-
-
The Archivist
Inspiration
Have you ever physically torn your hair out because Batman literally blows a guy up with a flamethrower tank... the same Batman who has a strict no-kill policy? Or have you had to restrain yourself from throwing something at the TV because somehow Game of Thrones went from gritty, chaotic medieval battles to perfectly coordinated flanking formations and instantaneous logistics overnight? Or when watching Harry Potter, have you ever wondered how on earth Hermione had a time-turner this whole time and nobody, not even Hermione herself, thought to mention it ever again?
Plot inconsistencies are plentiful in almost any fictional world, and despite authors' best efforts and editors' proofreading, these slip through the cracks, breaking the immersion readers invest in. The most common are character-focused, where a character acts in a way that fundamentally contradicts who they are, or setting-focused, where the world shifts arbitrarily without reason or logic.
We were inspired by these inconsistencies to build an AI that helps authors keep track of their characters and settings, ensuring their world-building stays airtight, no mistakes, no immersion-breaking moments, just the story staying true to itself.
What it does
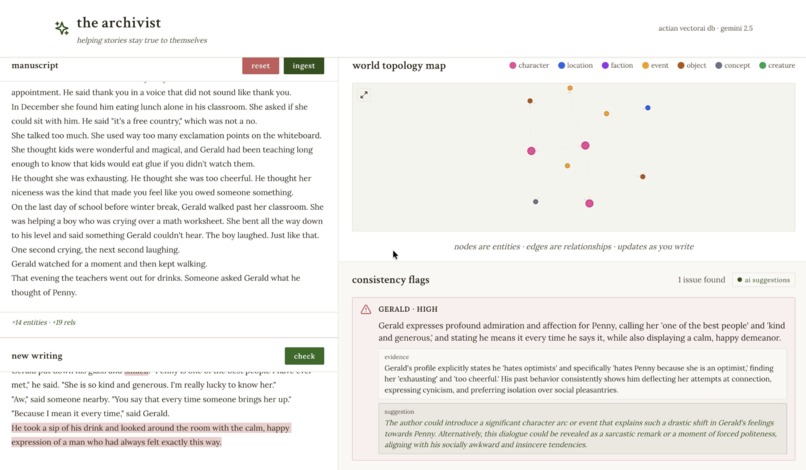
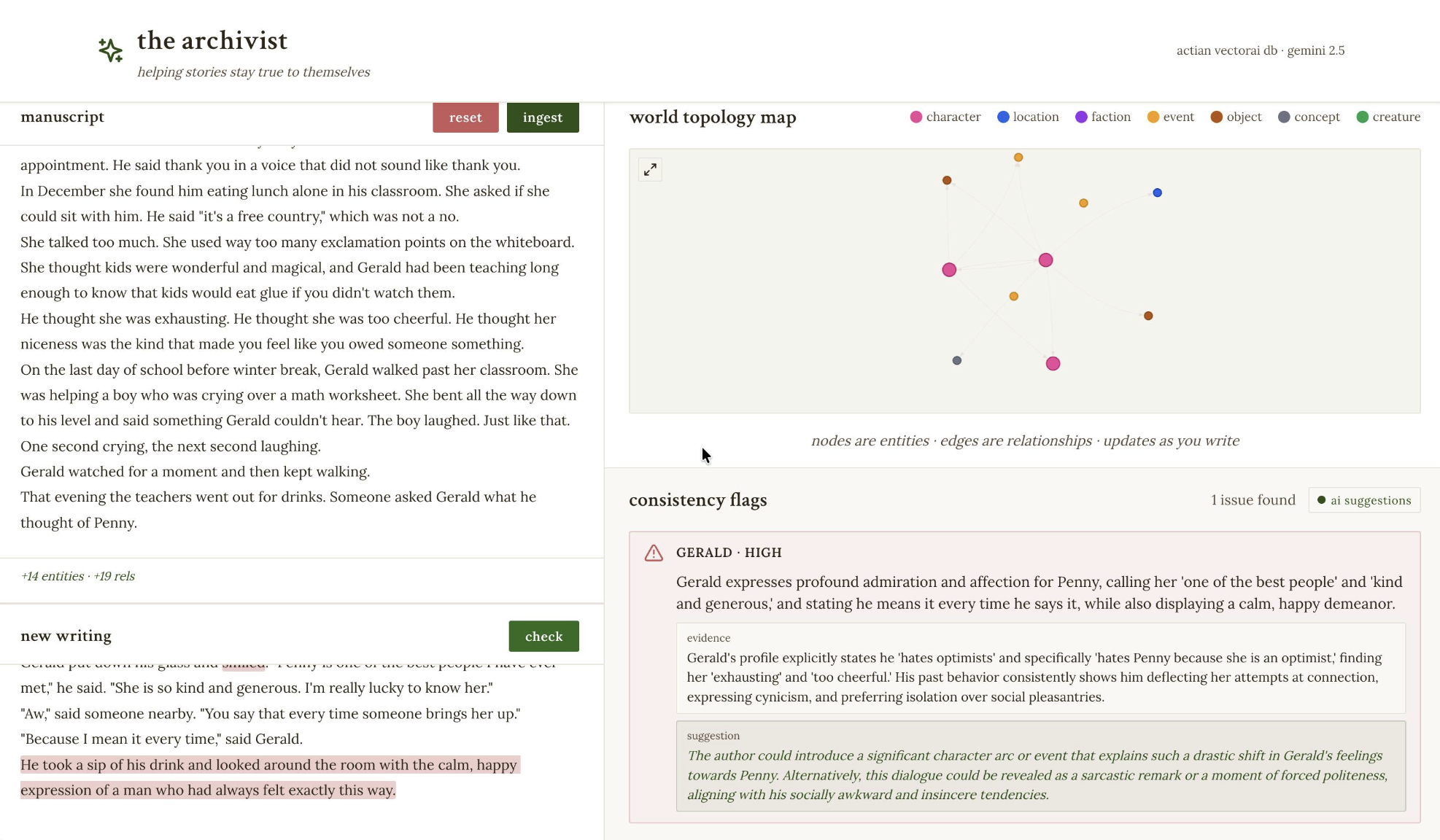
The Archivist processes a story manuscript to create a knowledge graph built on character traits, settings, and story concepts. Using modern LLM based RAG, as you continue writing, the Archivist flags any inconsistencies, which can range from character contradictions to setting errors, and offers real-time suggestions to resolve those conflicts. It provides immediate corrections for your work as you type, in order to ensure narrative continuity.
