-
-
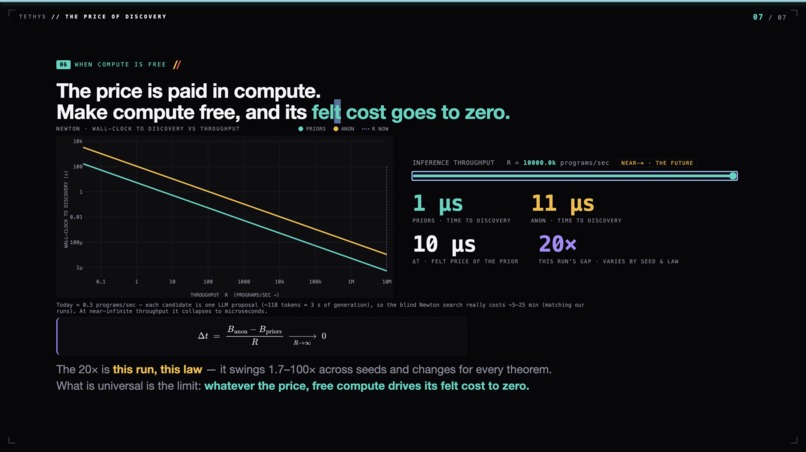
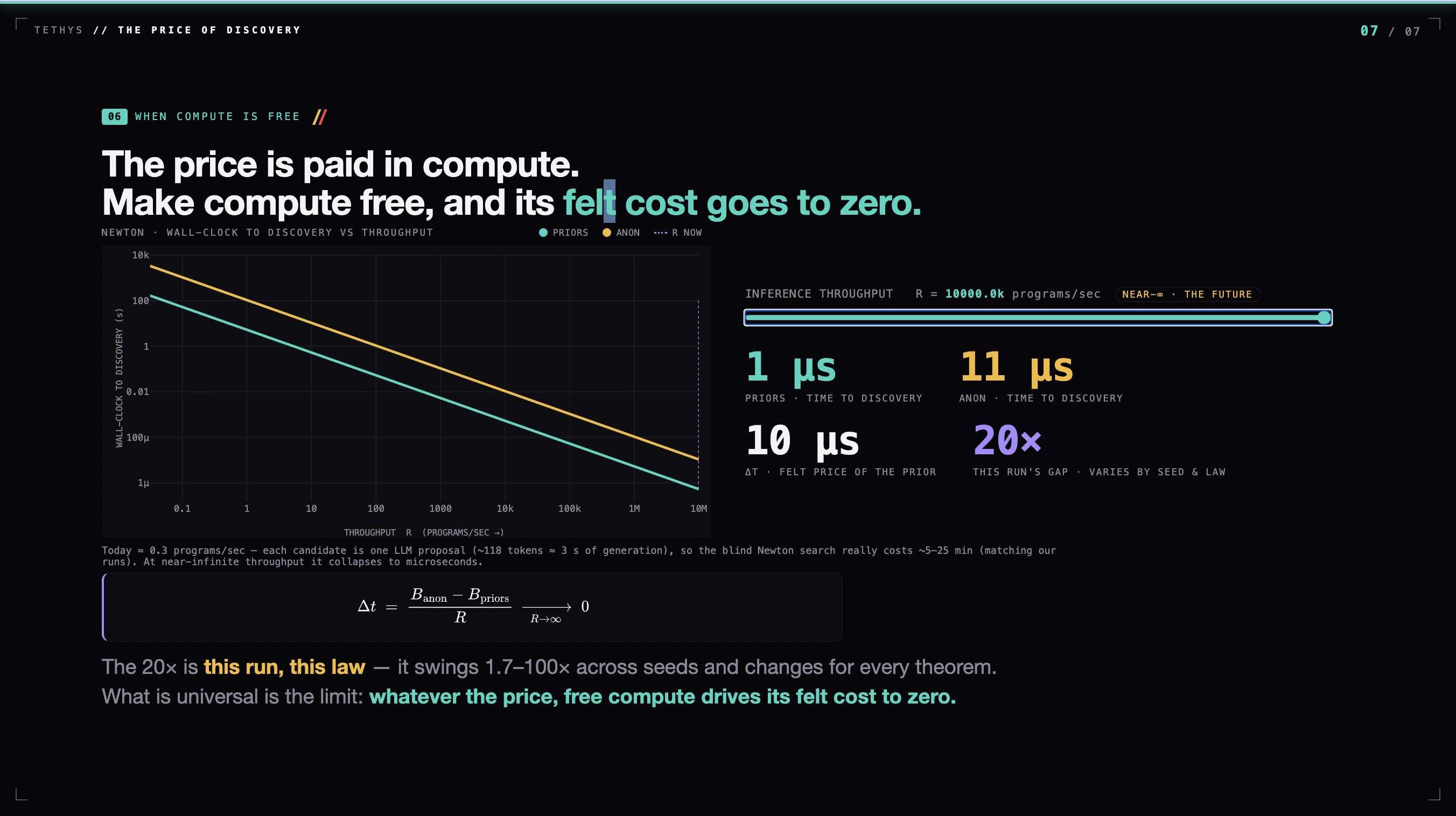
As inference throughput rises, speed of discovery scales drastically
-

Tsiolkovsky's rocket equation, 1903, between deduced by the engine successfully
-
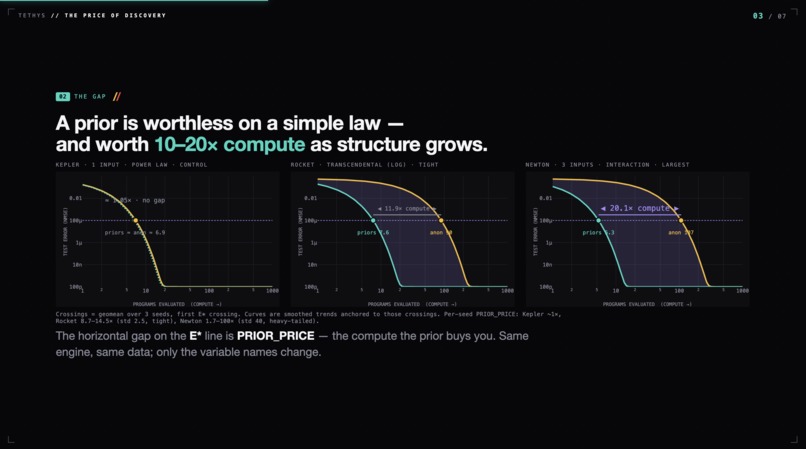
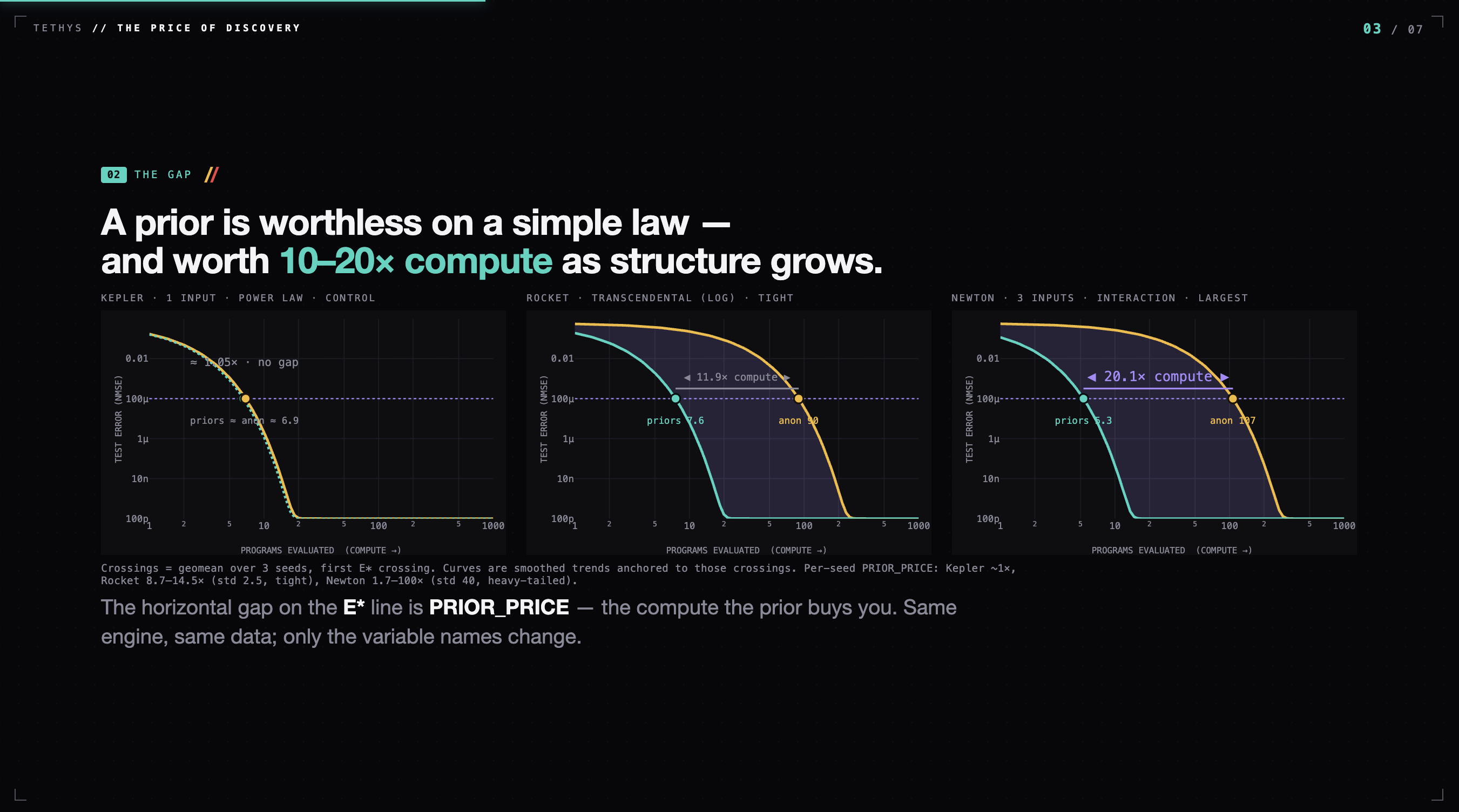
Visualize the Gap - Between Agent with Prior Knowledge, and Rediscovery Agent with no hint
-

Engineering Structure


In the limit of infinite compute, what is knowledge worth?
If compute were free, you would never need to know anything — you could simply compute your way to any answer. That is the world inference hardware is racing toward. So we asked a measurable question: how much compute does a piece of knowledge actually replace?
We answer it by putting a price tag on discovery itself — denominated not in dollars, but in inference.
What inspired us
Discovery is a search over explanations. A scientist with the right prior leaps straight to the answer; a scientist without one has to grind through the space of possibilities. Those feel like different activities — but in the limit, they are the same activity at different compute budgets. Knowledge is just pre-paid search.
