-

-
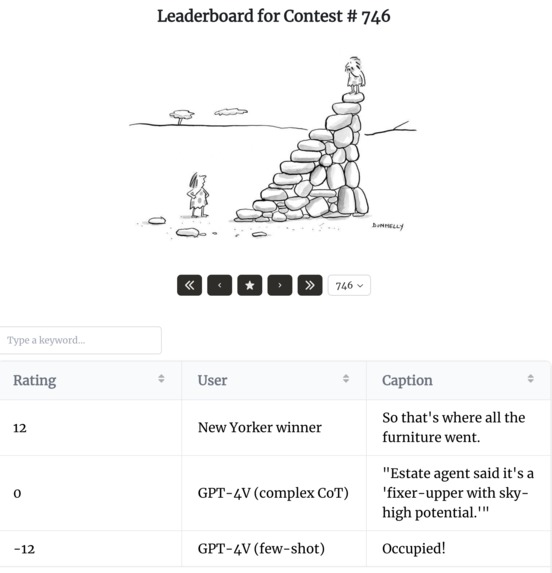
Per-contest leaderboard showing each caption's ELO score
-

Intuitive comparison interface for participants



Inspiration
People often remark that ChatGPT is bad at creativity. So we thought, what better scenario to quantify the gap in human vs. AI creativity than the New Yorker Caption Contest? After all, the contest is notoriously difficult, with some notable players failing to win for years on end.
In the process, we ended up creating a surprisingly fun app that lets you compete to write the funniest caption for a given cartoon, and compare how you do with an AI that has put less than a minute of GPU time into the same task.
What it does
Our application leverages the vision capabilities of GPT-4V to generate inventive captions for the New Yorker Cartoon Contest. We design two reasonable baselines: few-shot GPT-V, where it is given 5 examples of winning image-caption pairs from the past; and a complex chain-of-thought prompt, where it is told to generate many candidates and reject ones which are bad.
We then randomly pair these captions up and show them to human participants for rating. Users engage in a straightforward selection process, choosing the caption they find most fitting or amusing among pairs. We use these comparisons to generate an ELO score both for each caption within a contest and for each user on the platform. This allows us to calculate the effective win-rate for each caption and user. Additionally, the application features allow users to explore top-rated captions and draw comparisons between the creativity of GPT-4V and human participants, offering a unique insight into the evolving capabilities of artificial intelligence in the creative domain.
How we built it
The site is a single-page-app built using Reflex, with state stored in Reflex’s integrated SQLite database. The production site is hosted on Fly.io.
A primary research challenge for us was making an AI system that could reliably produce humorous captions. We experimented with several different approaches; in the end, we found that the most interesting results came from few-shot GPT-4V (given pairs of (image, winning human caption)), as well as a more complex prompted GPT-4V (a multi-step prompt that asks the model to consider what's unusual in the image, create ~10 candidates, and self-roast). Whether these two baselines do better than human creativity is yet to be seen - and that's where you all come in!
Challenges we ran into
Deployment was surprisingly hard. Reflex's documentation in this area is lacking, and we encountered hard-to-debug errors like a deployment that would fail with absolutely no errors reported to the log.
State management in Reflex was a challenging but formative learning experience. While the docs were clear and direct about many aspects such as components and callback functions, there were some nuances to State interactions that we primarily discovered through trial and error. However, the process of iteratively testing and refining our application's state management allowed us to create an intuitive UI. These challenges pushed us to think adaptively about how to best utilize Reflex to meet our project goals.
Accomplishments that we're proud of
- Aesthetic design of the application in Reflex
- The statistical ELO rating system we created
- Design of our system and how it effectively merges LLMs with human creativity within the theater of comedy
- Sanitation of inputs — given the public nature of our leaderboard, we include a moderation api to ensure singular bad actors aren’t able to spam the leaderboard with profanity or other malicious content.
What we learned
- Reflex — it’s actually pretty useful for prototyping, but has several quirks and poorly documented aspects.
- Formatting, CSS styles, Button animations
- Typography
- Deployment of the website
- Pushing the boundaries of the API
- Learned more about multi-modal large AI models
- The state of the art for language model evaluation in subjective domains, including for hard-to-evaluate topics like humor. Some of us have had experience doing evals for language models, but typically it’s for pretty objective behavior, like MCQ performance. This fuzzier space feels more similar to reward modeling, which is really cool to get experience with!
What's next for The New Yorker Caption Club
- Add more social features & login to the application
- Better AI baselines, like training our own multimodal model, using Google models like Gemini Pro
- Configuring deployment for public use
Built With
- dall-e
- fly.io
- gpt-4v
- openai
- python
- reflex


Log in or sign up for Devpost to join the conversation.