-
-

Telegram Bot
-
Website
Inspiration
The inspiration behind this project was to contribute towards the noble initiative of Ekatra by Vruksh Ecosystem Foundation. We understand that in both urban and rural schools, there is a significant digital divide. We are also awared that according to a recent survey, over 75 percent of students were impacted by the lockdown because they found it difficult to study online; over 80 percent of students said they need assistance transitioning from offline to online; and over 25 percent said they require proper training to pursue education online. Ekatra addresses this issue by providing an Integrated Education Platform for Under-Served Learners. Students can now learn over text & audio medium without the need for a smartphone. We strived to come up with solutions that could make this tool more efficient and sustainable. Real life implications of this project will help in more feasible transaction of learning material and help for solving the global education crisis.
What it does
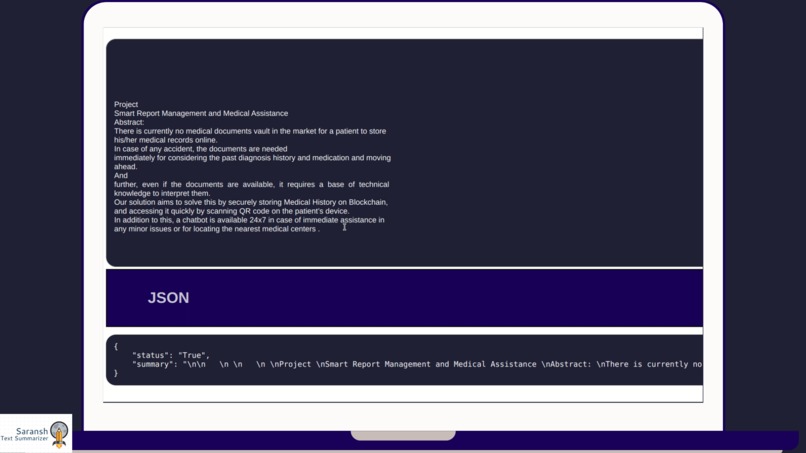
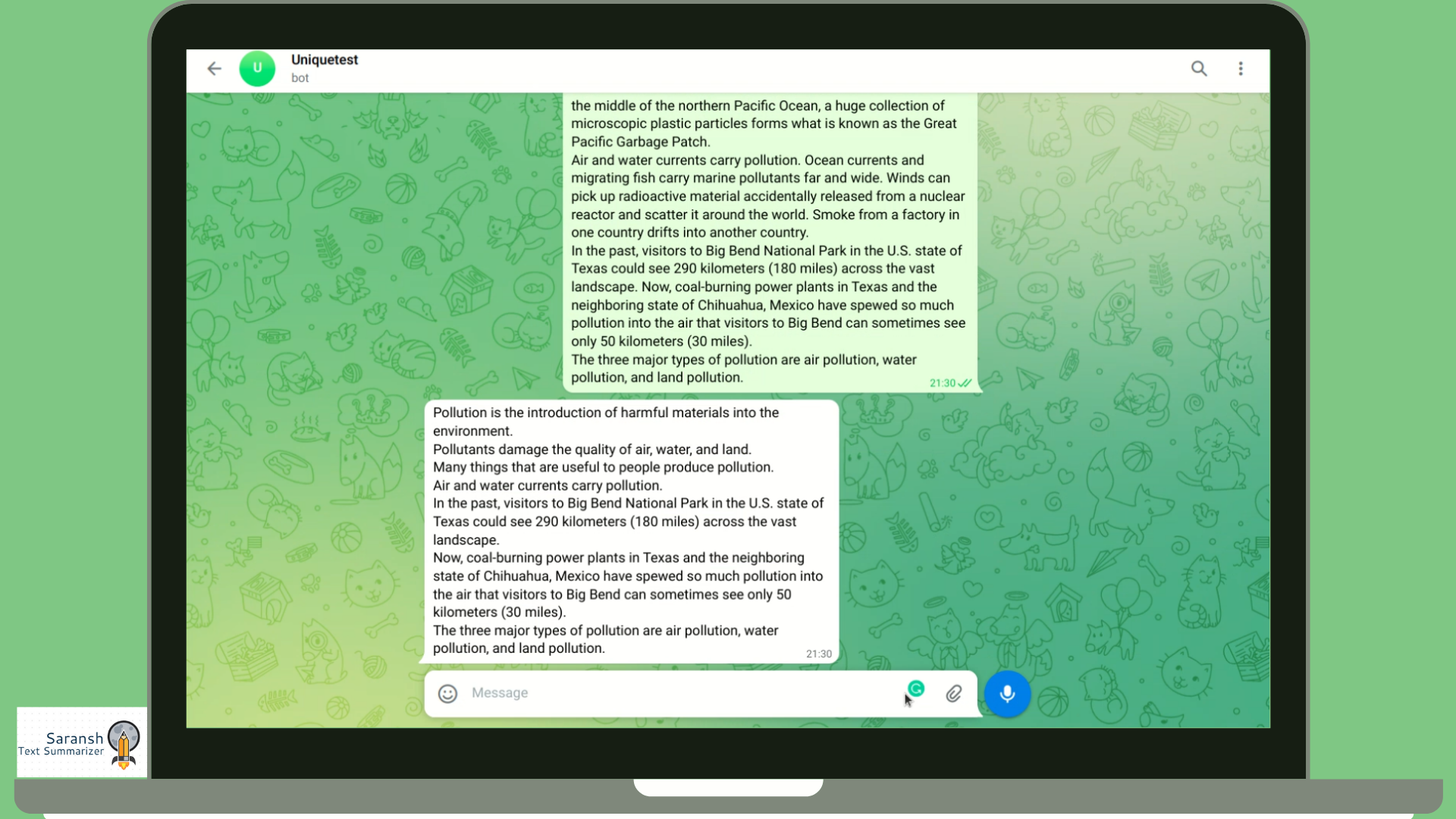
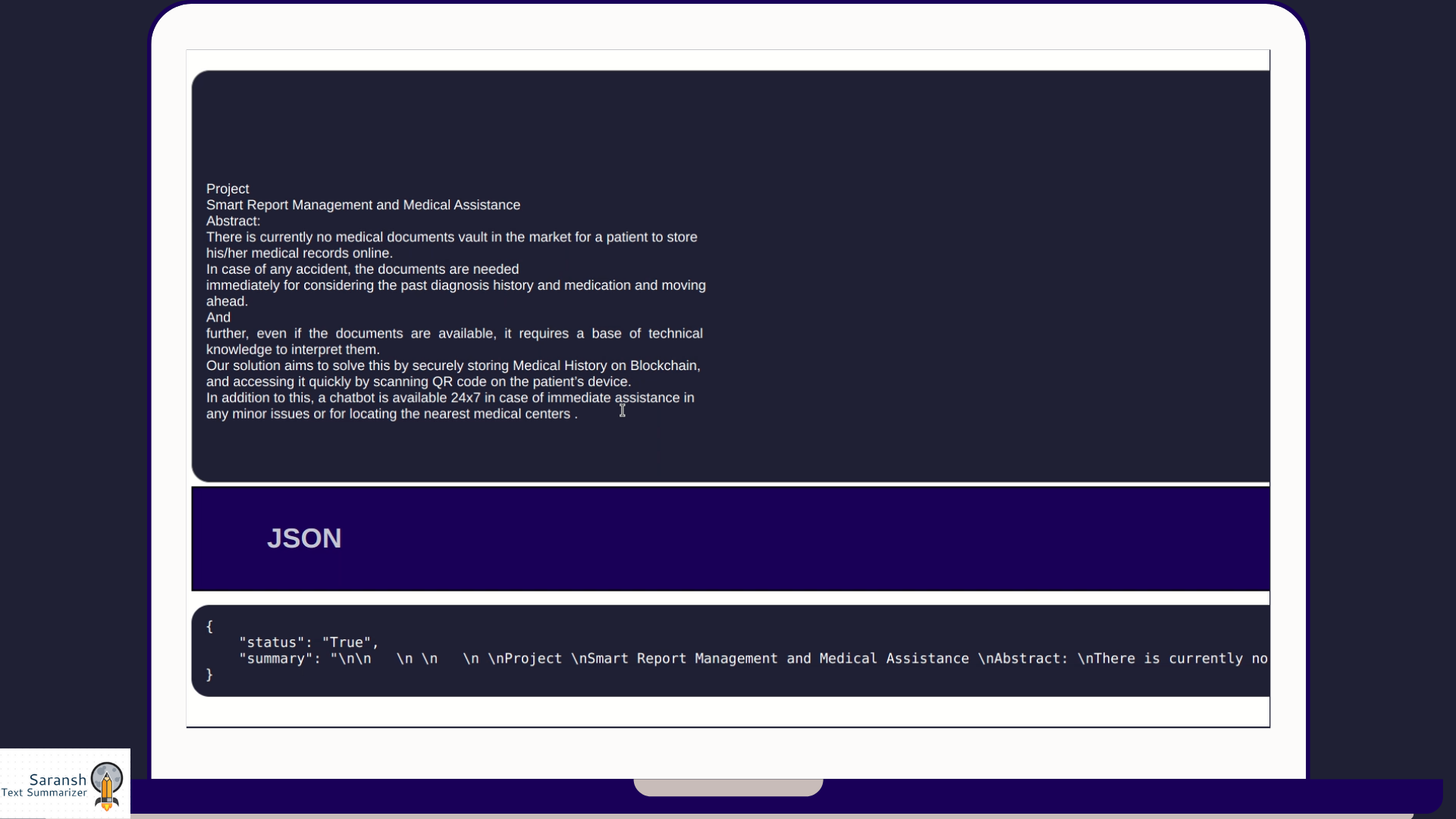
It is a highly efficient tool to produce a concise summarized text for any pdf document or text data. We created a python notebook that cleans the data up and uses a simple natural language procedure to produce a highly concise summary of the text data provided. Our tool Saransh is able to not only work on manually entered text but also on pdf documents that the user can choose to provide. Saransh is integrated both with a web interface and a Telegram bot to provide the best user experience.
How we built it
