-
-

The Earth Datasphere - Enabling natural environment data research at scale
-

Environmental data comes from a wide variety of sources and this is increasing rapidly with new innovations in data capture.
-

Data capture innovations provide major opportunities for science but also key challenges.
-
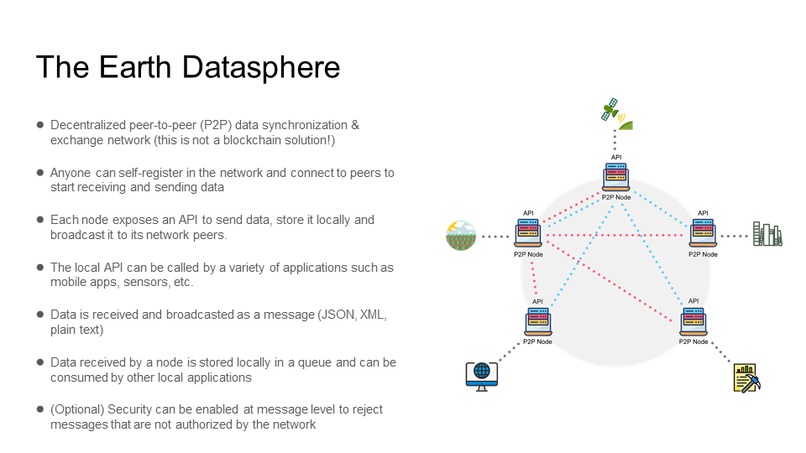
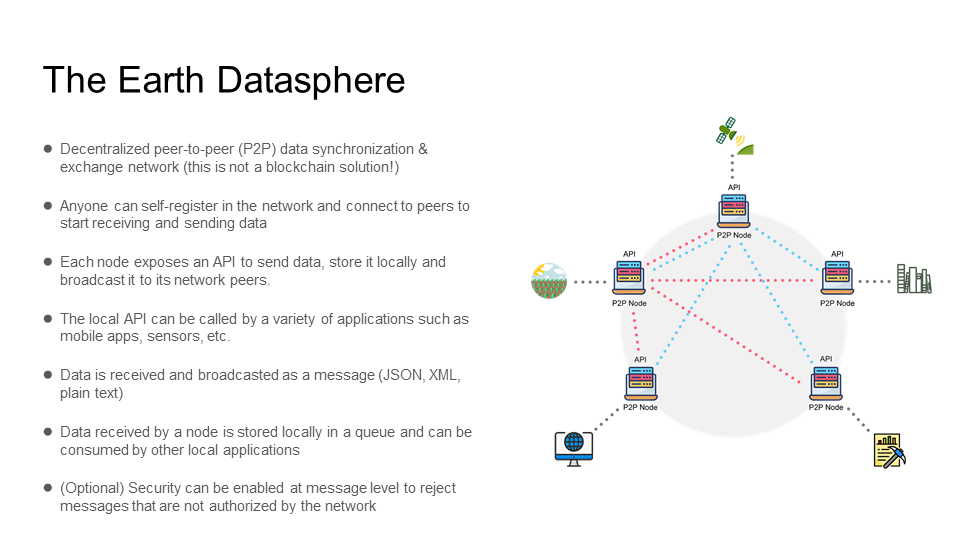
The Earth Datasphere is a decentralized peer-to-peer (P2P) data synchronization & exchange network
-

