-
-

Look of the desktop application
-
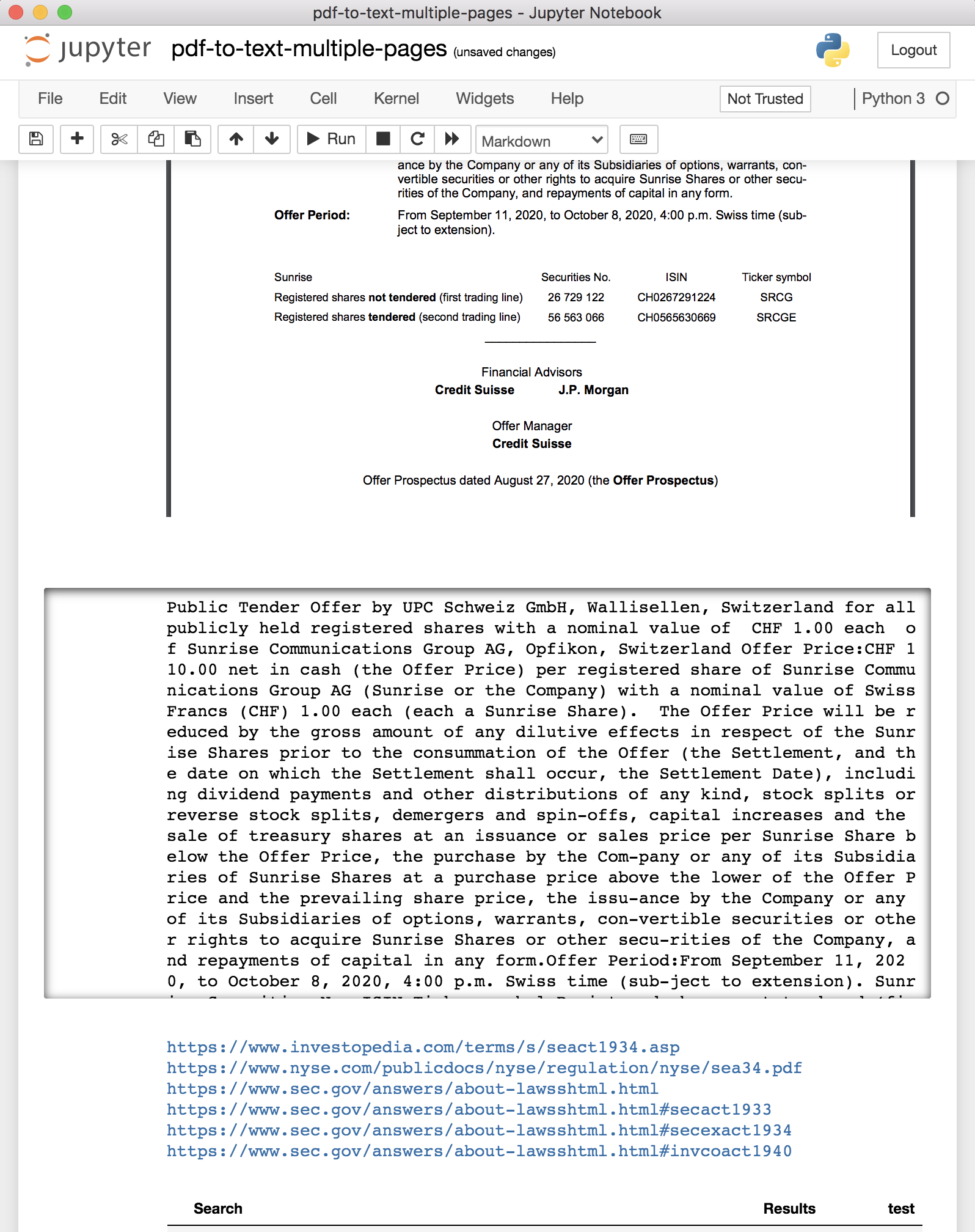
One of the notebooks with the input document
