-
-

Logo
-
Intervention
-
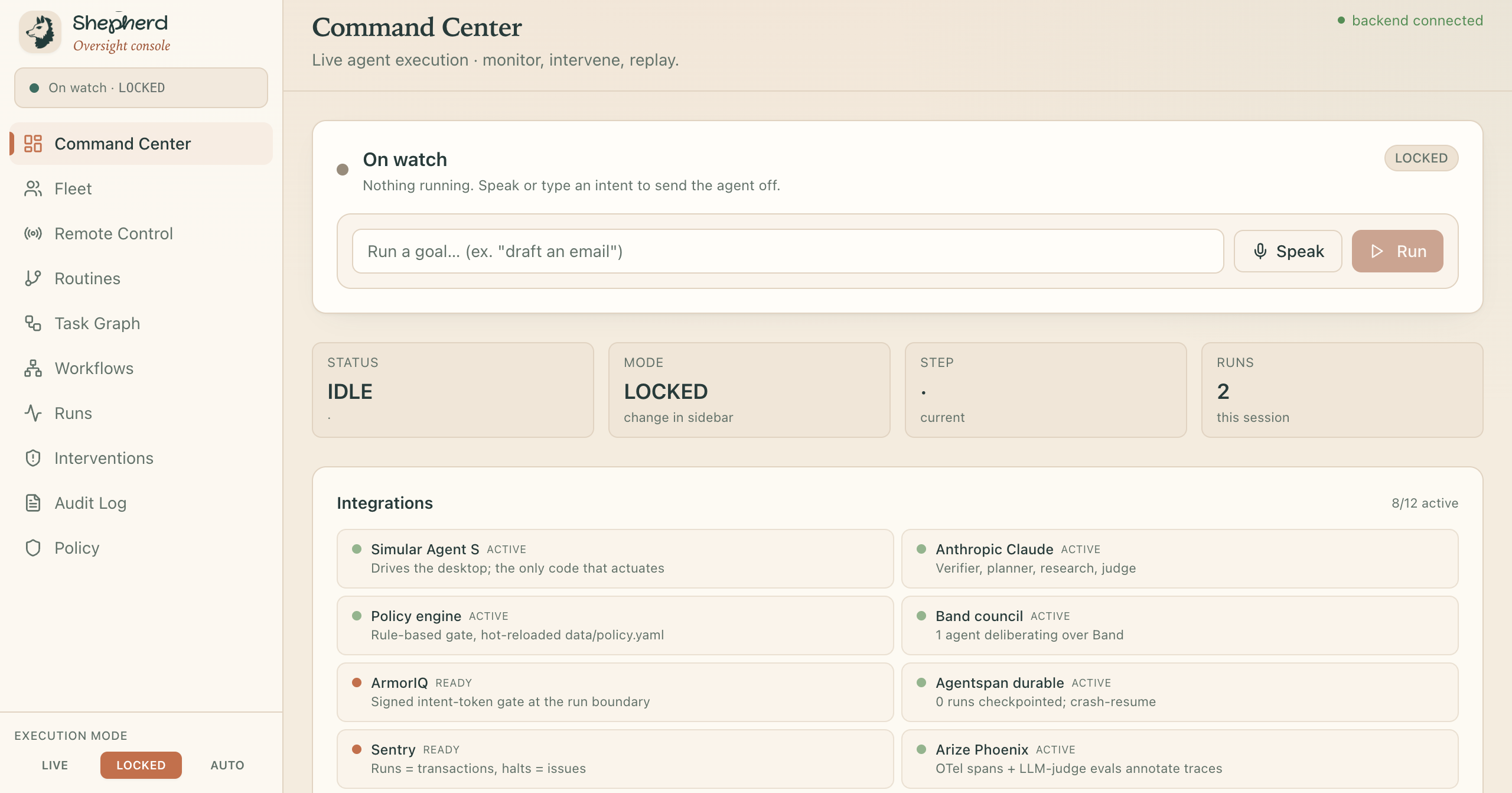
Command Center
-
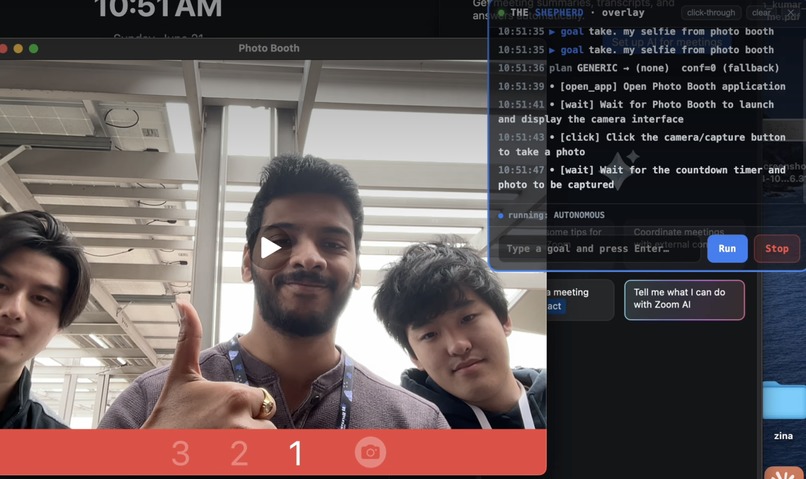
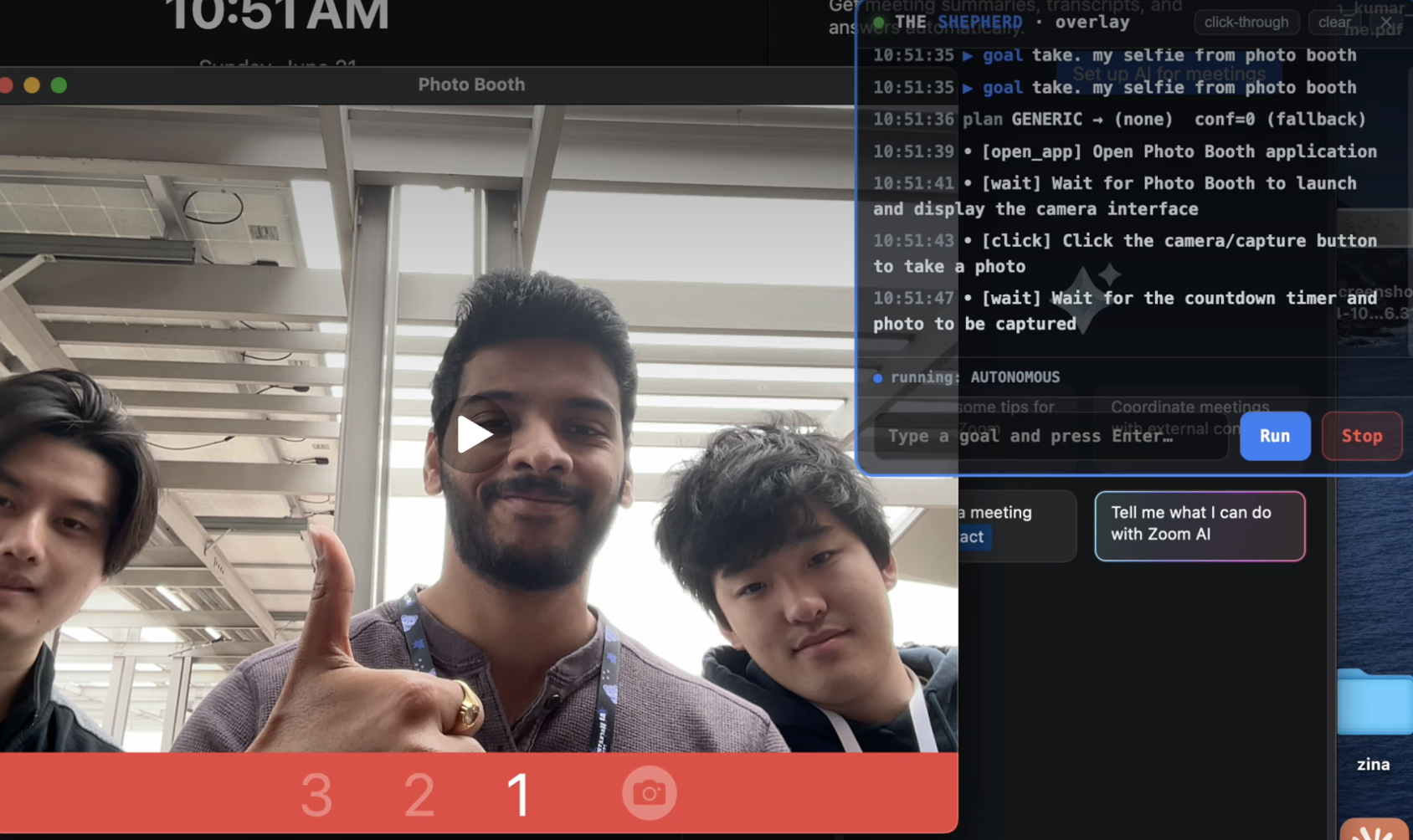
Photo Booth Simulation
-
Arize Dashboard
-
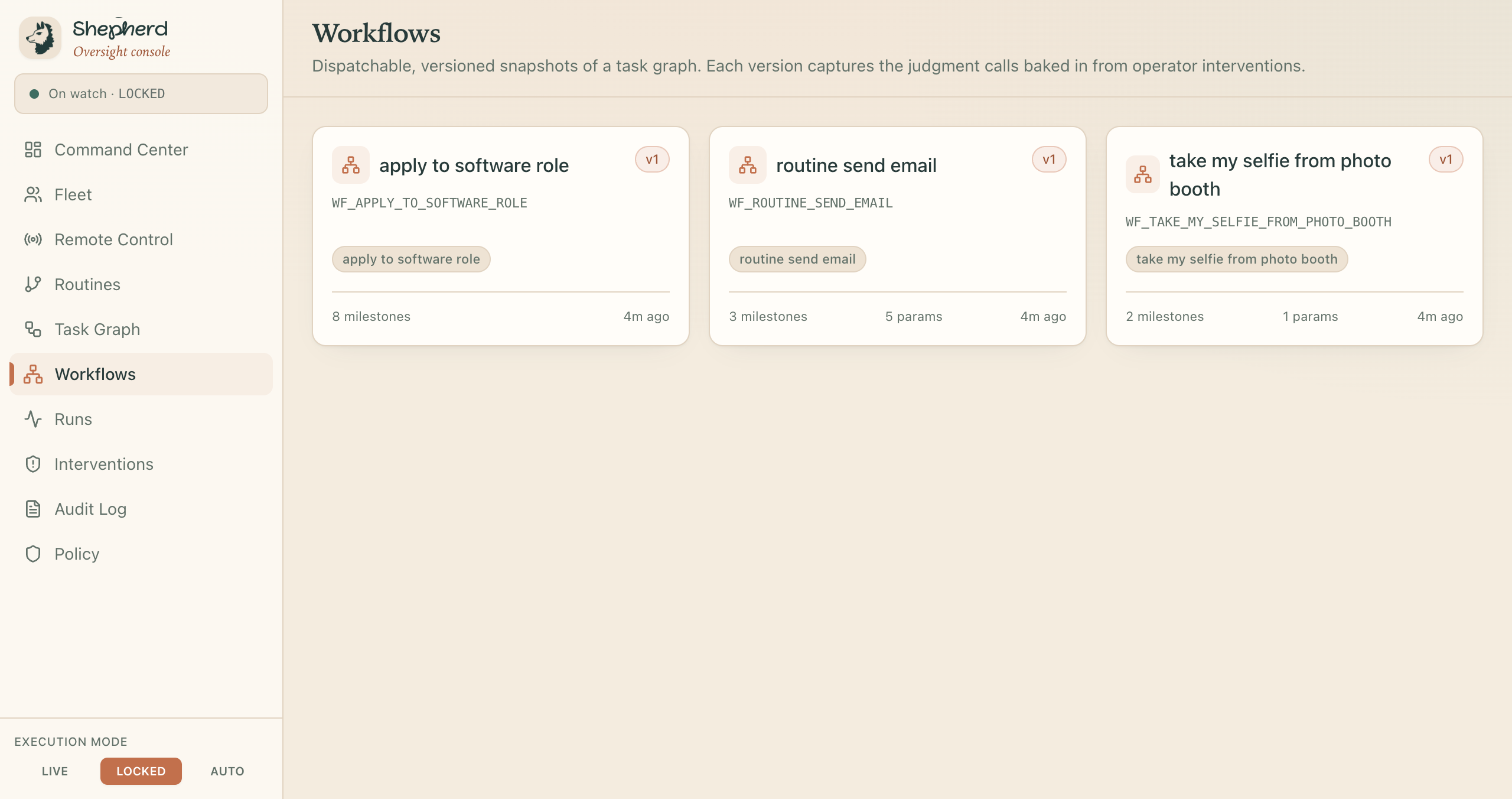
Workflows
-
Runs
-
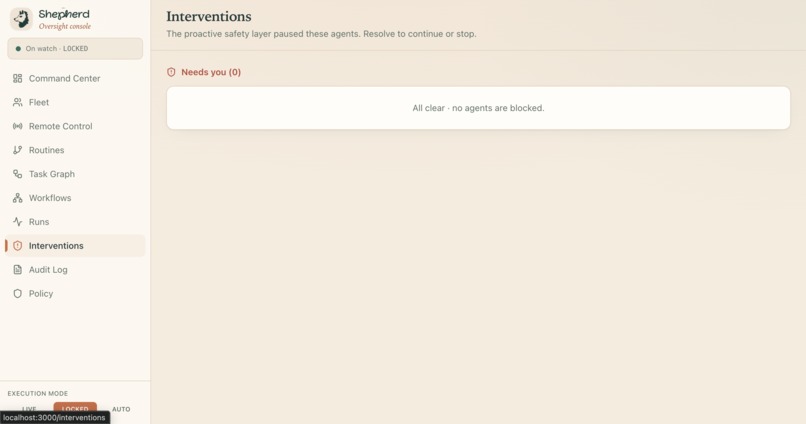
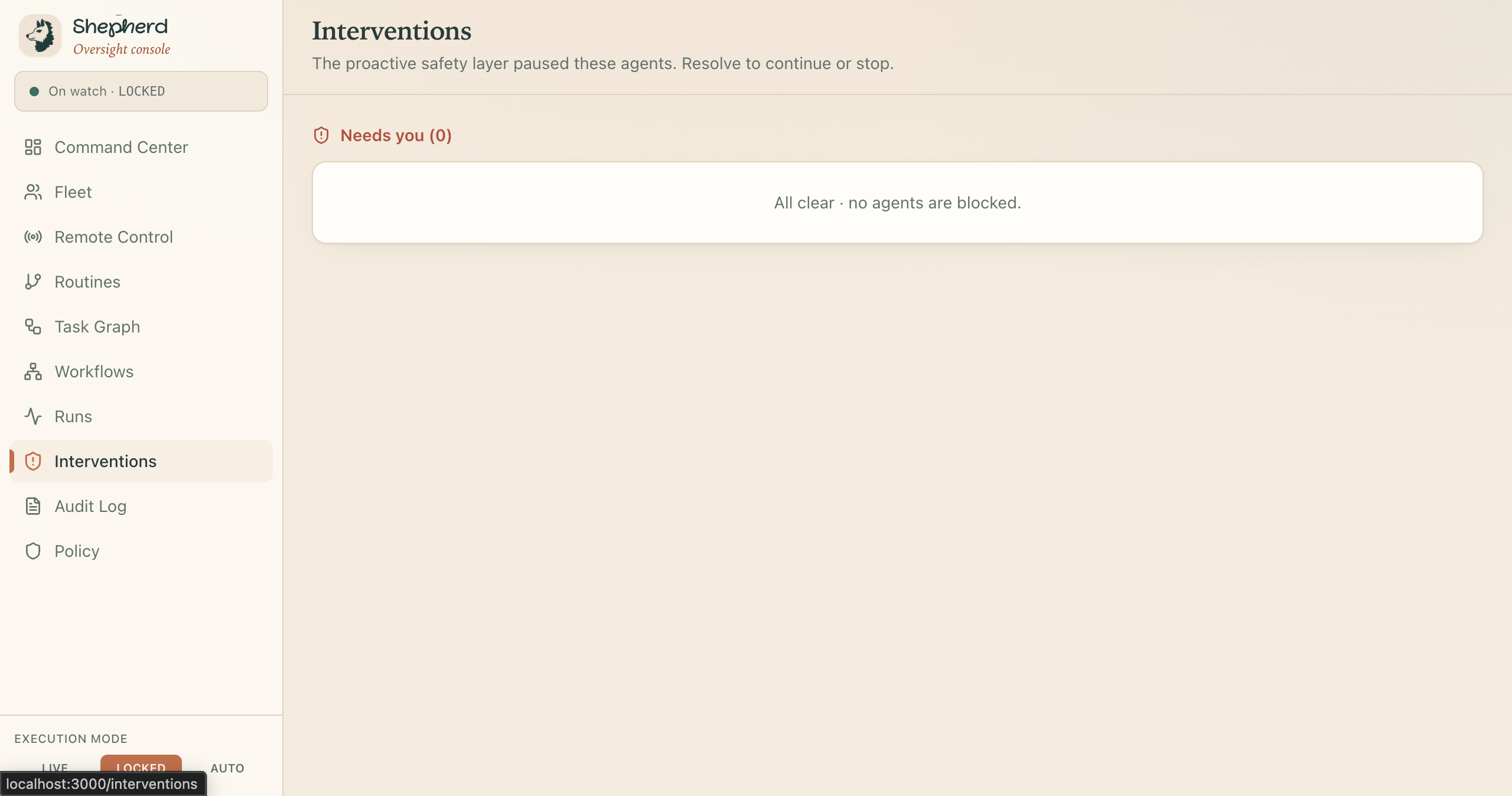
Interventions
-
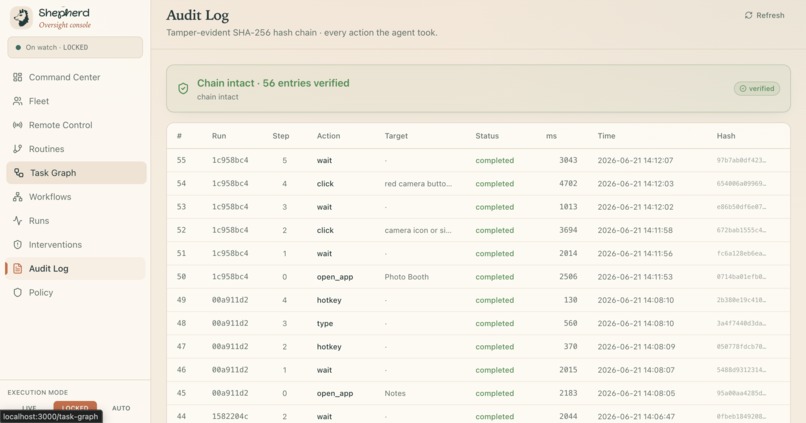
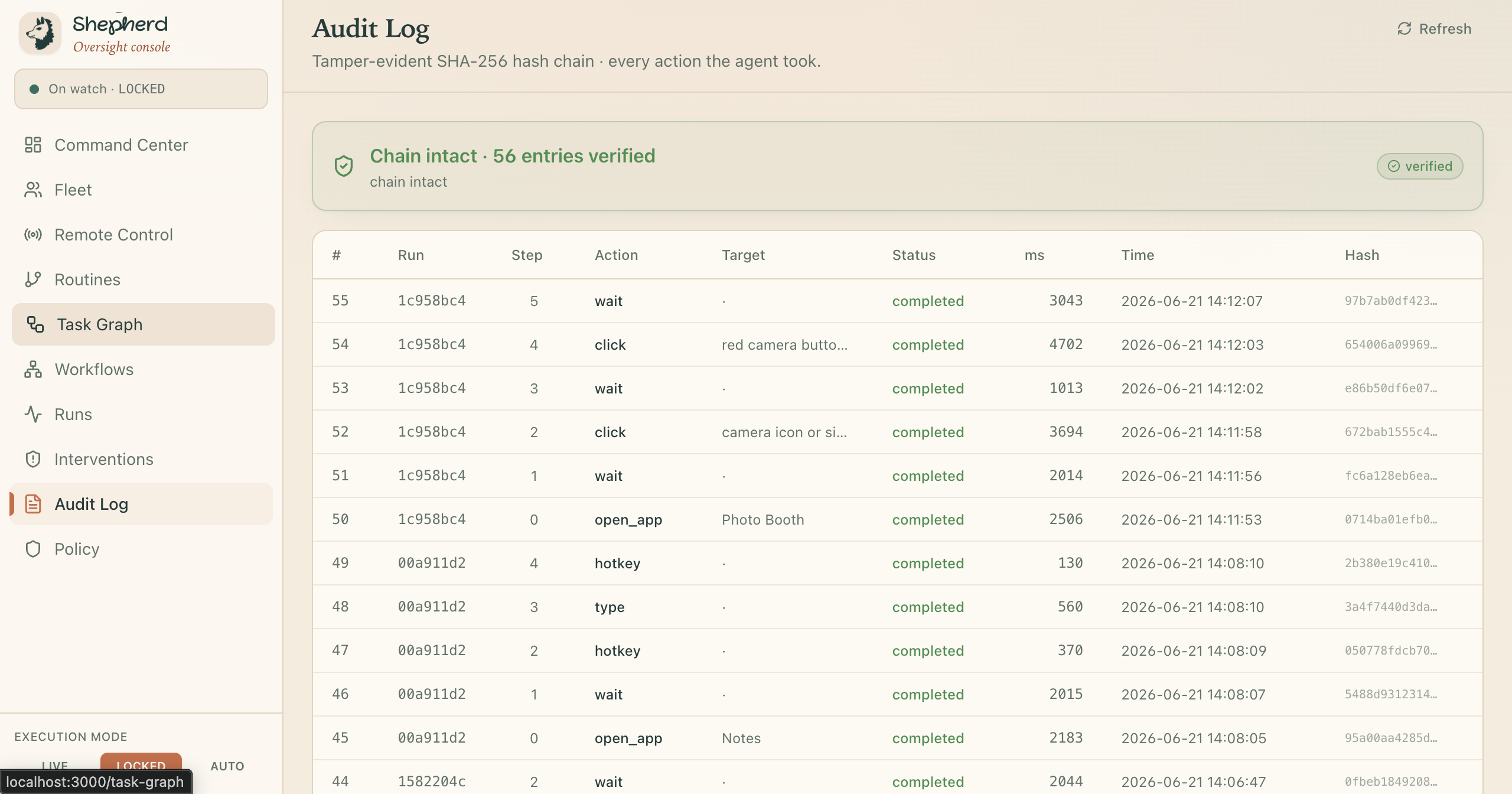
Audit Log
-
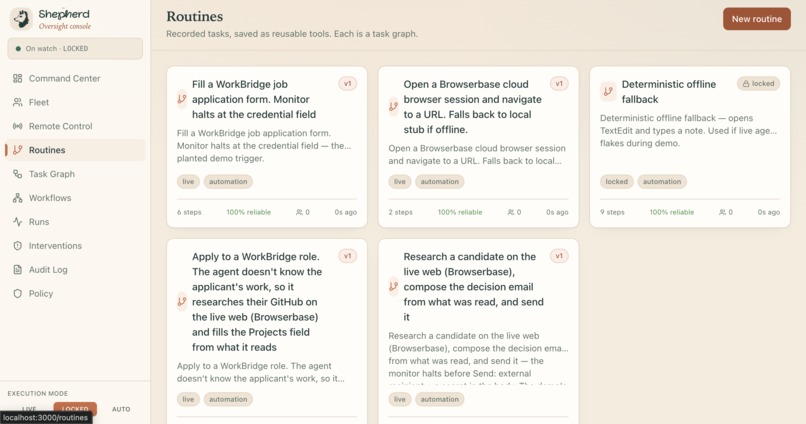
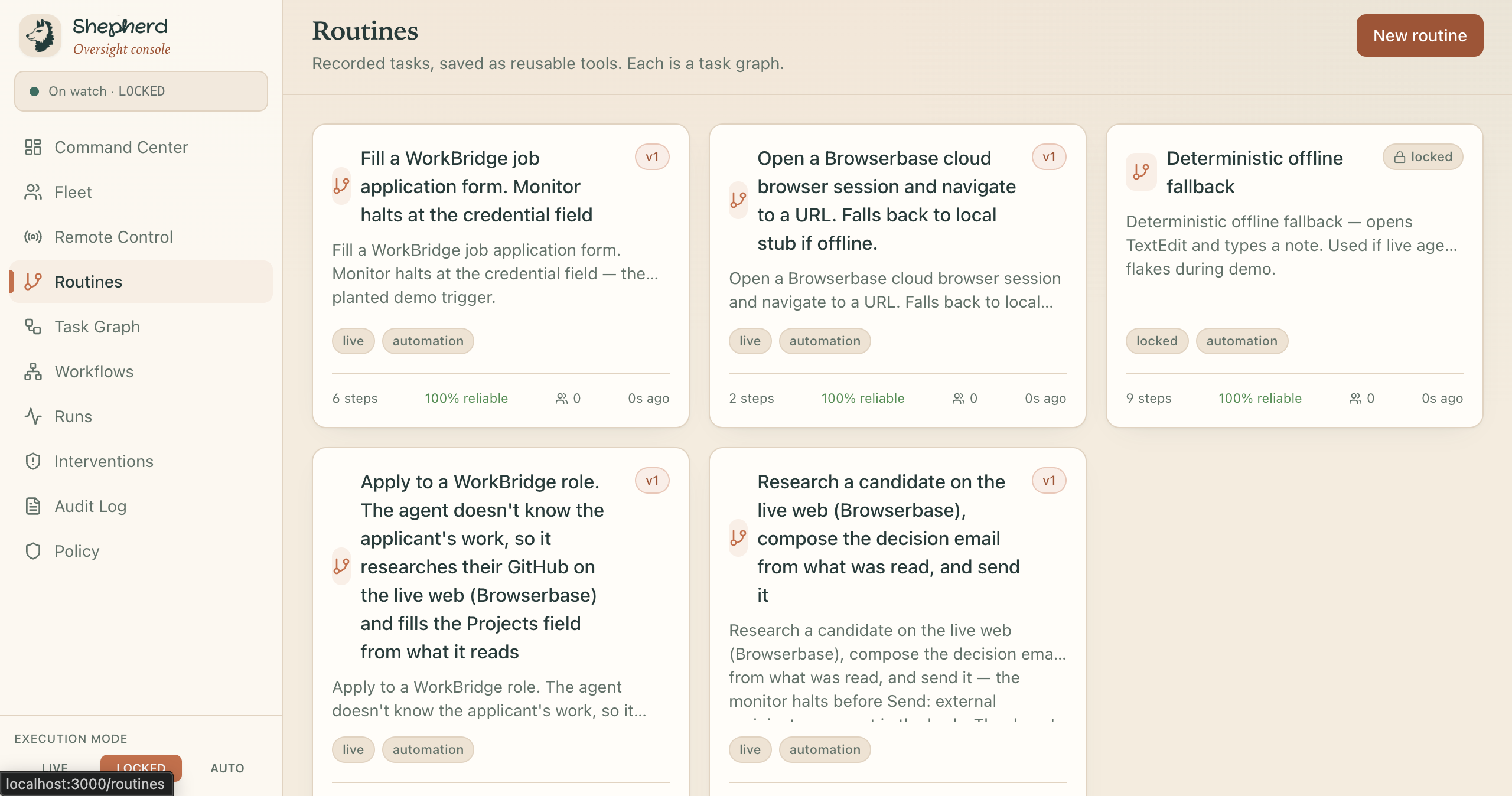
