-

-
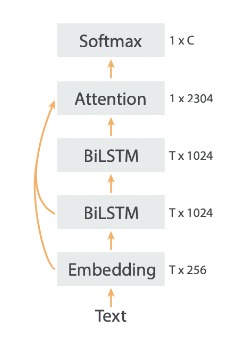
Model architecture, obtained from pg. 1616 of the original paper
-
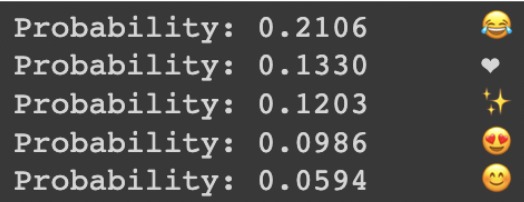
Pretrained models output to the custom tweet of "I am happy very happy and it is so sunny today”
-
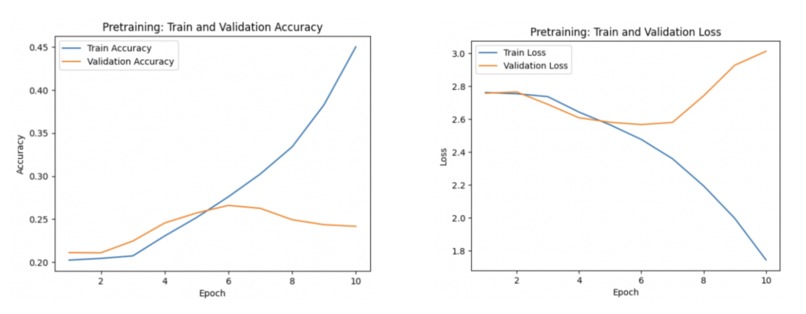
Loss and accuracy for 10 epochs of pretraining
-
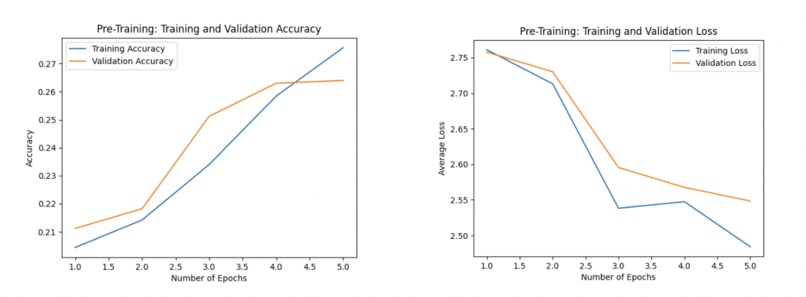
Loss and accuracy for 5 epochs of pretraining after implementing early stopping
-
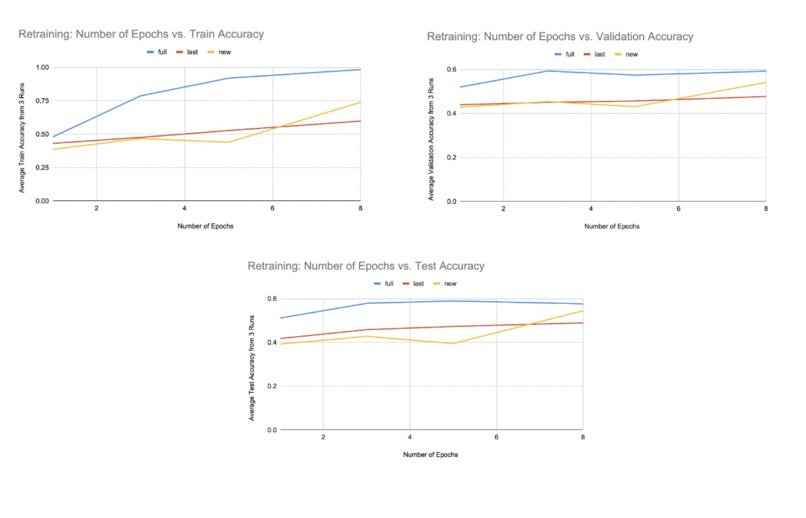
Retraining Test and Train Accuracy
-

Thumbnail (Left to Right: Amanda, Anna, Lilly)



Final Writeup
Title: Model for Predicting Emojis from Text and Transfer Learning
Who
Anna Ohrt (aohrt) Amanda Hernandez Sandate (aherna57) Lilly Schroeder (lschroe2)
Introduction
The authors of "Using Millions of Emoji Occurrences to Learn Any-Domain Representations for Detecting Sentiment, Emotion, and Sarcasm" proposed a solution to overcome a prominent and persistent challenge in natural language processing, the shortage of large and comprehensive datasets. The authors developed a model named DeepMoji that predicts an emoji to go with any given text. Then, they were able to retrain the model to repurpose it for various other NLP tasks through transfer learning.
