-
-
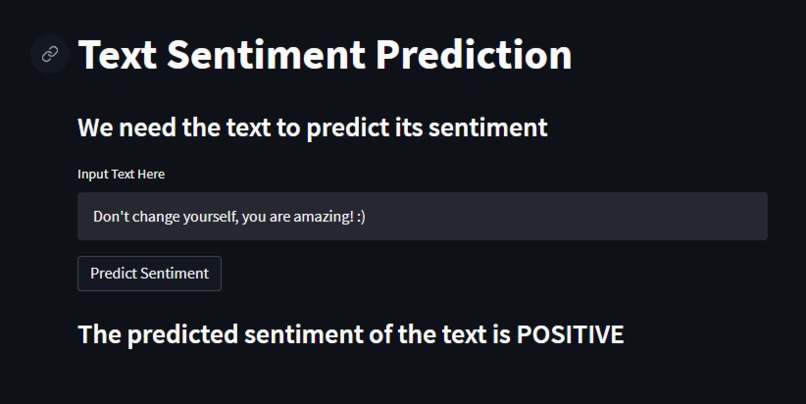
positive prediction :)
Inspiration
Social media has become prominent within our generation and will continue to grow and grow. However, this leads to many other effects on the users. Cyberbullying and other forms of harassment is important issue that needs to be addressed. From this, we wanted to use data to create a model that can help determine positive and negative messages in fights of countering negativity online.
What it does
Our project allows users to use our trained machine learning model by inputting a text and getting a predicted sentiment (POSITIVE or NEGATIVE). Users are able to report bugs, and change settings of the User-Interface as they wish with the integration of Streamlit.
How we built it
We trained the model using a dataset of Amazon reviews. Using the sci-kit-learn library in Python, we used the SVM algorithm to create our model using a technique called bag-of-words vectorization which associates certain words to POSITIVE or NEGATIVE. We then implemented our model into Streamlit to create a user-interface for users to input their own text and use our trained model to predict its sentiment.
Challenges we ran into
Since it was our first time creating a machine learning-based model, there were many times when we were stuck on a problem. One of these was implementing the SVM model that we used to predict the sentiments. To combat this issue, we were able to find help on the official scikit-learn website that provided a lot of useful information that helped us create the model.
After implementing the model, we noticed that the accuracy was significantly higher for predicting positive sentiments as opposed to negative sentiments. After some debugging and testing, we realized the root of this issue, which was our data sample size. Since the dataset of amazon reviews that we used contained significantly higher positive reviews than negative reviews, we obtained a larger dataset and shrunk it to contain approximately the same number of positive and negative reviews, which greatly increased the accuracy of our model.
Accomplishments that we're proud of
We were able to create an effective model with an 80% F1 score. We are also very proud that we learned how to implement python code into a user-interface (with Streamlit).
What we learned
We learned how to use real-world data to implement a model that is able to make predictions based on our dataset. We were able to learn how to use libraries such as sci-kit learn. We also learned the importance of model testing and the different types. Especially as beginners to the realm of data science and code, this is a really good beginner project as it allowed us to have a great idea of what it's like to apply code for the real world.
What's next for Text Sentiment Predictor
A possible improvement for this project would be to implement a neutral sentiment, which would tell us if the text is neutral. We could implement this by categorizing the amazon reviews into 3 portions, where 3 stars may represent words with a neutral sentiment. Another approach to this may be to analyze the ratio of positive to negative words within a statement, and assign it neutral if the ratio is within a certain appropriate range. Another improvement would be to integrate an option that provides suggestions on how to make a text more positive if it was given a negative sentiment. We could do this by highlighting the specific words within the text that are associated with negative sentiments and providing alternatives for those words.
Built With
- python
- scikit-learn
- streamlit

Log in or sign up for Devpost to join the conversation.