How we built it
Backend
The backend is separated into three distinct flows.
Tech Stack: Actian VectorAI DB, Gemini 2.5 Flash API, Gemini Embedding 001, SQLite3, Python, FastAPI, Docker
1.) The first processes the manuscript by chunking it into paragraphs, summarizing them with Gemini, converting them into vector embeddings, and storing them in Actian VectorDB for later retrieval.
2.) The second process involves the manuscript being chunked into paragraphs and passed through Gemini to extract rules, which are stored in a SQL database as entities, attributes, and relationships.
3.) The last process gets the current paragraph being written, converts it into a vector embedding, and searches the VectorDB for the top three most similar paragraphs based on cosine similarity.
Finally, all three flows converge at a final Gemini model, which takes the current paragraph, the top three similar paragraphs, and the extracted relevant rules from knowledge graph to search for conflicts and generate output suggestions.
Throughout this entire process, Actian VectorDB, SQL, and Gemini are closely integrated, working together to develop rules, surface relevant context, and resolve conflicts before they make it into the final story.
Frontend
Tech Stack: React 18, TypeScript, Tailwind, Vite, Axios, vis-network
1.) The frontend initializes a single-page React 18 application where all application state is managed inside a central Dashboard component, ensuring a single source of truth with no routing or global state.
2.) When a user performs an action (such as ingesting data, querying relationships, validating logic, or resetting the system), the Dashboard constructs a fully typed request and sends it to the backend using Axios.
3.) The backend returns structured, strongly typed data (entities, relationships, validation results, or graph structures), which the Dashboard stores in local state and uses to trigger a re-render.
4.) The updated graph data is passed as props into a WorldGraph visualization component, which uses vis-network to render entities as nodes and relationships as edges in an interactive graph.
5.) Because all requests and responses are strictly typed with TypeScript, the entire data flow — from user interaction to visualization — remains predictable, safe, and easy to reason about.
Challenges we ran into
One challenge we encountered was maintaining context for entities addressed as pronouns across the chunking process. For example, if "Character A" is referred to by name in Chunk 1 but only by pronouns in Chunk 2, the system loses the character's context and cannot assign new information to the correct entity. We resolved this issue by identifying entities in the initial chunks and forward-propagating that metadata into subsequent chunks. This essentially created a "linked list" of context, allowing us to overcome the problem of ambiguity.
Another challenge we faced was poor LLM output quality, where the system failed to accurately recognize entities, attributes, and relationships. We solved this issue through aggressive prompt engineering, providing the model with more context using few-shot prompting and strict output templates.
Lastly, we faced compatibility issues between Actian VectorDB and macOS on the Apple Silicon architecture. We spent a significant amount of time attempting to alter Docker settings and adjusting our command-line configurations. However, through trial and error, we discovered that the solution was simply to update macOS to the latest version to ensure full compatibility with the hardware's virtualization layer.
Accomplishments that we're proud of
We are very proud to have developed a fully functional RAG model that uses a manuscript as its core corpus. Then, by utilizing vector embeddings and similarity searches, the system is able to build a robust knowledge graph using SQL and Actian Vector DB in conjunction. This architecture creates a viable and fully functional conflict tracker that is able to maintain deep context across large-scale narratives.
A standout achievement of this project is the AI's ability to "remember" precise characterization and setting details from the earliest chapters without fine-tuning LLM on the context. Usually an AI will not be able to remember early context in a large text file because it is overwhelmed with so much information, but by using a knowledge graph and rules based reasoning we can allow it to flag narrative inconsistencies despite the large amount of context.
What we learned
We learned how to utilize Actian Vector DB and SQL to construct a structured knowledge graph, as well as how to implement vector embeddings and retrieve efficiently to build a functional RAG model.
What's next for The Archivist
In the future we want to expand the system’s capabilities to support other media formats, such as comic books and films. We also would like to identify deeper, latent relationships between subjects, mainly connections that are not explicitly stated but can be inferred through reader subtext. Finally, we think it would be beneficial to implement parallelism and multi-threading within the chunking process to significantly reduce system latency and loading times.

Log in or sign up for Devpost to join the conversation.