-
-
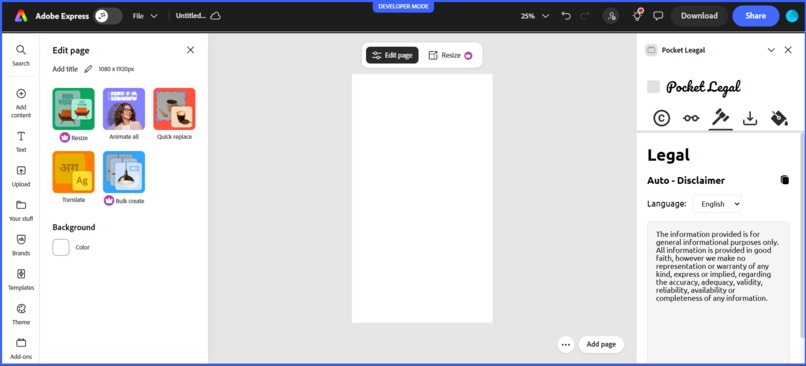
Auto-Disclaimer Prototype
-
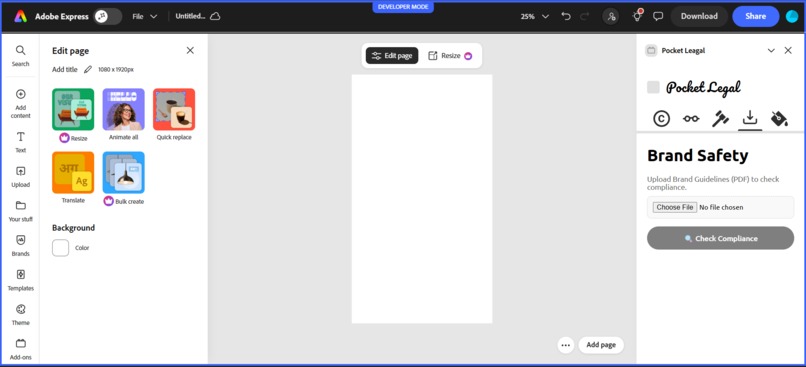
Brand Safety Compliance enforcer
-
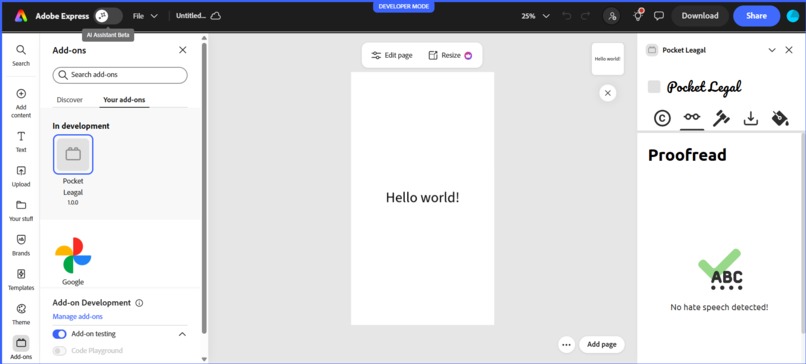
Profanity Filter
Inspiration
In today's digital age, content creators face mounting pressure to ensure their work is compliant, inclusive, and legally sound across global markets. A single piece of offensive content or copyright violation can damage brand reputation, trigger legal action, or alienate audiences. We noticed that designers and marketers often lack real-time tools to catch these issues before publication.
Pixel-Proof was born from a simple question: What if AI could act as a guardian angel for content creators, catching compliance risks before they become costly mistakes?
We envisioned an Adobe Express add-on that would seamlessly integrate into creative workflows, providing instant feedback on hate speech, copyright violations, and brand safety—all powered by cutting-edge machine learning.