-
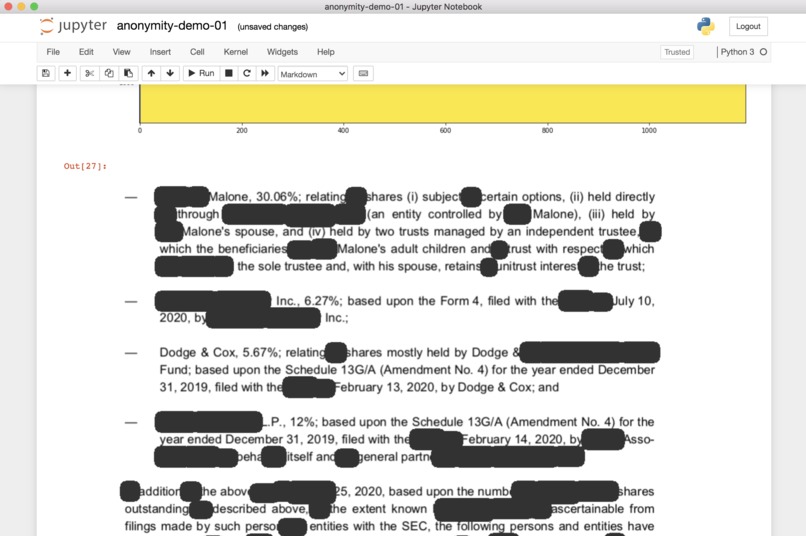
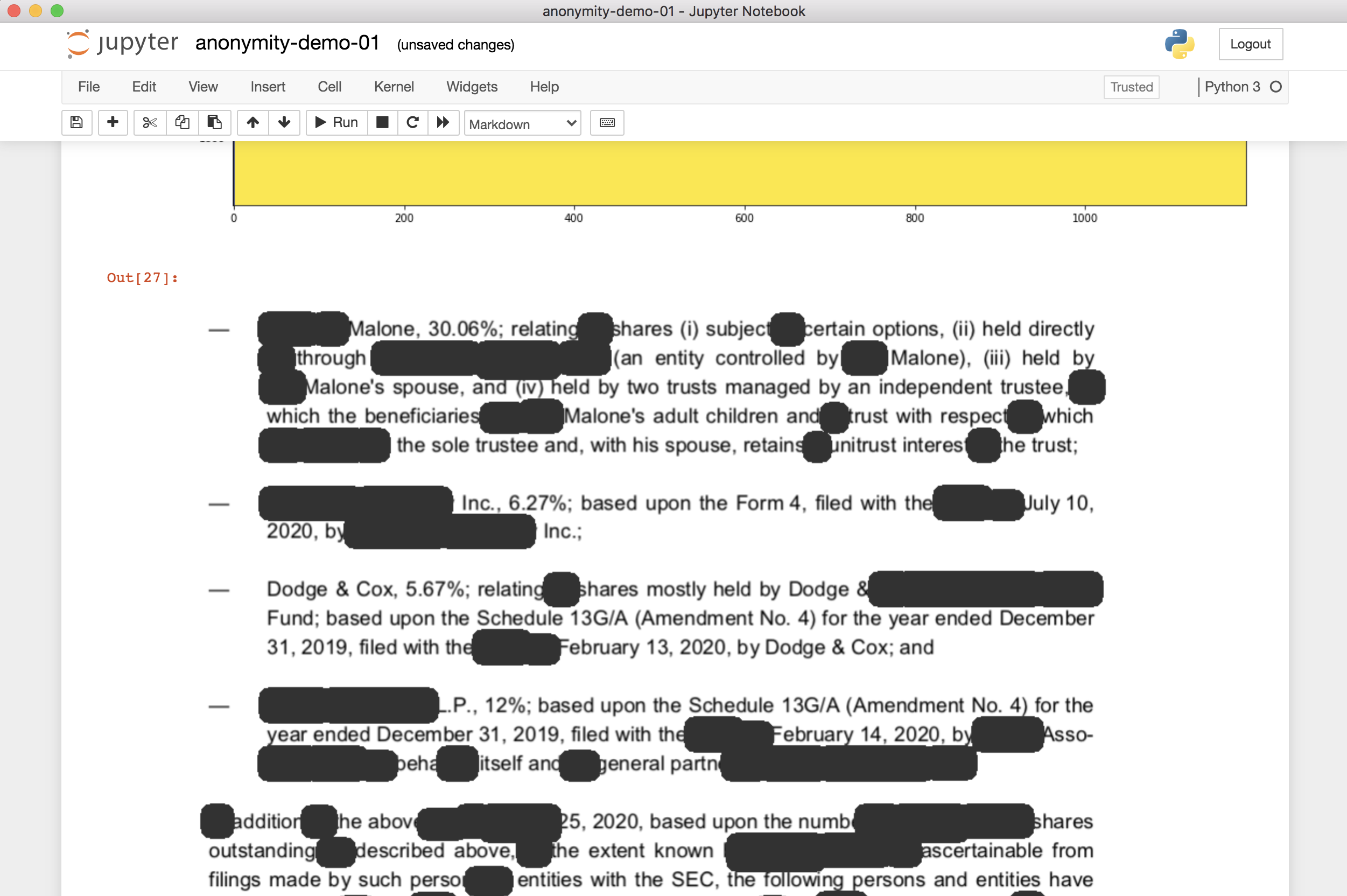
a notebook with an output document
-

