Inspiration
Mindlessly scrolling through content has plagued our young generation. This is an attempt to create a passive intimation system.
What it does
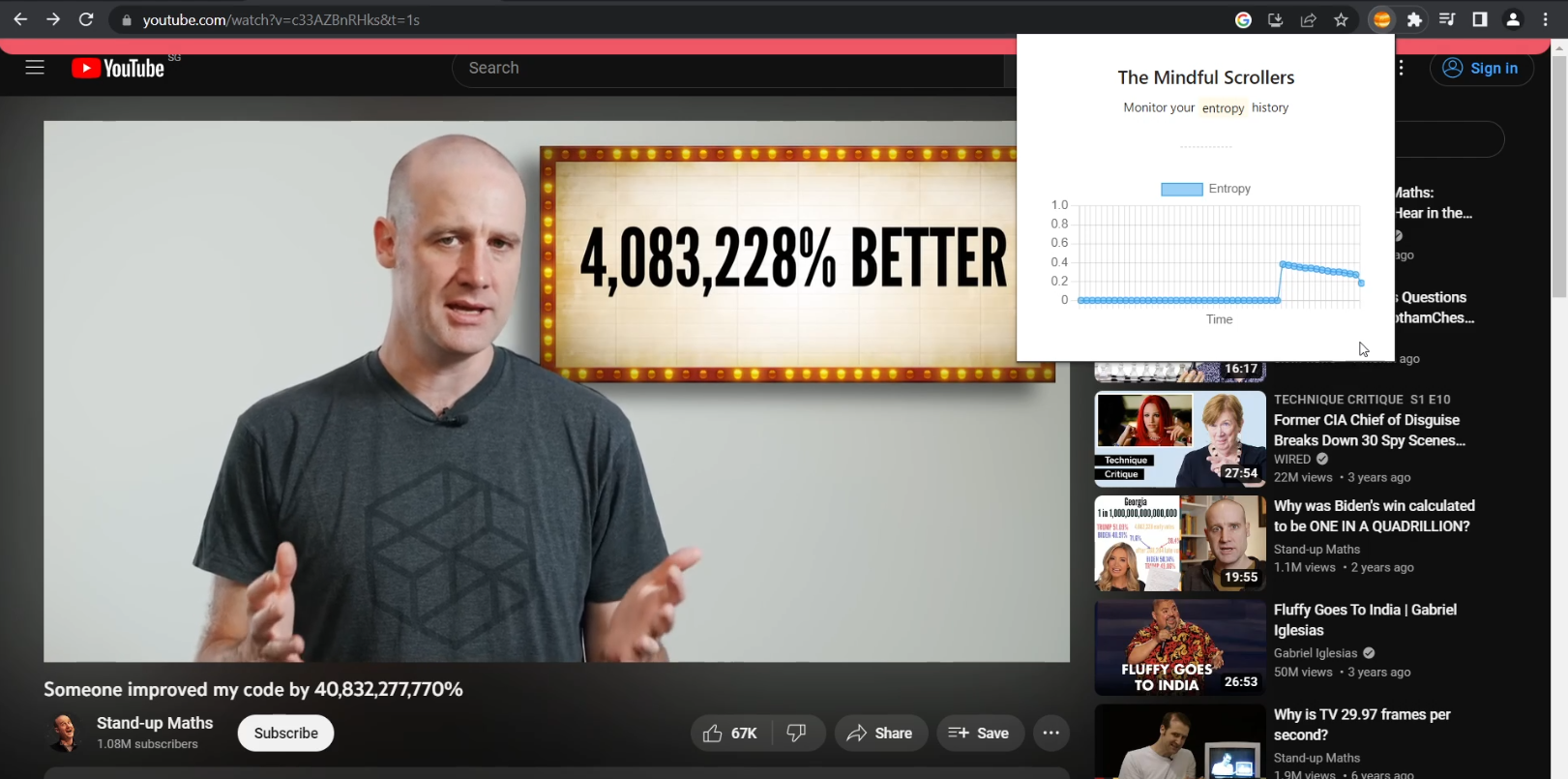
This chrome extension can categorize content into buckets, and track the user's browsing session. Whenever the user jumps from browsing content of one category to another semantically different category, we define it as an increase in the entropy of the user's browsing session. Since the goal is to make the user mindful of his or her focus, the extension passively intimates the users whenever there is a change in entropy.
How we built it
There are 2 components of the project
The Chrome Extension
The chrome extension displays a coloured ribbon over, all webpages a user visits. It syncs with a background worker to update its colour. This colour temperature indicates the entropy in the browsing session. However, the entropy is always decaying because if users spend a lot of time in a new genre of content, maybe it is the genre the user might be interested in.
