Eight specialists. One multi-morbid patient. A peer-to-peer A2A network that surfaces every conflict, preserves dissent, and synthesises a single concordant care plan.
Built on Prompt Opinion's MCP + A2A + SHARP + FHIR stack.

Inspiration
60% of Medicare patients live with two or more chronic conditions. Multi-morbidity drives ~$1.5 trillion of U.S. healthcare spend annually. And yet most clinical AI tooling still assumes you're optimising one disease at a time. Single-LLM RAG over a guideline corpus, or single-condition decision support.
The hard problem isn't retrieving cardiology guidance, oncology guidance, or nephrology guidance. It's reasoning across them when they pull in different directions.
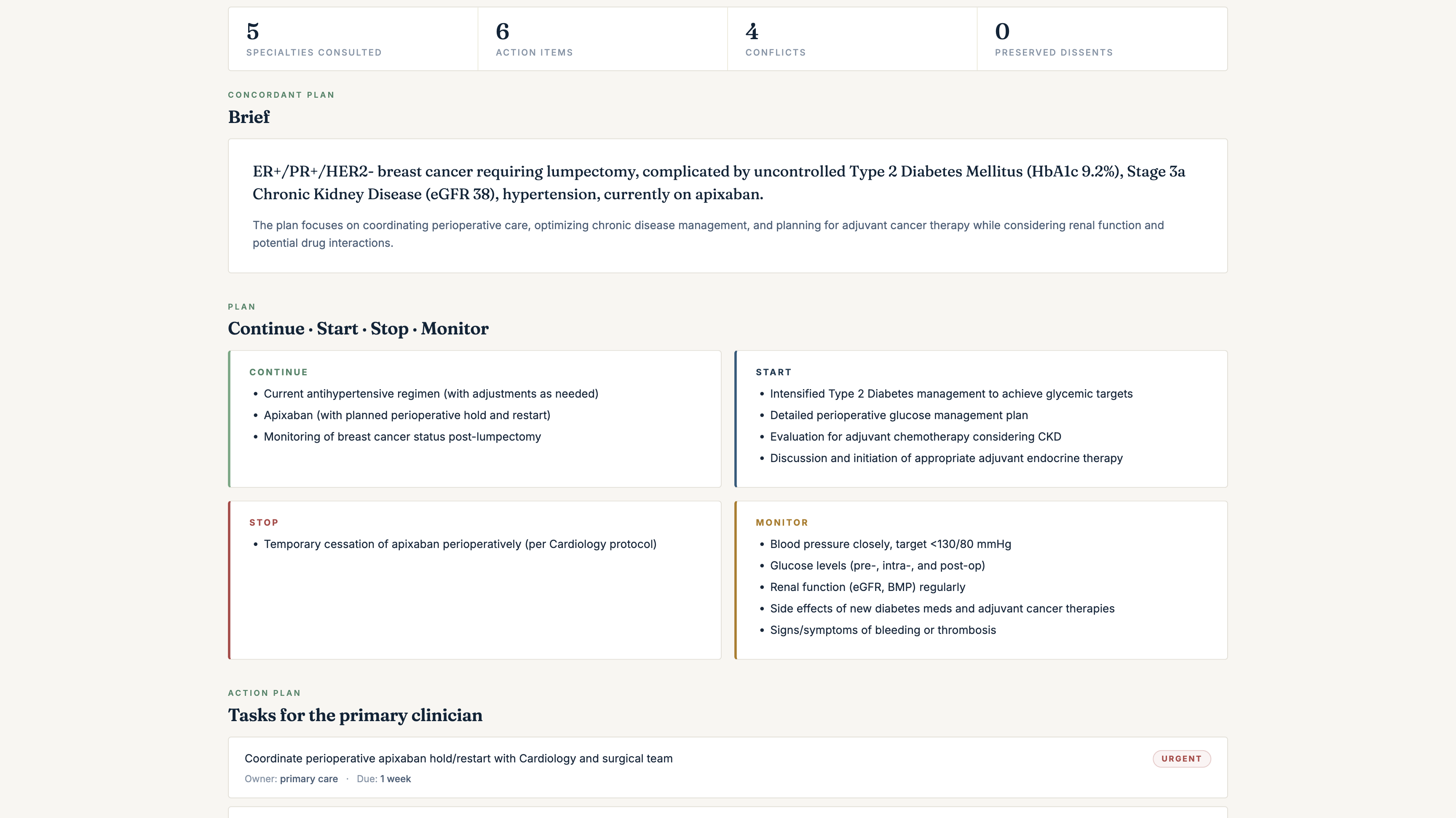
A 67-year-old woman with new ER+ breast cancer, paroxysmal AF on apixaban, T2DM with HbA1c 9.2%, and CKD stage 3a is guided in four different directions simultaneously by four different specialty literatures. Every recommendation a single specialty would make is reasonable in isolation. The interaction is where harm happens.
Microsoft's Healthcare Agent Orchestrator (HAO) showed multi-agent collaboration worked for cancer tumour boards. The Council generalises the architecture to multi-morbidity and inverts the topology: peer-to-peer A2A, not orchestrator-with-router. Eight specialty agents reason in parallel through their own clinical lens, exchange A2A messages, surface their conflicts explicitly, and synthesise one concordant plan with preserved dissent.
