-
-
Project
Inspiration
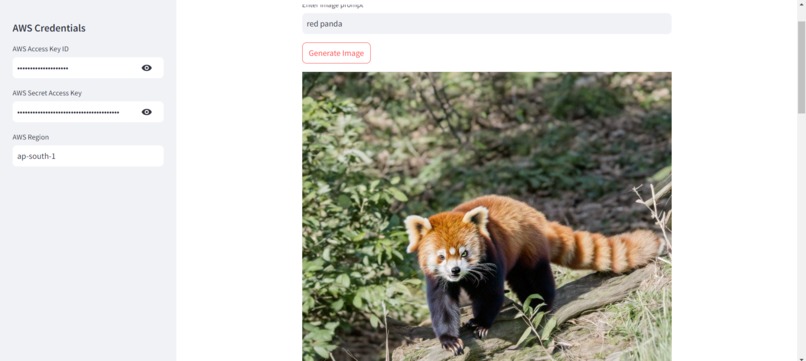
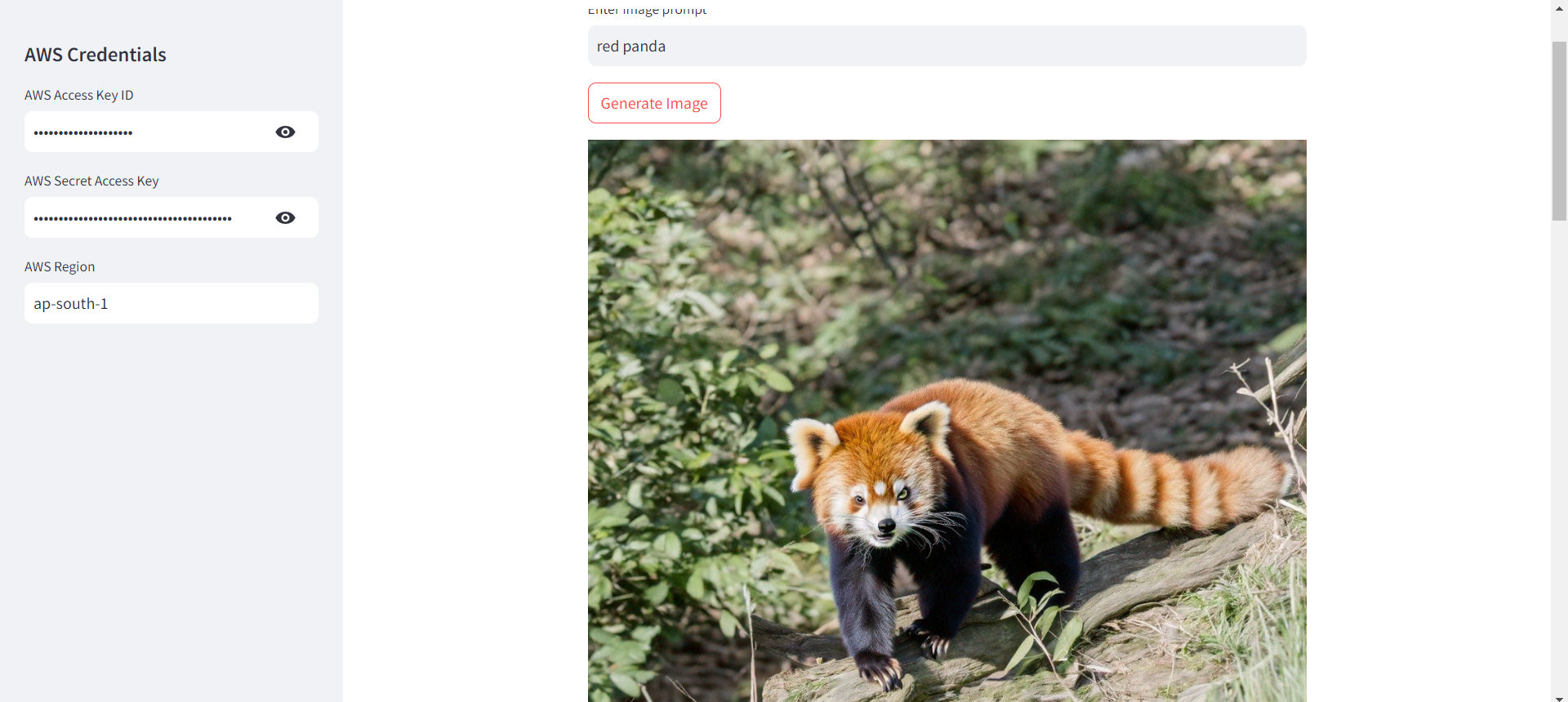
The inspiration behind this project came from the rising need for efficient text generation from images, especially in applications like automatic captioning, document digitization, and accessibility solutions for visually impaired individuals. I wanted to explore how advanced LLMs, like Amazon's Titan, could be leveraged for accurate and context-aware text generation directly from image inputs.
What I Learned
Throughout this project, I gained a deeper understanding of how to integrate large language models (LLMs) with web frameworks like Streamlit. I also learned about the internal workings of image-to-text pipelines and how Amazon Titan LLM excels in natural language processing tasks. Implementing the model in a real-world web application sharpened my skills in:
- Streamlit web app development
- Handling pre-trained LLMs in practical scenarios
- Image pre-processing techniques for model input
How I Built It
I started by creating a Streamlit web application where users can upload an image. The image is pre-processed and passed to the Amazon Titan LLM, which generates the corresponding text description. The entire process involves:
- Frontend: Built using Streamlit for simplicity and user interaction.
- Backend: Leveraging Amazon Titan LLM for text generation from image input.
- Deployment: Hosted the web app using Streamlit sharing, ensuring smooth user access.
Challenges
The biggest challenge I faced was optimizing the model to handle various image types and sizes while maintaining text generation accuracy. Additionally, integrating the model in a web app without significant latency posed another hurdle, but I overcame this by implementing efficient pre-processing steps and model optimizations. Deploying the project on Streamlit required fine-tuning to balance between performance and user experience.

Log in or sign up for Devpost to join the conversation.