-
-

-
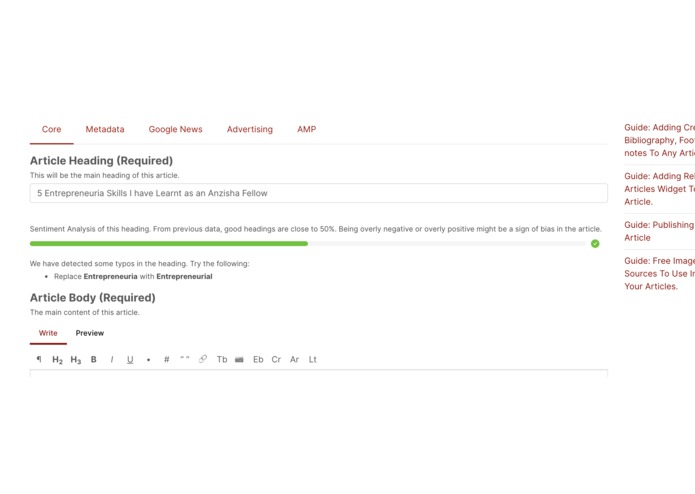
Sample - Detect spelling errors in headings
-
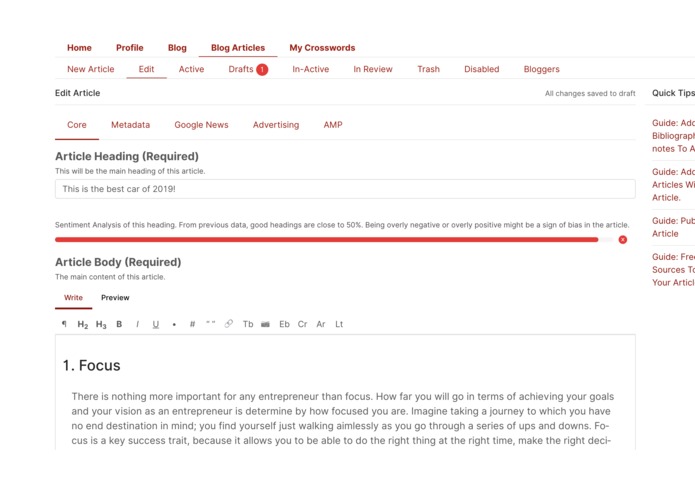
Sample - Detect overly positive articles
-
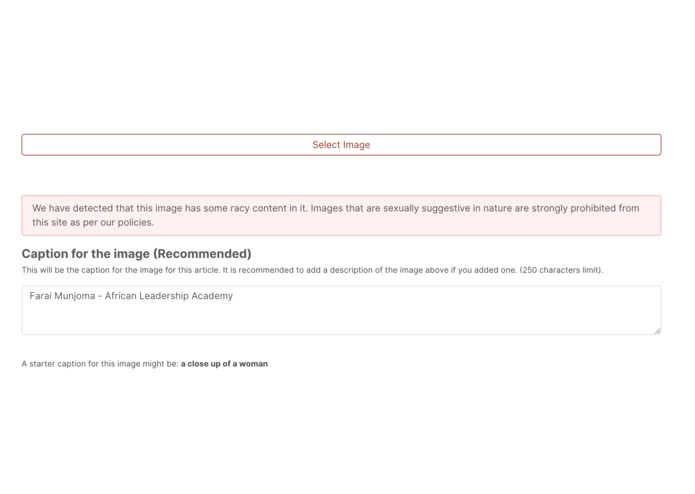
Sample - Detection of adult Images
-
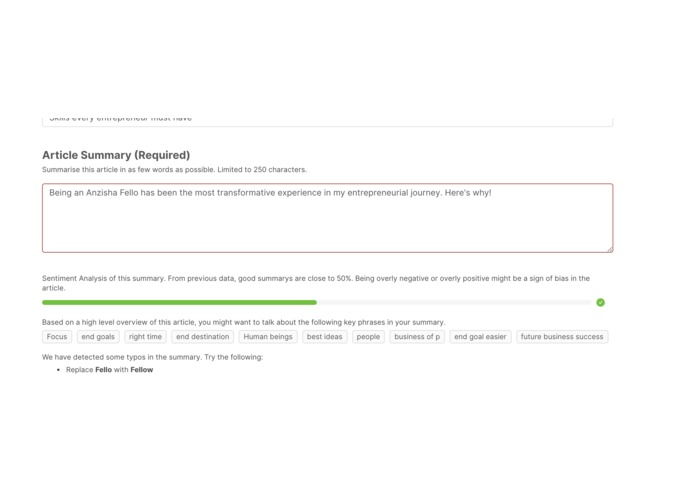
Sample - Detect and suggest key phrases for article summary





