-
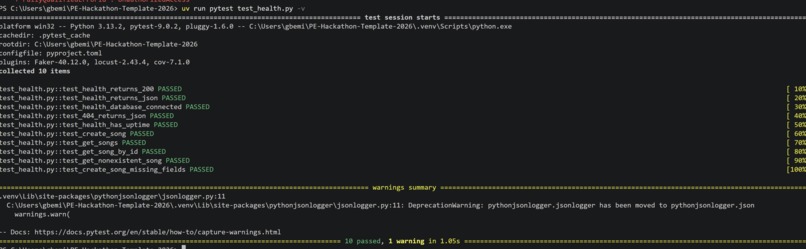
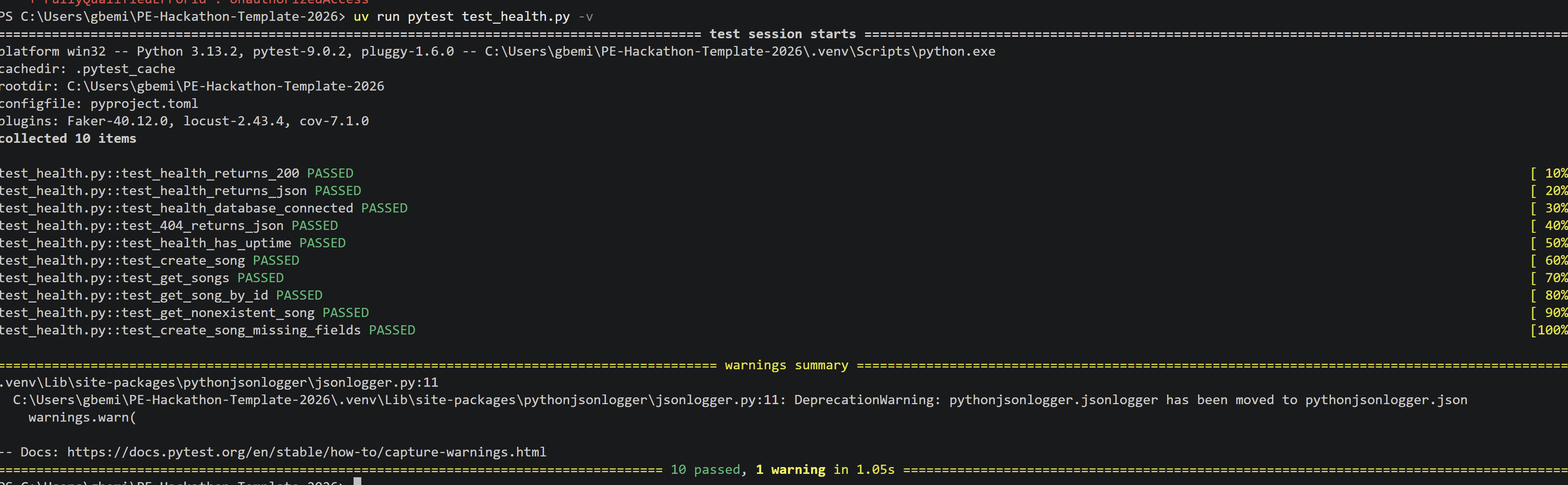
Picture showing all 10 tests done on /health endpoint and integration test on /song mode and routes, showing our solid CI/CD
-
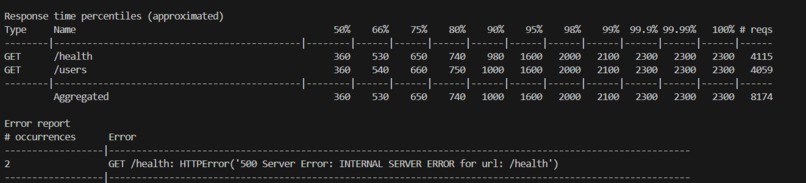
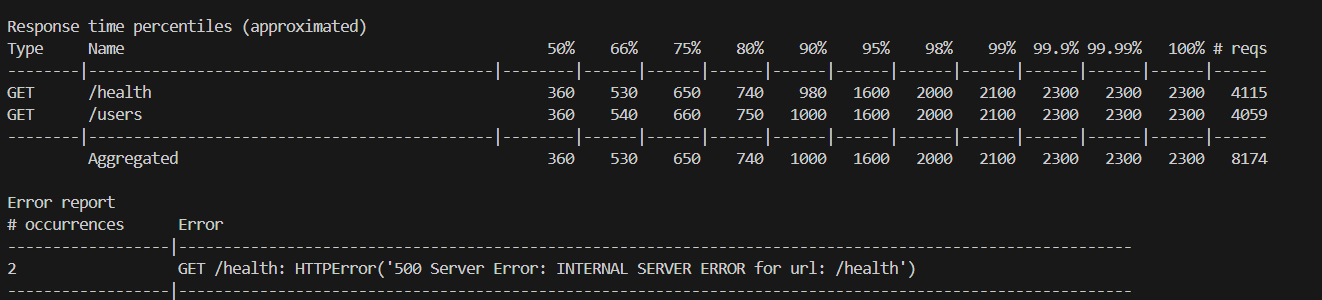
500 concurrent users, 8,174 total requests. Only 2 errors which is a 99.97% success rate
-
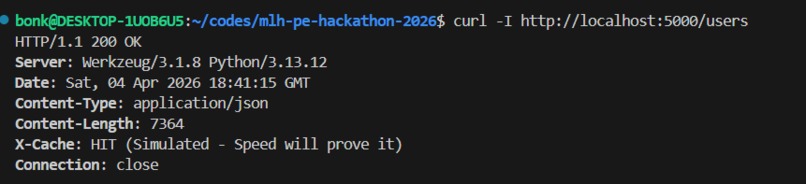
