-
-
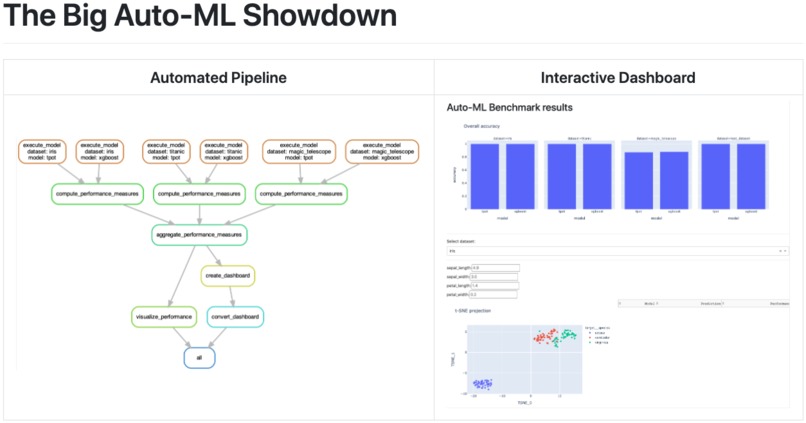
Overview
-
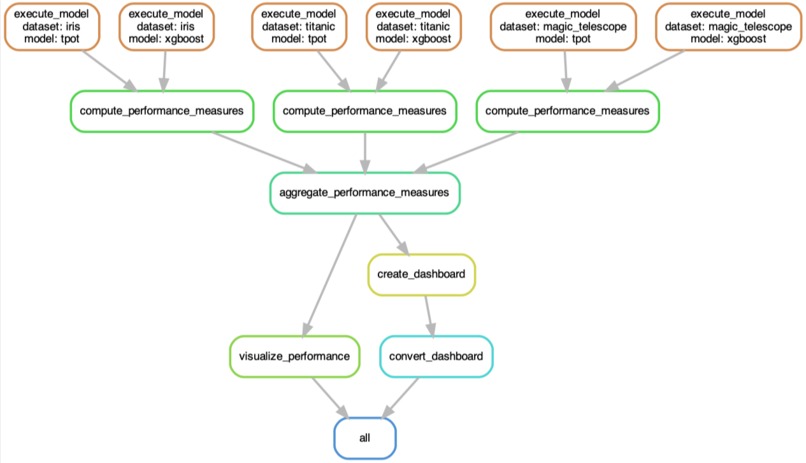
Automated Pipeline
-
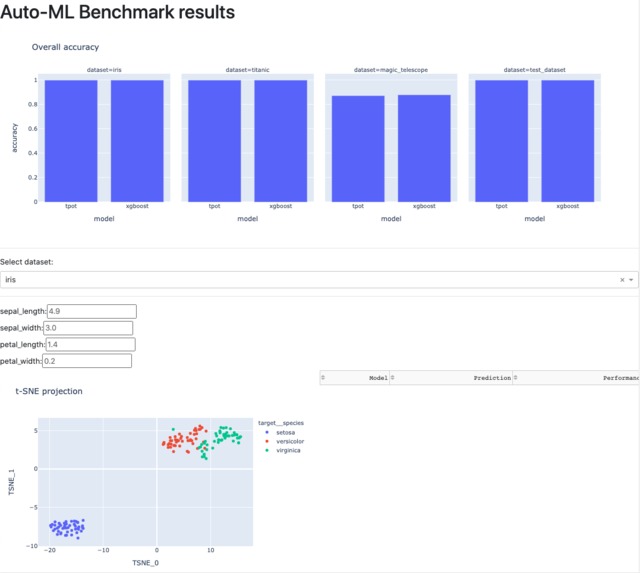
Interactive Dashboard

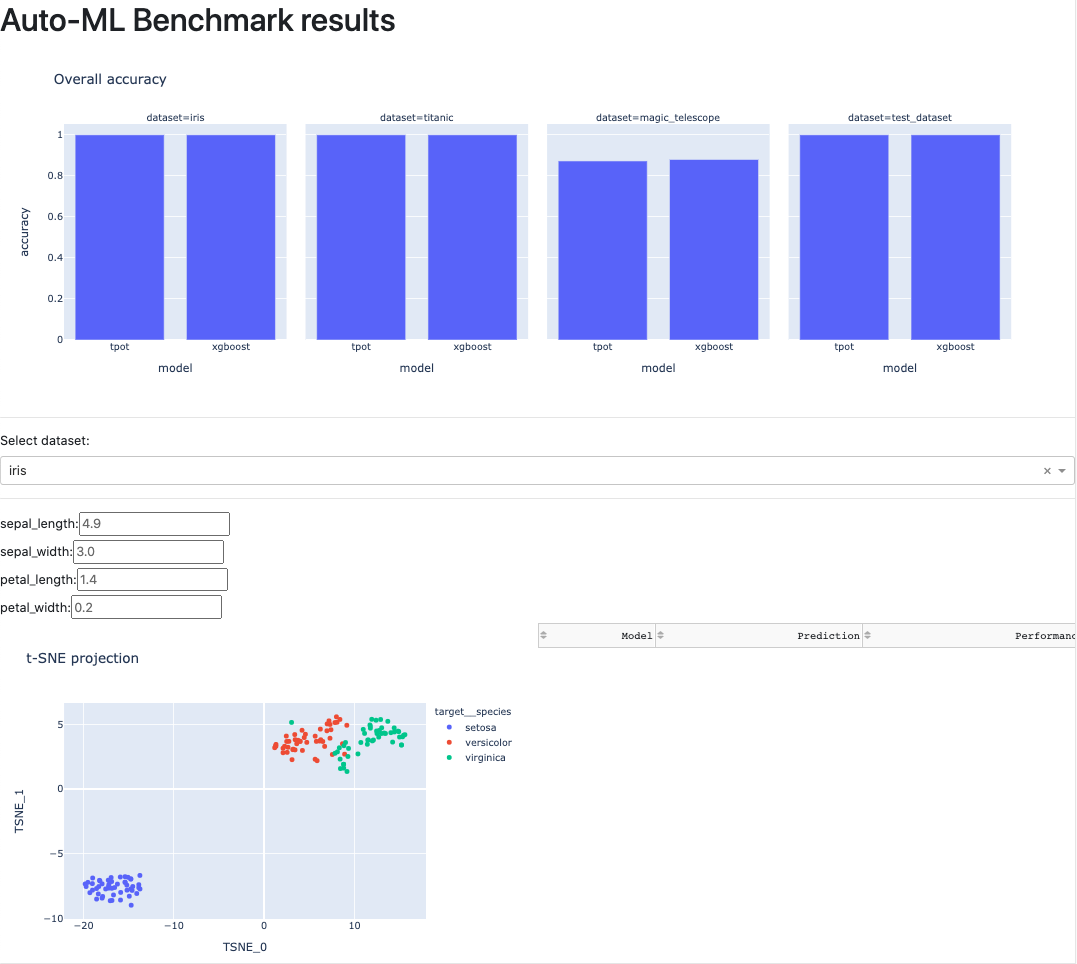
Machine learning methods are often seen as black boxes which are difficult to understand. Automated machine learning frameworks tend to take these boxes, put them into a dark room, lock the door, and run away (watch out for sarcasm!). So instead of improving interpretability directly, let's conduct a benchmark in a meaningful way in order to learn more about them.
There have been some approaches in this direction already. See, e.g., the AutoML Benchmark, the work of STATWORX, and the benchmark accompanying the Auto-Sklearn publication. However, they are all lacking with regards to the underlying pipeline system using to setup the benchmark, as well as the exploration capabilities of the results.
Here, we build a sustainable (i.e. reproducible, adaptable, and transparent) workflow to automatically benchmark a multitude of models against a diverse set of data. The models are existing auto-ML frameworks which each have their own advantages and disadvantages related to ease-of-use, execution speed, and predictive performance. All of these features will become apparent in this benchmark. The datasets try to be as representative as possible and cover a wide range of applications. They thus serve as a reasonable playground for the aforementioned models. Finally, the results are displayed in an interactive dashboard which allows an in-depth exploration of the generated performance evaluation.
Challenges:
- Making the pipeline run with literally a single command, no further tweaks needed. This includes automatic feature (pre-/post-) processing (e.g. encoding of non-numeric variables), incorporating the ML Python packages in a robust way, and designing the pipeline in a way which makes adding new datasets and models trivial.
- Certain aspects of building the dashboard using jupyter, plotly, and dash. E.g. dynamic input field detection in dash is a rather recent feature, and required some documentation and blog-post digging on my side to figure out. More importantly, noticing that the jupyter-dash package (https://github.com/plotly/jupyter-dash) exists made rapid prototyping so much easier.
- Running the models in the dashboard. Most models can luckily be simply pickled and then loaded from within dash. However, the feature encoding needs to be the same in the pipeline and dashboard to avoid subtle bugs. So these two models need to be loaded synchronously.
- For some of the bigger datasets (e.g. the MAGIC telescope one), it took a long time to run the t-SNE projection using the normal sklearn model. Luckily, there exists a more efficient, multi-threaded implementation (https://github.com/DmitryUlyanov/Multicore-TSNE). Using the GPU for acceleration was not suitable for me, so finding the best way of doing the projection required some thought. In addition, one could add a umap projection as well.

Log in or sign up for Devpost to join the conversation.