-
-
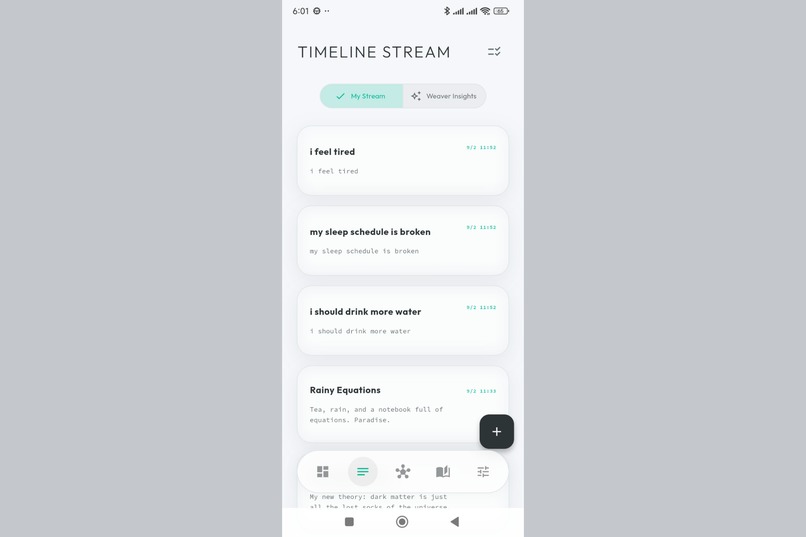
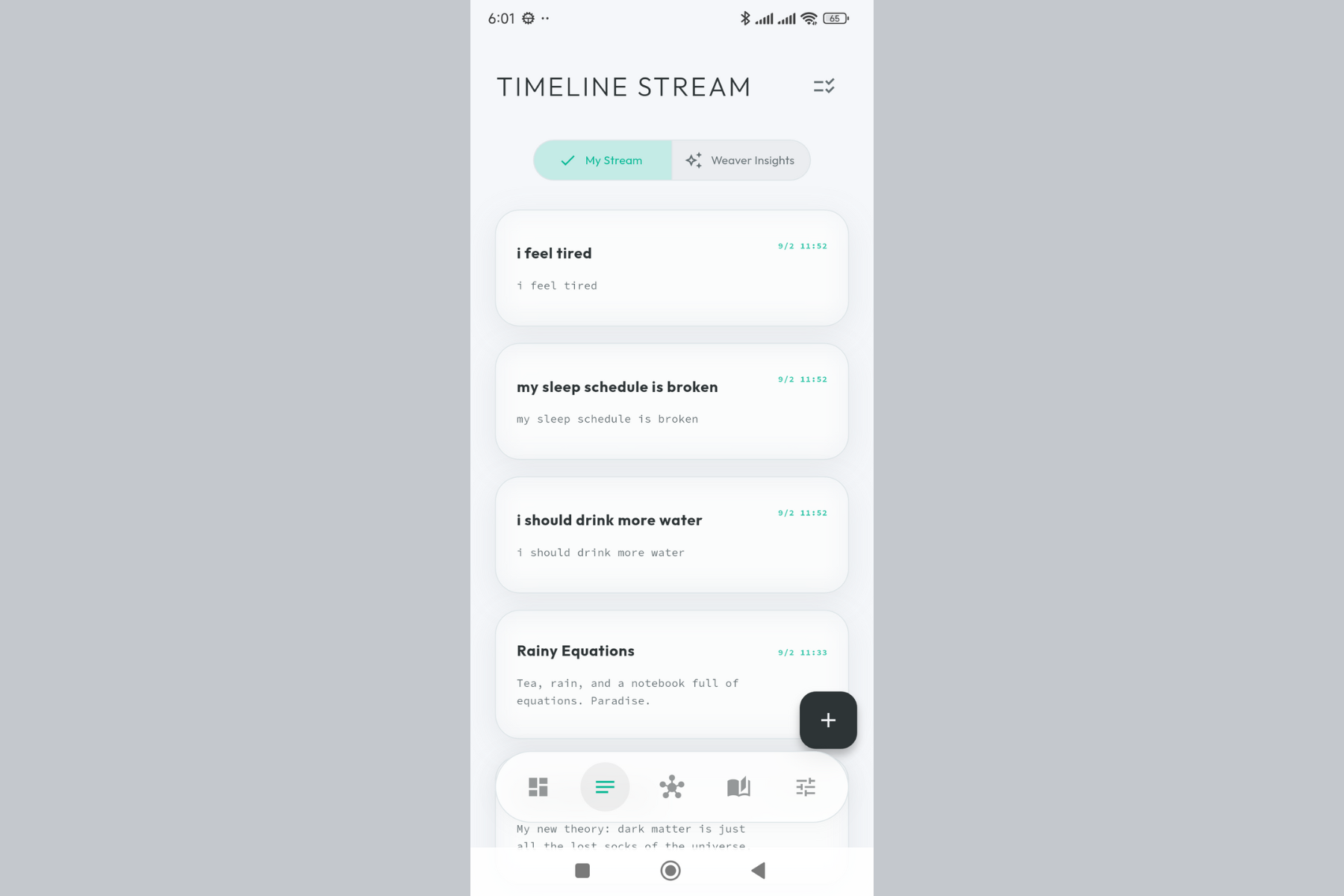
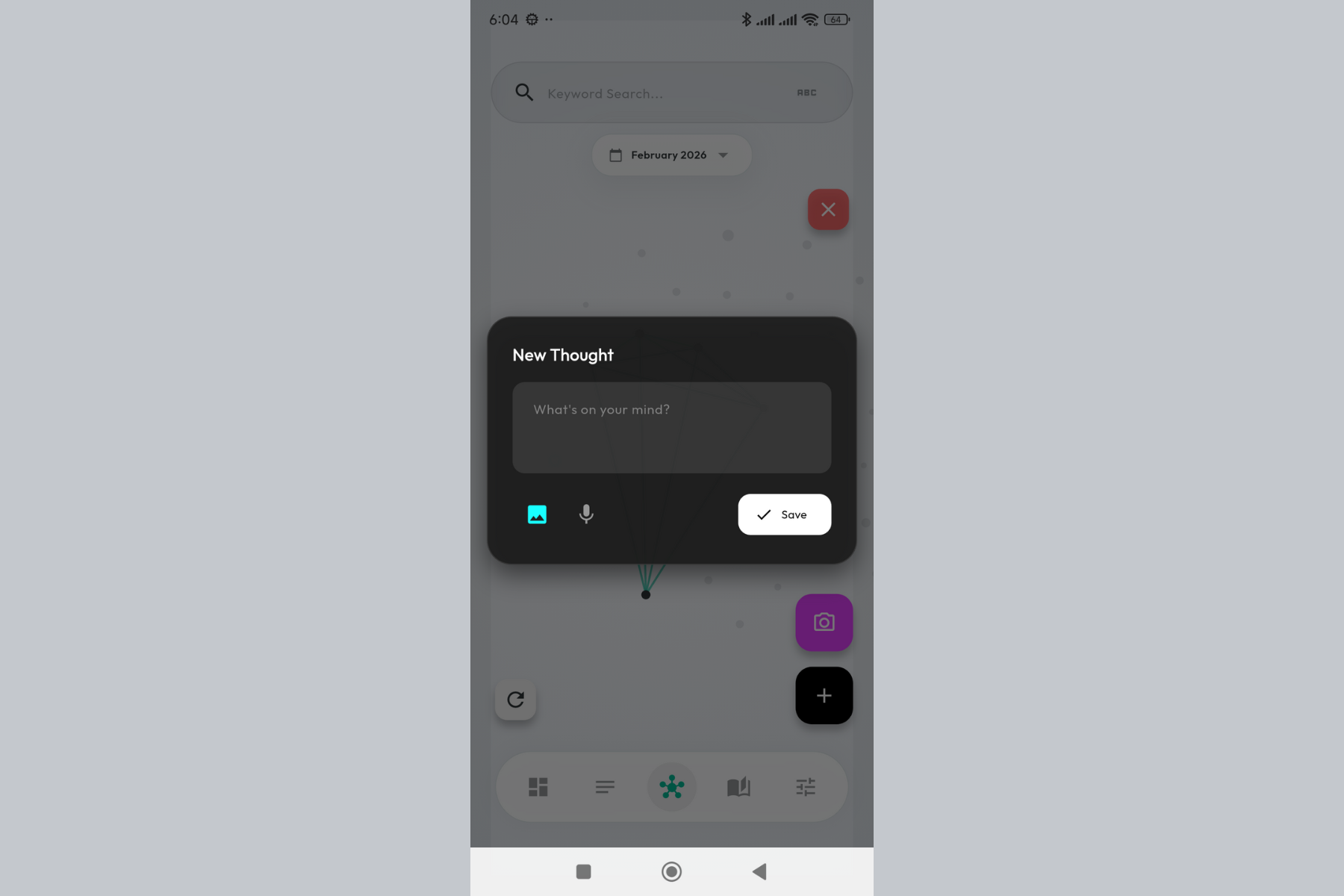
Your thoughts as a living stream. Capture ideas instantly, each one embedded with AI-generated semantic meaning.
