-
-
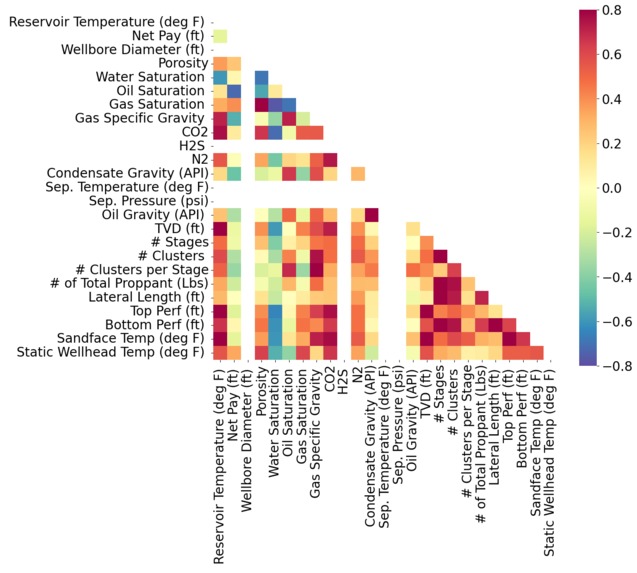
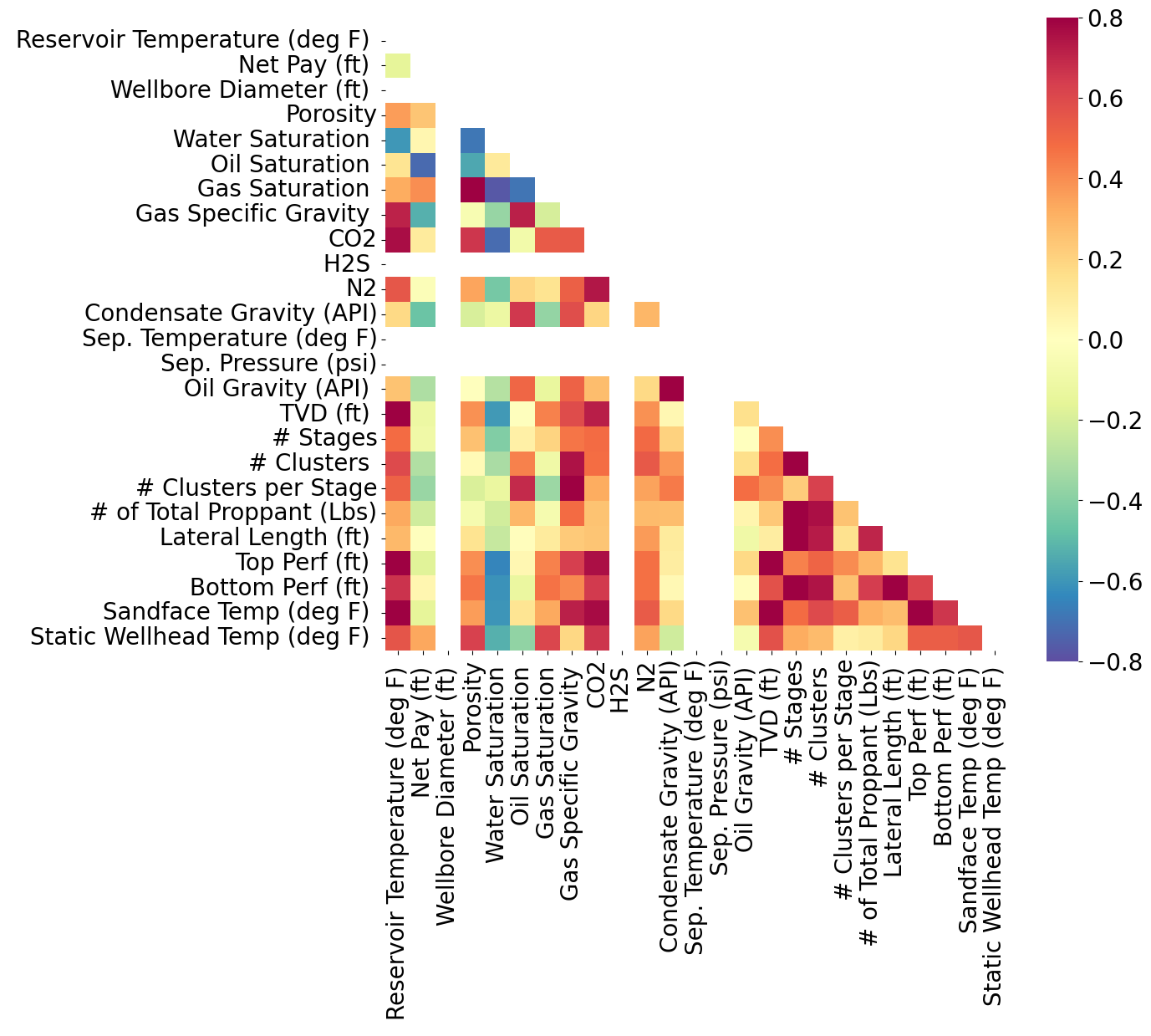
Heatmap for Variability in Well Data
-
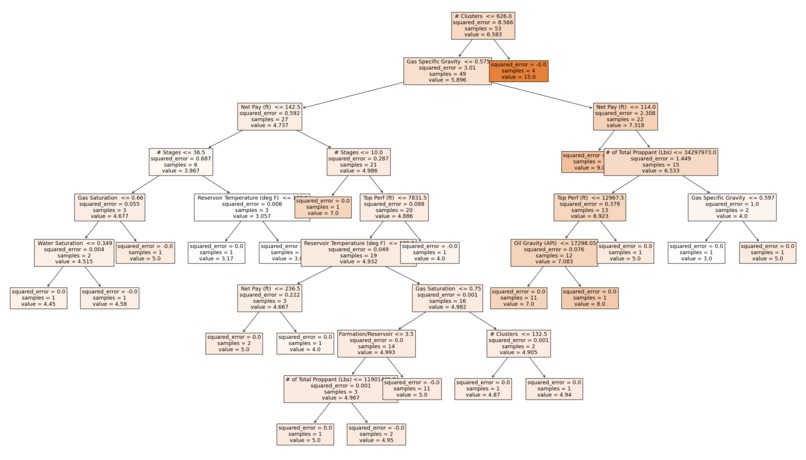
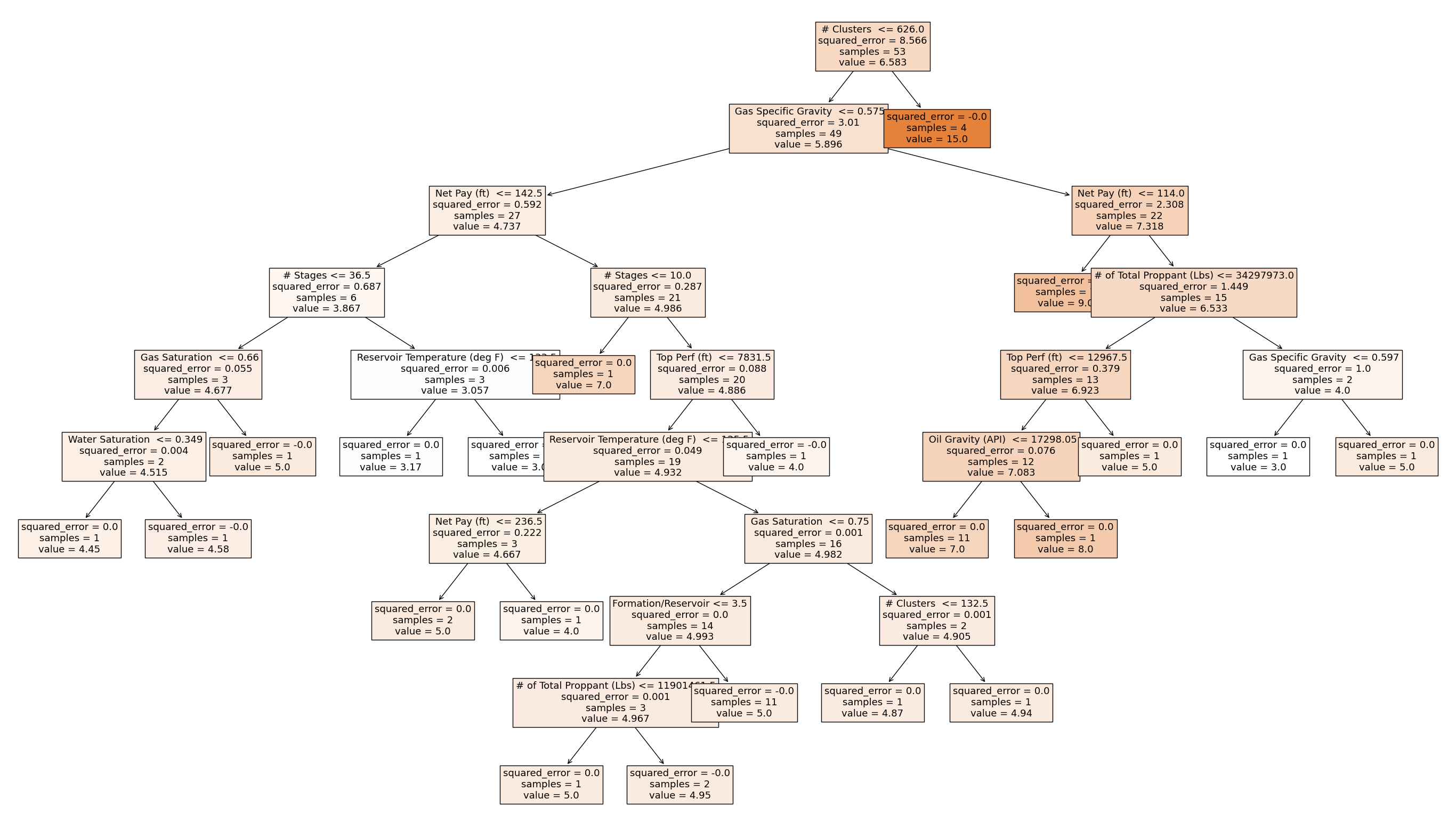
Data Tree Produced
Inspiration
Hydraulic fracturing or "fracking" has transformed the oil and gas industry, but also raises environmental concerns. As someone who cares deeply about our planet, I wanted to explore how data science could optimize fracking to extract resources responsibly. Fracking involves pumping fluid at high pressure to fracture shale rock, releasing trapped oil and gas. But determining how to best perforate the well is challenging. This project was inspired by a desire to use data to improve this process, reducing its footprint.
What it does
Fracking perforates the wellbore through explosions shaped into "clusters" across "stages" along the well. The number of perforation clusters greatly impacts results. Too few, and fractures are limited. Too many causes complex, uncontrolled fractures. Currently, the number of clusters is determined through trial and error.