We decided on implementing this model due to our personal interest in the subject. Emojis play a significant role in expressing emotions in modern digital communication. By delving into this project, we hoped to learn how AIs may work in creating a more authentic and effective digital communication experience.
Methodology
Data
To train our DeepMoji model (the tweet to emoji classifier) we will be using the emoji subset of the TweetEval dataset (Link). The emoji subset has 45000 training examples, 50000 testing examples, and 5000 validation examples. After pre-training, we will retrain our model on the emotion subset of the TweetEval dataset (Link) which contains 3260 training samples, 1420 testing samples, and 374 validation samples.
Architecture and Hyperperameters
Here is an image of the architecture (from pg. 1616 of the DeepMoji paper):

We plan on replicating the model within the paper. The model within the paper uses two bidirectional layers with 1024 hidden units in each layer with 512 for each direction. Additionally, there is an attention layer that will take in all of the layers as inputs and a L2 regularization of 1e−6 on the embedding weights. Lastly, a softmax layer is applied for classification. In contrast to the paper, our model used an embedding size of 256, two bidirectional layers with 1000 hidden units with 500 for each direction, a single attention layer, and a softmax layer.
In addition to pretraining, the model will be retrained in order to fine tune it to the task. Within our example paper, they use a novel transfer learning approach that they refer to as “chain-thaw”. In this approach, the new softmax layer is finetuned until convergence on the validation set, then each layer from the first layer is fine tuned. After this process, the model is trained with all layers. However, we plan on only doing the “full” (initialized with pretrained model) and “last” (initialized with pretrained model but only dense layer gets updated) transfer learning methods from the paper (note that in our implementation of the “last” method, the embedding layer also gets updated).
Metrics
Since the size of the dataset that we plan on using is drastically smaller than the one in the paper, we don’t expect our accuracy to be nearly as good. However, we do expect our accuracy to be better than chance. We will be implementing classifiers, therefore accuracy is an appropriate metric for our project.
In the DeepMoji paper, for the pretraining task, the authors compared the accuracy of the DeepMoji model, a smaller DeepMoji model, another simpler model, and random chance (see pgs. 1618-9 in the paper). In addition, for eight other datasets, the authors compared the state of the art results to the results you get from DeepMoji using four different training/retraining methods (see Table 5 on pg. 1620 in the paper). Our base goal is to preprocess the emoji subset of the TweetEval dataset and implement the DeepMoji architecture. Our target goal is to retrain our DeepMoji model for one new task (the emotion subset of the TweetEval dataset) using simple retraining methods. Our stretch goal is to implement the chain-thaw retraining method described in the DeepMoji paper and to retrain our DeepMoji model for multiple new tasks.
Ethics: What is your dataset? Are there any concerns about how it was collected, or labeled? Is it representative? What kind of underlying historical or societal biases might it contain?
Our dataset consists of twitter tweets that contain one emoji, using the tweet text as the data and emoji as the corresponding label. Because the dataset is on HuggingFace, no information is given about how the data was collected- only that tweets with one emoji were used. The other issue with our dataset is that it only contains 20 emoji/emotion labels, meaning that there are a very small number of emojis and therefore emotions that are being recognized from the tweets. This means that the data is definitely not representative of all of the emotions that could exist in a sentence, since way more than 20 emotions exist.