-
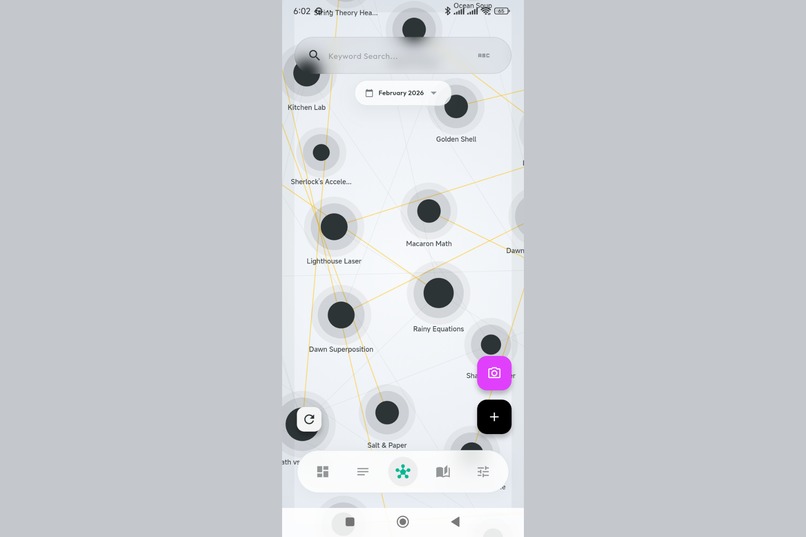
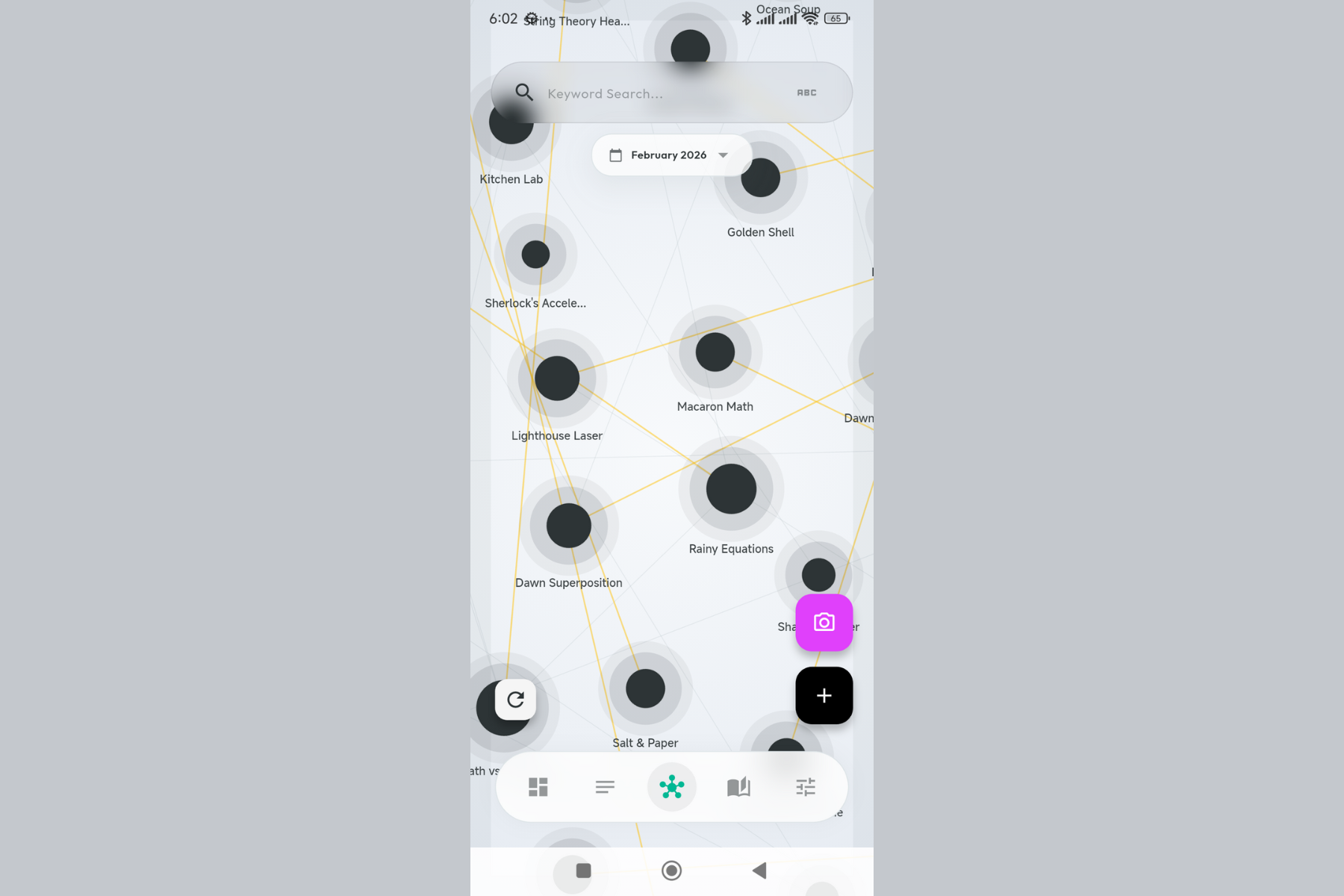
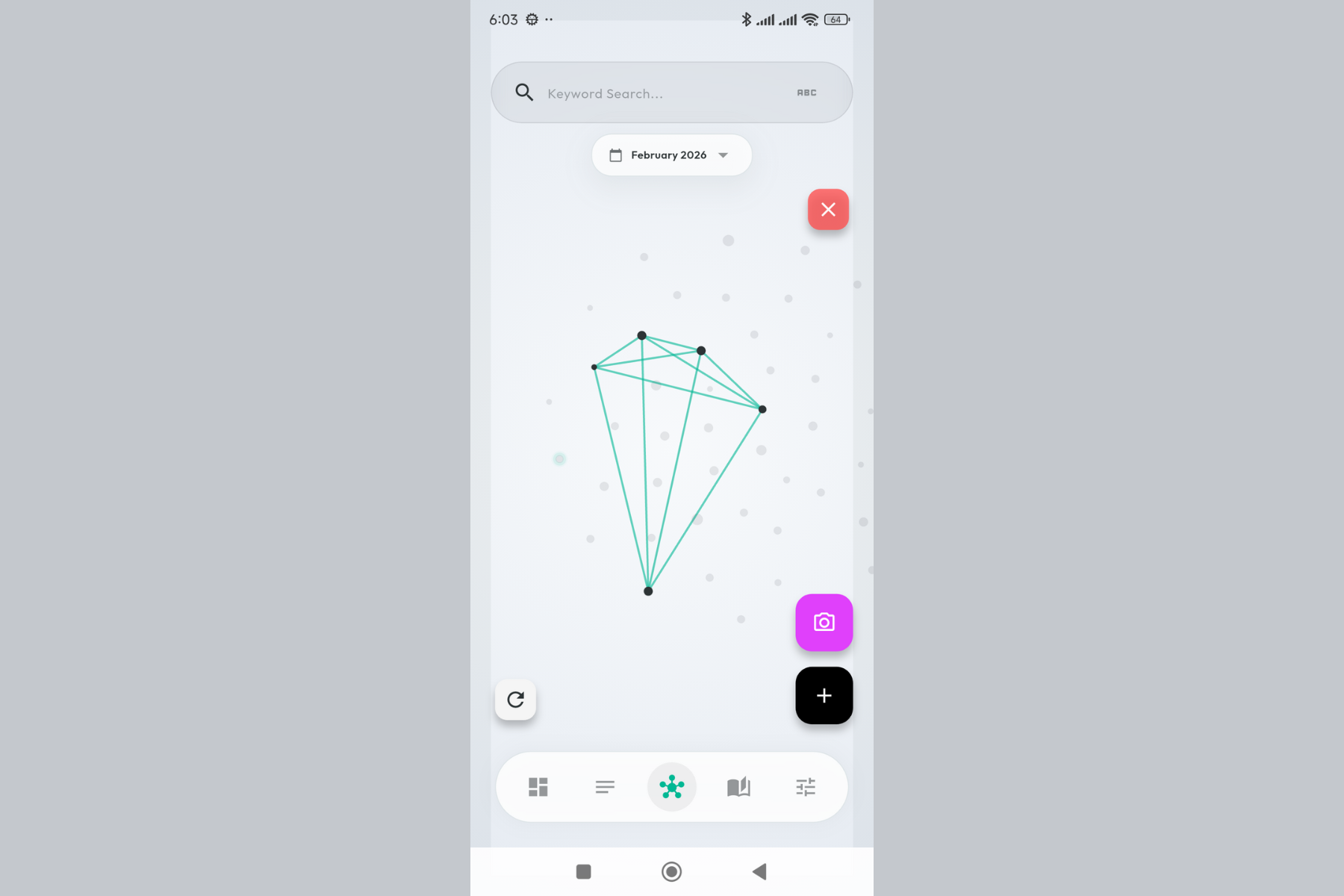
The galaxy view. Thoughts self-organize based on semantic similarity - related ideas cluster together automatically.
