Inspiration
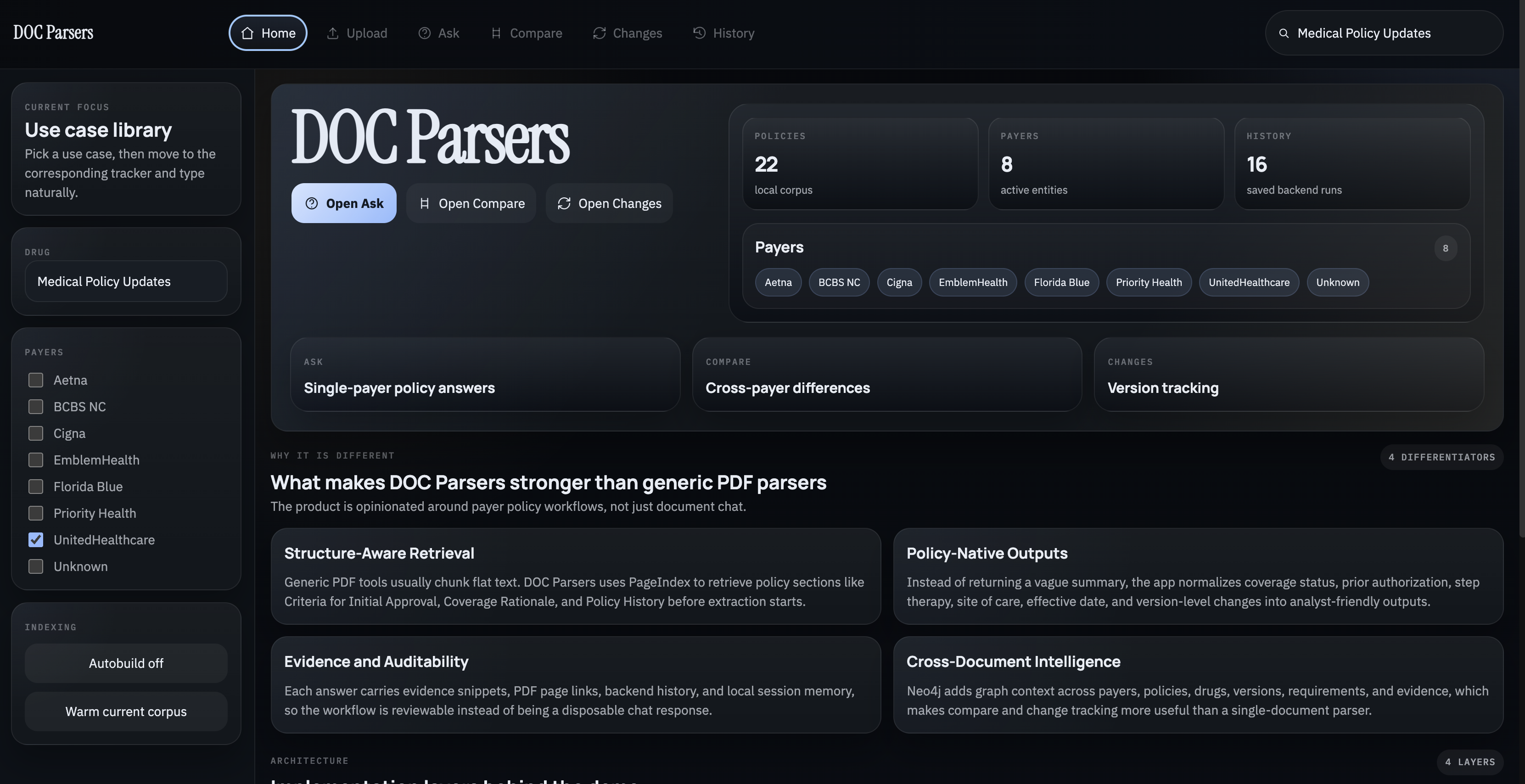
Medical benefit drug policy review is operationally painful. Analysts often need to answer practical questions like:
- is a drug covered
- does it require prior authorization
- what step therapy applies
- how do payer rules differ
- what changed from the last version
The source documents are usually long, inconsistent PDFs filled with policy history, references, and administrative text. Generic PDF chat tools can summarize them, but they do not consistently return analyst-ready policy intelligence.
We built DOC Parsers to turn those PDFs into a structured workflow for Q&A, comparison, and change tracking.
What it does
DOC Parsers supports five main user flows:
1. Ask
Users ask a payer-specific question for a drug and receive:
- a readable summary
- a detailed explanation
- evidence snippets
- links back to the exact PDF pages
2. Compare
Users compare multiple payers for the same drug and see normalized differences across:
- coverage
- prior authorization
- step therapy
- site of care
- effective date
3. Changes
Users compare two policy versions and get:
- meaningful change summaries
- field-level differences
- version-aware evidence
4. Upload
Users can upload a new PDF into the local corpus so it can be indexed and analyzed.
5. History
Users can reopen stored runs and review:
- prior requests
- saved responses
- evidence-backed explanations
How we built it
Frontend
- React
- Vite
The frontend separates the workflow into dedicated tabs:
- Home
- Ask
- Compare
- Changes
- Upload
- History
It also preserves local tab state with browser localStorage.
Backend
- FastAPI
The backend handles:
- document discovery
- upload and ingest
- retrieval orchestration
- OpenAI extraction
- comparison and change tracking
- saved run history
Retrieval
- PageIndex
This is one of the core differentiators.
Instead of treating a PDF as flat text, PageIndex helps us retrieve structured sections like:
- Criteria for Initial Approval
- Coverage Rationale
- Policy
- Scope of Policy
That improves downstream extraction quality because the model sees the policy logic instead of random chunks.
Extraction
- OpenAI API
We use OpenAI to convert retrieved evidence into structured policy outputs that are useful for analysts, not just generic summaries.
Storage
- SQLite for local operational storage and cached results
- local filesystem for PDFs, cache, and PageIndex artifacts
- Neo4j for cross-document graph relationships
Architecture Summary
High-level system flow:
- user interacts with the React frontend
- FastAPI receives the request
- PageIndex retrieves the right policy sections from local PDFs
- OpenAI extracts structured policy outputs
- SQLite and local files store operational data and artifacts
- Neo4j stores graph relationships across payers, policies, drugs, versions, requirements, and evidence
Challenges we ran into
- payer policy PDFs are inconsistent in structure and quality
- version tracking is hard when documents are very similar or partially duplicated
- retrieval quality matters more than generic chunking because the wrong section leads to the wrong answer
- graph persistence needs normalization to avoid noisy or duplicated relationships
- keeping the system local-first while still supporting structured extraction and graph analysis required careful layering
Accomplishments that we're proud of
- built a working end-to-end workflow across Ask, Compare, Changes, Upload, and History
- integrated PageIndex into a real policy-analysis pipeline
- connected the extracted outputs into Neo4j for graph-aware analysis
- added PDF page links and evidence-backed results instead of freeform answers
- preserved both backend history and frontend local session memory for demo and auditability.
What we learned
- for document intelligence, retrieval quality is often more important than prompt complexity
- domain-specific normalization is critical; analysts need structured outputs, not just summaries
- graph persistence becomes much more useful once the evidence and requirement relationships are clean
- local-first architecture makes a demo more stable and easier to reason about during development
What's next for The DOC Parsers
- improve version-diff accuracy for near-duplicate policy versions
- strengthen extraction for weaker payer documents
- add richer graph visualizations in the product
- expand the upload-to-index workflow for faster out-of-the-box onboarding
- improve export and analyst reporting flows

Log in or sign up for Devpost to join the conversation.