-
-
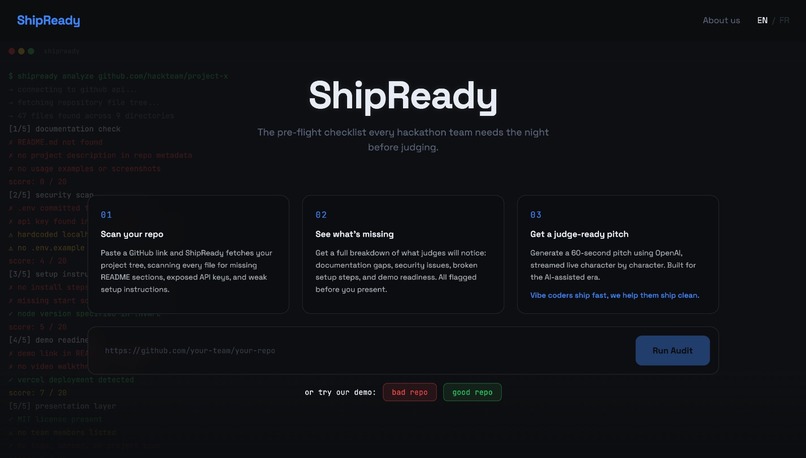
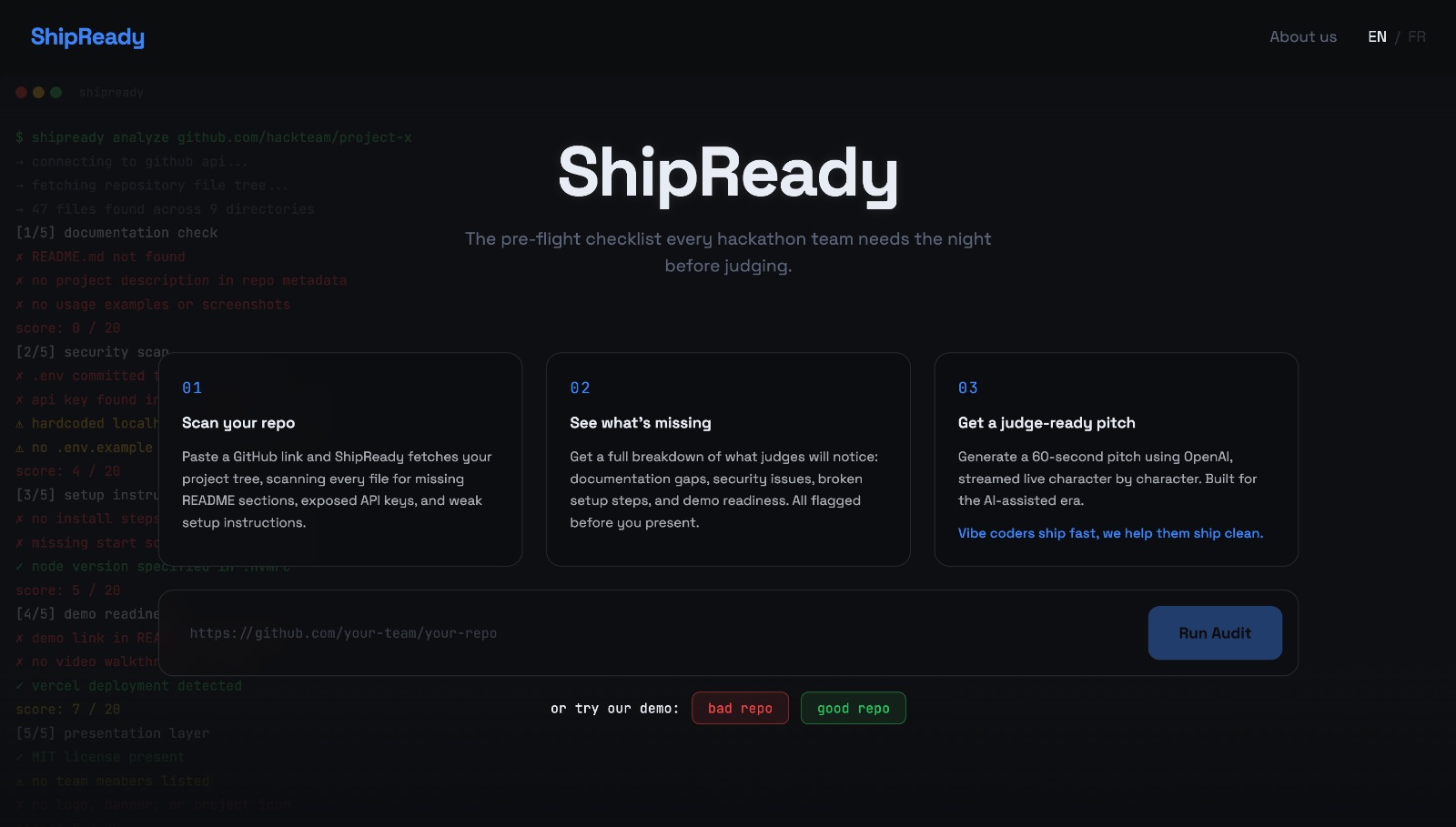
Main page
-
Loading Page
-
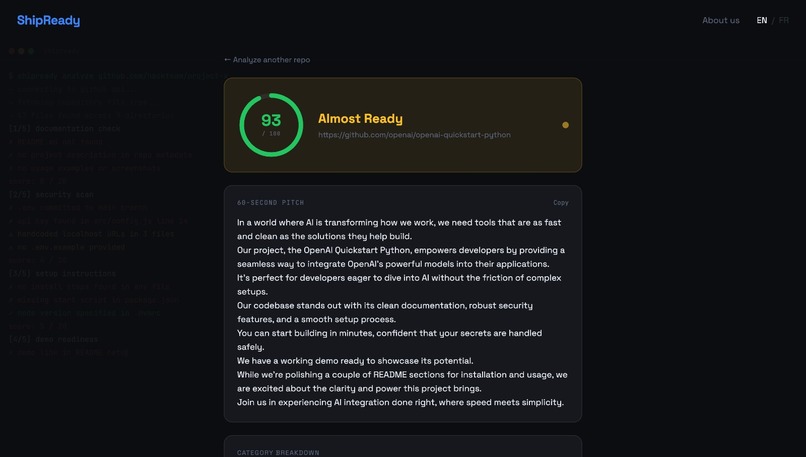
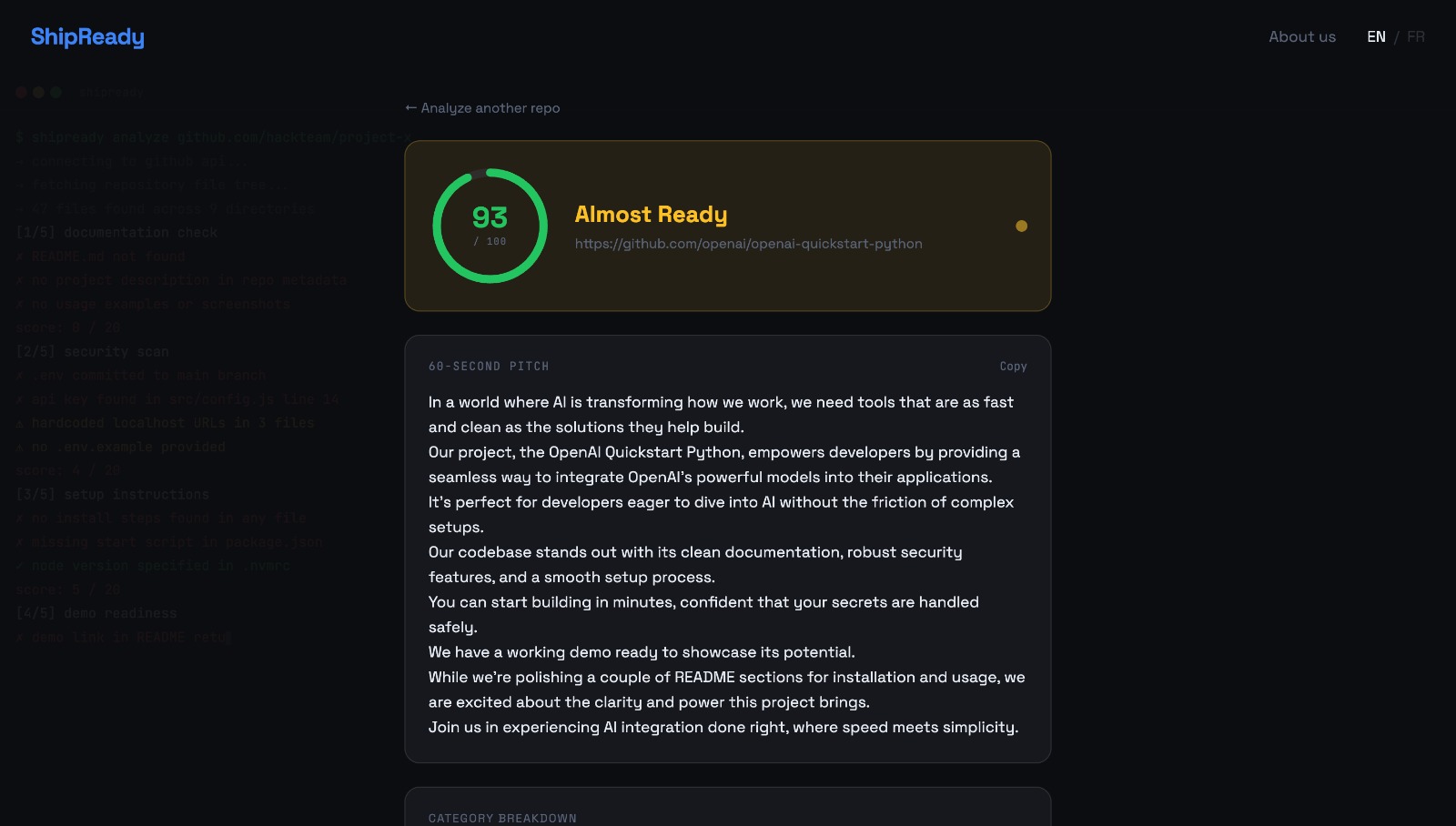
Results
-

Results
-
