The Ledger of the Unknown
Most small businesses run thousands of card transactions a month and have no real way to interrogate them. The data sits in a statement nobody reads. We wanted to make that data talk, and we wanted the act of reading a ledger to feel like something other than a chore.
So we built an expense intelligence platform that wears the skin of a storybook. An original, hand-drawn Keeper (styled after Over the Garden Wall) narrates a fleet company's spending across a two-page book spread, walking and turning pages between chapters. Underneath the illustration is a real analyst.
What it does
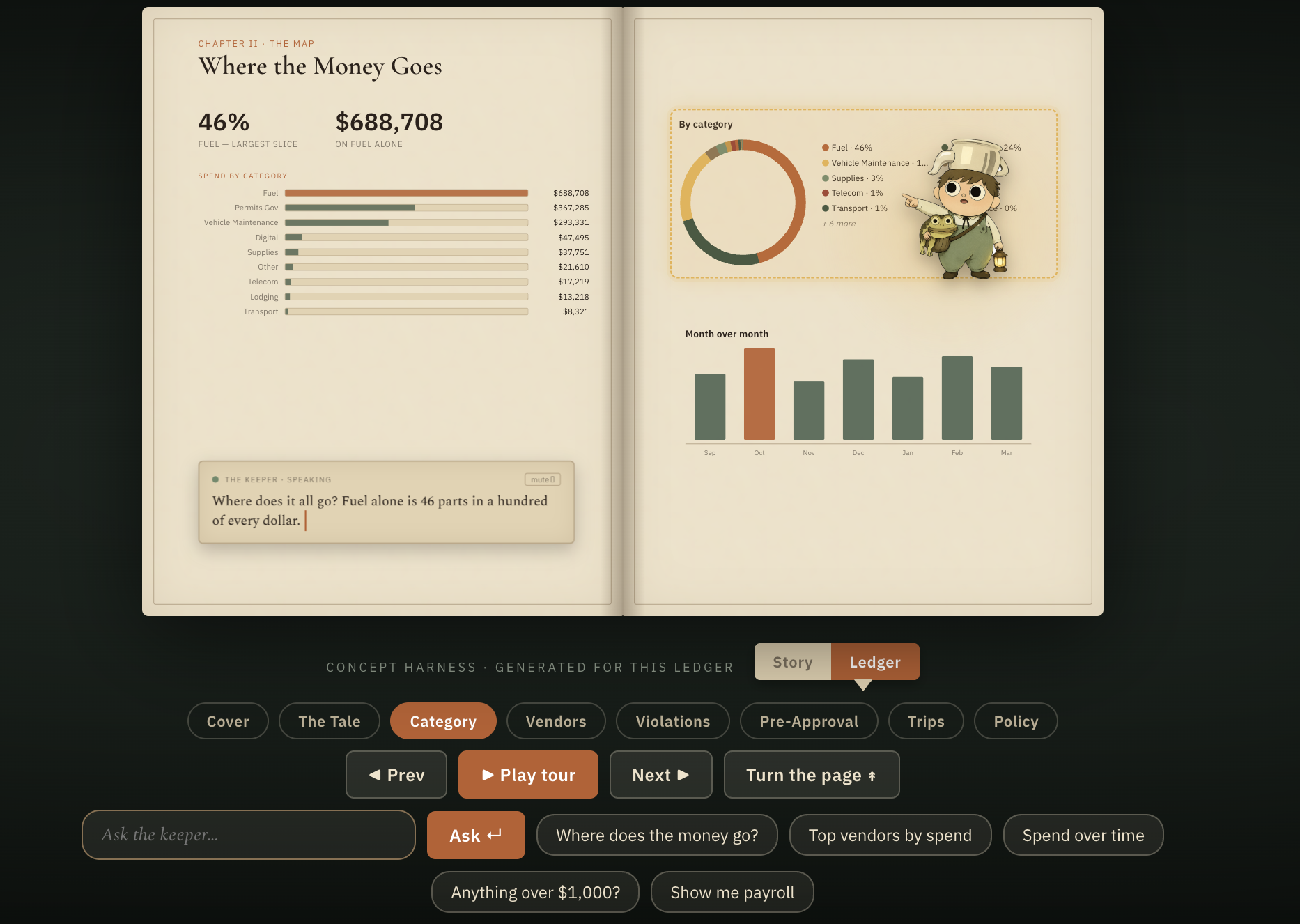
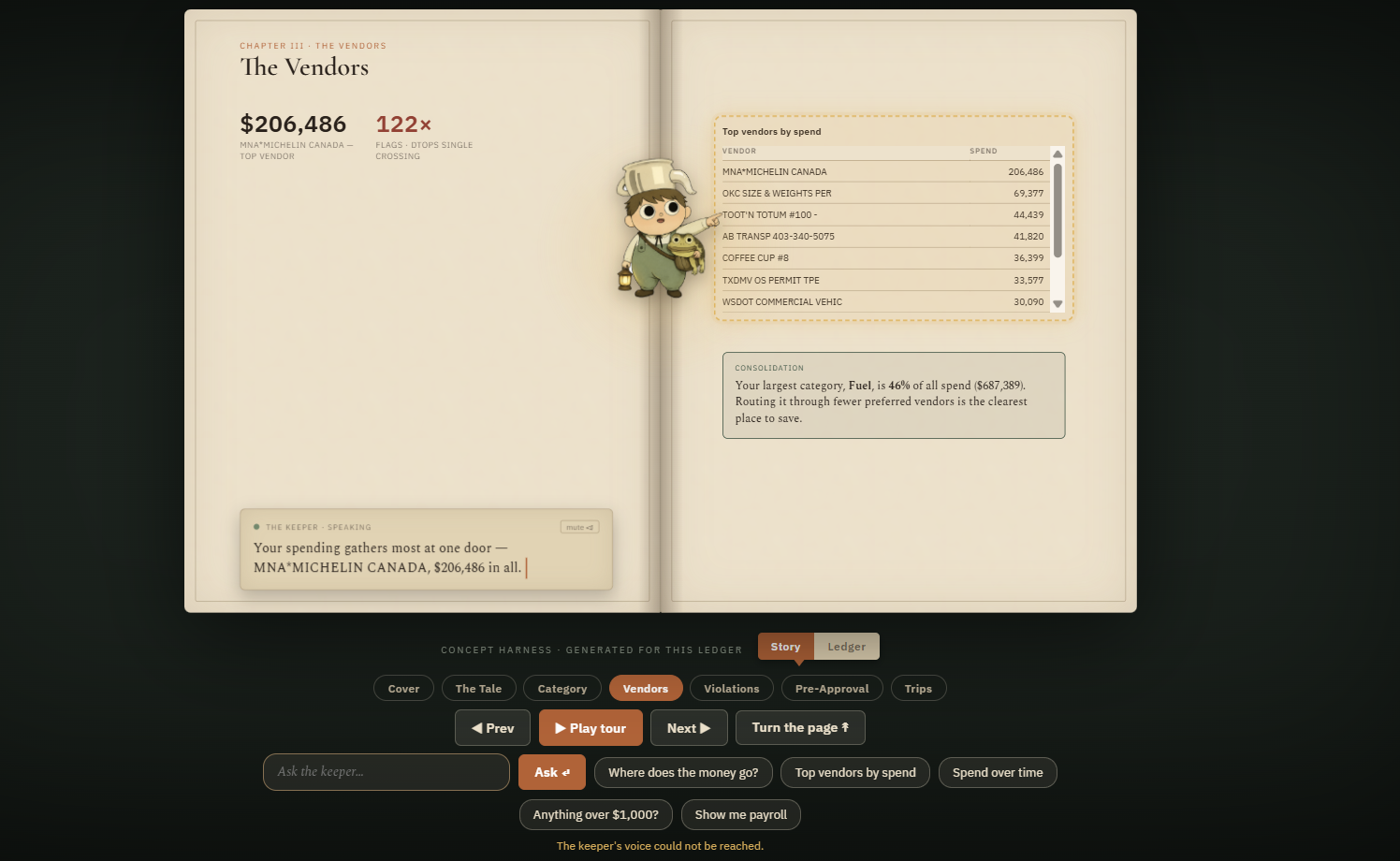
Talk to your data. Ask a question in plain English and get an answer with the right visualization (a chart, a table, or just a number). It handles follow-ups and reasons across categories and time periods without re-explaining the context. This is not a fixed set of canned queries. The model writes SQL against the live data, so any grouping you can think of is answerable.