We used advanced python for the Summarizer and released it as a web interface, essentially applying Natural Language Processing techniques to Machine Learning. It is simple to understand. The basic idea is to count the frequency of the words occurring on the text and assume that highest occurring words are important given the threshold of occurrence and based upon it, summarize the text. This method treats phrases as ordered sequences, and words inside sentences as ordered sequences. It consists of four basic steps:
- Word weighting
- Sentence weighting
- Choosing all sentences that exceed a specific weight threshold
- Rearranging the sentences in the order they appear in the original article
The weighting method is based on frequency. The TF-IDF (term frequency – inverted document frequency) technique is used to assign a weight to each word/phrase. The weight of a term is equal to the term frequency multiplied by the inverse of document frequency.
The number of times a word appears in a document is known as term frequency. The inverted document frequency is 1 divided by the number of documents in which the words appear.
In addition, the score takes into account factors such as the word's position, the syntactic structure of the sentence in which it appears, and the existence of the term in the title. Each sentence is given a weight equal to the total of the words' weights. After all of the sentences have been weighted, they are sorted by weight in descending order. The weight of a sentence that can be used in a summary is set to a specified threshold, and then the sentences are filtered. The filtered sentences are reassembled in the document's original order. This is a statistical method that solely relies on the story's word level content. This method entails term preprocessing such as deleting stop words, normalizing terms, and substituting synonyms, among other things.
We also tried using the advanced GPT3 model and made a separate implementation for the same.