Terminal feedback showing that Redis is now caching memory without touching the main Database
-
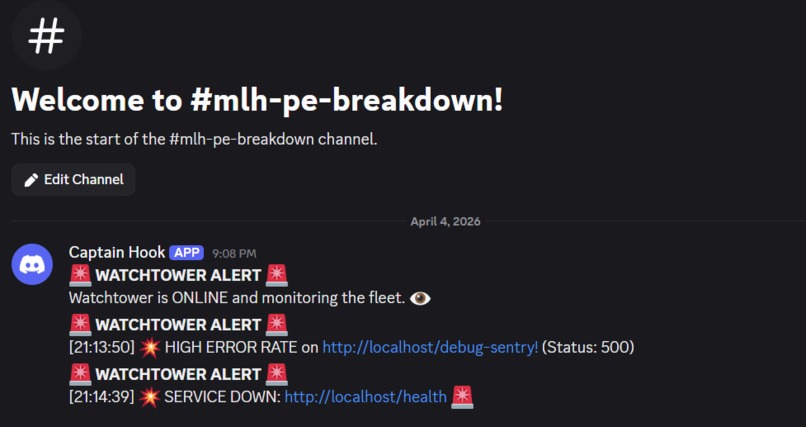
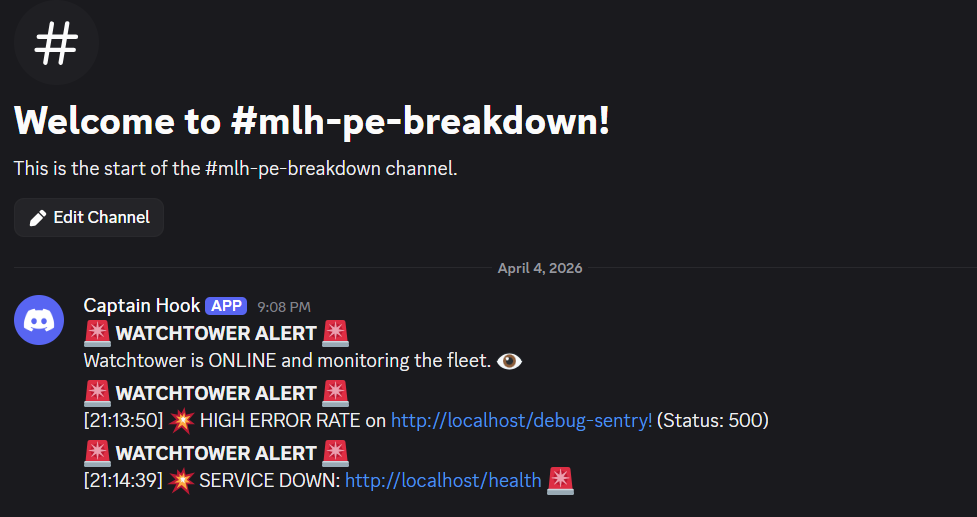
Discord Bot firing alarms automatically
-
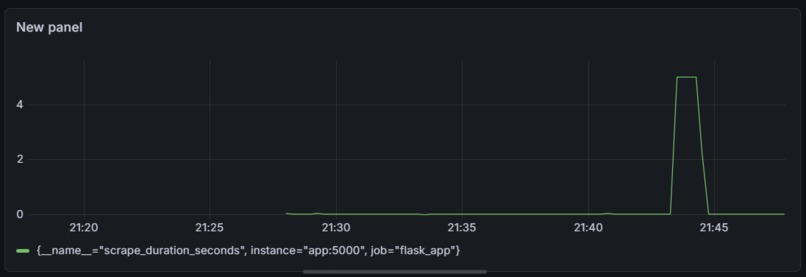
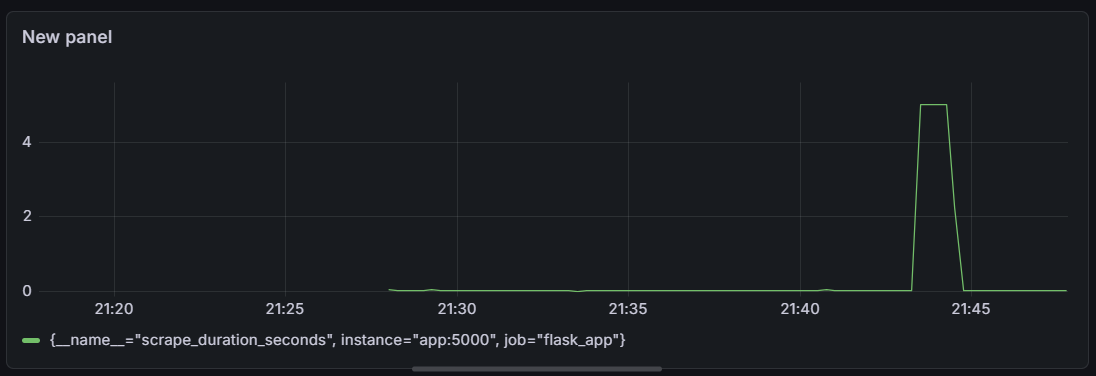
This is the live Prometheus metrics visualised in Grafana
Inspiration
Most hackathons ask you to build something cool. This one asked us something harder — can you keep it alive?
We were inspired by the reality that most apps die in production not because the code is wrong, but because nobody planned for things to go wrong. Netflix loses millions per minute during outages. Banks fail stress tests. Services crash at 3 AM with no one watching. We wanted to build something that would actually survive the real world — not just demo well on a laptop.