What it does
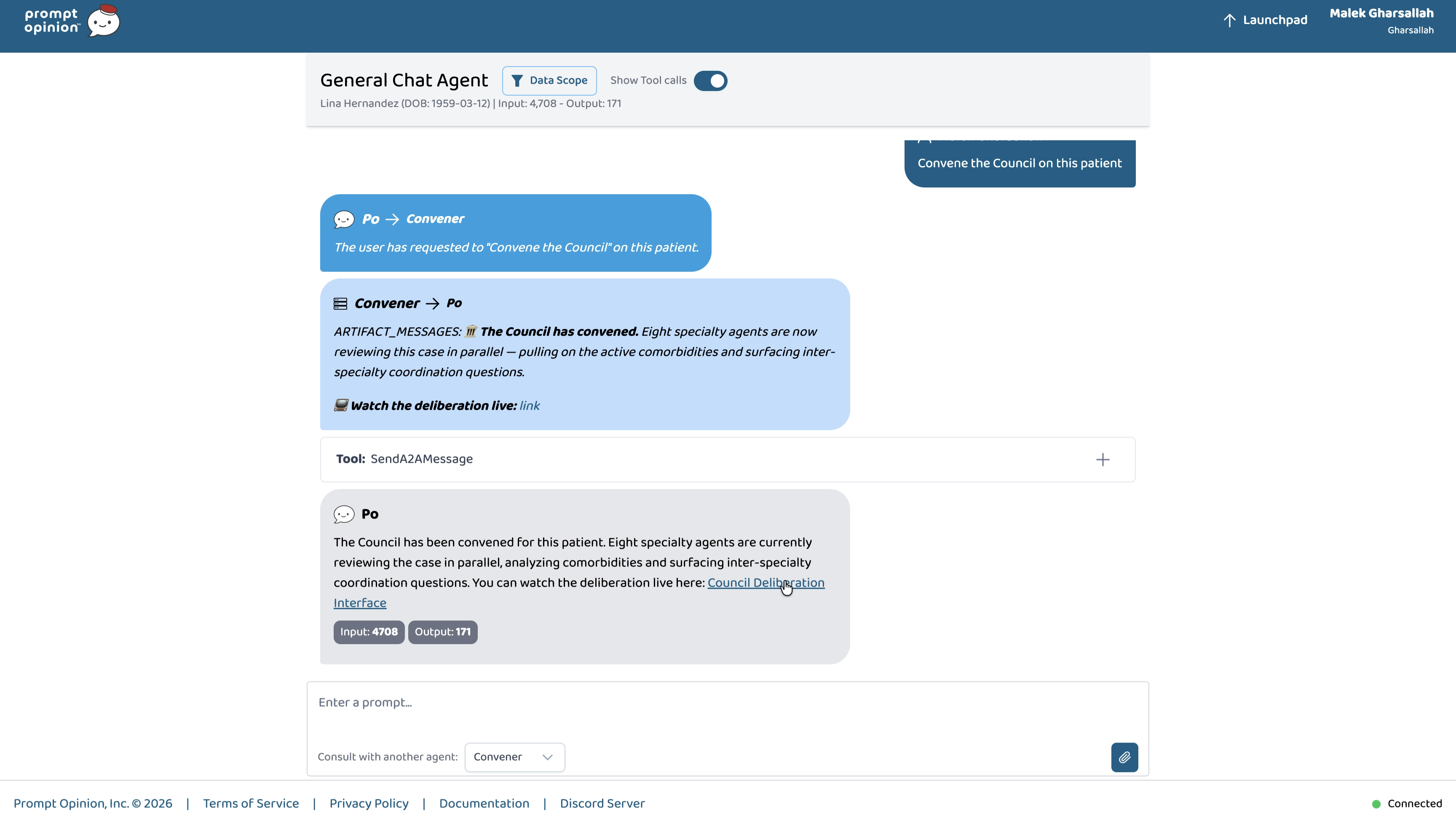
A primary-care clinician opens General Chat in Prompt Opinion with a patient selected and types one sentence:
"Convene the Council on this patient."
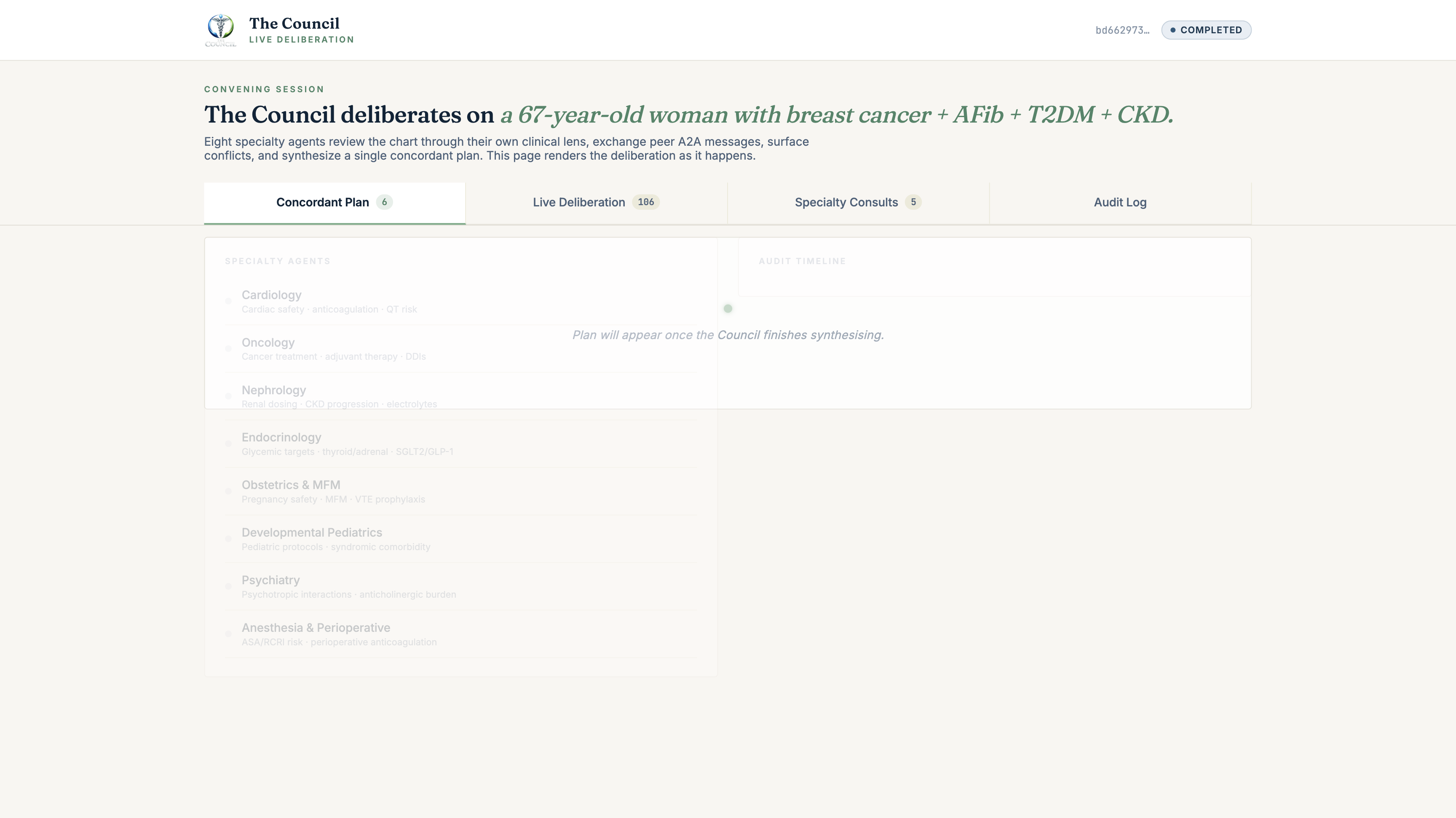
What happens next:
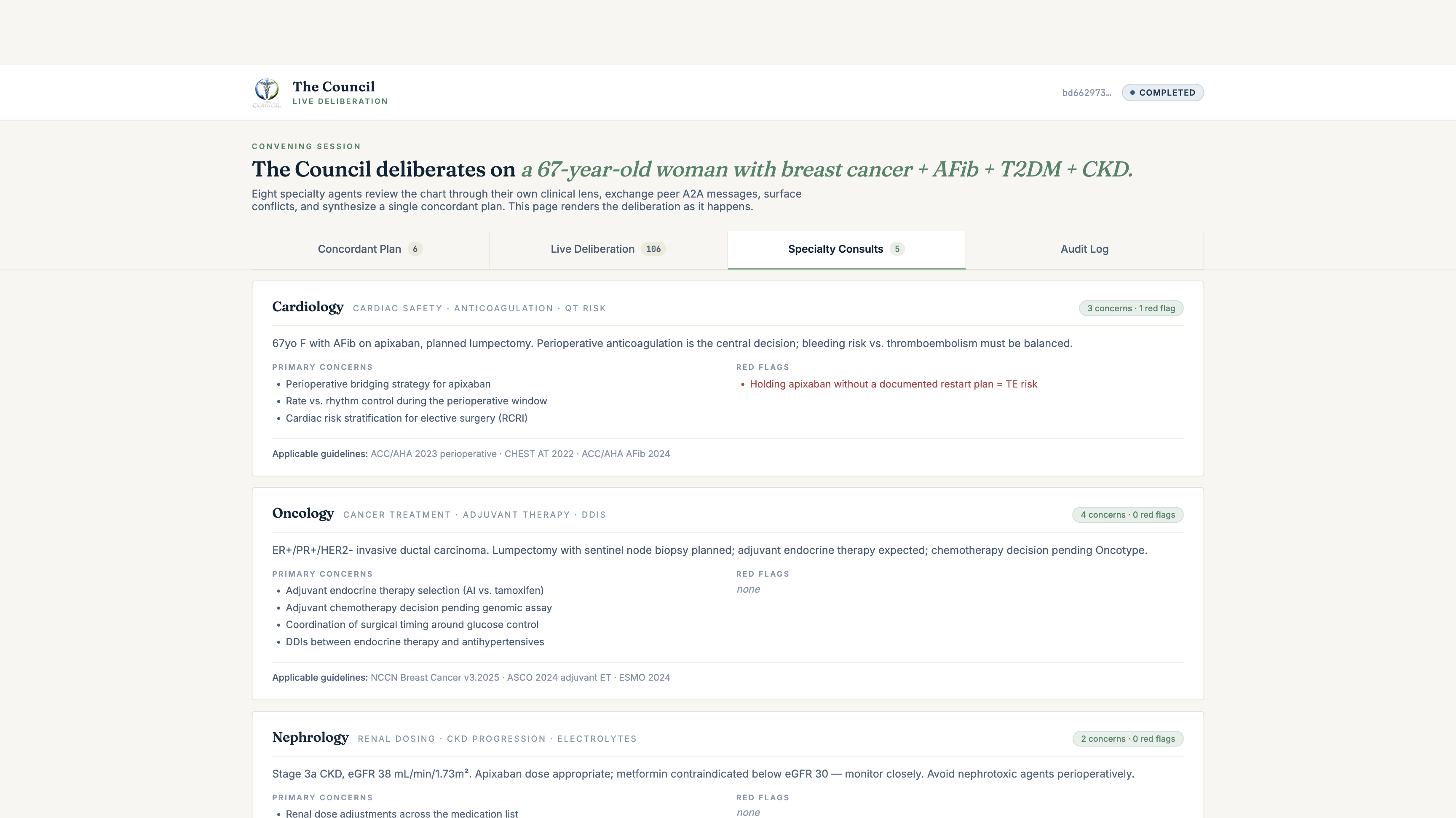