The Generative Pre-trained Transformer 3 (GPT-3) (stylized GPT-3) is a deep learning-based autoregressive language model that produces human-like text. It is the GPT-n series' third-generation language prediction model (and the successor to GPT-2) developed by OpenAI, a San Francisco-based artificial intelligence research group. GPT-3 has a total capacity of 175 billion machine learning parameters in its full edition. GPT-3 is part of a trend in natural language processing (NLP) systems using pre-trained language representations, which was announced in May 2020 and was in beta testing as of July 2020. As a beta, it's open to the public, and API keys can be generated via their website.
We have also made a Telegram Bot that is combined with the summarizer tool to provide the best user experience.
Challenges we ran into
It was challenging to rescale and reorient the data in a format that would make the modelling less cumbersome while also preserving the meaningful insights from the data during summarization. Applying different approaches of extraction and abstraction and choosing the best algorithms was also a challenge.
What we learned
We learned about advanced technologies that are currently in the trend and are used for Text summarization like the GPT3.
What's next for Text Summarizer
We look forward to integrate this tool with Ekatra's learning platform and make it efficient for the learners to grab the crux of the text and boost their learning. The integration of our developed tool with Ekatra that combines the power of Text (SMS & Whatsapp), Audio & Video communication will help to deliver learning at scale. We are motivated to contribute towards finding innovative and efficient solution for the global crisis of education particulary for children in remote areas lacking needful facilities.



Log in or sign up for Devpost to join the conversation.