Emoji use in text is historically biased towards technology users who do not rely on screen readers to access text. This is because emojis often either do not have a direct text representation, or the text equivalent is not useful (for example sometimes emojis are just translated into ?, or face_with_hands for a hugging emoji). These descriptions, if they exist, are not representative of the emotions that emojis often represent, and therefore are not helpful for screen reader users who only have access to these descriptions. Therefore this group of people have been historically excluded from emoji use in the past and are therefore very likely under-represented in our dataset.
Ethics: Who are the major “stakeholders” in this problem, and what are the consequences of mistakes made by your algorithm?
The major stakeholders include people who routinely use emojis to express emotions as part of text, and anyone who analyzes social media posts such as tweets to understand the context and intent of the users. This group could include advertising companies who want to understand users’ tweeting habits, and the software engineers at these social media companies who want to figure out how to improve the platforms. If this algorithm misidentifies emotions from emojis or text tweets, these ad or social media companies could use this information to give users content or suggestions that they don’t want.
Results
Pretraining
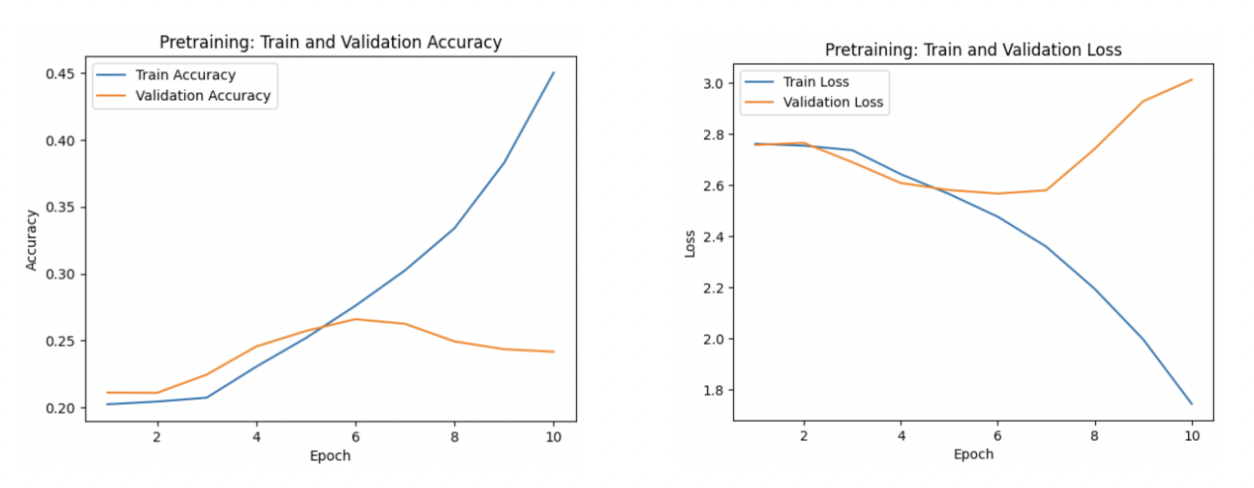
For pretraining, our results showed that our model was learning over the stretch of ten epochs with a peak of 45 accuracy. However, after a certain amount of training, it was severely overfitting as can be seen through both the validation accuracy and the validation loss. The validation accuracy and the validation loss began to decrease after six epochs. Due to several constraints including lack of computational power and time we were unable to run the numerous iterations to fine tune the model. We found that the best solution to this problem was to stop the models training once overfitting begins, early stopping. It is a form of regularization that stops the model's training when the validation accuracy stops increasing.