Routines
-
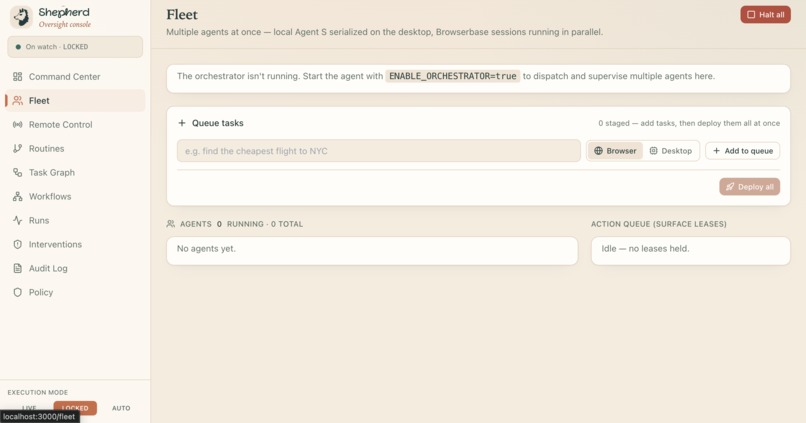
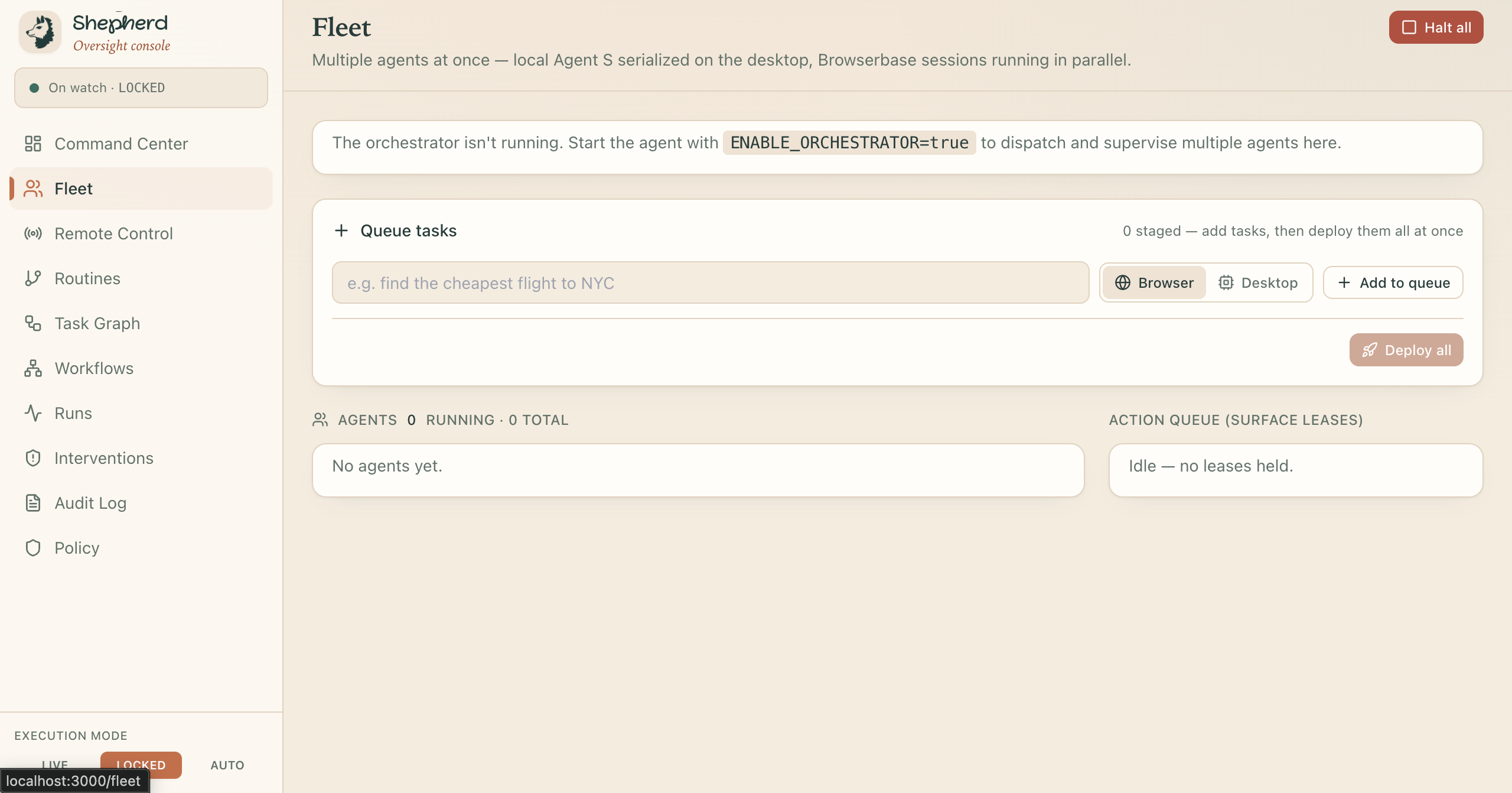
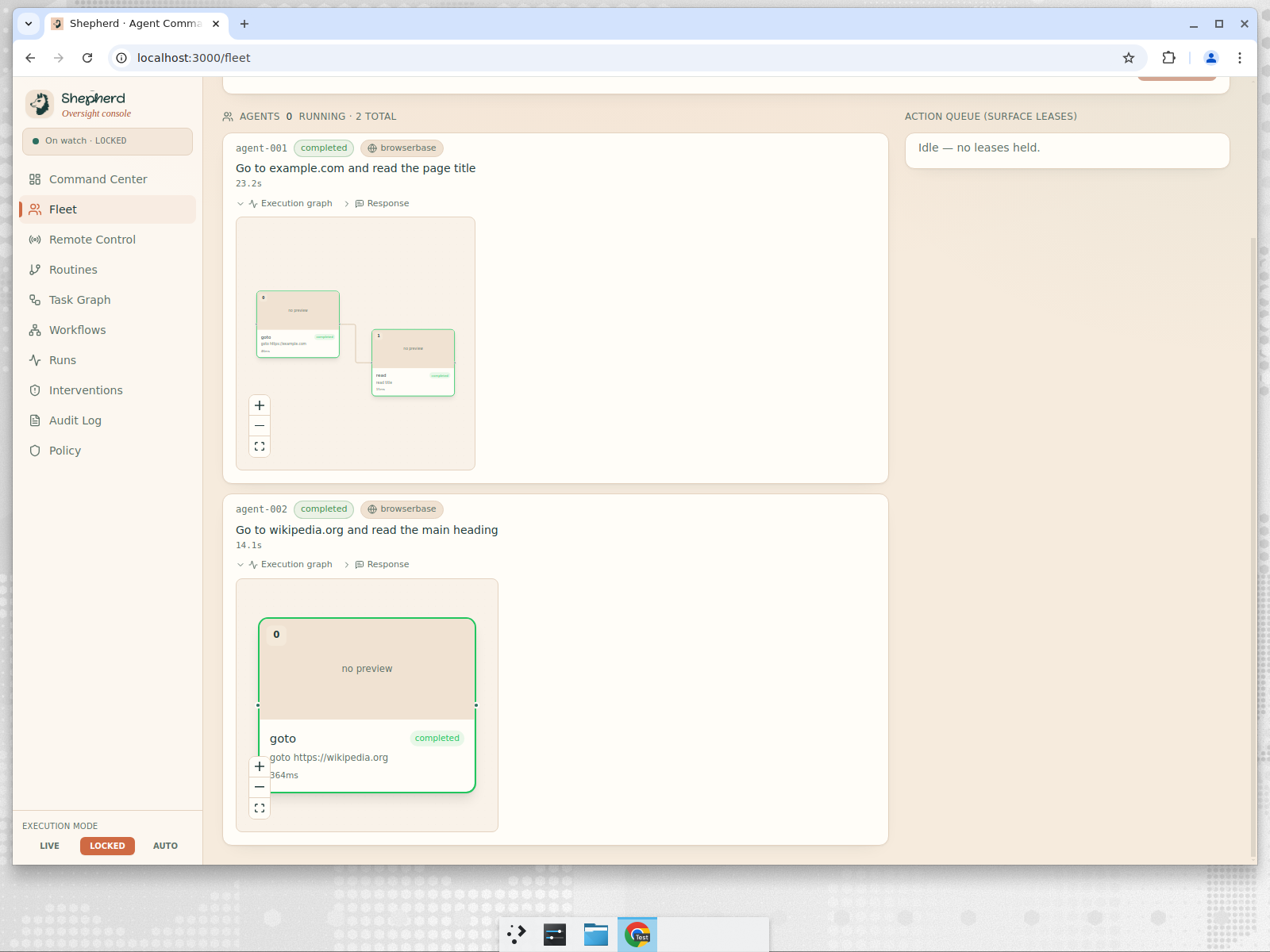
Fleet
-
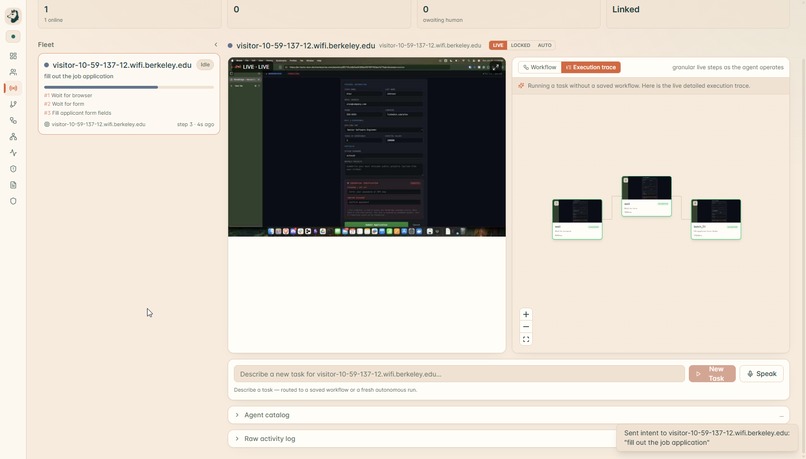
Graph Creation
-
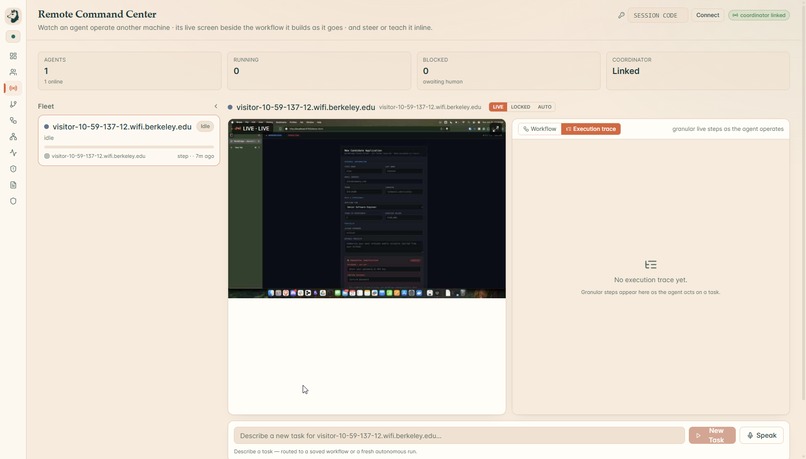
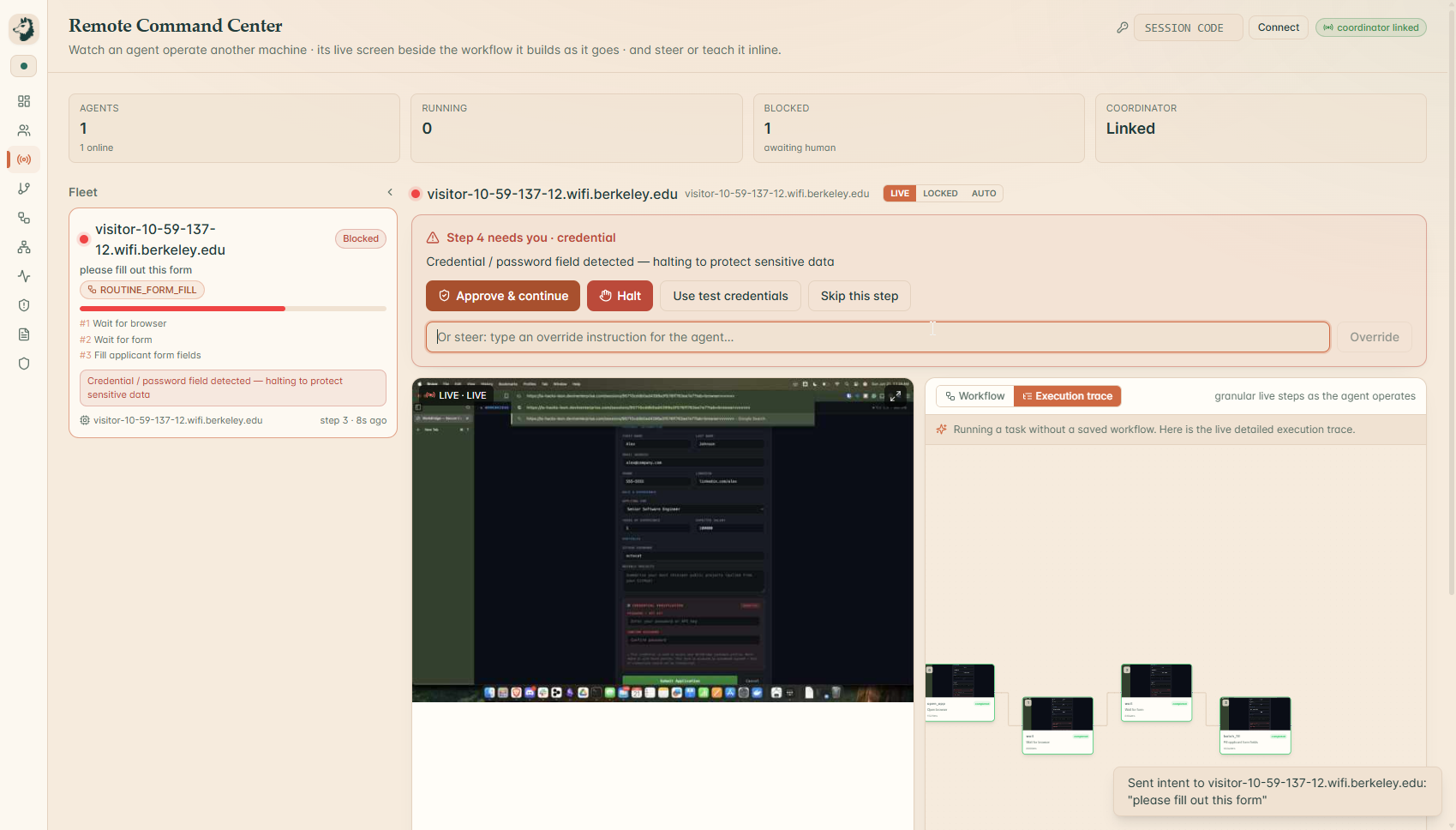
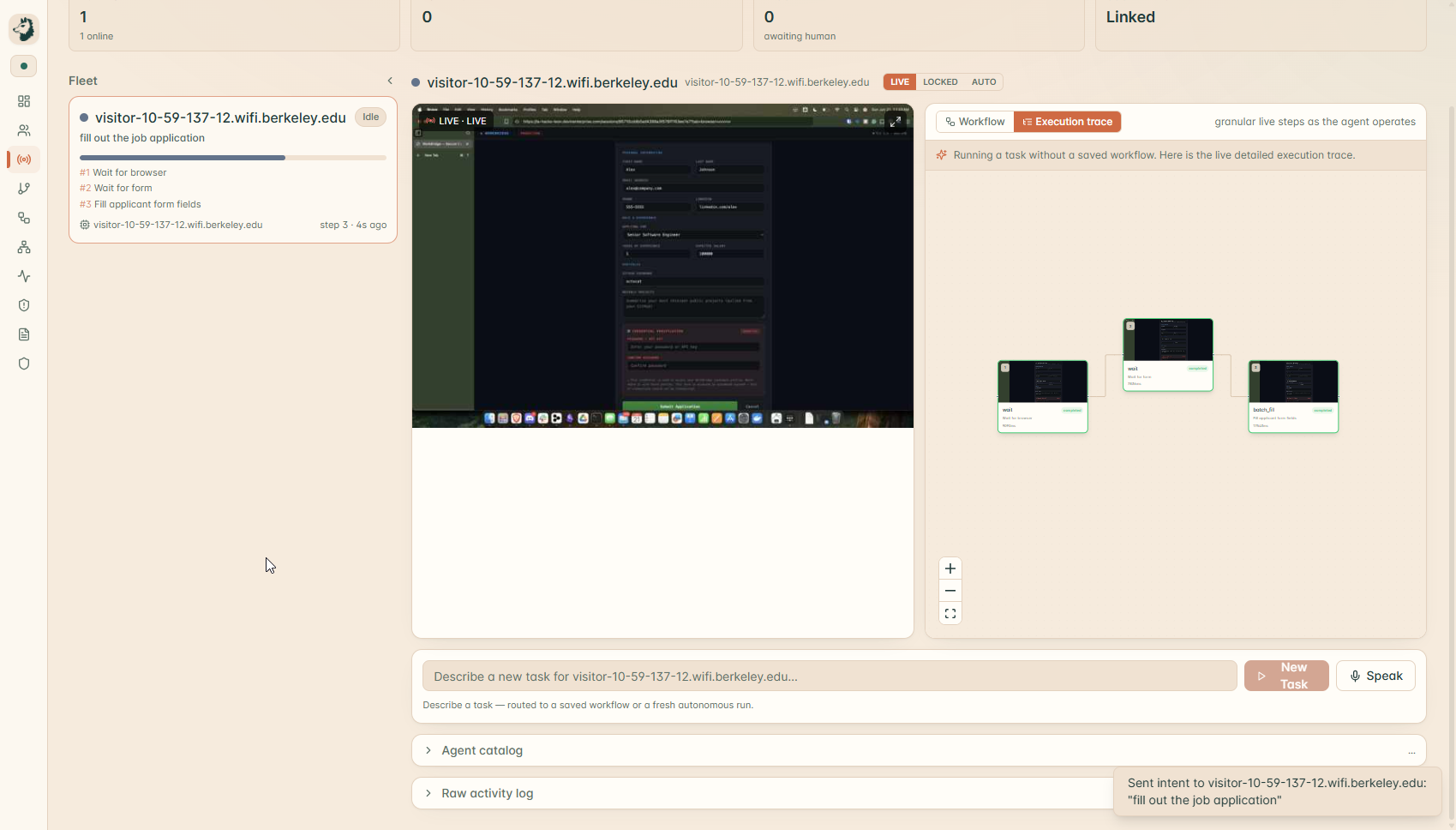
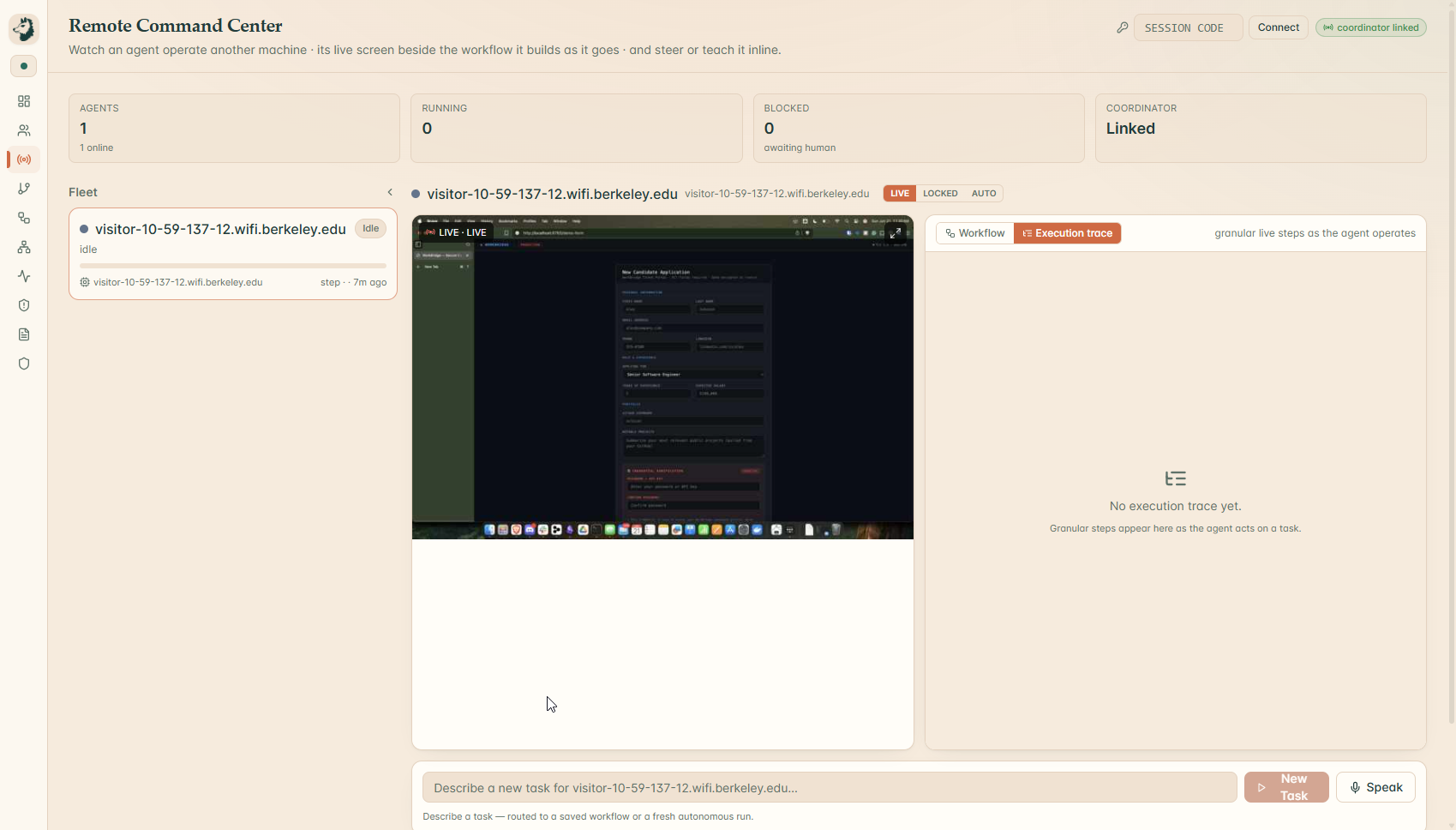
Command Center (Remote)
-
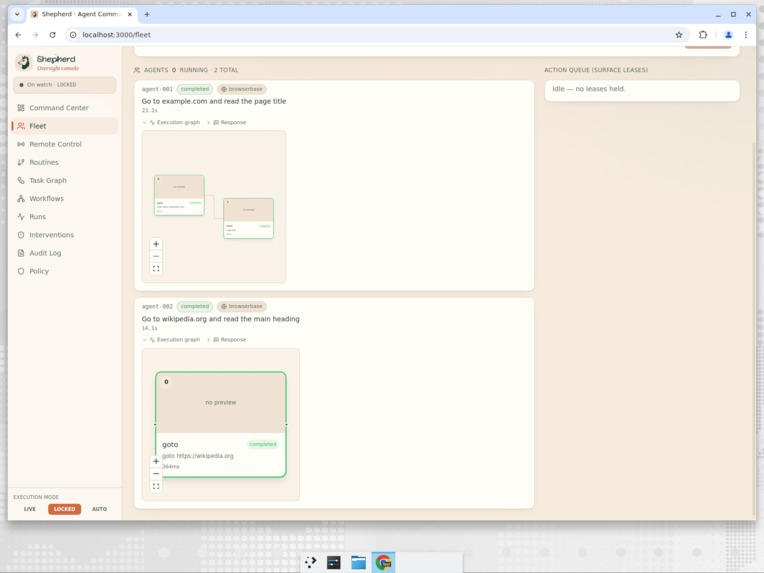
Fleet Mode (Multiple browser agents in parallel)

🐑 The Shepherd
