebSocket Lifecycle Management: Adapting to the new Gemini Multimodal Live API meant building custom logic to manage secure, bi-directional WebSocket connections, ephemeral authentication tokens, and real-time payload throttling.
- Error Resilience: We built a custom "Named Model Toast" system to provide clear, human-readable feedback when the model hits rate limits or billing issues, rather than opaque WebSocket crashes.
Accomplishments that we're proud of
- Seamless Visual Integration: Achieving a real-time "seeing" loop where the AI can identify and point to physical objects with minimal latency, breaking the paradigm of traditional text/voice-only chat.
- Secure Agent Architecture: Creating a system that safely acts as a broker for the Live API by using backend-validated ephemeral JWTs, ensuring the user's API key is never exposed.
- Automated Cloud Native Deployment: Implementing a robust architecture ready for Google Cloud Run deployment using Terraform/Pulumi tools.
What we learned
Building this project taught us the nuances of agentic workflows, specifically how to handle "function-calling tool use" seamlessly within a live audio/video streaming context. We gained deep experience in designing secure WSS proxy architectures for real-time AI services on Google Cloud and managing ephemeral authentication tokens to protect user API keys while maintaining a "Bring Your Own Key" architecture.
What's next for The Spatial Eye
Future developments include expanding the "Spatial Live" mode to support action execution—connecting spatial detection to home automation and industrial IoT control loops. Beyond that, we plan to fully enable two additional multimodal features currently in research: Creative Storyteller (transforming physical objects into active narratives) and IT Architecture (generating interactive architecture diagrams from live voice brainstorming sessions).
Built With
- antigravity
- biome
- bun
- cloudrun
- docker
- fastapi
- firebase
- framemotion
- gcp
- gemini2.5liveapi
- next.js
- python
- react
- ruff
- tailwind
- terraform
- typescript








Log in or sign up for Devpost to join the conversation.