Start your own datasphere network! - National Geographic Challenge




Here’s the Whole Story
Data is central to earth and environmental sciences with significant investments in techniques for managing a wide range of environmental data. The data challenge is quite distinct from many fields of science with the most striking factor being the heterogeneity of the underlying data sources and types of data, hence the inappropriateness of the term “big data” in this field.
Environmental data comes from a wide variety of sources and this is increasingly rapidly with new innovations in data capture:
- Large volumes of data are collected via remote sensing where environmental phenomena are observed without contact with the phenomena, typically from satellite sensing or aircraft-borne sensing devices, including an increasing use of drones.
- Other data are collected via earth monitoring systems, which consist of a range of sensor technologies more typically in close proximity with the observed phenomena. Such sensors will monitor a range of parameters around the atmosphere, lithosphere, biosphere, hydrosphere, and cryosphere. Examples include weather stations and monitoring systems for water quality.
- Significant quantities of data are collected through field campaigns involving manual observation and measurement of a range of environmental phenomena and these are increasingly supplemented by citizen science data collected by enthusiasts with strong exemplars in the areas of soils data.
- There are large quantities of historical records that are crucial to the field. Many of these are digitized but, equally, significant quantities of potentially important information are not, particularly at a local level.
- Significantly, there is growing interest (as in many fields) of exploiting data mining, discovering data, and data patterns from the web and social media platforms, such as seeking images showing localized water levels during periods of flood or seeking evidence of air quality problems and impacts on human health. This area is in its infancy but is likely to grow massively over the next few years.
The Data Challenge
Data capture innovations provide major opportunities for science but also key challenges.
- Managing the variety and heterogeneity in underlying sources of data, including achieving interoperability across data sets;
- Reducing the long tail of science and making all data open and accessible through environmental data centers;
- Ensuring all data are enhanced with appropriate semantic meta-data capturing rich semantic information about the data and inter-relationships;
- Ensuring mechanisms are in place to both record and reason about the veracity of data;
- Finding appropriate mechanisms and techniques to support integration of different data sets to enhance scientific discovery and constrain uncertainty.
The Technical Solution
(This is not a blockchain application, does not use a blockchain ledger, has no consensus algorithm and it is built from scratch.)
Each node will host a P2P server that will connect and broadcast data (as JSON, XML, plain text messages) to its peers and a HTTP server that will expose an API (Application Programming Interface) so that other local applications (mobile apps, sensors, etc.) can call with data they wish to distribute to the network.

P2P Server
The P2P server listens via port 5002 (port can be changed) for incoming messages and connects to other peers via websockets (for example ws://another-node-address:5002).
Messages can arrive to the P2P server in two ways:
- via a local API call when the data (message) is stored locally and broadcasted to the network peers
- data (message) is sent by a peer in which case it is stored locally in a message queue (DATASTORE) so it can be later consumed by local applications (data pipelines, dashboards, etc.)
Data Manager
The Data Manager is focused on storing data locally in a DATASTORE queue when it arrives via API call or from a peer and in a BROADCAST queue when the data needs to be distributed to the network peers (via an API call).
HTTP Server
The HTTP Server exposes an API (POST /api/v1/datasphere) that handles calls from local applications (mobile apps, sensors, etc.)
Message Broker
A message broker will be required to store incoming and outgoing data. For this challenge I opted for RabbitMQ (open-source message-broker) because it's easy to setup (via a docker image) and works very well. Any message-broker that implements the AMQP 0.9 protocol should work with my solution.
Security
Security can be implemented at both the HTTP layer (API JWT token authorization) and at the P2P WS layer. At the P2P WS layer the message has an authorization token. In case the authorization token is invalid peers can reject the message and even remove the sending peer from the network.
Why It Matters
The Earth Datasphere makes it easy to share data across a network of peers, everyone has the same view of the same data and integration costs for anyone joining the network are practically nil. Anyone can join and leave the network at will and decide how much data they share (via API interface) and what they do with the data they receive from peers.
It has a significant impact in the research efforts where relevant data is scattered in multiple locations and stored in different formats (CSV files, plain text, DB tables, XML files etc.). Building data pipelines for a data science of the natural environment becomes incredibly easy.
For Datasphere networks where the same type of data is shared (see National Geographic Challenge slide example for a weather station) the benefit is in building a more complete view of the data (data can vary from location to location). This benefit cannot be achieved at scale in a centralized approach where a master (server) collects data from its slaves (servers) as the cost of integration would be too high.
Challenges
This solution scales incredibly well for real-time data synchronization. Some challenges:
Data harmonization over time - Let's assume we have an already established network with peers that exchange data. A new peer wants to join the network to share and receive data. Currently, he can only receive data that was broadcasted after the time he joined and no data before that time. Ideally, I want to do data harmonization in a decentralized manner and not have a centralized replication server that holds the historical data.
Peer discovery - Right now, if a new peer wants to join the network he needs to know the addresses of all the existing network peers. I want to expand the API functionality (something like GET /api/v1/peers) so that if I know the address of one peer, I can get a list of all active network peers and connect to them.
Future
Ideally, I am seeking for partners who are willing to try out this technology (would love to work with the National Geographic team). Long-term I want to make this technology a reality so partnerships are required to test it and grow it to maturity.
In the near-term I will work to further develop this concept into a production ready solution. The Earth Datasphere has the potential to cover many use cases.
A near-term roadmap:
- Work on the peer discovery functionality
- Implement security at every layer
- Better exception handling
- Data harmonization over time
- Make the technology cloud ready (serverless)
Built With
- api
- microservices
- mq
- node.js
- websockets





Log in or sign up for Devpost to join the conversation.