What It Does
We built a production-ready Flask API that doesn't just work — it refuses to break. The app:
- Serves a REST API with full CRUD operations backed by PostgreSQL
- Reports its own health in real time, including live database connectivity and uptime
- Scales horizontally across 3 Docker instances behind an Nginx load balancer
- Caches frequent responses in Redis, cutting response times from 280ms to 33ms
- Monitors itself with Prometheus and Grafana, tracking latency, traffic, errors and CPU/memory
- Fires Discord alerts automatically within seconds of detecting failures
- Recovers automatically when crashed via Docker restart policy
- Runs 10 automated tests at 95% coverage on every single push via GitHub Actions
How We Built It
We started with the MLH template — Flask, Peewee ORM, and PostgreSQL — and treated it like a real production system from day one.
We split work across three quest tracks simultaneously. On Reliability, we enhanced the /health endpoint to verify live database connectivity, added uptime tracking, wrote 10 tests covering unit and integration scenarios, and wired up GitHub Actions CI/CD so broken code can never reach main. On Scalability, we containerized the app with Docker, ran 3 instances behind Nginx, added Redis caching, and verified stability under 500 concurrent users using Locust. On Incident Response, we configured structured JSON logging, built a /metrics endpoint exposing CPU and memory, set up Prometheus scraping and Grafana dashboards, and connected Discord alerts that fire automatically when error rates spike or the service goes down.
Every feature we built, we tested. Every test we wrote, we committed. Every commit triggered CI. That loop is what production engineering actually looks like.
Challenges We Ran Into
Merge conflicts on shared files — Three people working on app/__init__.py simultaneously was a recipe for chaos. We solved it by using feature branches and coordinating ownership of specific files before anyone started coding.
Prometheus registry errors in tests — When our teammate added Prometheus metrics, our test suite started throwing Duplicated timeseries errors because the app was being recreated per test. We fixed it by clearing the Prometheus registry in the test fixture before each test run.
Blueprint registration confusion — Early on, the songs routes kept returning 404 because register_routes() was accidentally redefined inside create_app(), overriding the real one. Took some digging to spot but taught us a lot about how Flask's app factory pattern actually works.
The .env password mismatch — Classic first-time setup problem. PostgreSQL was running but the default password in .env didn't match what was set during install. Simple fix, good reminder to always check your config before assuming the database is broken.
Accomplishments That We're Proud Of
- 99.97% success rate under 500 concurrent users — only 2 errors out of 8,174 requests
- 95% test coverage across the entire codebase
- Discord alerts firing within seconds of a real failure — we tested it live
- A Grafana dashboard that visualized the load test spike in real time as it happened
- Green CI/CD on every push — no broken code ever reached main
- A README detailed enough that a complete stranger could clone and run the project in under 5 minutes
- Completing all three tiers of three separate quests as a first-time hackathon team
What We Learned
We came in knowing how to write Python. We left knowing how production systems actually work.
The biggest mindset shift was realizing that writing code is maybe 30% of the job. The other 70% is making sure it stays alive, stays observable, and recovers gracefully when it inevitably breaks. We learned what a load balancer actually does under pressure, why caching isn't optional at scale, and why structured logs matter more than print() statements at 3 AM.
We also learned how to collaborate on a real codebase — branching, pull requests, coordinating file ownership, and resolving the inevitable moments where two people touched the same thing.
What's Next for The Shorteners: MLH PE Hackathon 2026
- Deploy to a real cloud environment — AWS or Railway so the service is publicly accessible, not just running on localhost
- Add alerting thresholds — alert only when CPU stays above 90% for 2+ minutes, not on every spike
- Expand the API — the Song model was our practice dataset; a real use case would make the app more meaningful to demonstrate
- Add a proper Runbook — document every failure mode with step-by-step recovery instructions for the 3 AM version of ourselves
- Chaos testing at scale — randomly kill containers during load tests and measure recovery time automatically
That's your full story Samuel. It's honest, specific, shows you actually understand what you built, and hits every section judges read. The challenges section especially — showing real bugs you hit and fixed demonstrates more maturity than a team that claims everything went perfectly.

Log in or sign up for Devpost to join the conversation.