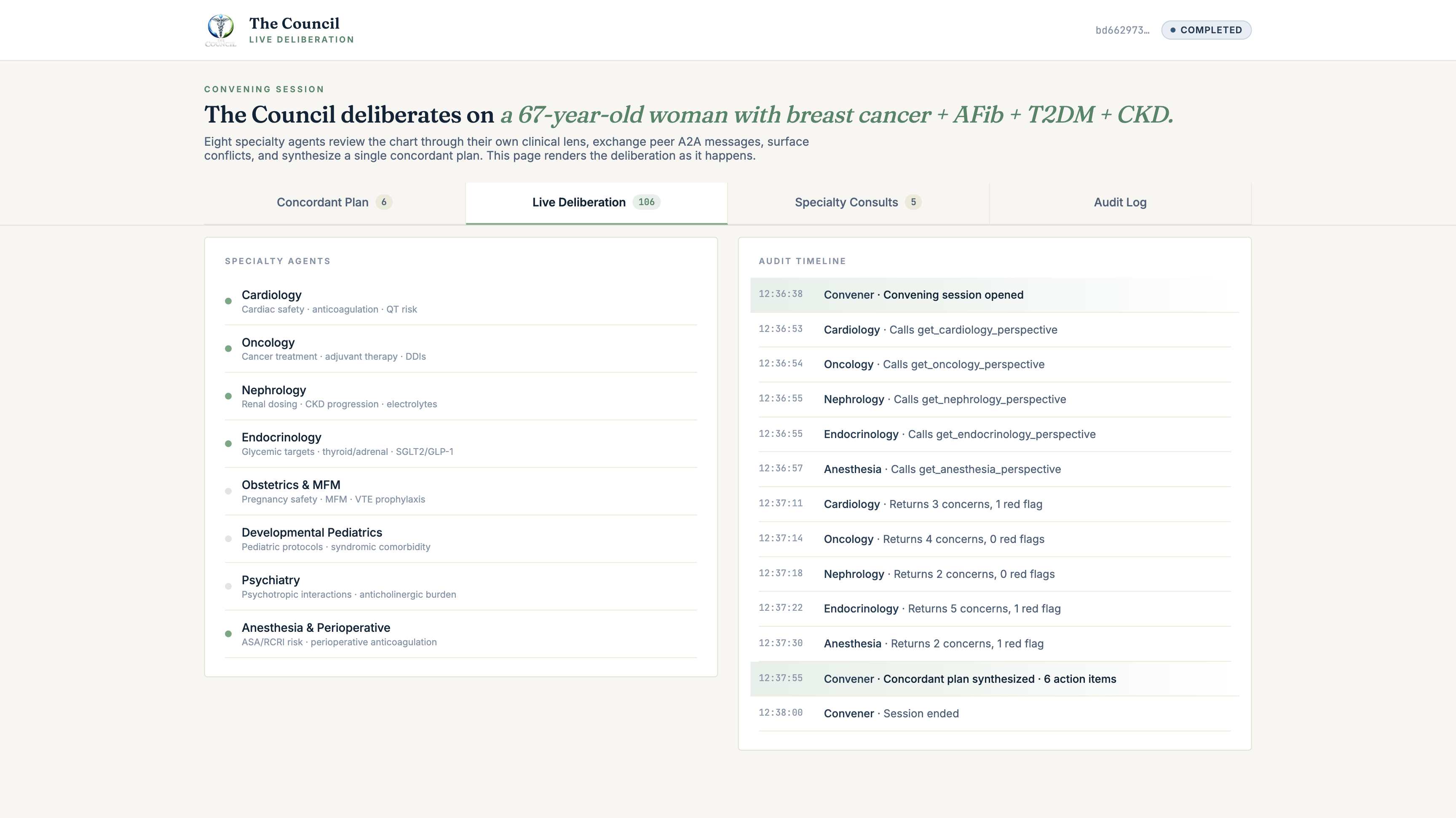
- The Convener agent (a real A2A peer) opens a convening session in Supabase, then fans out a Round-1 prompt over A2A to eight specialty agents in parallel: Cardiology, Oncology, Nephrology, Endocrinology, Obstetrics & MFM, Developmental Pediatrics, Psychiatry, Anesthesia & Perioperative.
