-
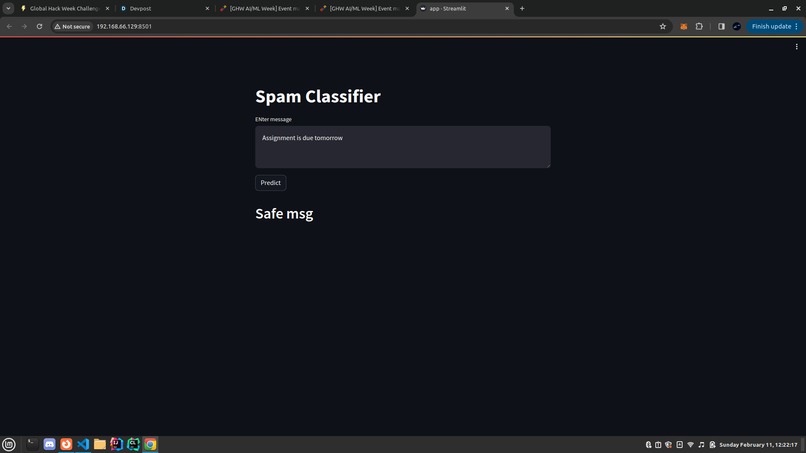
Safe
-
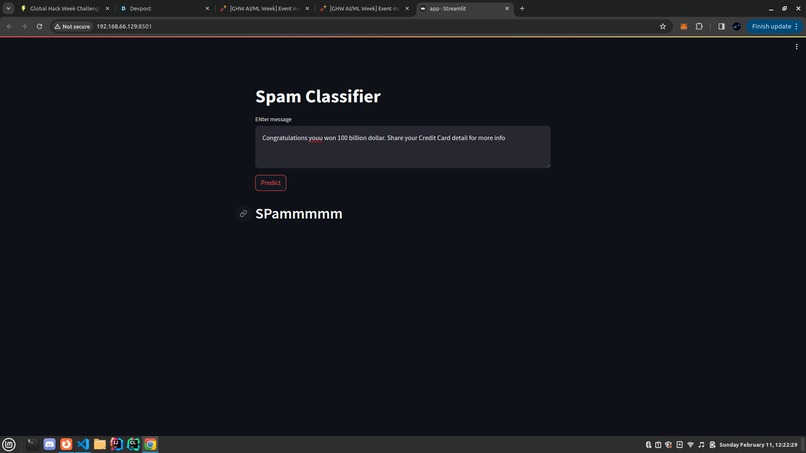
Spam

Inspiration
The inspiration behind our project stems from the growing concern of spam messages inundating communication channels. We aimed to develop a robust solution leveraging the Multi Naive Bayes algorithm to accurately classify messages as spam or not, thereby empowering users to filter out unwanted content effectively.
What it does
Our Streamlit message spam classifier built with Multi Naive Bayes efficiently distinguishes between spam and legitimate messages. Users can input text messages, and our model swiftly processes them, providing a classification result indicating whether the message is spam or not.
How we built it
We constructed our solution using the Streamlit framework for the user interface and implemented the Multi Naive Bayes algorithm for message classification. The process involved data preprocessing, feature extraction, model training, and deployment. We utilized Python libraries such as Pandas, NumPy, and Scikit-learn for data manipulation, modeling, and evaluation.
Challenges we ran into
One of the primary challenges we encountered was obtaining and preprocessing a diverse dataset representative of real-world message data. Additionally, optimizing the model's hyperparameters and ensuring its scalability posed significant hurdles. Moreover, integrating the model into a user-friendly Streamlit interface while maintaining performance efficiency required careful consideration.
Accomplishments that we're proud of
We're proud to have developed a functional message spam classifier that demonstrates high accuracy in distinguishing between spam and legitimate messages. Additionally, creating an intuitive user interface with Streamlit that enhances accessibility for users is a significant achievement. Moreover, overcoming various technical challenges and optimizing the model's performance showcases our team's dedication and expertise.
What we learned
Throughout the project, we gained valuable insights into text classification techniques, particularly the Multi Naive Bayes algorithm. We also deepened our understanding of Streamlit for building interactive web applications and learned effective strategies for dataset preprocessing, model evaluation, and deployment. Furthermore, collaborating as a team enabled us to enhance our communication and problem-solving skills.
What's next for Text Spam Detection
In the future, we aim to further enhance the accuracy and efficiency of our spam detection system by exploring advanced text classification algorithms and incorporating more sophisticated features. Additionally, we plan to implement real-time monitoring capabilities to adapt to evolving spamming techniques. Furthermore, integrating user feedback mechanisms will allow us to continuously improve the system's performance and usability.
Built With
- python
- sklearn
- streamlit

Log in or sign up for Devpost to join the conversation.