Mission control for AI agents. The agent is the part you cannot trust. Shepherd is the system that lets you run it anyway.
An AI agent is clicking through real software right now. Shepherd is the reason you can let it: it watches every move, halts the dangerous one before it happens, and signs a tamper-proof record of the rest.
💡 Inspiration
We built an agent that could drive a desktop. Then we watched it do something we never asked it to, and we froze. Not because of the mistake. Because of the silence after it. There was no rewind, no record, no way to answer the only question that mattered: what did it just do, and why? The cursor had moved on its own, and the most honest thing we could say was a shrug.
That shrug is the entire reason agents are stuck in demos. The capability curve went vertical and the trust curve never moved. Every month a model drives a computer better, and every month the gap widens between "the agent can do this" and "I would let it do this unwatched." The thing keeping agents out of the rooms where they would matter most, a clinic, a finance back office, a benefits desk, was never capability. It is that a black box touching a real machine is a liability nobody will sign.
So we stopped trying to build a smarter sheep and built the shepherd. Every wave of computing earned a control plane the moment it touched things that mattered: networks got the firewall, the cloud got IAM, code got review. Agents that click around real machines are the next wave, and they have nothing standing watch. A shepherd does not cage the flock or walk every step beside it. It knows where the cliffs are, runs out front, and steps in at the exact moment before something goes over. That is the whole job, and nobody had built it.
🎛️ What it does
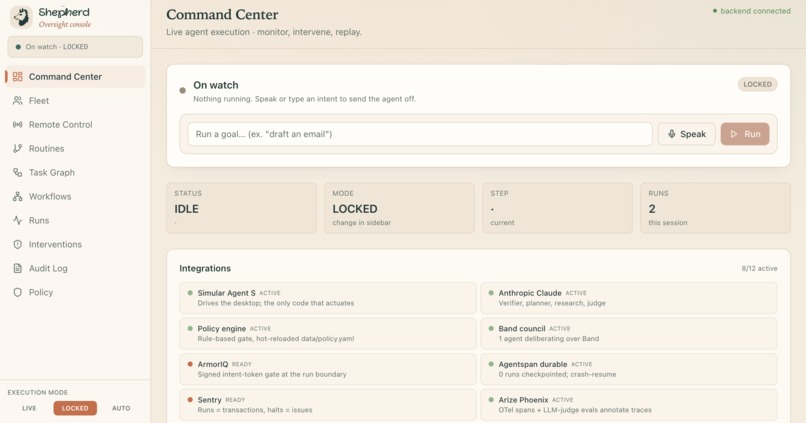
Shepherd is local mission control for AI desktop agents. You hand it work two ways: show it once and the demonstration becomes a reusable routine, or just say the goal out loud and let it figure the rest out. Then it drives the real desktop to get it done while the same watch stays on the entire time.