-
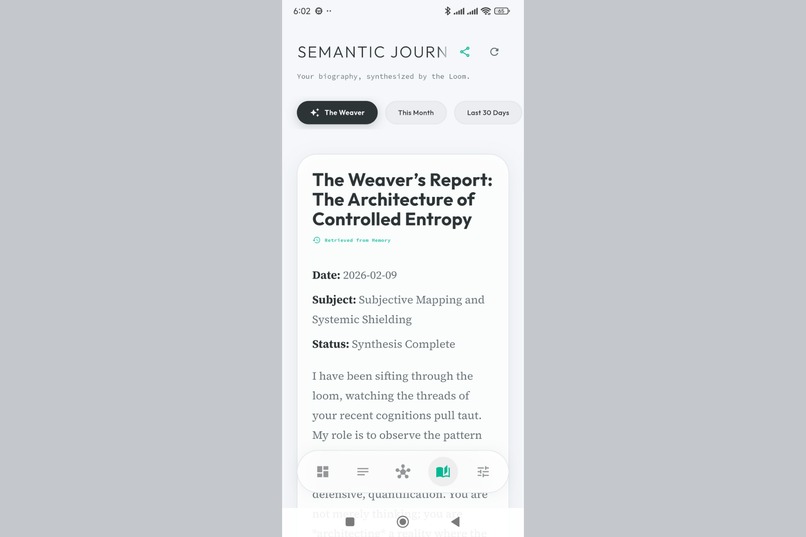
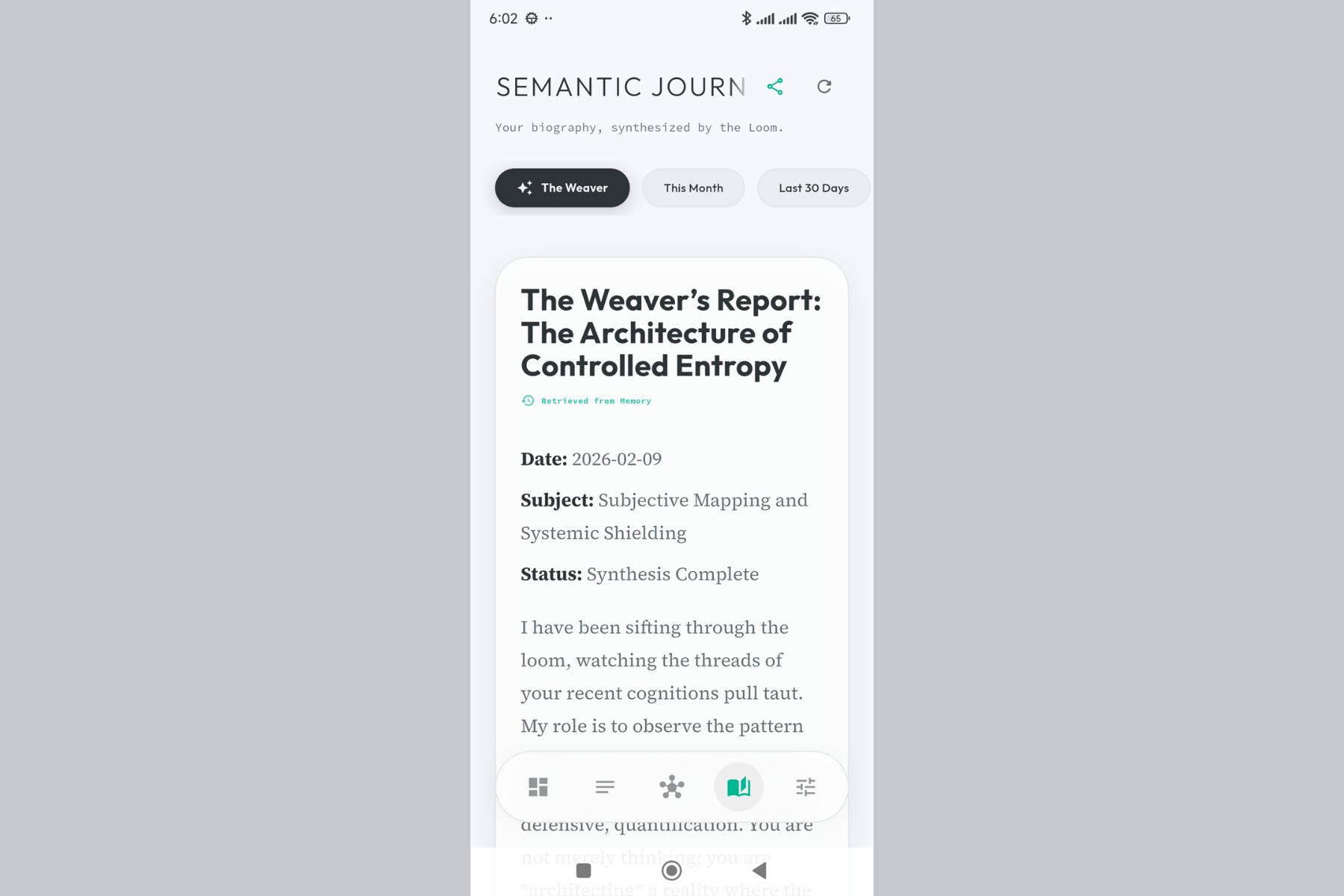
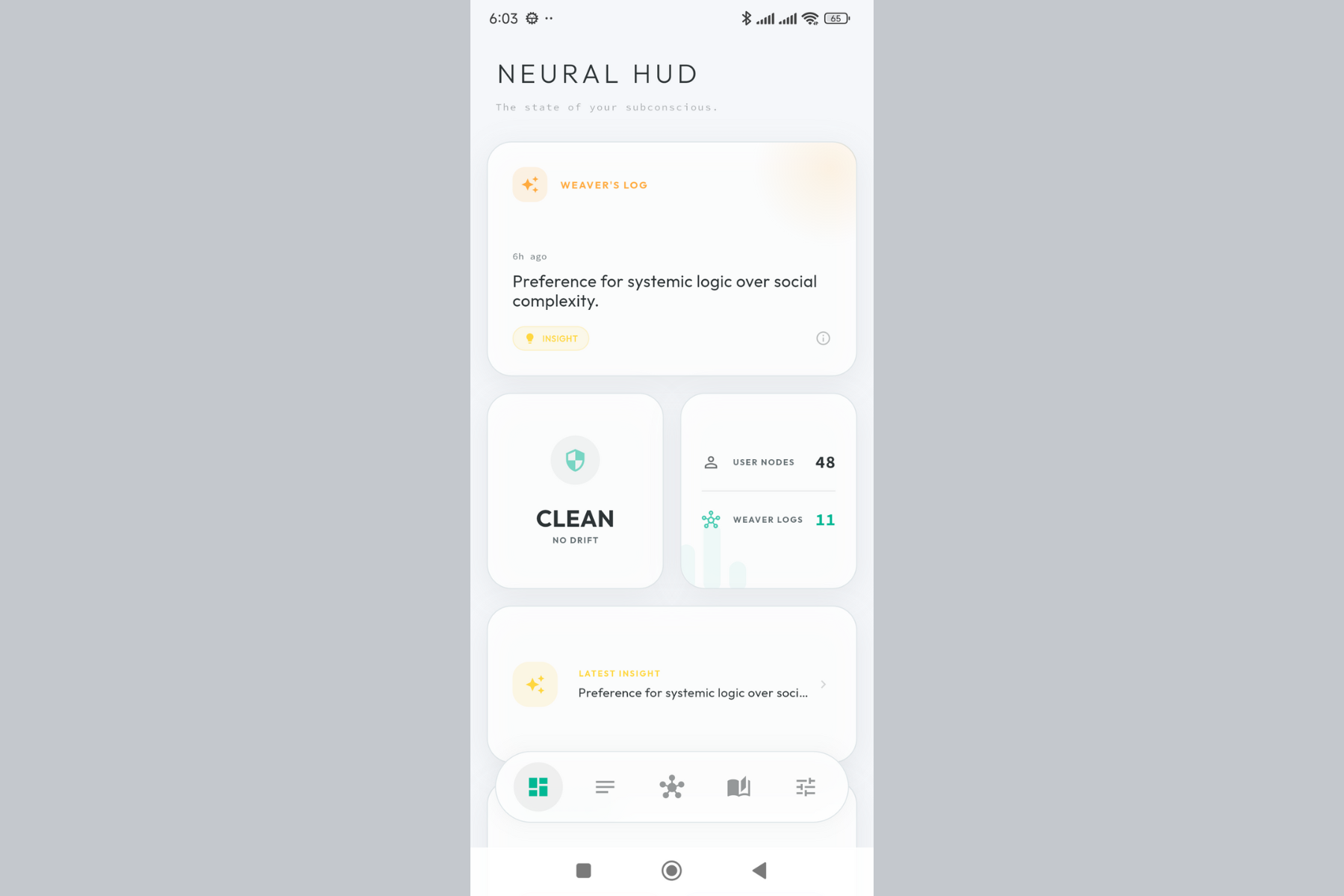
AI-generated summaries of your thought patterns over time. Like having a biographer who actually understands you.