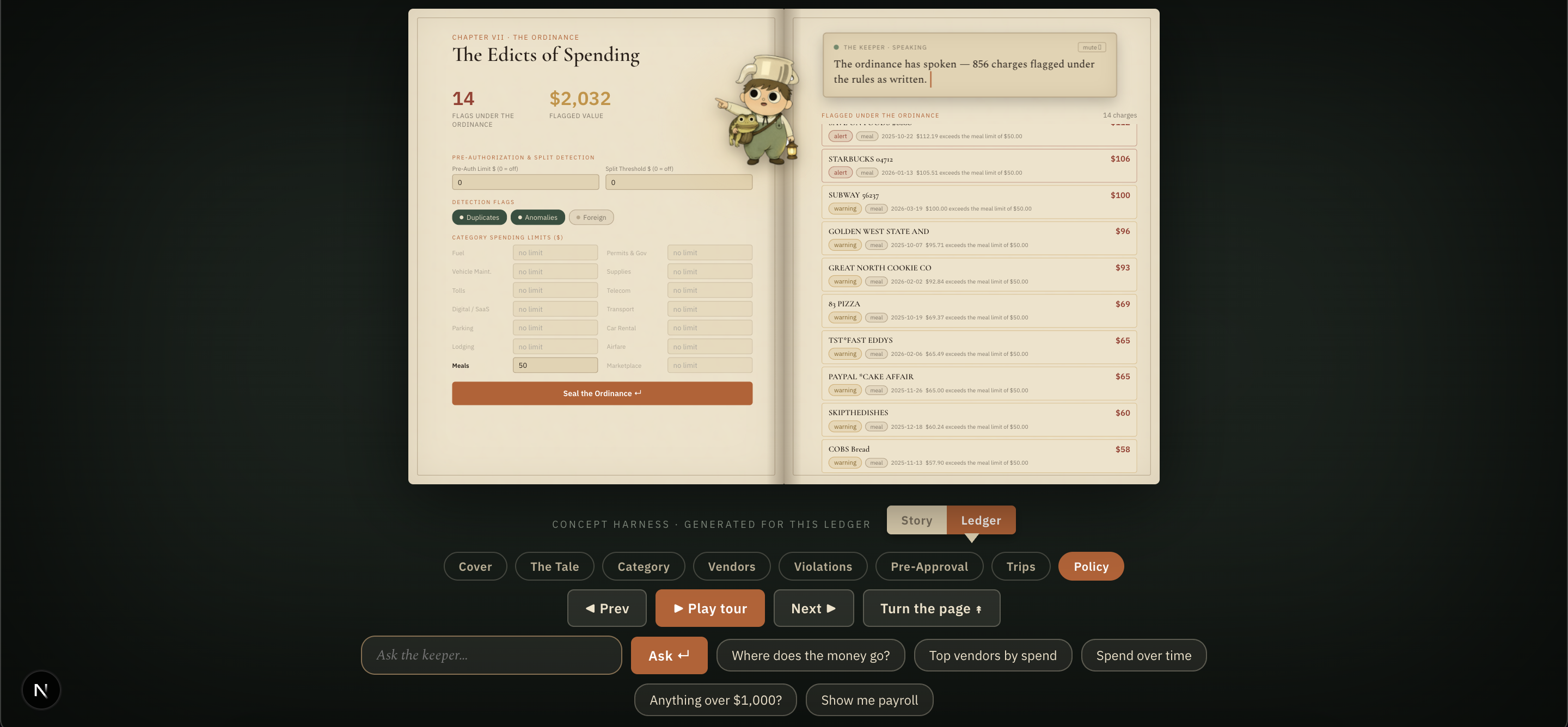
Policy compliance engine. Every transaction is checked against the company's expense policy. The finance team sets the rules: the pre-authorization threshold, per-category limits, and which checks to run. The scan updates the moment a rule changes. Code catches the determinate cases (duplicates, split charges that dodge a limit, statistical outliers, foreign and gift-card spend); the AI handles ambiguous ones.
