-
-

logo
-
architecture
-

screenshot app

Inspiration
Site Reliability Engineering (SRE) is often a high-stress job, especially when production incidents occur at 3 AM. The standard protocol involves opening a laptop, logging into VPNs, typing complex log queries, and staring at static dashboards.
We asked ourselves: What if we could simply talk to our infrastructure?
Inspired by the concept of hands-free, real-time operations, we wanted to build a true "Cloud Copilot." Not just a text chatbot that reads documentation, but an active, voice-native agent that can monitor live systems, analyze real-time error logs, and execute recovery actions while we simply converse with it.
What It Does
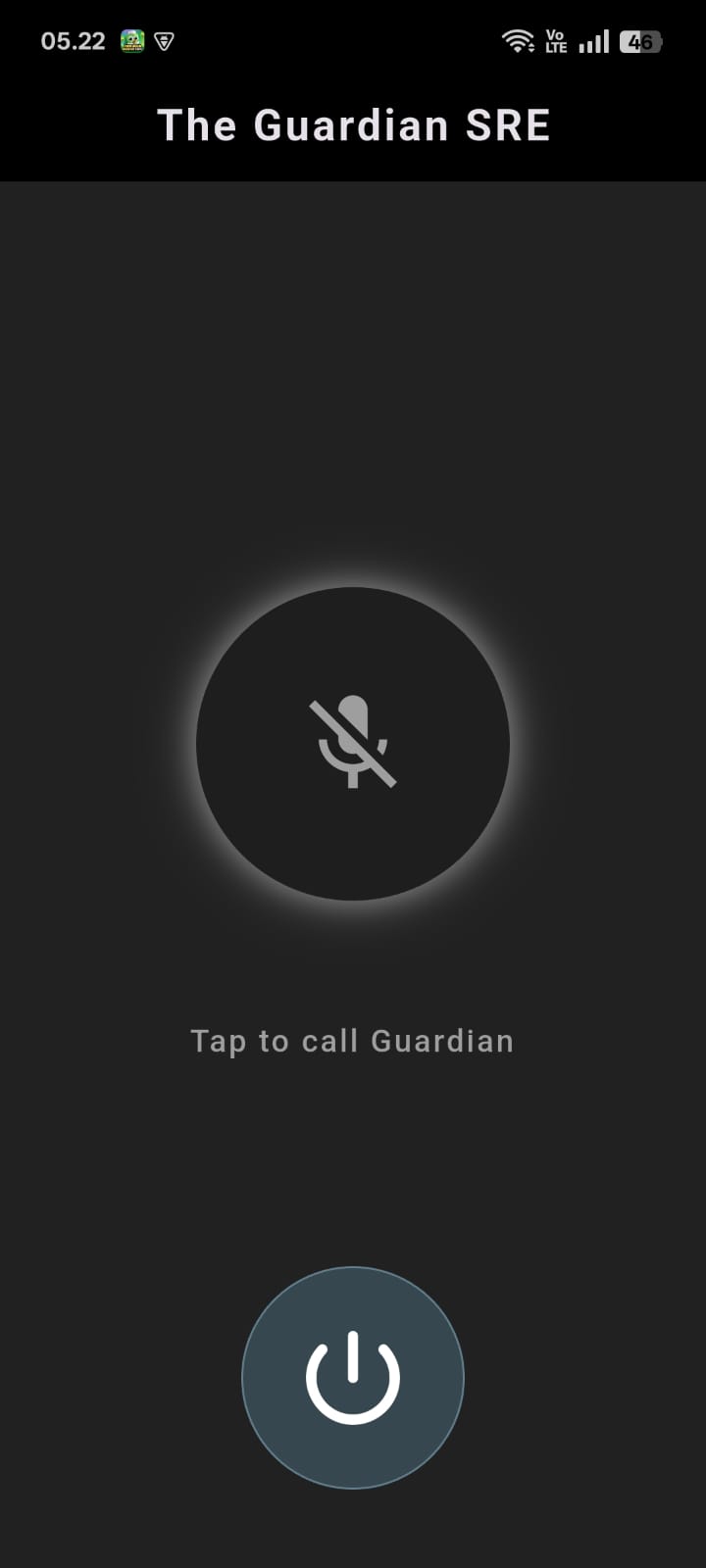
The Guardian SRE is a voice-activated, multimodal operations copilot powered by the Gemini Live API.
Instead of typing, SREs can press the "Guardian Orb" and speak naturally:
"Guardian, check the LocaSentiment API."
The agent will:
1. Listen & Understand
Process the natural language via Vertex AI.
2. Ground on Reality
Query the Google Cloud Logging API in real-time to check for active severity logs on the target service.
3. Speak the Results
Report the system health back to the user using native generative audio.
4. Display a Multimodal HUD
Emit out-of-band telemetry (via Socket.IO) to display a hacker-style Terminal HUD on the mobile screen simultaneously.
5. Execute Actions
SREs can interrupt the agent mid-sentence to say:
"Wake that service up"
This triggers an actual HTTP Cold Start ping to the dormant Cloud Run instance.
How We Built It
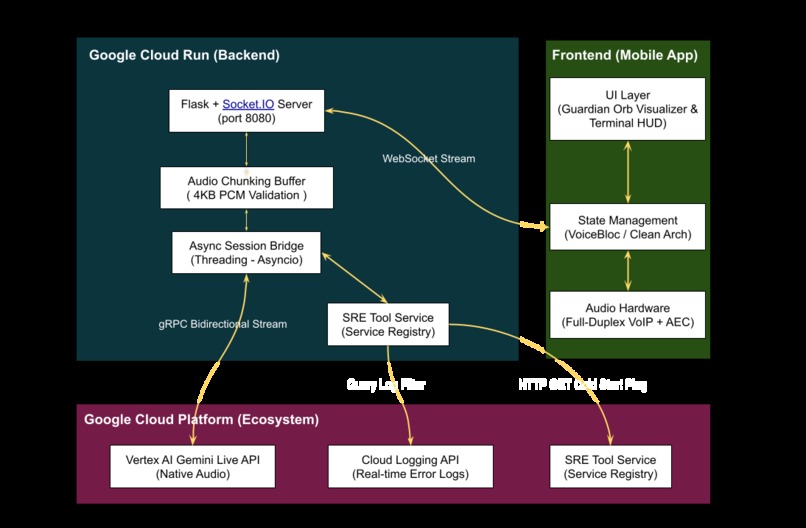
We designed a robust, event-driven streaming architecture:
1. The AI Core
We utilized the Google GenAI SDK (Gemini 2.5 Flash Native Audio) to establish an asynchronous, bidirectional gRPC stream.
2. The Middleware (GCP Cloud Run)
We built a Python backend using Flask and Socket.IO.
This acts as the bridge, buffering 16-bit PCM audio chunks and executing SRE Tool Calls (querying logs, pinging services).
3. The Frontend (Flutter)
We built a mobile application using the BLoC pattern for state management.
We bypassed standard OS audio restrictions by aggressively configuring the AudioContext to VoIP Mode, enabling Hardware Acoustic Echo Cancellation (AEC).
4. Out-of-Band Signaling
We separated the voice stream from the UI metrics stream.
When the Python backend executes a tool, it broadcasts a JSON payload via WebSocket to trigger the Flutter Terminal HUD in real-time.
Challenges We Ran Into
Building a true real-time, interruptible voice agent is fundamentally different from building a text-based LLM app.
We encountered several severe technical hurdles:
1. The "Mic-Drop" OS Restriction
Android/iOS naturally kills the microphone when media is playing to prevent acoustic feedback.
This destroyed our Full-Duplex Interruption goal.
Solution:
We forced the app into VoIP (Voice Communication) mode, leveraging hardware AEC.
2. Gemini Error 1007 (Corrupt Payload)
Mobile microphones often emit odd-sized byte chunks, causing the Gemini gRPC stream to crash.
Solution:
We built a custom 4KB Even-Byte Chunking Buffer in Python to strictly validate the PCM stream before it reaches Google's servers.
3. Background Thread Context Crashes
When triggering our Multimodal HUD, emitting Socket.IO events from the Gemini background thread caused circular import deadlocks.
Solution:
We implemented strict Dependency Injection, passing the socket object directly into the SRE Service Class memory.
4. Simultaneous Tool Calls Deadlock
Gemini can emit multiple SRE tool calls at once.
Solution:
We implemented Batch Function Response Processing to prevent the state-machine from freezing.
Accomplishments That We're Proud Of
1. True Full-Duplex Interruption
We achieved a seamless experience where an SRE can literally cut off the AI mid-sentence to issue a new command — just like talking to a real human engineer.
2. Action-Oriented Grounding
We didn't just ground the AI on static documents.
We grounded it on live Google Cloud production logs and gave it the power to execute real network requests.
3. The Out-of-Band HUD
We successfully synchronized the AI's native audio response with a real-time visual UI (Terminal HUD) without adding any latency to the conversation.
What We Learned
We learned that Voice-Native UI is a completely different paradigm.
Latency is the enemy of natural conversation.
During this project we learned how to:
- Manipulate raw PCM byte streams
- Manage asynchronous state machines across mobile and cloud
- Structure tool-calling for LLMs in a way that is safe for production environments
What's Next for The Guardian SRE: Voice-Native Cloud Ops
This hackathon prototype is just the beginning.
The next steps for The Guardian SRE include:
1. Read/Write IAM Integration
Expanding capabilities beyond Cold Start pings to actually:
- Scaling up Cloud Run instances
- Rolling back deployments
- Managing infrastructure via voice commands
2. Database Telemetry
Integrating with Cloud SQL or Elasticsearch so SREs can ask:
"Why is the database slow right now?"
3. Incident Alerting (PagerDuty / Slack)
Allowing the agent to:
- Automatically wake up
- Page the on-call engineer
- Read the incident summary directly from the phone's speaker


Log in or sign up for Devpost to join the conversation.