-
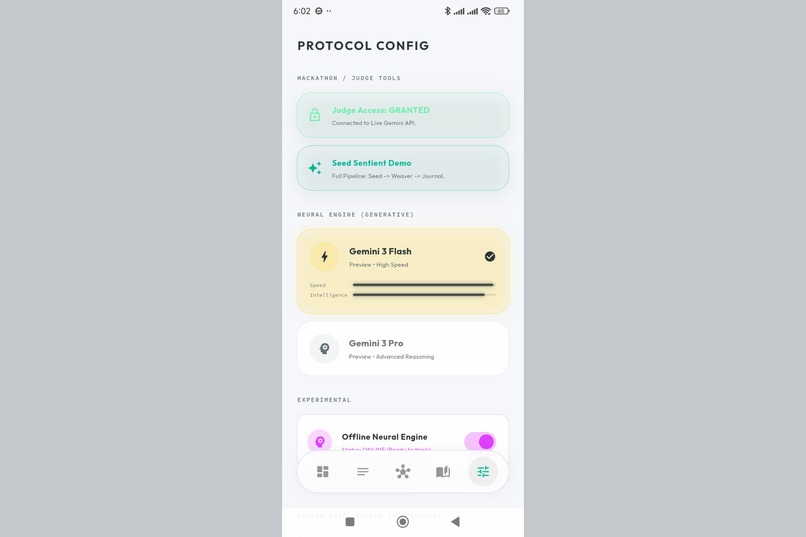
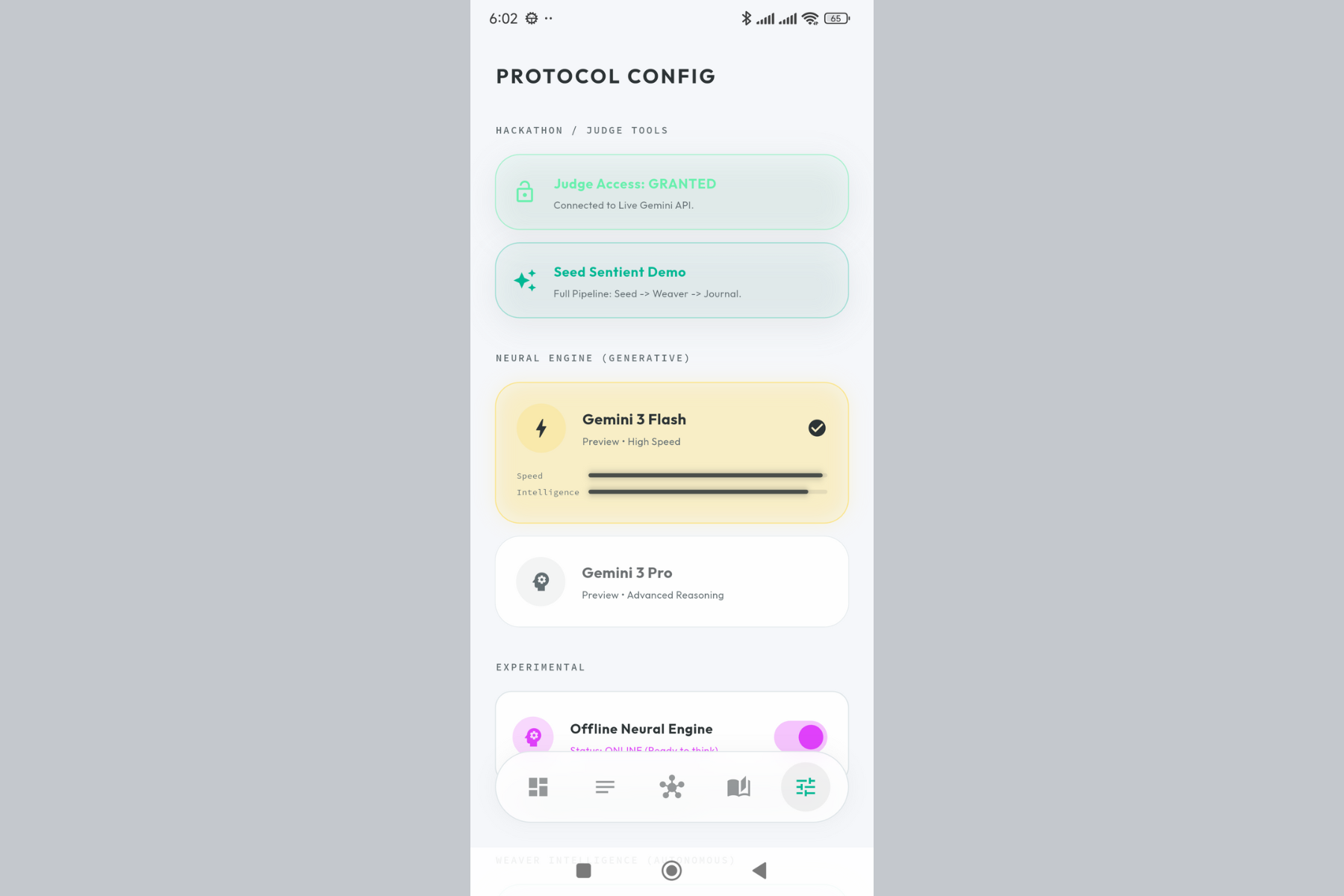
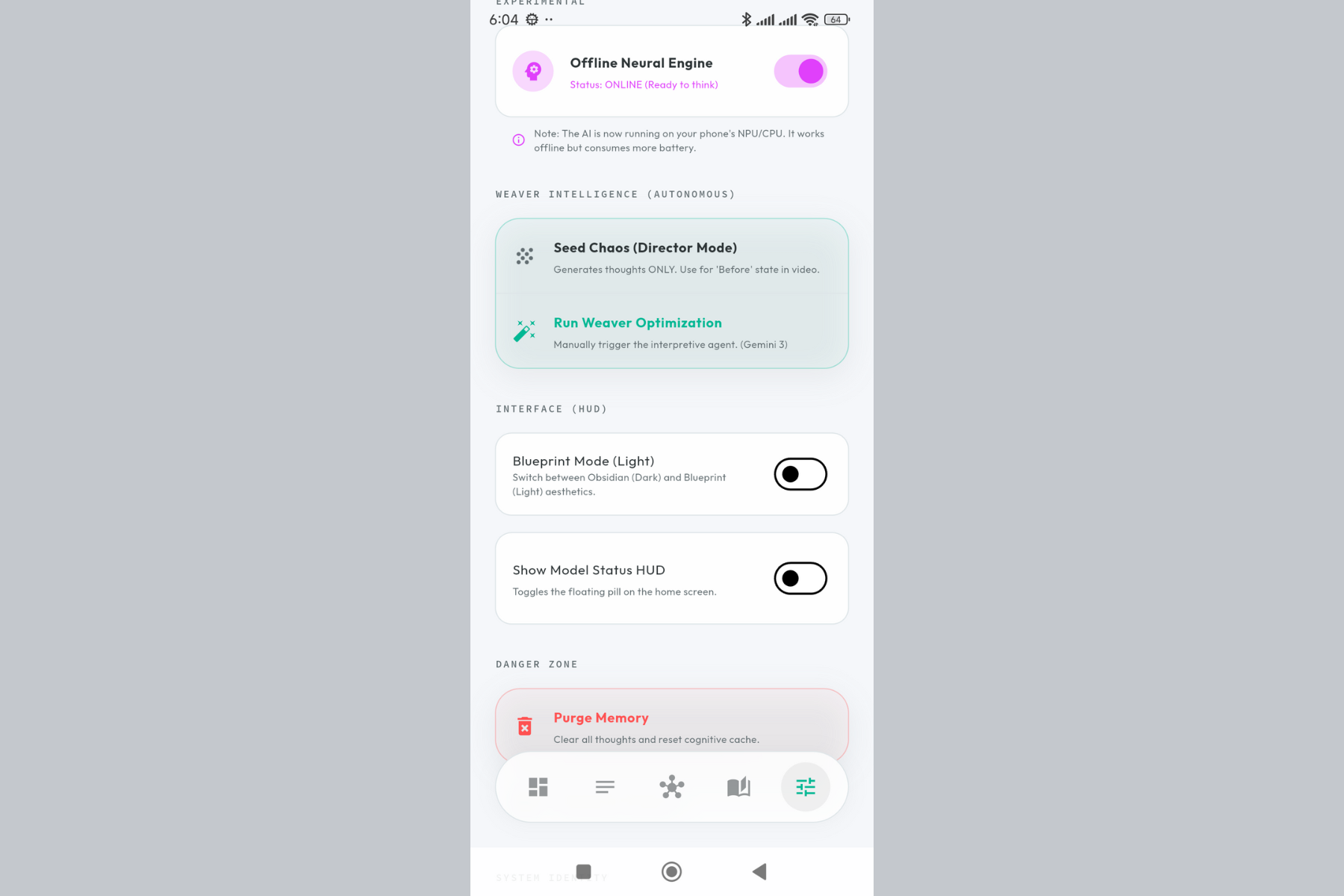
Choose your AI models. Gemini 3 Flash for speed, Gemini 3 Pro for depth. Full control over your semantic engine.