- Each specialty agent calls its SHARP-on-MCP lens tool (
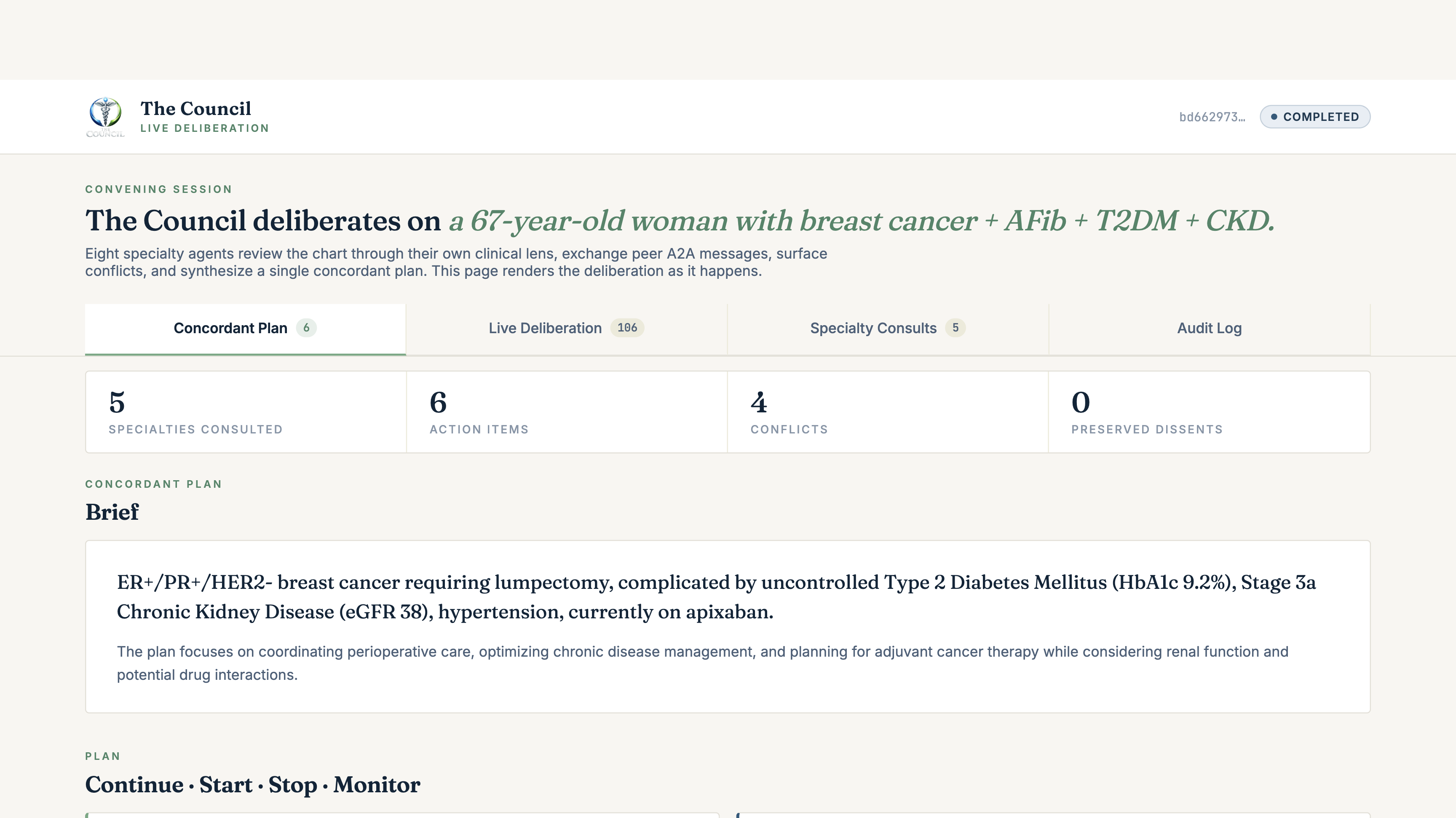
get_<specialty>_perspective). The MCP server fetches the live FHIR R4 chart through the SHARP-bound token, summarises it through that specialty's clinical lens, and returns a structuredSpecialtyView: primary concerns, red flags, applicable guidelines, proposed plan (continue / start / stop / monitor), and full reasoning trace. - The Convener calls
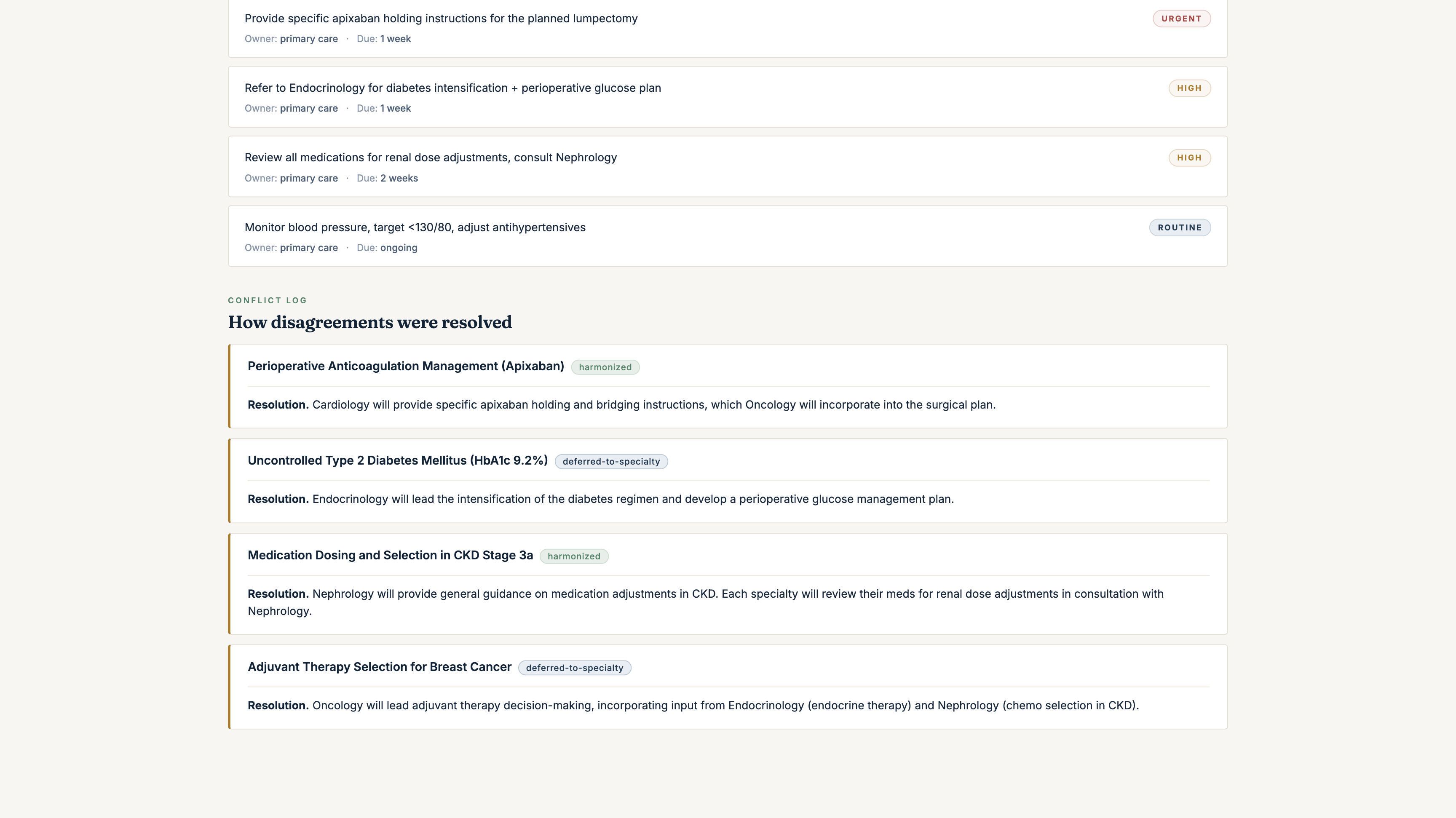
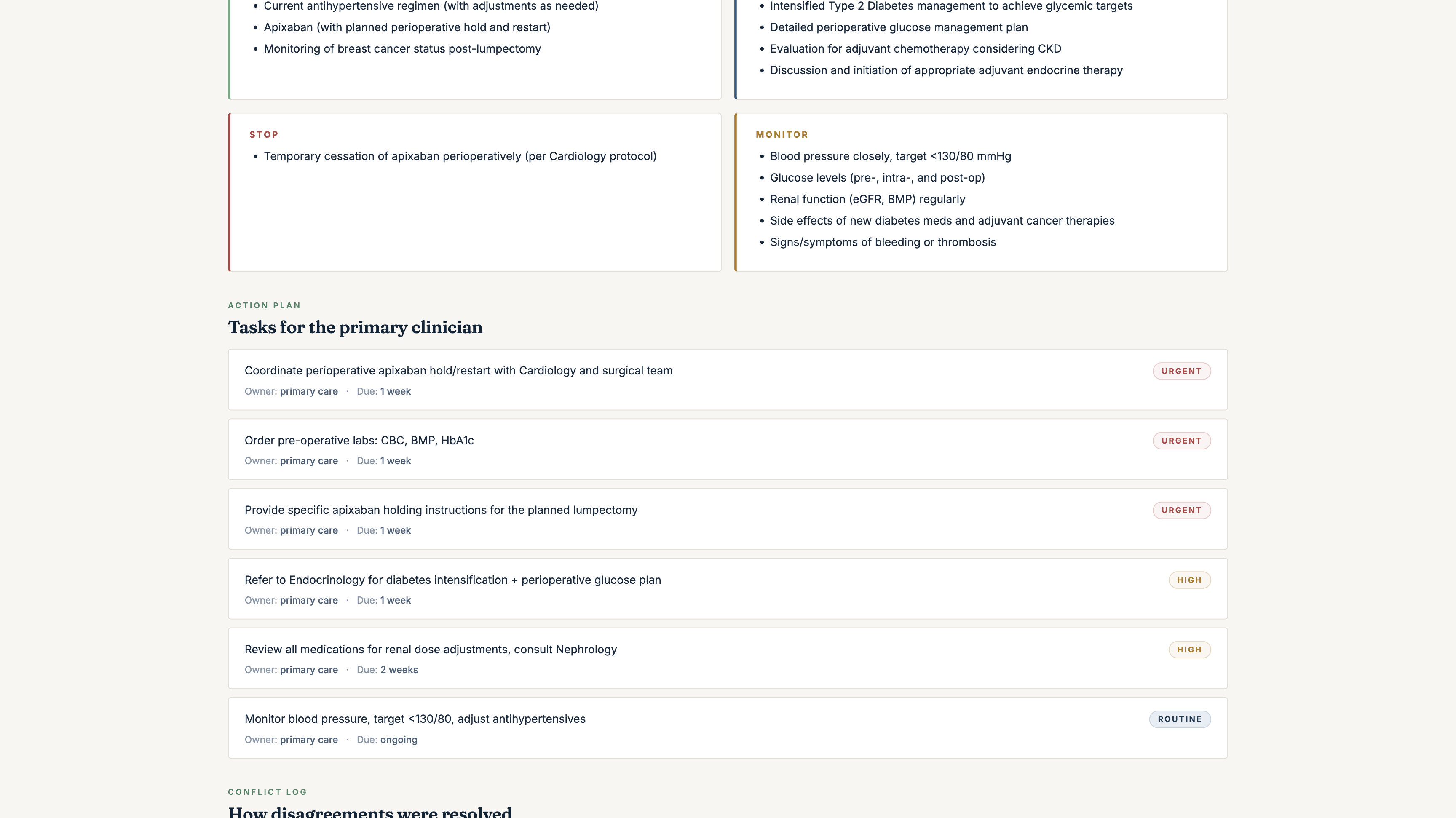
get_council_conflict_matrixthenget_concordance_brief, two MCP tools that detect conflicts inline and synthesise aConcordantPlanin Prompt Opinion's 5T framework: a plain-English brief, a continue/start/stop/monitor plan, an action-item table for the primary clinician, a conflict log with explicit resolution methods (harmonized/deferred-to-specialty/guideline-aligned/patient-preference/unresolved), and preserved dissents where the Council didn't fully converge. - Every reasoning step writes to a Supabase audit table with Realtime publication enabled. A live deliberation viewer subscribes via Realtime and renders the multi-agent deliberation as it happens: agents activating, audit events streaming, the ConcordantPlan landing as a fully formatted clinical document.