AI pre-approval. When a charge needs sign-off, the approver shouldn't have to hunt for context. A pre-approval decision needs to know who is spending, what department they belong to, and how the request compares to their past behavior, and a single fleet-card statement carries none of that. So we built an employee layer. Each transaction is mapped to a spend category, then grouped by category, geography, and date window, so a reconstructed employee represents a coherent route and spending pattern. A department is inferred from their dominant activity (fuel and tolls → Operations, permits → Compliance, hotels and meals → Sales & Travel, retail → Administration, cash and fees → Finance). Pre-approval then shows the approver everything in one view: the request, the employee's spend history and department, the budget remaining, and an AI recommendation to approve or deny with its reasoning. One reply instead of a back-and-forth.
Automated expense reports. Spend is grouped into reports, and the Keeper walks you through each one, narrating the main insights aloud — what was spent, where it went, and what got flagged — so a report reads like a passage in the book rather than a spreadsheet you have to decode.
How we built it
Next.js 15 (App Router) with React 19 and TypeScript on the front, an in-memory SQLite mirror of the dataset on the back. The "talk to your data" feature is a genuine agentic loop, not a single-prompt wrapper: the model gets one tool, run_sql, and reasons over up to six turns at temperature 0 to settle on an answer. A guarded read-only query layer rejects anything that is not a SELECT, blocks writes and multiple statements, and caps result size, so model-authored SQL can never mutate the data.
Charts are derived deterministically from the returned rows (no second model call) by scoring each query and picking the most chartable one. A separate narration pass turns the prose answer into something the Keeper can speak and emote, with a severity score that maps to its mood. Voice is ElevenLabs running a cloned narrator. Everything resolves through a single typed API client that never throws, so a failed model call or a network drop degrades into a fallback instead of a crash.
What we learned
Grounding is most of the battle. The honest numbers only appeared once we defined the difference between a purchase and a payment in the data dictionary (rows without a merchant category are fees and EFT payments, not spend). Before that, the agent happily reported a $264K bank transfer as the largest purchase. We wrote a ground-truth test that asserts the real figures (total spend, largest genuine purchase, exact foreign-transaction count) and ran it after every backend change.
We also learned how easy it is to build three clocks that drift apart. The page-turn, the Keeper's mouth animation, and the narration audio each ran on their own timer, so the voice and the visuals fell out of sync. Fixing it meant making the tour wait for the audio to actually finish before turning the page.
Challenges
The dataset is a single fleet card at the category and trip level, with no employee or department columns. The brief assumed a multi-employee org. Rather than fake structure that was not there, we adapted: category budgets instead of department budgets, monthly route reports instead of per-employee expense reports, merchant-level patterns instead of per-person repeat-offender tracking. Naming what the data could and could not support, and building honestly against it, was the real constraint.
Built With
- better-sqlite3
- elevenlabs
- google-gemini
- next.js
- node.js
- react
- sqlite
- tailwindcss
- typescript


Log in or sign up for Devpost to join the conversation.