-
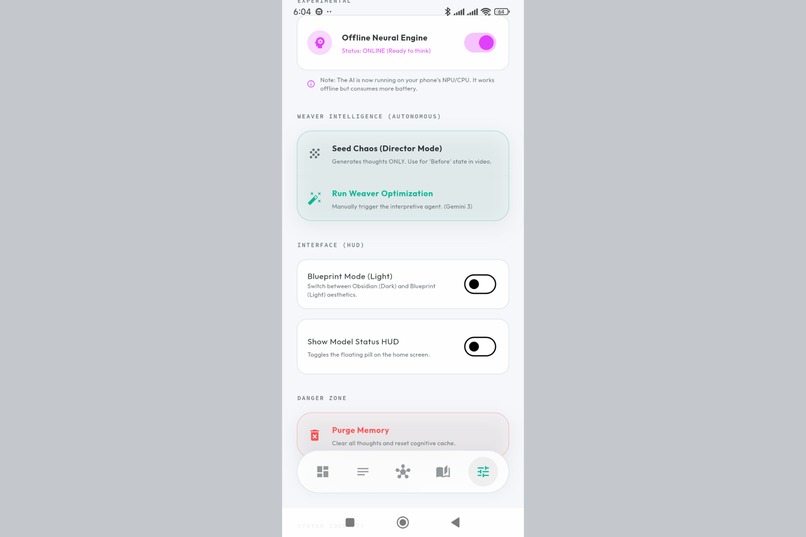
Configure the Weaver - your autonomous agent that scans for patterns, conflicts, and hidden connections.
-
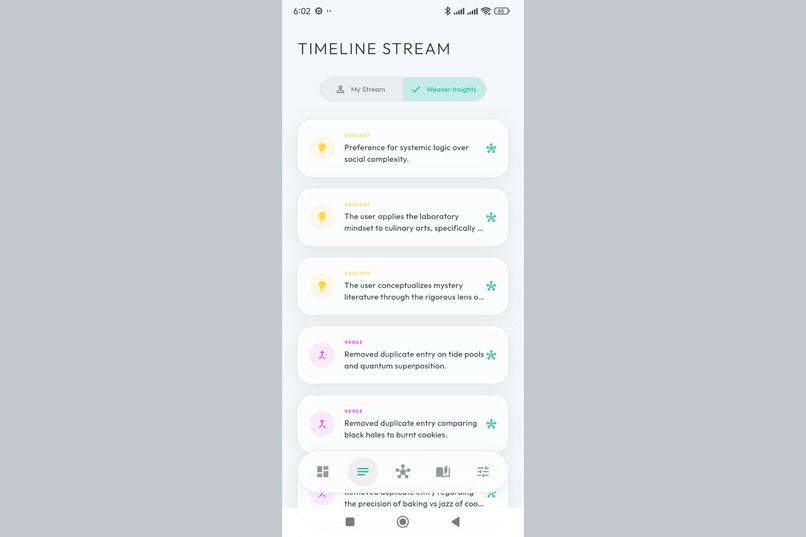
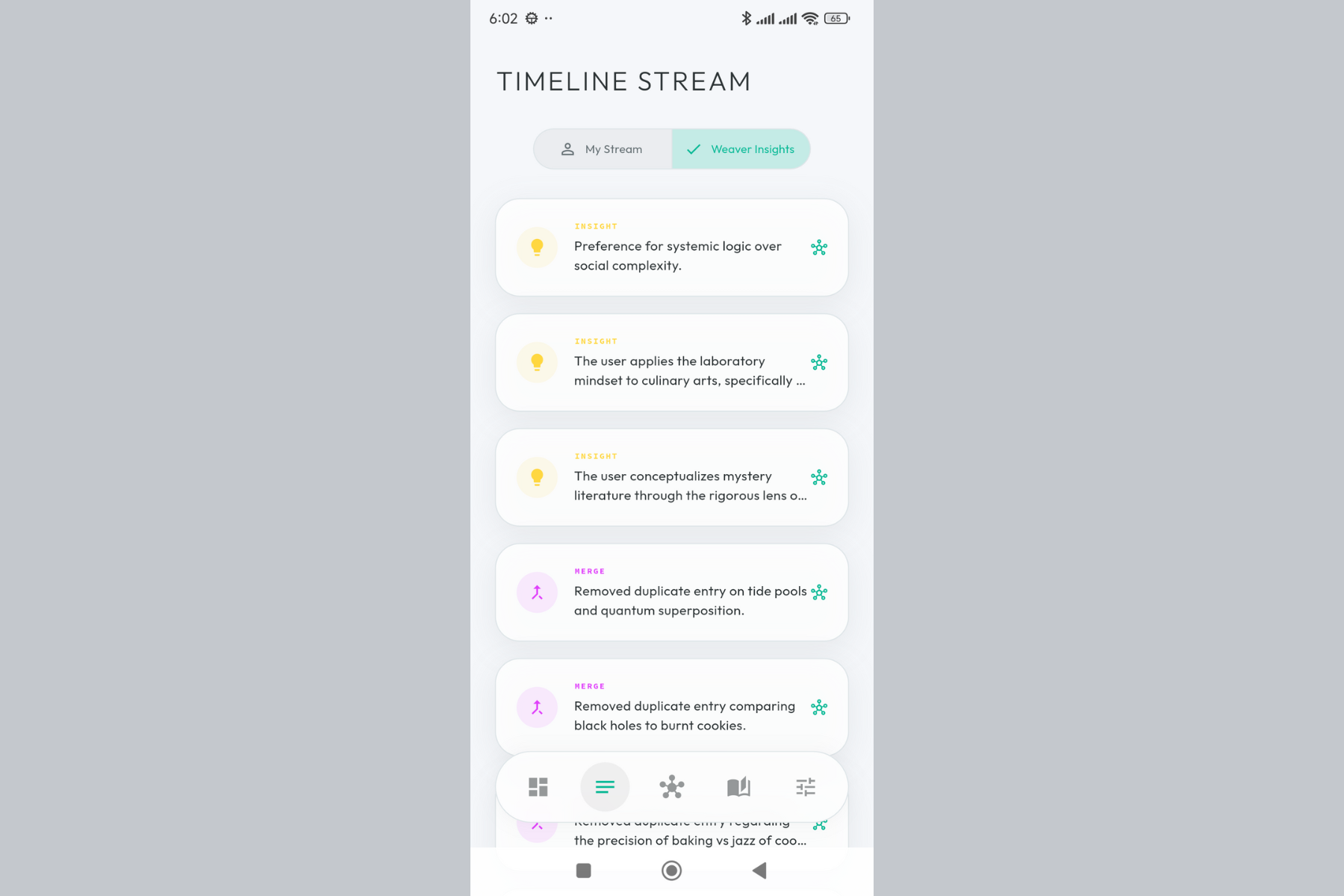
The Weaver at work. AI-discovered insights appear in your stream, connecting ideas you never explicitly linked.