The Convener's response in PO chat is intentionally short, a single paragraph plus a live link. The rich rendering happens on the convene-ui, where it has its own time budget.
The Council doesn't decide. The clinician does. The Council surfaces the trade-offs that single-LLM systems hide.
How we built it: the four standards
Every one of Prompt Opinion's four core standards is load-bearing here, not decorative:
MCP
specialty-lens-mcp. TypeScript Express 5 + @modelcontextprotocol/sdk. Exposes 8 get_<specialty>_perspective tools + 2 concordance tools (get_council_conflict_matrix, get_concordance_brief). Each tool returns structured output (validated SpecialtyView / ConflictMatrix / ConcordantPlan schemas). No free-text JSON parsing.
A2A
Real peer A2A. Each agent has its own AgentCard served at both /.well-known/agent-card.json (v1) and /.well-known/agent.json (v0 backcompat). The Convener fan-out is deterministic peer dispatch, not gemini.decideWhichExpertToConsultNext(). Specialty agents that don't apply to a patient (Developmental Pediatrics on a 67-year-old) explicitly abstain, and the abstention is preserved in the audit log as clinical signal, not silently skipped.
SHARP
Full SHARP context propagation across the entire 8-agent A2A call chain: patient_id, FHIR token, audience binding, every hop. First SHARP-on-MCP impl with real HTTP 403 enforcement at the request edge. None of the three reference implementations in prompt-opinion/po-community-mcp (TypeScript / Python / .NET) do this. We also shipped an upstream RFC PR to po-community-mcp proposing three new SHARP headers (X-Council-Convening-Id, X-Council-Specialty, X-Council-Round-Id) for grouping MCP calls into a multi-agent deliberation session, and we use the extension in production right now.
FHIR
Live FHIR R4. No mocks, no fixtures. Every specialty lens fetches the real chart through the SHARP-bound token: Patient, Condition, MedicationStatement / MedicationRequest, Observation, AllergyIntolerance, Procedure. The lens then summarises through its specialty filter: anti-coag for Cardiology, glycaemic targets for Endocrinology, renal-cleared dosing for Nephrology, perioperative risk for Anaesthesia, etc.
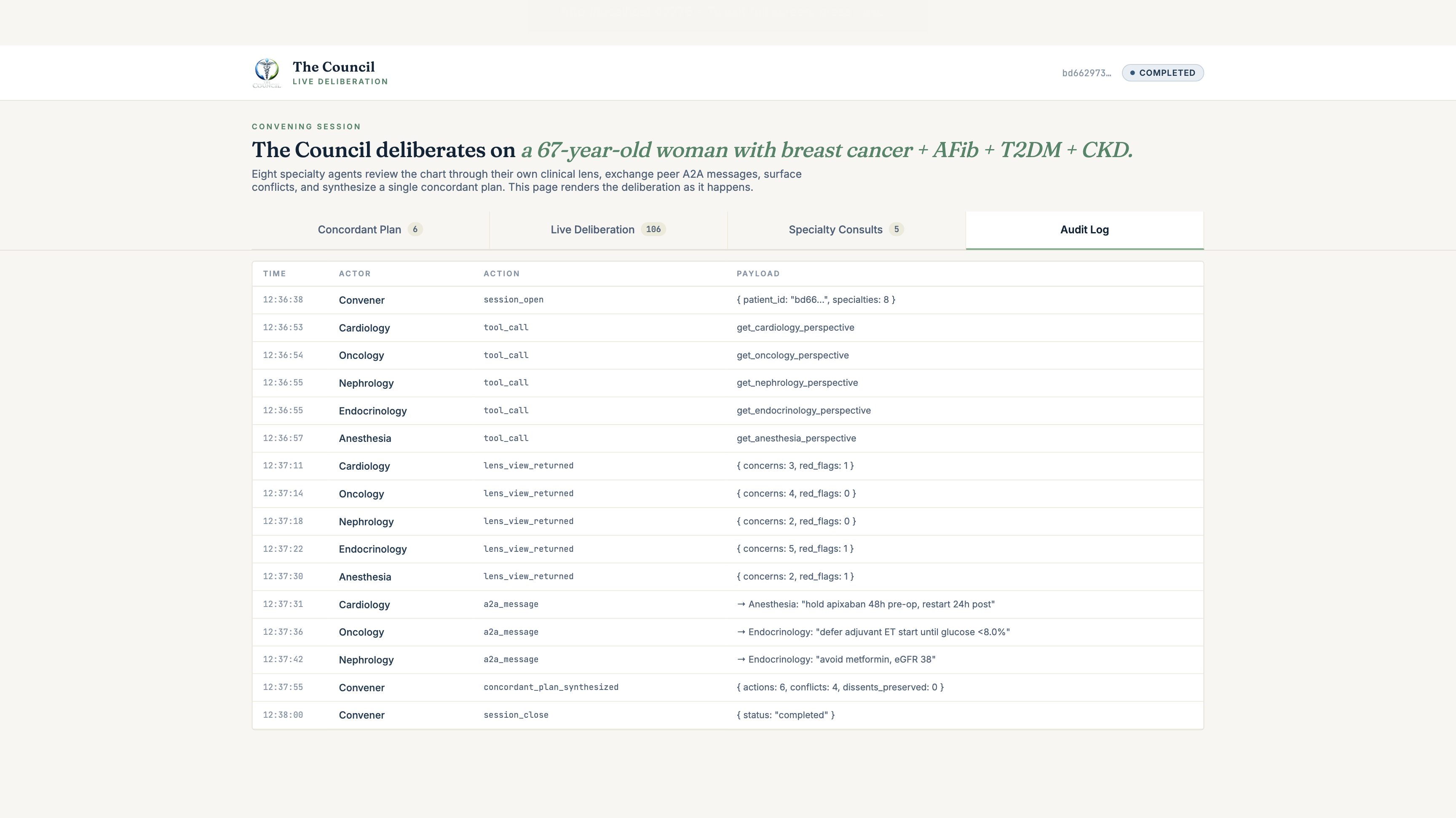
The audit trail
Healthcare clinical decision support without a queryable reasoning trail is unshippable. The Council writes four parallel ledgers to Supabase:
| Table | What's logged |
|---|---|
audit_events |
Every state transition, one row per event |
agent_messages |
Every A2A message between Convener ↔ specialty peers |
mcp_tool_calls |
Every MCP tool invocation, with SHARP context + latency + result hash |
convening_sessions |
One row per session, plan_artifact JSONB column holds the final ConcordantPlan |
Supabase Realtime publication is enabled on all four. The convene-ui subscribes and renders the deliberation as it streams. Every reasoning step is queryable: by clinician, by oversight, by future audit. Audit-trail-native multi-agent systems are what the SMART-on-FHIR community wants. Real audit logs beat real-time chat for clinical decision support.