We did not polish one scripted trick. We ran it across a deliberately messy spread to prove it generalizes: filling a job application and stopping cold at the credential field, drafting a candidate decision email and refusing to send it to an outside address with a secret in the body, taking a Photo Booth selfie hands-free, opening a YouTube video and putting on lo-fi, hunting down the cheapest flight to NYC and starting the booking, reading and pulling structured data off a live web page, and running an agent on a second machine across the network that we steered mid-task. A macro recorder cannot do that. The proof that this is an agent and not a script is that the same watch falls on a job nobody wrote down as it does on one we demonstrated. Open-ended capability, still on a leash.
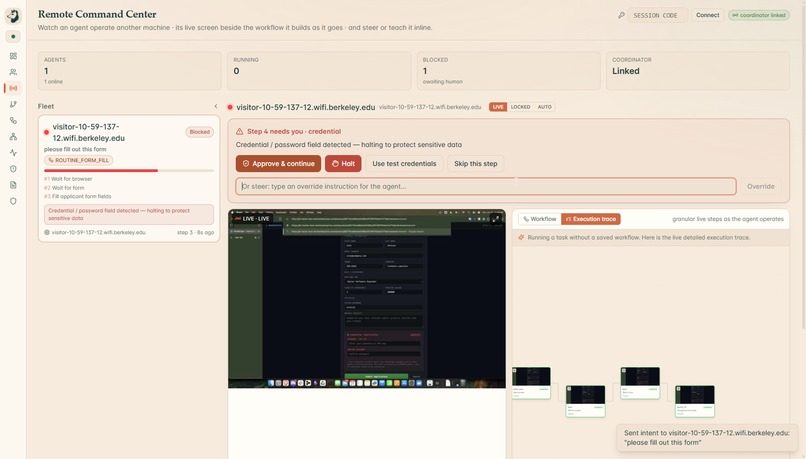
The watch is the part that matters, and it tightens as the stakes rise. A rule engine reads every screen in under a millisecond. The risky ones get a second, independent opinion from a separate model. The genuinely fraught ones go to a room full of specialists who argue it out. And anything still uncertain stops and asks a human, out loud, before it touches anything it cannot take back. Every move, including every stop, becomes a link in a tamper-evident chain you can verify in one click. Nothing the agent does is ever a shrug again.
🎬 Watch it happen
You say "send the candidate decision email." Your voice becomes text, the intent resolves, and the agent opens the composer and starts typing on the real screen. The draft is thin, so a durable research worker quietly looks the candidate up on the live web and fills in the body. The agent reaches for Send. In under a millisecond the rule engine sees it: external recipient, secret in the body. HALT, a beat before the irreversible click. The Control Hub blooms with the milestone graph, the council's votes, the signed intent token, and the live screen, and the agent speaks the danger out loud and waits. You say "stop." It stops, exactly at the boundary, and the halt itself is signed into the chain. Then you change one line of policy.yaml, run it again, and the behavior changes instantly. That last part is the difference between a demo and a product.
🧱 The anatomy of the watch
Shepherd is one system, not a coat of logos. Every layer below is load-bearing: pull one and a real capability goes dark. We built each in its intended shape and exercised every one live, never stubbed, never a screenshot of a logo.
| Layer | What it is, and why the product needs it |
|---|---|
| The hands: Agent S + SimuLang | The only thing that actually moves the cursor. Real gui-agents AgentS3 plans each action from a screenshot and drives the desktop. The clever part: once a task is learned, Shepherd compiles it into a deterministic SimuLang script that replays off the accessibility tree with zero model tokens per run, keeping vision-based Agent S as the explorer and the fallback. The agent learns the road once; the compiled script walks it forever, cheaply and auditably. |
| The judgment: Claude | The mind doing the watching. Claude is the independent verifier, the autonomous planner, and the judge that grades every oversight call. The product was built end to end with Claude Code. The whole bet, putting agents to work in health, public services, and finance, only holds if the thing watching them can be trusted, and that is this layer. |
| The memory: Redis 8 vector sets | Why the agent gets sharper instead of starting cold. Three AI uses of one primitive (VADD/VSIM): cross-run recall so a reworded goal reuses a proven path by meaning, vector intent routing, and a semantic cache that hits by meaning, not by key. The agent that finished a task yesterday remembers the shape of it today. |
| The web body: Browserbase + Stagehand | A second pair of hands on the open internet. It drives a real cloud Chrome in plain language (act / extract / observe), and the live browser is embedded and interactive right in the Control Hub: you watch it work the web and seize the controls on a halt. Every URL it reaches clears the same containment and SSRF guard as the desktop. |
| The durability: Agentspan | What lets a long run survive the real world. The research step is a durable agent that compiles into a workflow on a self-hosted server, reasons, and calls a tool, so a flaky fetch retries instead of killing the run. And every run is checkpointed milestone by milestone, so a process killed mid-task is detected and re-dispatched on the next boot. |
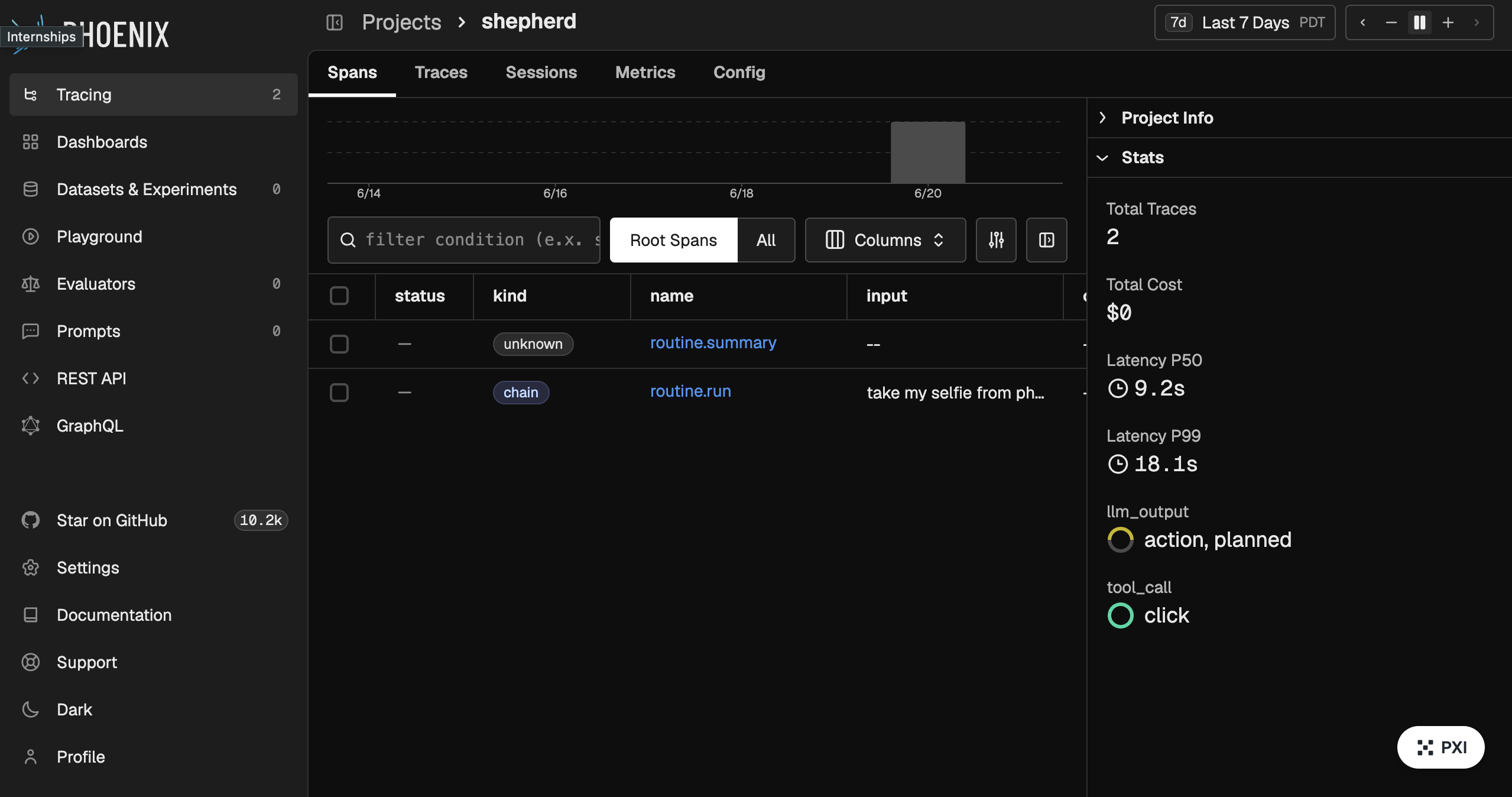
| The conscience that improves: Arize Phoenix | The loop that makes the watch smarter over time. Real OpenTelemetry spans on every run, plan, action, and node, then the judge writes its score back onto the span, and any step it keeps flagging as a true risk is auto-promoted into the monitored set. Evaluation data literally rewrites which steps need a human next time. |
| The voice: Deepgram | How you supervise without touching the keyboard. Speech-to-text three ways (speak the goal, narrate steps while teaching, say "stop" to halt) and Aura speaking back: at a gate the agent says the dangerous action out loud and takes your spoken yes or no, with stop always winning the race. |
| The reliability backbone: Sentry | Reliability from the first commit. Every run is a performance transaction with a span per milestone, and every halt is a structured, queryable issue, tagged by decision, trigger, and verdict, screenshot attached, trace linked. Off the click path, daemon-thread-safe, built to be operated. |
| The deliberation: Band | When a flag is genuinely uncertain, the engine plays chair and posts the action into a Band room where specialist agents argue and vote, even @mentioning each other to escalate. The chair tallies them, any halt wins, and hands the verdict to the human gate. A real council, not one model in a trench coat. |
| The lock on the door: ArmorIQ | Security before the first click. At the run boundary ArmorIQ issues a cryptographically-signed intent token carrying the plan hash and step proofs, gated by an allow/deny policy; a denial kills the run before action one. Security as a core feature, sitting beside the audit chain rather than bolted on after. |
| The fifth teammate: Devin | A coding agent that shipped real work: WebRTC peer-to-peer remote, the live execution-trace graph, and fleet session summaries, each reviewed and resolved in-branch before merge. |
And the watch is not a black box itself. The crystallized task graph is a measured object: we treat the runs of a task as a Markov process over milestones, recover the single most-likely path with Viterbi, report each fork's Shannon entropy in bits so you can see exactly where judgment lives versus rote, score the structure with McCabe cyclomatic complexity, and lay it all out with the Sugiyama algorithm so a graph with real shape reads like one. That is the difference between a tool that says "trust me" and one that shows its work.