-
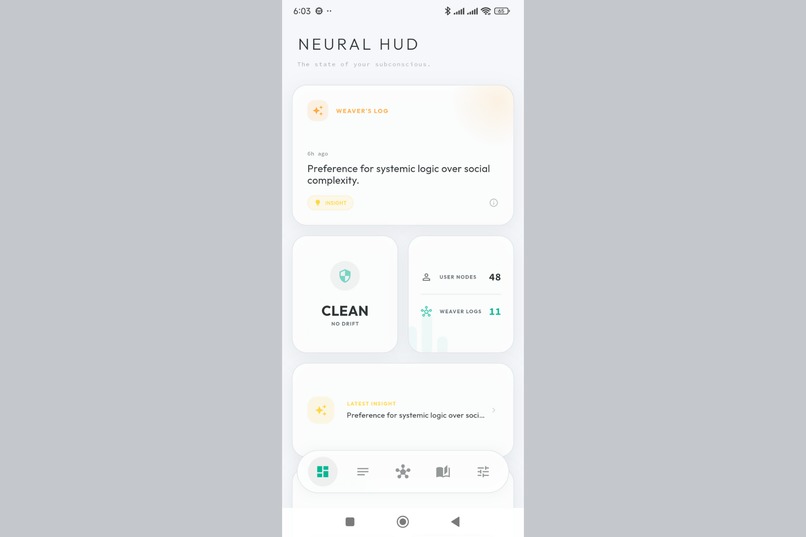
Your thought universe at a glance. Quick stats, recent activity, and one-tap access to all features.
-
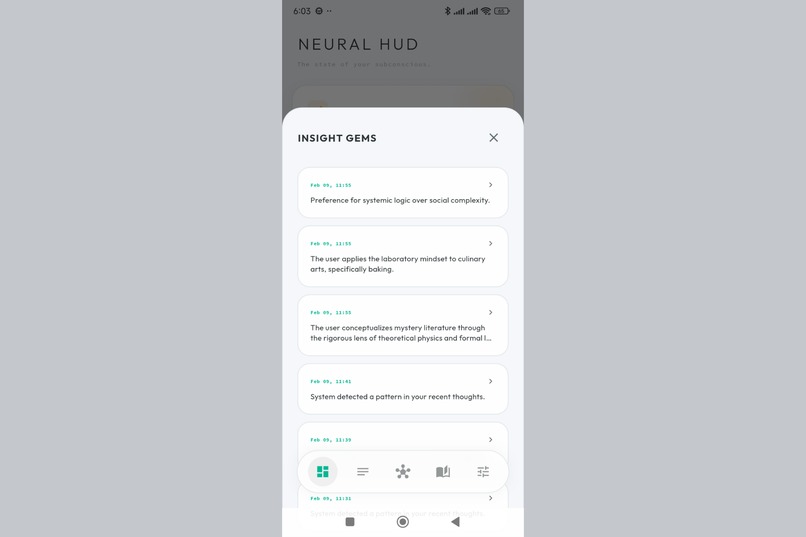
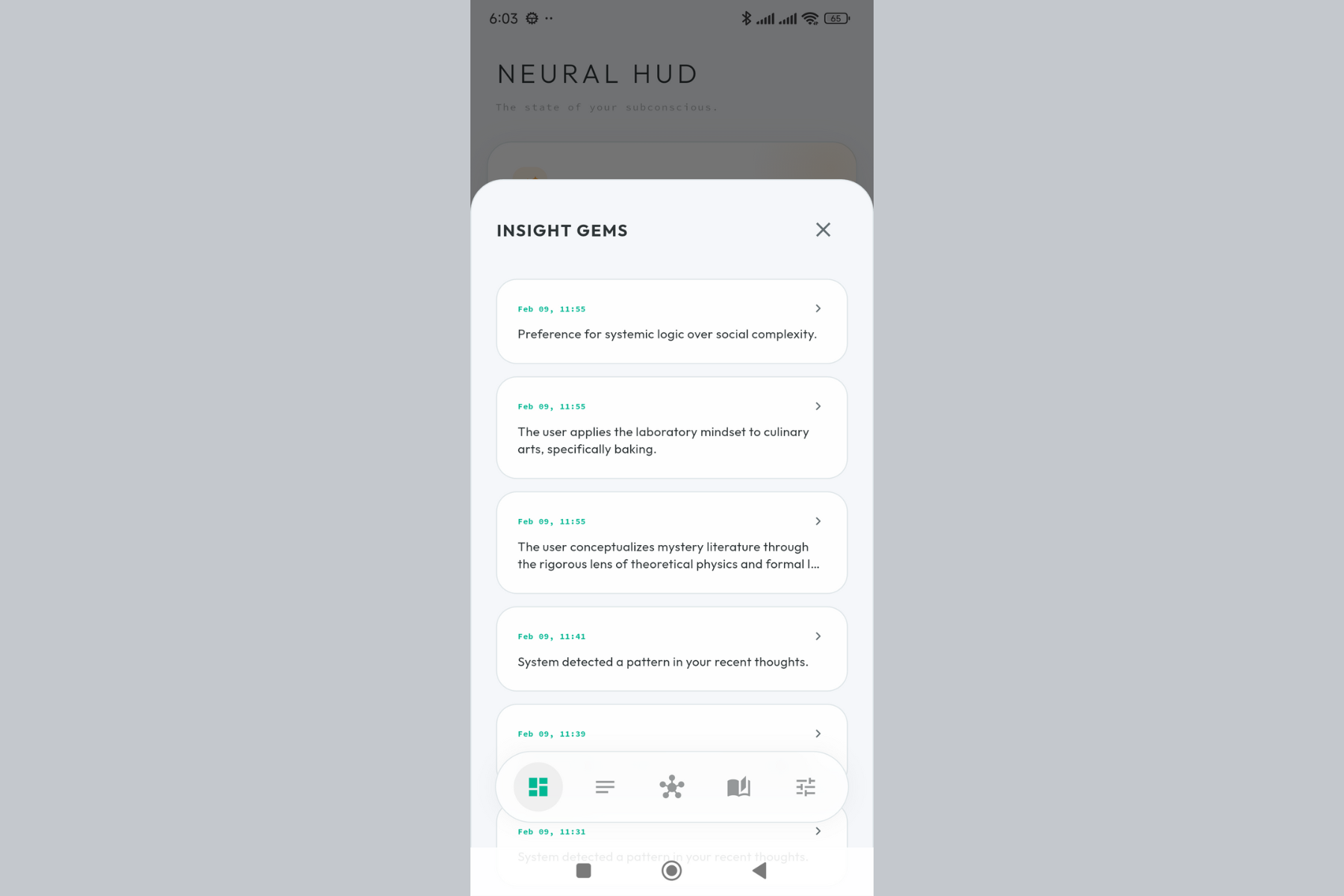
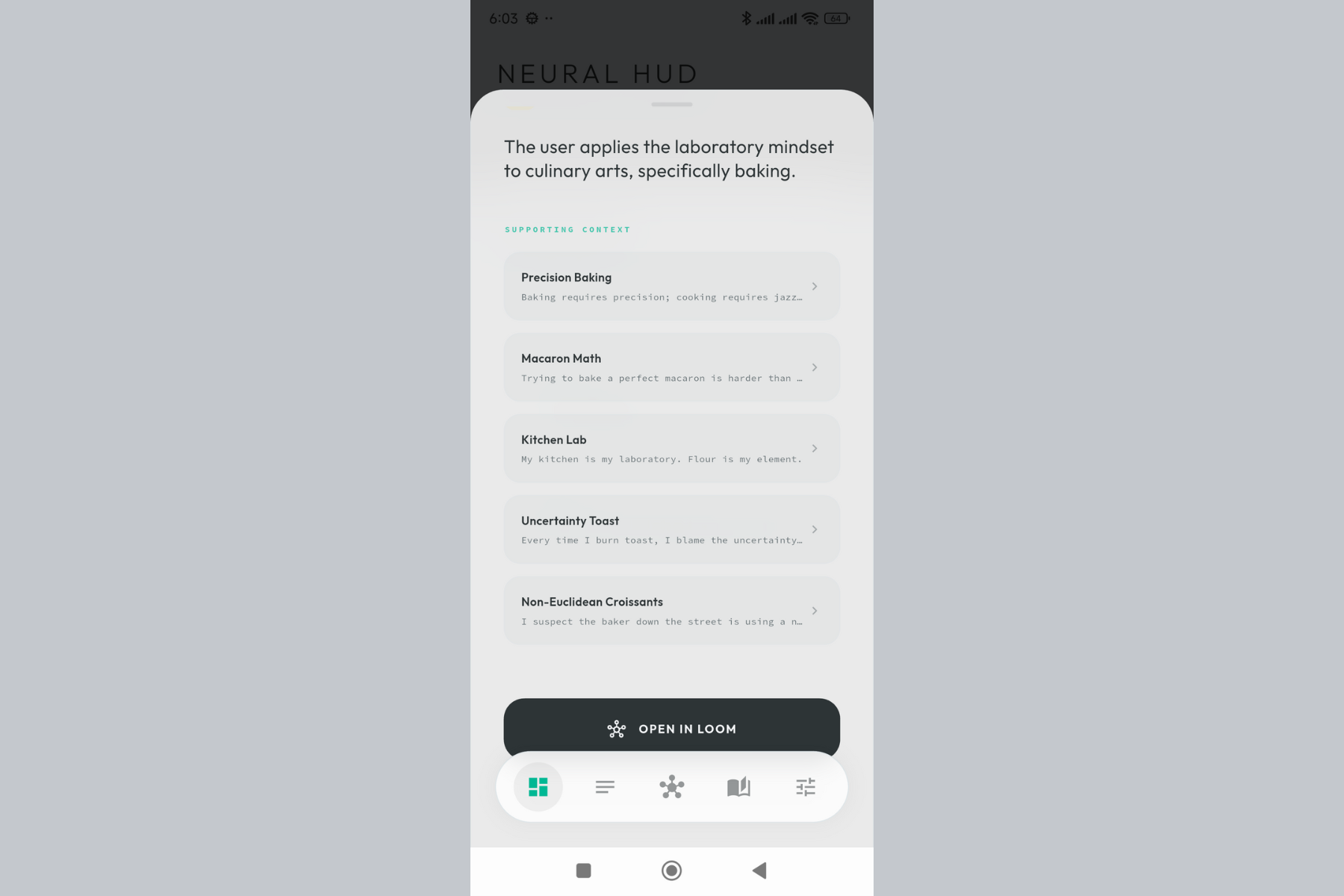
Every insight the Weaver has discovered. Conflicts, connections, and patterns - all in one place.