Notebook with input and partial output
-

mobile view of the suuite website
-

mobile view of the suuite website with filter applied



Inspiration
The LegalTech Suite came as a natural response to the set of challenges presented by the Legal Tech Team. Natural because when you set the User Experience (UX) as the most important feature of your project, beautiful things happen. First, you realise that the user needs one, and only one point of access to the tools. She/he should be able to find all that is required to perform her/his tasks in a single place, something easy to infer when the challenges were presented.
Once the main objective is set, the tools were selected according to the most up-to-date tools in ML and static web pages development (Open Source), and desktop app cross-platform development.
Desktop and cross-platform because this is how the lawyers perform this difficult job, in a laptop or a desktop computer. This feature was carefully analysed and discussed with the Legal Tech Team.
What it does
Machine Learning and Jupyter join forces to analyse legal documents. It includes algorithms that:
Anonymise legal documents
Taking legal documents and using OpenCV for Computer Vision, it extracts the information that other ML tools use to identify names, companies, cities and countries, among other features from the text, and perform anonymisation of those fields. This is a capital task that takes a lot of time to the lawyers and their assistants. Some of those documents contain 200 or more pages. So, any help, particularly Smart an automatise help, can boost the productivity of any team, and minimise mistakes that can have real consequences when performing business. Constant fine-tuning and more robust models will be the next step. But the prototype is entirely functional and complete the task in less than a second.
Smartify legal documents
Another script uses algorithms to identify keywords and names, similar to the previous section. Still, in this case, the idea is to enhance the information that the lawyer can have immediate on the document—imaging a case of "Augmented reality" for your PDF. The working prototype does not perform this enhance document yet, but it does identify key terms and look for those automatically on the internet. Also produce an HTML version of the paper where the user can get context directly in the text that is reading in the form of popups.
Aggregation of legal documents to identify patterns and generate templates
Created a simple mockup of how text detection and pattern recognition can be used to generate an ordered collection of documents with standard features and concepts that can allow identifying candidates to templates for similar cases. Also, boosting the productivity of the users.
How I built it
It was built using Jupyter notebooks running in a Ubuntu Virtual Machine serving as a local server in the machine of the user. The Electron.io framework was used so to have a clean cross-platform design and deployment, while Hugo framework was used to create the web-app. A desktop application is the best proposal to solve the current needs, and it is a way to adapt to the user as much a technological possible. And minimise the friction in the interactions. It was critical during all the time that the design was under construction to keep in mind that the learning curve for this product needs to be smooth.
Challenges I ran into
The ML learning technologies used are complicated. Nothing new there, but it is relevant to keep in mind that this kind of product we will need constant improvements, and it will learn from more and more cases. Being better with each iteration.
Accomplishments that I'm proud of
Genuinely proud of merging technologies and techniques as I never did before. Computer Vision was the best of the learnings. The same approach will be applied in two other challenges, even after the event is over.
What I learned
I learn some insides on the dynamic of the future users of this suite: the Law firms and employees. I had the opportunity to get direct feedback from the Legal Tech Team.
What's next for The LegalTech Suite
I want to address all the challenges of this collection. Also, to deploy some computer elements in the cloud. Something that I must say, it was not done because this kind of documents contains sensitive information and the law firms do not distribute that information out of their premise —an extra reason for the desktop application development.




Log in or sign up for Devpost to join the conversation.