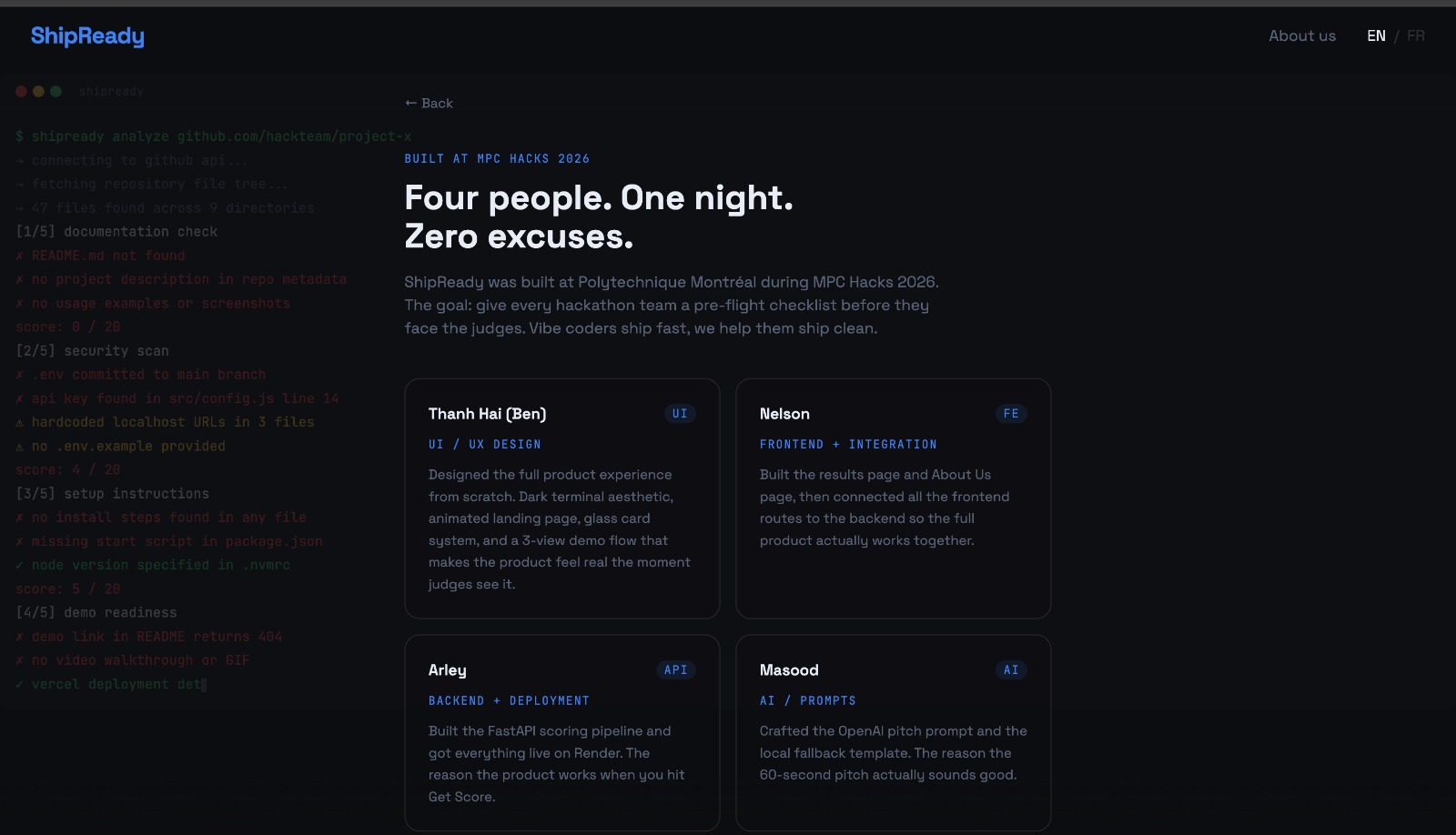
About us

Inspiration
MPC Hacks had no theme, so we knew from the start that execution and a believable "why does this exist" story would matter more than a flashy concept. Going in, we did our homework: we ran a Zoom brainstorm as a team, put several ideas on the table, and pressure tested each one against a single question: what is a problem every team at this hackathon will have, that almost nobody will solve?