-
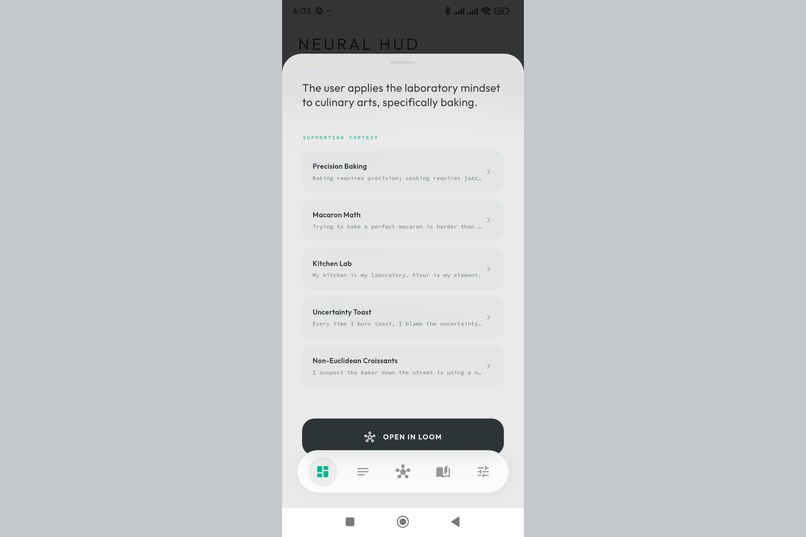
A single insight card. The AI found a connection between thoughts you didn't consciously link.
-
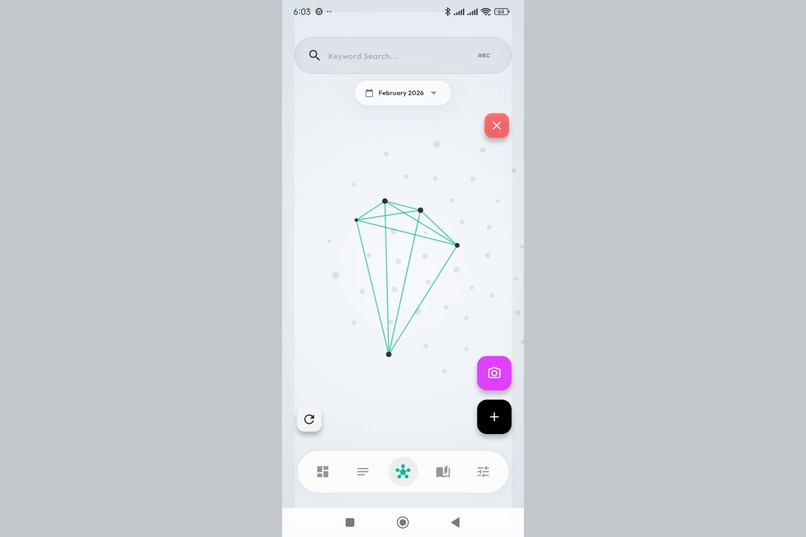
Insights visualized in the graph. See exactly which thoughts the AI connected and why.
-
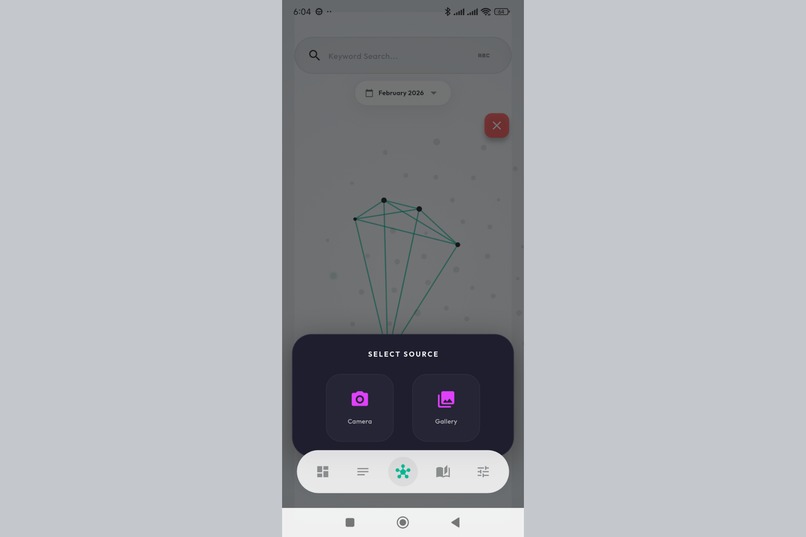
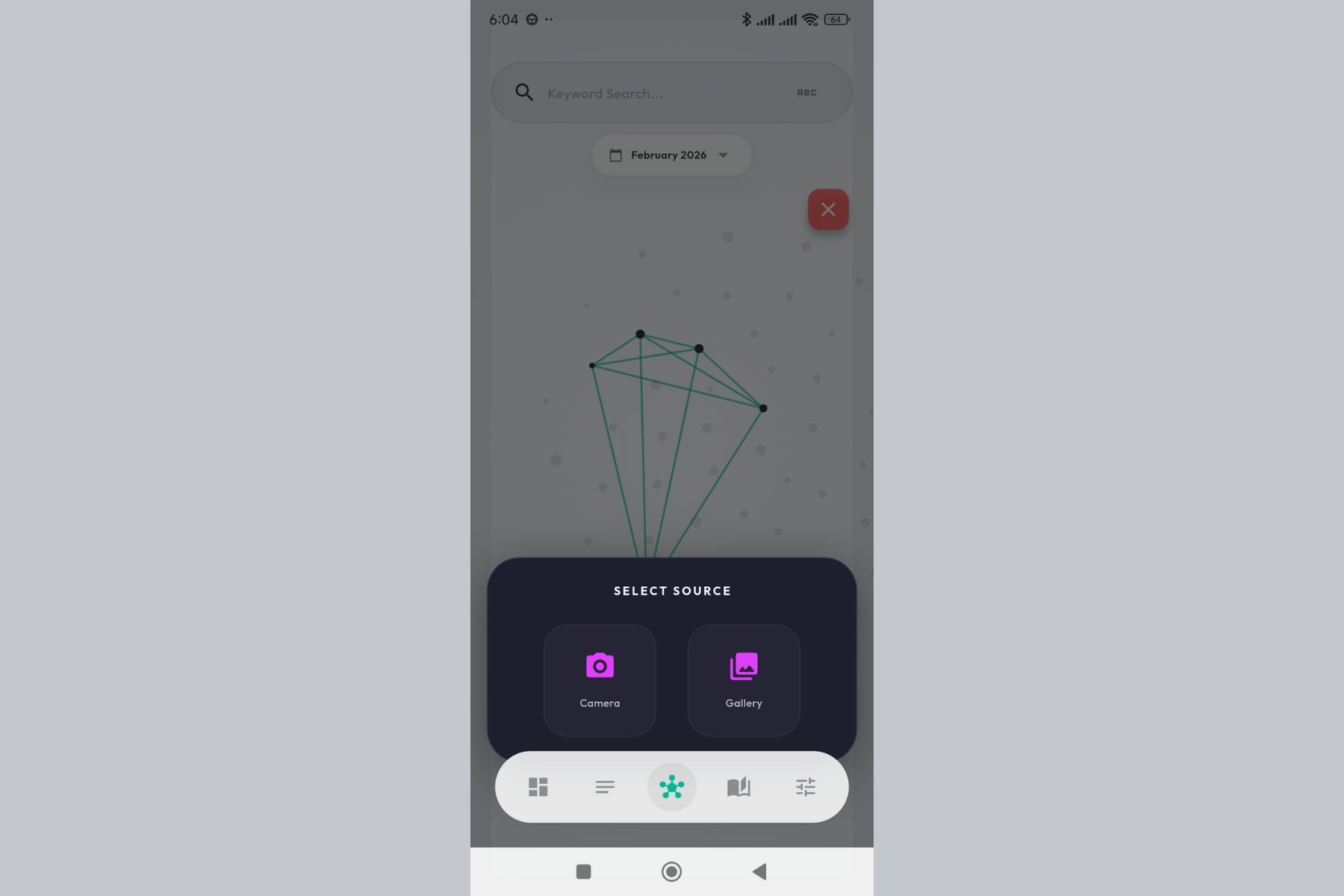
Multimodal input. Capture images directly or pick from gallery - Gemini 3 extracts meaning from visuals.