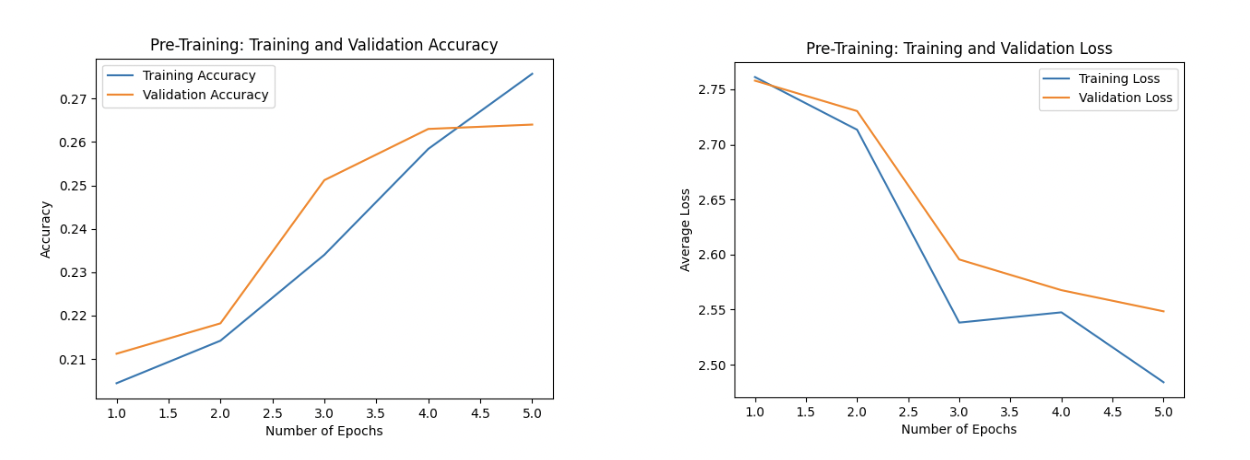
Ultimately, this process led to the model stopping training after five epochs. The figures show the results from the final pre-trained model. The model reached a peak training accuracy of 27.57% and a peak validation accuracy of 26.40%. The training and validation loss curves displayed a steady decrease during the pre-training process, suggesting that the model was learning effectively. However, given the relatively low accuracy percentages for both training and validation sets, it is clear that there is room for improvement in the model's performance. In future recreations or developments of this work, we would work more with fine-tuning the hyper parameters as well as implementing dropout layers to help with overfitting as the model trains for longer periods of time.
For the last part of pre-training, we checked the models accuracy on our own custom tweets. Here is an example of the models output for the following string:
“I am happy very happy and it is so sunny today”

The output shows the models top 5 predicted emojis with the probability of that emoji being used with the tweet.
Retraining
The last part of this project involves retraining the pretrained model to see how it performs on other different but similar NLP tasks. The task we chose to look at was emotion detection. The model was retrained using three different methods as described in the original paper: full, last, and new. Full refers to the model initialized with the pretrained model, new means randomly initialized, and last refers to the model being initialized with the pretrained model but the optimizer only updates the embedding and dense layers.
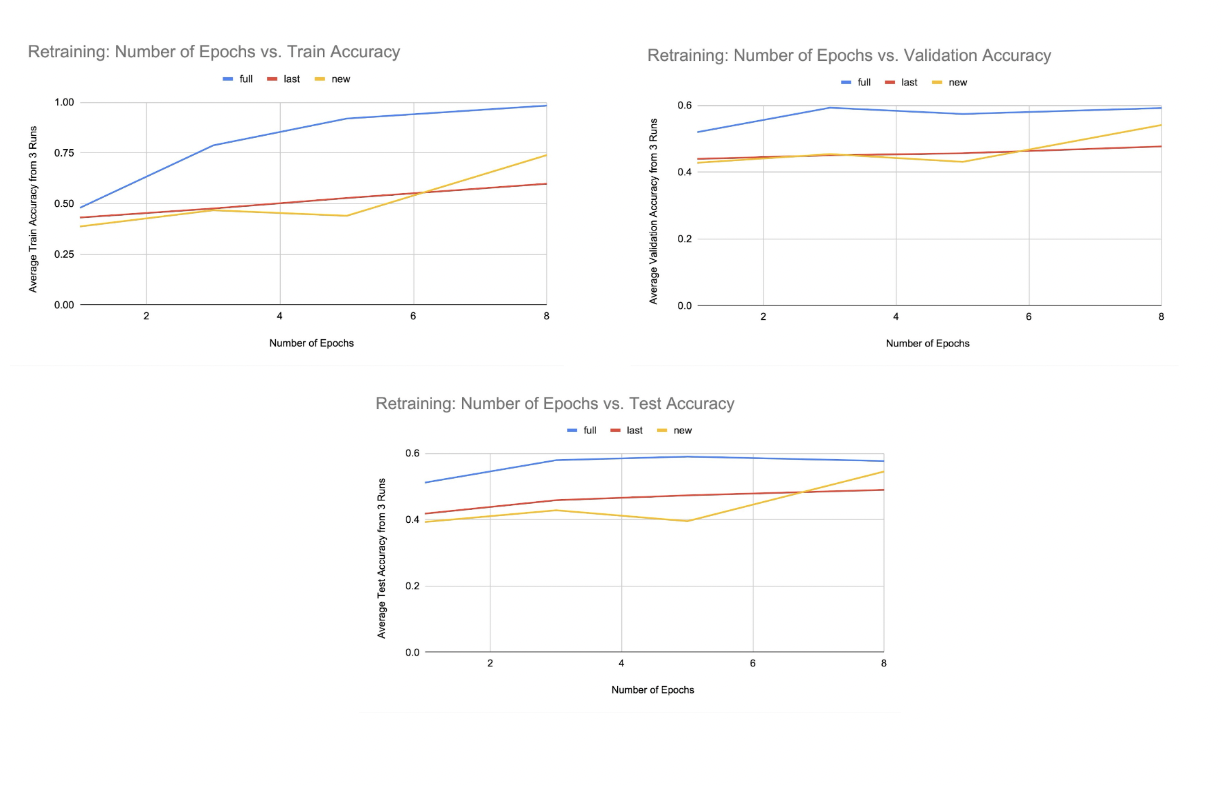
For retraining, on average, full had both the highest test accuracy and train accuracy for all num_epochs, last was in second place for both test accuracy and train accuracy for num_epochs=1, 3, and 5, and new was in second place for both test accuracy and train accuracy for num_epochs=8, which suggests that you can get better accuracy with pre-training (especially type=full) but the difference might become smaller as you increase the number of epochs. It was determined that by pretraining a language model to classify emojis that correspond to tweets, that model can have increased accuracy for other language tasks, such as classifying the emotion expressed in tweets. In the future, we could improve our accuracy by implementing the chain-thaw method described in the paper we replicated, which is a new transfer learning technique where each layer is trained separately. We could also increase our set of emojis to > 20 to further increase the performance of our model.