The answer was sitting in the room with us. Everyone builds fast with AI and then panics in the last hour. The code runs on one laptop, the README is empty, an API key is sitting in plain text, and nobody has a clean 60 second pitch. We kept coming back to the same observation: good ideas lose because they demo messy, not because they are bad.
That reframed the whole project. Instead of being one more team building with AI, we decided to be the team that evaluates what everyone else builds. ShipReady was the tool we wished existed: a pre-flight quality advisor that looks at your project the way a judge or a senior engineer would, before you walk up to present.
What it does
You paste a GitHub repo link. ShipReady analyzes the project across the dimensions that decide whether something is ready to ship: security, usability, scalability, maintainability, and presentation readiness. It returns:
- A scorecard with a real, differentiated score per dimension, not four identical placeholder numbers.
- A list of warnings pulled from the actual repo: a missing README, no setup instructions, a possibly exposed API key, no auth explanation.
- A prioritized fix board, so a team knows what to fix first with the time it has left.
- A generated 60 second judge pitch that streams in live, so you walk into your demo with a script.
- A "Ready for Judges?" readiness indicator that ties it all together.
How we built it
We planned the build before the clock started. We split the team by domain so the work could run in parallel: frontend and UX, backend and scoring logic, AI and prompt design, and demo and QA. We locked a shared contract between frontend and backend early, and we wrote a rules file so everyone prompting an AI agent produced one consistent coding style instead of four we would have to untangle later.
The frontend is React and Vite with Tailwind for the scorecard, fix board, and the streaming pitch reveal. The backend is FastAPI and Python: a scoring engine that pulls the repo file tree from the GitHub API and grades it against the signals, plus a /pitch streaming endpoint. The pitch generation uses GPT-4o when a key is present and a local template fallback that streams identically when it is not, so the reveal lands the same way whether or not the network cooperates.
Challenges we ran into
Making the scores real. Our first pass risked returning four identical placeholder numbers. We had to ground every score in what is actually in the repo so the scorecard means something, which meant carefully engineering the prompts we sent to the OpenAI API to produce structured, differentiated output rather than generic filler.
Integrating the frontend and backend. Getting the React frontend and FastAPI backend talking cleanly was one of our biggest friction points. Locking a shared API contract early helped, but we still hit mismatches in how data was shaped and passed between the two halves, especially once the OpenAI responses were wired in and the payload structure evolved mid-build.
Wiring in the OpenAI API end to end. Getting the API integrated correctly across both the scoring engine and the streaming pitch endpoint took more iteration than expected. We had to handle streaming responses reliably, make sure errors from the API degraded gracefully on the frontend, and ensure the prompt outputs were consistent enough to drive the scorecard logic without breaking the UI.
Coordinating parallel work. Keeping four people and their AI agents from stepping on each other's context meant disciplined branches and one owner for the rules file.
Accomplishments that we're proud of
We shipped something that looks and behaves like a real SaaS product, not a single prompt wrapper. The analyzer produces differentiated, repo grounded scores. The streaming pitch lands as the high point of the demo. And the whole thing degrades gracefully: every critical path has a fallback, so the demo holds together even when the network does not.
What we learned
Depth beats breadth at a hackathon. A focused, polished product that fully works beats one juggling six half wired sponsor logos. Lock the contract between frontend and backend early so the halves can be built in parallel and integrated cleanly. And build the fallback first: a demo safe path is worth more than an impressive path that can break live.
What's next for ShipReady
Deeper analysis: real static analysis and dependency scanning instead of signal heuristics. A V2 agentic architecture where the analyzer plans, inspects, and re queries rather than running a fixed checklist. And CI integration, so a repo gets a readiness score on every push.
Built With
- fastapi
- javascript
- openaiapi
- python
- react
- tailwindcss
- vite

Log in or sign up for Devpost to join the conversation.