-
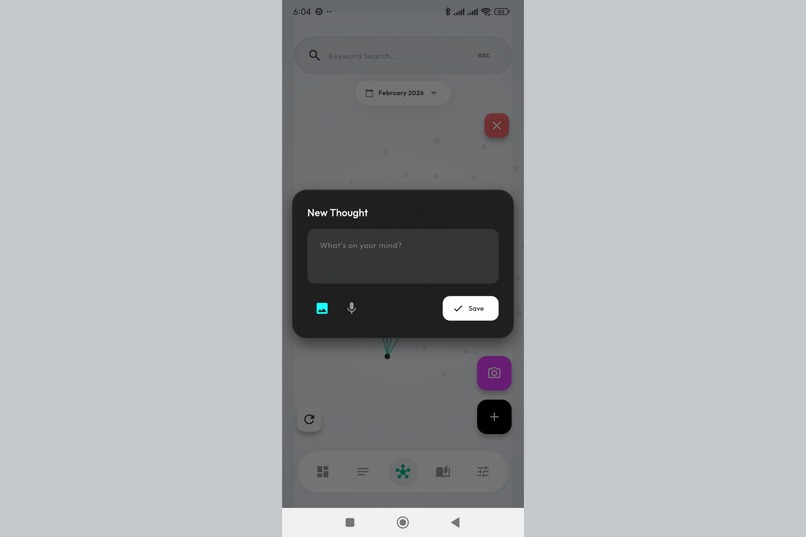
One tap to capture. No friction between thinking and recording - just pure, unfiltered thoughts.
Inspiration
I've always struggled with scattered thoughts. Ideas come at random moments - in the shower, during a walk, at 3 AM - and they feel connected somehow, but I can never quite see the pattern. Traditional note apps are just lists. They store thoughts but don't understand them.
I wanted to build something that could see what I couldn't: the invisible threads between my ideas. A second brain that doesn't just remember, but weaves.
When Gemini 3 launched with its improved reasoning and multimodal capabilities, I saw the opportunity to combine cloud intelligence with local privacy. What if the AI could understand my thoughts without ever reading them?
What it does
The Context Loom transforms your scattered thoughts into a living, self-organizing galaxy.
- Capture - Jot down any thought in seconds
- Embed - An on-device AI generates a "soul" (semantic embedding) for each thought, completely offline
- Weave - Related ideas automatically cluster together based on meaning, forming a visual constellation
- Discover - Gemini 3 analyzes patterns, finds insights you missed, and detects contradictions in your thinking
The result is a privacy-first knowledge graph where you can see how your mind connects ideas.
How I built it
The Dual AI Architecture:
| Component | Technology | Purpose |
|---|---|---|
| The Shield | EmbeddingGemma-300m-ONNX + Dart Isolate | On-device embeddings. Raw thoughts never leave the phone. |
| The Sword | Gemini 3 Flash/Pro | Cloud-powered analysis, summaries, and insight generation |
The Stack:
- Flutter for cross-platform UI
- Riverpod for state management with code generation
- Hive with AES encryption for local storage
- flutter_onnxruntime for running a 300MB embedding model on-device
- Dart Isolates for background processing (physics simulation + AI inference)
The Physics Engine:
A custom force-directed graph runs at 60 FPS in a background isolate. Thoughts repel each other (like electrons), but semantically similar ones attract (via cosine similarity > 55%). The result is an organic, self-organizing layout.
Gemini Integration
The Context Loom uses Gemini 3 as "The Sword" - the cloud intelligence layer that provides deep reasoning capabilities. Here's exactly how Gemini is integrated:
Models Used:
- Gemini 3 Flash (
models/gemini-3-flash-preview) - Primary model for fast operations - Gemini 3 Pro (
models/gemini-3-pro-preview) - Fallback for complex reasoning - Gemini Embedding 001 (
models/gemini-embedding-001) - Cloud embedding fallback
Gemini-Powered Features:
Thought Summarization - When you capture a thought, Gemini generates a concise title that captures the essence of your idea.
Image Analysis - For thoughts with attached images, Gemini's multimodal capabilities extract semantic meaning, describing what's in the image so it can be woven into the graph.
The Weaver (Autonomous Agent) - The core innovation. Gemini analyzes clusters of related thoughts and:
- Generates Insights - New thoughts that connect previously unlinked ideas
- Detects Conflicts - Contradictions in your thinking
- Proposes Merges - Identifies duplicate or overlapping concepts
Journal Generation - Gemini synthesizes your thought patterns over time into readable summaries, using content generation to create narrative reports.
Privacy-First Design: Raw thoughts are embedded locally using EmbeddingGemma (ONNX). Gemini only receives:
- Text for summarization (after local embedding)
- Minimal context for Weaver optimization
- Image data only when explicitly attached
This hybrid approach ensures your private thoughts stay on-device while still leveraging Gemini's reasoning power when you choose to.
Challenges I ran into
1. The Int64 Crisis
The ONNX model demanded 64-bit integer inputs, but Flutter's C++ bridge only supported 32-bit. The model wouldn't budge. The wrapper couldn't help.
Solution: I wrote a Python script to surgically modify the neural network graph itself, injecting Cast nodes at the input layer. Flutter sends Int32, the Cast Node converts it, and the model thinks it's getting Int64. Surgery successful.
2. The 5-Second Freeze
Loading a 300MB model blocked the UI thread completely. The app was unusable.
Solution: Implemented the Actor Pattern with Dart Isolates. The main thread handles UI at 60 FPS while a background isolate holds the entire model in RAM. They communicate via message passing.
3. Tensor Dimension Mismatch
The model returned 3072-dimensional outputs instead of the expected 768. It was giving me raw tokens instead of a sentence embedding.
Solution: Implemented smart output handling - check for pre-pooled output first, fall back to manual mean pooling if needed.
Accomplishments that I'm proud of
- True offline AI - The core embedding engine works without any internet connection
- 60 FPS physics - The graph simulation never drops frames thanks to isolate architecture
- Privacy by design - Your raw thoughts are embedded locally; only summarization requests touch the cloud
- Zero-config demo mode - Judges can experience the full app without an API key
- Solo build - The entire system was designed and implemented by one developer
What I learned
On-device AI is possible, but requires surgery. Model formats, tensor types, and runtime versions rarely align. Be prepared to modify the model itself.
Isolates are underrated. Dart's isolate model made it possible to run heavy AI and physics without touching the UI thread. This is how mobile AI should be built.
Privacy and power aren't mutually exclusive. By splitting responsibilities (local embeddings + cloud reasoning), you can have both.
Cosine similarity is beautiful. The way semantic vectors naturally cluster is almost magical. Two thoughts about "coffee" and "caffeine" end up as neighbors without any explicit linking.
What's next for The Context Loom: Hybrid Semantic Cortex
- On-demand model download - Currently the 300MB ONNX model is bundled. Moving to dynamic download would shrink the APK significantly.
- Multi-modal thoughts - Adding voice recordings and images as first-class nodes
- Collaborative weaving - Shared spaces where multiple people's thoughts can connect
- Export to Obsidian/Notion - Bringing the discovered connections back to traditional tools
- Larger models - As phone hardware improves, I could run more powerful embedding models for even better clustering
Third-Party Tools Used
- EmbeddingGemma-300m-ONNX - Google's open embedding model, converted to ONNX format for on-device inference
- ElevenLabs - AI voice generation for the demo video narration
- flutter_onnxruntime - Flutter plugin for ONNX model inference
- SentencePiece - Tokenizer for the embedding model

Log in or sign up for Devpost to join the conversation.