What It Does
Pixel-Proof is an enterprise-grade Adobe Express add-on that provides real-time content compliance analysis through three core capabilities:
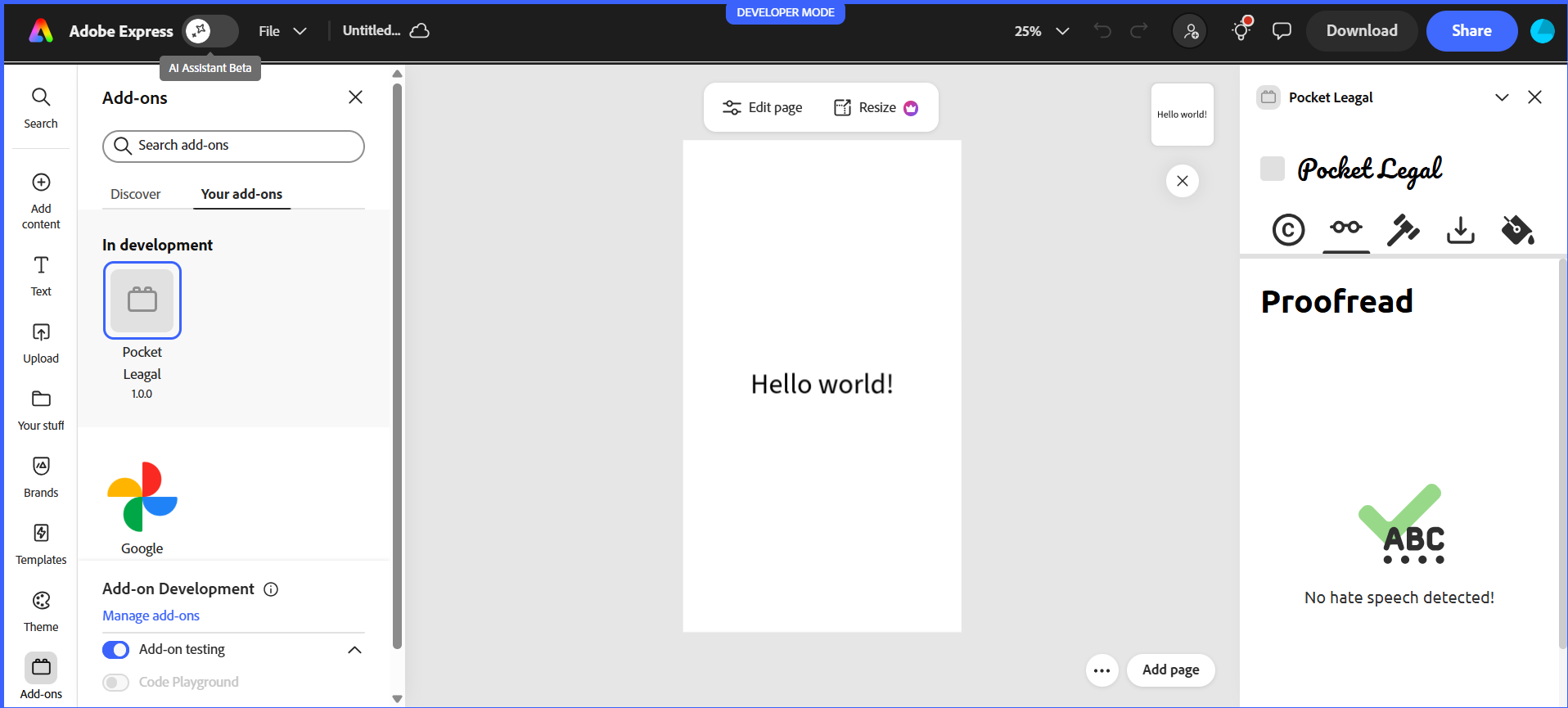
🛡️ Hate Speech Detection
- Analyzes text using fine-tuned HateBERT transformer models
- Provides segment-level analysis with confidence scores
- Visually highlights problematic content in red directly within documents
- Processes both text nodes and OCR-extracted text from images
🔍 Copyright & Trademark Detection
- Recognizes logos using color descriptor-based matching
- Searches against a database of 4.2 million brand logos
- Detects trademark violations and copyrighted brand usage
⚖️ Legal Compliance Tools
- Auto-generates multilingual legal disclaimers (English, Spanish, French, German)
- Customizable disclaimer templates for different industries
- Brand guideline compliance checking
How We Built It
Architecture: We designed a three-tier architecture optimized for performance and scalability:
Adobe Express Add-on (React + TypeScript)
↓
Node.js Backend (Express Server + MCP Server)
↓
Python ML Service (Flask + HateBERT)
Challenges We Faced
1. Adobe Express SDK Limitations
- Challenge: The SDK had limited documentation for advanced text manipulation
- Solution: Extensive experimentation with the Document API, reverse-engineering examples, and creative workarounds for text styling
2. ML Model Performance
- Challenge: HateBERT model (110M parameters) took 5-10 seconds to load on startup
- Solution: Implemented model pre-loading on service startup and kept the model in memory for fast inference
3. Cross-Origin Communication
- Challenge: Sandbox isolation prevented direct API calls from the document context
- Solution: Designed a runtime API proxy pattern for secure UI-to-sandbox communication
4. Logo Recognition Accuracy
- Challenge: Initial color-based matching had ~20% false positive rate
- Solution: Refined color descriptor algorithm, implemented stricter thresholds, and added chi-squared distance metrics
5. OCR Integration
- Challenge: Tesseract.js processing was slow (3-5s per image)
- Solution: Optimized image preprocessing, implemented parallel processing for multiple images, and added progress indicators
6. Real-time Visual Feedback
- Challenge: Highlighting hate speech in documents without disrupting layout
- Solution: Developed custom text node traversal algorithm that preserves document structure while applying styling
What We Learned
Technical Learnings:
- Deep understanding of transformer-based NLP models and their practical deployment
- Mastery of Adobe Express SDK and add-on development patterns
- Advanced image processing techniques with OpenCV
- Microservices architecture design for ML applications
- Real-time document manipulation in constrained environments
Product Learnings:
- The importance of visual feedback in compliance tools
- Balancing accuracy with performance in real-time systems
- Designing for enterprise workflows and compliance needs
- The value of multilingual support in global markets
Process Learnings:
- Iterative development is crucial when working with new SDKs
- Comprehensive documentation saves countless hours of debugging
- Performance optimization should be data-driven, not assumption-based
- User feedback is invaluable for feature prioritization

Log in or sign up for Devpost to join the conversation.