Privacy & feasibility
Multi-specialty AI on real patient data demands real privacy guarantees. We deliberately built three layers:
- SHARP enforcement at the edge. The MCP server emits real HTTP 403 on any request missing or carrying invalid SHARP context. No opaque fallback, no silent "best effort". The reference impls in
po-community-mcpdescribe this enforcement; we are the first to actually emit it. - Per-session isolation in the convene-ui. The viewer requires an explicit
?id=<convening-uuid>URL. No auto-loading of "the latest session", no public browsing of sessions. (Per-session RLS is the next layer, planned post-hackathon for clinical pilots.) - Synthetic data for the demo. All FHIR data in the public deliberation viewer is synthesised via Synthea. No real PHI is stored or rendered in this hackathon submission.
Challenges we ran into
1. Eight specialty agents bursting Vertex in parallel
Eight specialty agents firing concurrently into a single Vertex Gemini region produced sub-second 429 RESOURCE_EXHAUSTED storms, with half the fan-out lost on every deliberation. Documented per-region RPM ceilings for gemini-2.5-flash were nominally sufficient for 8-way burst, but in practice the regional capacity throttled hard under sub-second concurrency and the Gemini-internal retry envelope didn't recover within our latency budget. Single-region was a non-starter for a real multi-agent system. The fix: pin each of the 10 services to a distinct Vertex region (us-central1, us-east1, us-west1, us-east4, us-south1, europe-west1, europe-west4, us-east5, asia-northeast1, asia-southeast1). Per-region quotas are independent; spreading the burst across 10 regions gave us linear capacity, deterministic latency, and quota isolation across specialties. Cardiology saturating us-west1 doesn't degrade Anaesthesia in asia-southeast1. This is the architecture a global multi-specialty network should have anyway: locality-aware, no single point of regional failure, fan-out scales without changing the service contract.
2. The Prompt Opinion / a2a-sdk shape mismatches
PO is a young platform with its own Agent Card schema; the canonical a2a-sdk is the reference. We hit six distinct shape gaps in production: PO requires the v1 nested-key securitySchemes shape with location instead of in; PO sends proto-style PascalCase JSON-RPC method names (SendMessage) where the SDK only registers the spec form (message/send); PO sends ROLE_USER where the SDK expects user; PO puts FHIR context at params.message.metadata where the SHARP spec puts it at params.metadata; PO's response parser expects the v1-nested result.task.{...} envelope with state as TASK_STATE_COMPLETED, where the SDK emits the spec form result.kind:"task" with state as completed; and ADK-emitted Agent Cards default to streaming: true, which makes the platform try to parse SSE and fail. The fix is a Starlette middleware (A2APlatformBridgeMiddleware) that does method aliasing, role aliasing, FHIR-metadata bridging, and response reshaping on the way in and out. Subtle wrinkle: the response reshape can only happen on the agent PO calls directly (the Convener); applying it to peer-to-peer calls between Convener and specialty agents breaks the canonical SDK on the receiving side. The middleware takes a reshape_response toggle: True for the Convener, False for the 8 specialty agents.
3. The Pydantic discriminated-union bug: text_len=0 for hours
Every specialty peer was responding with response_chunks=1 but our Convener's parser reported text_len=0 and dropped every view. The deliberation looked completely broken. The root cause turned out to be the A2A Task shape: Task.artifacts[0].parts[0].root.text. Part is a Pydantic discriminated union over TextPart | FilePart | DataPart, with the real content under .root. Our recursive walker peeked at attrs named text/parts/result/artifact/content but never .root, so it silently failed to find any text on every chunk. The fix: dump every chunk via model_dump(mode="json", exclude_none=True) first to flatten the discriminated union into a plain dict, then walk that. Smoke-tested with three response shapes (Pydantic Task, raw dict, empty stream) before redeploying.
4. PO's empty-bearer-token regression on the FHIR proxy, and the fixture fallback we deleted
PO's General Chat platform started shipping the SHARP fhirToken header as an empty string instead of a SMART bearer token. Our SHARP middleware initially rejected (treating empty-string as missing); we relaxed it to allow present-but-empty. The context extractor one layer down still rejected the empty token via if (!fhirAccessToken) return null (JS empty-string is falsy); we relaxed that too. With both fixes, the lens MCP attempted the FHIR call and got HTTP 403 from PO's workspace FHIR proxy because that endpoint requires the operating user's session cookie, not a bearer. To keep the demo path deterministic we initially shipped a server-side fixture fallback: on 401/403/404/422/500/timeout, the MCP loaded a hand-crafted Mrs. Chen FHIR bundle and surfaced "demo bundle fallback used" in the lens output's reasoning_trace. We deleted it before submission. Even with audit attribution, silently substituting synthetic patient data when the real FHIR call fails is the wrong default for clinical AI. A clinician reviewing a brief can't be expected to spot a reasoning_trace line buried in JSON, and the fallback engaged per-lens-call in some configurations, producing patient-identity drift inside a single deliberation (one consult saw 44yo Tamera live, another saw 67yo Mrs. Chen via fallback, in the same brief). The shipped behavior is live FHIR only; if PO's proxy fails for a given lens call, that lens abstains and the abstention is captured in the audit log. Abstention is itself clinical signal.
5. The audit log silent-FK failure
Hours of debugging "why is Round 1 yielding 0 valid SpecialtyViews?" ended with one query against Supabase: SELECT * FROM audit_events returned zero rows. Same for agent_messages, mcp_tool_calls. The Convener was firing record_audit_event(...) and the calls weren't raising, but nothing was landing. Both child tables FK-reference convening_sessions(id), and the Convener never inserted a row into convening_sessions first. Every child insert was silently FK-rejected. The audit.py module wrapped each insert in a try/except logging at WARN, but production structlog config swallowed it, leaving us blind. Fixed by calling open_session(...) synchronously at the start of every deliberation, returning the canonical session UUID, and caching it on tool_context.state. Also caught: SQL CHECK constraint on agent_messages.role allowed 'endocrine' but the code's Specialty literal sends 'endocrinology', a silent CHECK violation on every endocrinology message. Fix: dropped the role-check constraint (the literal type is the source of truth, SQL-level enforcement was adding silent failure surface without value).
6. The 60-second General Chat ceiling: accepting it as a feature
The final architectural pivot was the cleanest: we couldn't fit a real multi-agent deliberation (8 specialty fan-out + brief synthesis, typically 60-90 seconds) inside Prompt Opinion General Chat's ~60s LLM-orchestration timeout. Every speed optimization helped marginally. Dropping the conflict_matrix MCP call saved 12s, moving from 4 to 8 concurrency saved 5s, multi-region eliminated 429 retry storms, but we kept bumping the wall. The breakthrough was accepting the ceiling as a platform constraint and inverting the deliverable: the Convener now returns within ~3-5 seconds with a live deliberation URL, and the actual deliberation runs in a background asyncio.create_task that streams audit events to Supabase Realtime. A separate static page (convene-ui) subscribes via Realtime and renders the multi-agent deliberation as it plays out. The PO chat surface stays snappy and never times out; the rich rendering happens at convene-ui where it has its own time budget. This turned out to be the better demo anyway: watching eight agents deliberate in real time IS the architectural proof that we have something orchestrator-and-router patterns can't produce. The 60s ceiling forced us to build the right product.