Content Similarity Score
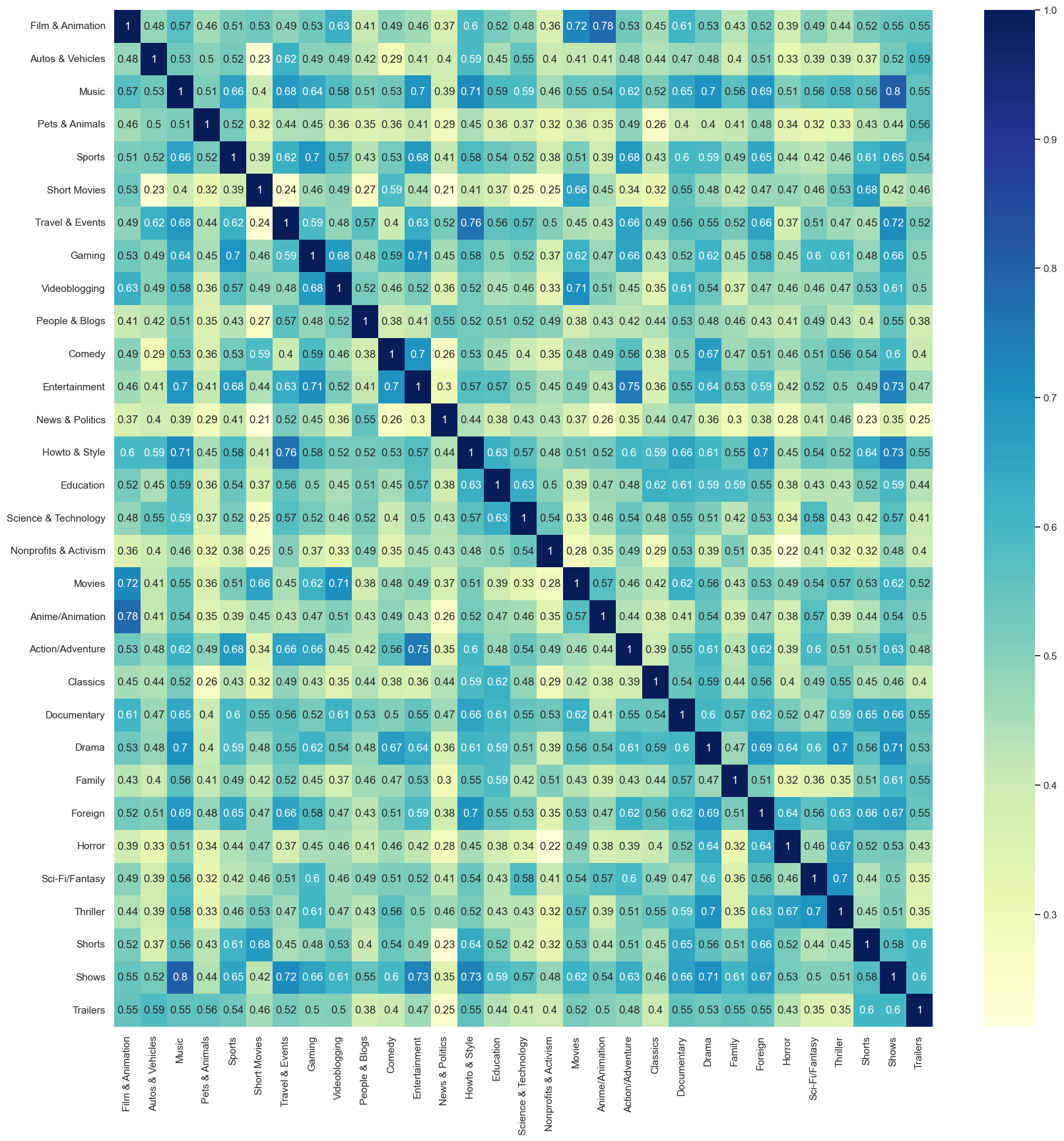
To understand how much entropy should increase when a user jumps from content to content we use Natural Language Processing. For this hack, we focused on Youtube videos only however we can prove that our method can be extended to any form of content.
We start with a fixed number of 20 broad categories and classify each video as one of them. There are two steps to calculating the increase in entropy.
- Classify the content into 1 of the N categories: For this, we either fetch the video details from Youtube API and find the assigned category of the video.
- Mesure the semantic differences in the categories: Since the category names are in English, we use pre-trained DisillBERT to find feature vectors for all the categories. Then we compute the cosine similarity between the previously watch genre and the current one.
1-similarityis the value we as the increase in entropy
Challenges I ran into
Understanding the structure, and the lifecycle of chrome extension was tough, Especially due to Google migration from manifest v2 to v3 and not enough resources being online on v3. Moreover debugging async calls and message passing from background service workers to injected content scripts was a challenge
Inference of any ML model is computationally expensive. Running in on the fly, especially on the client side javascript is even more challenging. Thus we had to preprocess our category similarity in python and load it in JS during execution.
Accomplishments that I'm proud of
A working implementation of the entire project in 24hour with a perfectly coordinated effort was beyond our imagination.
What I learned
What's next for The Mindful Scrollers
Expand the feature to other Websites. For this, we would collect data and train a supervised classifier to map BERT embeddings of titles to categories. Then we infer using titles for any content outside youtube. The remaining process can remain the same.

Log in or sign up for Devpost to join the conversation.