Inspiration
The African Exponent is a new site that is meant to be the one-stop-shop for all news that is related to Africa. Founded in 2015, The African Exponent had a few bloggers and writers who published content on the site. Today, The African Exponent serves over 500,000 unique page views every month featuring content from over 100 bloggers and writers. The African Exponent faces the challenge of ensuring that content published on the site is correct and unbiased. With so much content posted every day, it is tough to go over every individual article to review it. We needed a solution for this.
What it does
1) It automatically detects grammar errors in the article's heading and body and notifies the user before they publish their articles.
2) It analyzes headings and summaries of articles to detect overly negative or overly positive statements. One of the core principles that we impart to our writers is to learn how to come up with neutral headings and summaries. Excessively negative or positive titles are a big sign that the article might have a bias and (or) lack evidence.
3) It analyzes the article images to provide the author or blogger with a good starter caption they can use. Generally, we want all images in articles to have captions that explain more about the picture. Captions we get from Microsoft’s Cognitive Services serve as a good starting point to encourage users to write captions.
4) It analyzes images to detect adult content. Posting pictures showing nudity is against The African Exponent policies. Our editors can quickly identify images that go against our policies and take appropriate actions.
5) It analyses the article content and extracts essential phrases that are used to suggest topics that authors should focus on when summarizing articles. It is also used to suggest tags that an author might want to add to the article.
How I built it
The African Exponent today uses mainly NodeJS on the backend and ReactJS on the frontend. To make these improvements possible, we leverage several Azure Cognitive Services.
1) Azure Computer Vision API, [code] is used to analyze images posted in articles to get captions and detect inappropriate images.
2) Azure Text Analytics API, [code] - Entity Recognition, [code] - Key Phrase Extraction, [code] - Sentiment Analysis is used to analyze the text to get essential phrases and entities from texts such as article headings and summaries. Sentiment Analysis from the API is used to detect the positivity and negativity of article headings.
3) Azure Bing Spell Check API, [code], is used to detect spelling errors in headings and article content.
These APIs are integrated into the backend and served over GraphQL. The frontend application, in this case, the publisher, can request data about the author’s current input at any moment.
Challenges I ran into
There were a couple of minor issues that would have made the experience much better.
1) The Azure Javascript SDK is still evolving and is missing some of the APIs that are supported by Azure. To integrate these features, I needed to switch between using the SDK and raw HTTP requests. I would have preferred to use the SDK everywhere.
2) Azure Bing Spell Check API does not parse HTML content. Consumers of the API are required to parse the HTML content themselves and send only the text contained in the HTML. For complex editors such as the one used at The African Exponent, getting actual text data is a challenge. A good improvement might involve providing the flag to the Spell Check API that incoming text is of HTML format. Here is how I manually extract text from HTML in this project.
3) Both the Spell Check API and Text Analytics API fail on long texts. For a news site, some articles tend to be very long, and therefore we unable to provide useful feedback.
Accomplishments that I'm proud of
The most significant accomplishment that I am proud of is the ability to detect spelling errors in the articles. Many of our writers come from disadvantaged backgrounds, they do not have access to laptops and hence tend to publish articles from their mobile phones. The mobile publishing experience is inferior and can lead to many spelling errors in articles. This feature helps them to see their spelling mistakes and correct them before publishing. To our editors, this reduces the load of having to read an entire article to check for any errors.
What I learned
I have never integrated an Artificial Intelligence or Machine Learning service on any of my projects before. Using Azure Cognitive Services in such a short time has shown me the power that exists in these tools. I am excited to learn more about these tools. I am also ready to find new grounds on The African Exponent, where I can leverage these tools to make it easier for everyone to use the site.
What's next for The African Exponent
One of the key features that our users have asked to enable the automatic translation of our content into other languages. The Microsoft Immersive Reader API seems like the right candidate to help us with this. I am excited to explore and learn about how I can use this API to offer a better reading experience for users across the globe.
Built With
- azure
- graphql
- javascript
- node.js
- react

Log in or sign up for Devpost to join the conversation.