What we learned
Production multi-agent on platform constraints is mostly an integration problem, not a modeling problem. The LLM is the easy part. Wiring eight specialty agents into a platform that has its own LLM-orchestration timeout, its own auth shape, its own envelope format, and its own bearer-token regression is where 80% of the engineering goes. We shipped a 4-layer Starlette bridge middleware to handle PO's six shape gaps from the canonical a2a-sdk. That middleware is the integration story.
Multi-region distribution is an architectural primitive for parallel multi-agent systems, not an afterthought. When eight specialty agents burst concurrently into a shared regional capacity, you get sub-second 429 storms even within documented quotas. Pinning each agent to its own Vertex region delivers linear capacity, latency isolation, and per-specialty quota independence. Cardiology saturating its region doesn't touch Anaesthesia. The Council ships across us-central1, us-east1, us-west1, us-east4, us-south1, europe-west1, europe-west4, us-east5, asia-northeast1, and asia-southeast1. Every specialty in its own resilience domain.
Fire-and-forget + Realtime audit streaming is a stronger demo than waiting for a wall of text in chat. Once we accepted PO's 60s ceiling as a platform constraint and stopped fighting it, the whole story got better. The chat returns instantly with a live link; the deliberation plays out in
convene-uiwhere every event ticks in via Supabase Realtime. Watching eight specialty agents activate one by one IS the architectural differentiator. Orchestrator-and-router patterns produce a wall of text; peer A2A produces visible parallelism.The audit log is the architectural differentiator for healthcare. It's not a side effect of the system; it's the artifact a clinician trusts and a compliance officer demands. SHARP-on-MCP + Supabase Realtime + per-specialty consult cards gives us a live MedLog-style trail. Every state transition, every MCP tool invocation, every A2A peer message, queryable by session, by specialty, by time. No orchestrator-and-router pattern can produce this granularity, because the orchestrator IS the audit boundary; in The Council, every peer is an independently-auditable subject.
Clinical AI must never silently substitute synthetic data for failed real-data calls. We shipped a fixture fallback during development as a demo crutch, then deleted it before submission. The shipped behavior on FHIR-proxy failure is per-lens abstention recorded in the audit log, not a silent swap to a hand-crafted bundle. Identity drift inside a single deliberation (one specialty seeing real patient A while another silently sees fixture patient B) is the worst-case clinical-AI failure mode. The right default is "fail loud, abstain visibly."
Accomplishments we're proud of
All 10 marketplace listings live on Prompt Opinion under publisher "The Council": Convener + 8 specialty agents (Cardiology, Oncology, Nephrology, Endocrinology, Obstetrics & MFM, Developmental Pediatrics, Psychiatry, Anesthesia & Perioperative) + the SHARP-on-MCP server (
Council Specialty Lens MCP). All independently invokable by any PO user from day one.First SHARP-on-MCP implementation with real HTTP 403 enforcement at the request edge. None of the three reference implementations in
prompt-opinion/po-community-mcp(TypeScript / Python / .NET) actually emit 403 on missing/invalid SHARP context. We do.Upstream RFC PR shipped to
po-community-mcpproposing three new SHARP headers (X-Council-Convening-Id,X-Council-Specialty,X-Council-Round-Id) for grouping MCP tool calls into a multi-agent deliberation session. Used in production by The Council right now.10 services pinned to 10 distinct Vertex Gemini regions (us-central1, us-east1, us-west1, us-east4, us-south1, europe-west1, europe-west4, us-east5, asia-northeast1, asia-southeast1). Every specialty agent in its own resilience domain, with per-region quota independence. Linear burst capacity, latency isolation, no shared-fate failures across specialties.
A 4-layer Starlette bridge middleware (
A2APlatformBridgeMiddleware) that fixes six distinct shape gaps between PO's Agent Card schema and the canonicala2a-sdk, making any ADK-built agent PO-compatible without touching the SDK itself. Reusable for any future builder hitting the same gaps.Live deliberation viewer (
convene-ui) rendering Supabase Realtime audit events as a clinical document: Plan / Live Deliberation / Specialty Consults / Audit Log tabs. Watching eight agents deliberate in real time is the demo moment that no orchestrator-with-router architecture can produce.Zero mocks in the shipped path. Every specialty view comes from a real Vertex Gemini call on a real FHIR fetch via SHARP-bound token. Every audit row is real. Every plan artifact is generated by a real model on real data.
A submission video that shows the actual hosted app, including the empty/loading state, the live deliberation timeline ticking in event by event, and the final ConcordantPlan render. Not a Figma mockup, not a rehearsed click-through. The real thing.
Privacy substrate retro-fitted before submission. Discovered mid-build that the convene-ui auto-loaded the most recent session for any visitor; ripped it out, replaced with explicit
?id=<uuid>requirement + Synthea/synthetic-data disclaimer + per-session isolation banner. Clinical AI deserves clinical-grade defaults.
What's next for The Council
- Per-session RLS in Supabase so the anon-key client can only read sessions it's been granted access to via a sharing token. (Today: explicit URL = effective access; next: cryptographic session sharing.)
- Round-2 deliberation re-enabled outside the chat critical path. The codebase already has the targeted re-fan-out wired (
agent.py: ROUND_2_PROMPT_TEMPLATE); we cut it from the demo path because the conflict_matrix MCP call added 12s to a budget we didn't have. With fire-and-forget execution, Round 2 has all the time it needs. - Patient-preference axis: a 9th "lens" representing the patient's own values / preferences / contraindications, sourced from a structured intake.
- Tumour-board mode: same architecture, different specialty roster (path / rad onc / surgical onc / med onc / palliative). The Convener's peer list is config; adding a 9th specialty is one Cloud Run service, not an orchestrator rewrite.
- EHR write-back: today the ConcordantPlan is rendered for a clinician to read; the next step is FHIR
CarePlanresource write-back through SHARP scopes.
Built With
- a2a
- agent-to-agent
- express.js
- fhir
- fhir-r4
- gemini-2.5-flash
- google-adk
- google-cloud-run
- huggingface-spaces
- mcp
- model-context-protocol
- node.js
- pgvector
- pino
- postgresql
- prompt-opinion
- python
- react
- remotion
- sentry
- sharp
- smart-on-fhir
- supabase
- supabase-realtime
- typescript
- vertex-ai
- zod
Log in or sign up for Devpost to join the conversation.