My project uses machine learning to predict the ideal number of clusters. It analyzes parameters like rock properties and well geometry to build a customized model for the well. This data-driven recommendation optimizes clusters, improving yields while minimizing environmental impact.
How we built it
I used Python and scikit-learn to build a decision tree regressor, which splits data to make predictions. After exploring relationships in the dataset, I extracted key parameters like density and pay thickness as model features. Using techniques to avoid overfitting, it trains on this data to learn cluster patterns. By visualizing the tree structure and decision boundaries, I interpreted how different variables affect cluster numbers.
Challenges we ran into
The main challenge was the dataset's small size. With few samples, I had to employ validation methods like cross-validation to properly evaluate model performance during training. Feature selection and hyperparameter tuning were also critical to prevent overfitting. Finally, decision tree models can be complex black boxes. Visualizing the model provided insight into its reasoning.
Accomplishments that we're proud of
I'm proud of successfully applying data science to improve a real-world industrial process. The techniques used help ensure model quality despite limited data. I'm also happy with the model interpretability, which builds trust in its reasoning. Most of all, I'm excited this could help the oil and gas industry adopt more sustainable practices.
What we learned
This project gave extensive hands-on experience in areas like feature selection, managing model bias/variance, decision trees, and model diagnostics. I gained proficiency in sklearn and Python-based machine learning. Visualizing models also provided first-hand knowledge of decision tree internals.
What's next for The FrackOnTrack
To improve model accuracy, I plan to expand the dataset by collecting additional parameters and samples. Integrating geological data could also help. Packaging the model into an easy web application would benefit users without coding experience. There is also potential to apply similar machine learning techniques to related oil and gas processes like proppant amounts. I'm excited to continue developing data-driven solutions for responsible energy production.
Built With
- machine-learning
- matplotlib
- numpy
- pandas
- prediction
- python
- seaborn
- sklearn
- t-test
- treeplot

Log in or sign up for Devpost to join the conversation.