That intuition has a precise home in algorithmic information theory. The ideal predictor is Solomonoff induction — sum over every program that reproduces the data, weighted by simplicity:
$$ M(x) = !!\sum_{p\,:\,U(p)=x}!! 2^{-|p|} $$
It is uncomputable. Its tractable shadow is Levin search, which prices description length and compute in a single quantity:
$$ Kt(x) = \min_{p}\big(\,|p| + \log_2 t(p)\,\big) $$
Here $\log_2 t(p)$ is inference compute. As compute scales, that term goes free — and you converge to ranking hypotheses by simplicity alone: Solomonoff's ideal. Infinite compute is not a footnote to our project; it is the limit our measurement points at. We built a tractable shadow of Solomonoff/Levin, and measured the price of the prior inside it.
What we built — Tethys
Tethys is an equation-discovery engine: an LLM-driven evolutionary search over programs (in the lineage of FunSearch / LLM-SR), wrapped in a controlled experiment that measures one thing precisely.
The experiment. We take a known physical law, generate data, and run the same engine under two conditions:
priors— variables keep their semantic names (mass_1,distance,exhaust_velocity). The LLM's pretrained prior is live.anon— every name is stripped toSensor_A,Sensor_B. The prior is gone; the engine must search from raw numbers alone.
The numbers fed to both conditions are bit-for-bit identical — only the
names differ. A unit test (test_auditability) asserts the two prompts differ
only by names. So any gap in compute is attributable to the prior, and
nothing else.
The metric. For each condition we measure $B$, the number of programs evaluated to reach a target accuracy $E^* = 10^{-4}$. The price of the prior is their ratio:
$$ \text{PRIOR_PRICE} = \frac{B_{\text{anon}}}{B_{\text{priors}}} $$
The result. Across three function classes, with $n=3$ seeds each:
| Law | Structure | PRIOR_PRICE (geomean) |
|---|---|---|
| Kepler | power law | ~1.05× (control) |
| Tsiolkovsky (rocket) | transcendental, $\ln$ | ~12× (tight, std 2.5) |
| Newton | 3-input interaction | ~20× (heavy-tailed, std 40) |
Kepler is the control: a power law is the universal default a blind search tries first, so the prior buys almost nothing (~1×). This proves the method doesn't fabricate gaps — it distinguishes useful priors from useless ones.