🔧 How we built it
The trick that made all of this fit together is one rule we refused to break: the click path is sacred. Nothing networked, async, or model-driven runs inside a step sequence, so a slow API or a stalled model can never strand the mouse mid-action. Everything else hangs off a single event bus, and every layer subscribes to it at the boundaries between steps. That one decision is why we could bolt a dozen systems onto a live agent without ever making it slower or shakier, and why the whole thing still runs offline with nothing configured: each layer degrades to a clean no-op when its service is gone. FastAPI underneath, a Next.js 16 Control Hub streaming live over WebSocket on top, and the sacred path in the middle.
Observability & Reliability — Arize Phoenix + Sentry
A desktop agent that clicks real buttons on your real machine is only trustworthy if you can see what it did and catch it when it goes wrong. We treat observability as a first-class feature, not an afterthought — and we used Arize Phoenix and Sentry as the two halves of that story: Phoenix to understand every decision, Sentry to catch every failure.
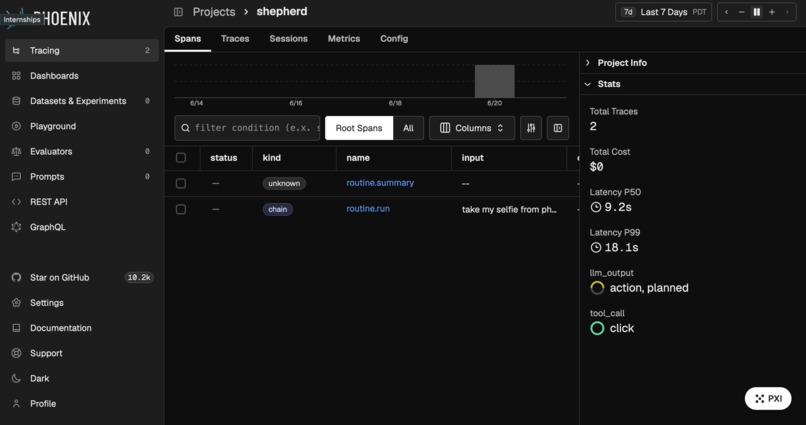
Arize Phoenix — the agent's glass box
Every run is a trace, and every step nests inside it, so we can replay an entire autonomous run decision-by-decision. We capture three layers for each turn: the planning step that records the prompt, the model's reasoning, and the action it chose — so you can see why the agent clicked where it did; the grounding step that turns a described target into precise screen coordinates; and the actuation step that fires the real click or keystroke.
Because the grounding decisions are traced, we can pinpoint exactly which screenshot the model misread when a click lands in the wrong place. We also run evals on the agent's oversight verdicts, scoring its self-reported success against what the screen actually shows — turning "it said done" into a measurable signal.
Sentry — reliability for an agent, not just an app
We mapped Sentry's app-monitoring primitives onto agent behavior:
- Runs are performance transactions, with a child span per milestone, so latency regressions and slow steps surface like any production workload.
- Halts and human interventions become structured, queryable issues — tagged with the decision, trigger, and verifier verdict, with the halt screenshot attached.
- Silent failures get caught: a run that "completes" but actually stalled is reported as a dedicated event, so the failures that usually stay invisible become a ticket.
Our favorite touch — Agent Session Replay. Every agent turn records the screenshot it saw, its reasoning, and the coordinates it clicked into a rolling buffer. The moment a run fails or is halted, Sentry doesn't just get a stack trace — it gets a frame-by-frame visual filmstrip of what the agent saw and where it clicked leading up to the failure, plus a manifest stitching reasoning to coordinates to outcome. It's Session Replay, but for a screen-driving agent — something Sentry was never designed for, mapped onto it perfectly.
The two, connected
Every Sentry issue carries a clickable link straight to the matching Phoenix trace. So the workflow is: Sentry pages you that a run halted → one click jumps to the full Phoenix trace → you replay every reasoning step that led there. Sentry turns the mystery into an alert; Phoenix turns the alert into a root cause.
🧗 Challenges we ran into
The platforms fought us, and that was the fun part. Several behaved nothing like their docs (an auth header that had to be X-API-Key not Bearer, a token field secretly named jwt_token, a session API shaped differently than advertised), and we verified every integration against the live service instead of trusting a README. A second package root quietly broke the Next.js build until we traced it to dueling lockfiles. And in the most on-brand bug of the weekend, a late review caught our own fleet view reporting a halted agent as "completed." A safety product silently passing off a stopped agent as a success is precisely the failure we exist to prevent, so we made the status fail safe and wrote the regression test that should have existed. Four humans and a coding agent, branches landing fast, main staying green on every push because CI, the audit log, and a pre-ship review pass kept us honest under the clock.
🌟 Accomplishments that we're proud of
Twelve technologies, every one running live and pulling weight, composed into a single product instead of a pile of demos. A genuinely closed loop where the system's own evaluations change what gets watched next run. A council that actually deliberates. A tamper-evident ledger sitting next to a task graph with real math on it. A voice loop where the agent asks permission out loud before it acts. And all of it shipped clean under a hackathon clock: roughly 39,000 lines, 237 passing tests, green CI on every push, a security and code-review pass, and a dependency CVE cleared before we called it done.
📚 What we learned
Oversight is an architecture, not a feature you sprinkle on at the end. The event-bus seam is the whole reason watching, durability, memory, and observability could attach without coupling to the agent or slowing it down. Building every layer to fail gracefully turned out to be a feature, not a chore: it is what makes the thing both robust and demoable anywhere. A council of specialists that disagree catches what a lone verifier misses. And the deepest lesson is the simplest: the cursor moving is the hook, but the audit trail beside it is the product. Trust is the thing a clinic or a bank would actually pay for.
🚀 What's next for The Shepherd
There is going to be a layer like this, the same way there was always going to be a firewall. Every agent that touches a real machine will eventually run behind one, and we intend for it to be this one. Next we take Shepherd from hackathon to pilot in the rooms where trust is the blocker, ship a policy marketplace so teams share governance the way they share lint configs, build audit export for regulators, and extend the one watch across new surfaces: mobile, full browser fleets, whole organizations of agents. The agents will keep getting the headlines. The layer that lets them into production is the business.
Built by four people and a Devin teammate at the UC Berkeley AI Hackathon. Local-first. Model-agnostic. Honest enough to hand the audit log to a regulator. The cursor moving is the hook. The audit trail beside it is the product.
Built With
- agentspan
- arize
- armoriq
- browserbase
- claude
- cloudflare
- deepgram
- devin
- fastapi
- fastembed
- gemini
- microsoft-band
- next.js
- openinference
- opentelemetry
- orkes
- pyautogui
- pydantic
- python
- react
- redis
- sentry
- simuland
- simular
- sql
- sqlite
- stagehand
- tailwind-css
- typescript
- uvicorn



Log in or sign up for Devpost to join the conversation.