Challenges
We have encountered challenges with slow training. Although the emoji dataset we are using is much smaller than the one used in the original paper, it still has 45,000 training examples and our model architecture has 2 BiLSTMs. We are using smaller layers to try to train in a reasonable amount of time. The slow training also makes hyperparameter tuning difficult as it takes a long time to get through an epoch.
Reflection
How do you feel your project ultimately turned out? How did you do relative to your base/target/stretch goals?
- We were able to complete our base goal of preprocessing the emoji dataset and implementing the DeepMoji architecture as well as our target goal of retraining our DeepMoji model for one new task (the emotion dataset) with simple retraining methods. While we were unable to implement the chain-thaw method from the paper (our stretch goal) due to time constraints, we were still able to observe interesting results.
Did your model work out the way you expected it to?
- We were able to get better accuracy on the emotion dataset with pretraining on the emoji dataset, which is what we expected based on the original paper.
How did your approach change over time? What kind of pivots did you make, if any? Would you have done differently if you could do your project over again?
- Our approach evolved a bit over the progression of the project. Initially, we intended to train the model over a larger number of epochs and be more involved in tuning the hyperparameters in order to achieve higher accuracy. However, after our initial implementation, our results showed that after a certain point, the model started overfitting tremendously. This observation led us to implement an early stopping strategy. This was a significant pivot from our initial strategy but proved beneficial in preventing overfitting. Given more resources or time, we would experiment with different combinations of hyperparameters to optimize our model's learning process.
What do you think you can further improve on if you had more time?
- If we had more time, we would try implementing the chain-thaw method and spend more time experimenting with hyperparameters such as the layer sizes and vocab sizes.
What are your biggest takeaways from this project/what did you learn?
- The biggest takeaway from this project was the power of transfer learning and how you can leverage pretrained models for new tasks.

Log in or sign up for Devpost to join the conversation.