The headline: stripped of every semantic clue, the engine needs ~12–20× more inference to rediscover physical law — and it does rediscover it. Blind to the word "rocket," from raw numbers alone, the engine writes:
$$ \Delta v = v_e \cdot \ln!\left(\frac{m_0}{m_1}\right) $$
The Tsiolkovsky rocket equation. The same equation NASA used to leave Earth — recovered with no physics, no names, just compute.
What we learned
The prior buys three things, not one. Speed (fewer programs), tokens (the blind search burns more generation per step — the token-priced gap is even larger, ~15–27×), and — most subtly — certainty. With priors, every seed converges in a handful of steps. Without them, discovery/rediscovert is a gamble: Newton's blind search ranged from 1.7× to 100× across seeds. The prior doesn't just make discovery cheaper — it makes it reproducible.
A blind search finds the truth the long way around. On one rocket seed, the anonymous engine never wrote a logarithm — it rediscovered the power-series approximation of one, $v_e\cdot(\text{ratio}^{\varepsilon}-1) \approx v_e\ln(\text{ratio})$, converging to the same law through a different door. Same truth, more compute.
How we built it
A six-module engine, shipped test-gated — every module behind a passing acceptance test before the next was written, not vibe-coded in one shot:
laws/datasets— ground-truth laws rendered into the two conditions, bit-identical numbers.proposer— the LLM prompt builder; the only place the prior enters.sandbox— process-isolated execution. Candidate code can infinite-loop; threads can't be killed mid-spin (the GIL), so we use aProcessPoolExecutorwith hard timeouts to force-kill runaway searches.evaluator— fits constants viacurve_fit, scores on held-out data with NMSE, and selects lexicographically: among equally-accurate programs, the shortest wins (Occam, by AST node count).search— the evolutionary loop: propose → execute → score → survivors become exemplars, with a temperature schedule for diversity.ablation_experiment— sweeps both conditions × seeds, computes PRIOR_PRICE (program- and token-denominated), and plots the gap.
The model under test was an open instruct model (Qwen3-235B) served on Prime Intellect — chosen non-reasoning on purpose, so program count and token count stay proportional and the price is denominated cleanly in inference.
What's ours, and what we stand on
The engine is not our contribution — and we want to be precise about that. LLM-driven evolutionary program searc h over executable hypotheses is the approach pioneered by FunSearch (DeepMind) and LLM-SR; our proposer → sandbox → evaluator → survivors loop is squarely in that lineage, and we make no claim to a novel search algorithm.
Our contribution is the experiment built on top of it:
- The ablation — running the identical engine on bit-identical data under
priorsvsanon, isolating prior knowledge as the only variable, with a test that proves it. - The metric —
PRIOR_PRICE$= B_{\text{anon}}/B_{\text{priors}}$, pricing knowledge in units of inference compute. - The framing — anchoring that price to Solomonoff/Levin, where infinite compute is the limit that drives it to zero.
Put differently: a pretrained LLM is a learned, highly non-uniform prior over program space. LLM-SR uses that prior to discover. We use the same machinery to measure what the prior is worth — and what it costs to do without it. The search is borrowed; the price tag is new.
You will be able to see all the datasets & inference logs in the results/ directory in our Github Repo. You can also open demo.html on your computer (which uses the same demo as our video) and see how the plot & price gap works out.
Challenges we faced
The capability trap. Our first transcendental law stalled completely —
priors filled the program pool with zero valid candidates. The cause: the
model correctly wrote math.log(...), but forgot to import math, so every
log candidate threw NameError. Ironically, the stronger the prior, the
more candidates used logs, the harder priors failed. We fixed it
engine-side (preset the exec namespace with math/log/ln) rather than via
prompt — models forget imports; the namespace doesn't. Crucially, the fix lives
in the scoring layer, which is condition-blind, so it stays fair to both
conditions.
Keeping the ablation clean. The entire result rests on the two conditions differing by nothing but names. Every change — adding transcendental capability, presetting the namespace — had to be condition-invariant, verified by the auditability test. A single leak and the 20× means nothing.
Discovery is heavy-tailed. LLM sampling is non-deterministic; the same seed converges in 82 programs one run and 600 the next. We learned to report the geometric mean (a ratio's natural center, robust to the lucky 100× tail) and honest ranges, never a single hero number.
The overnight-safe engine. An unattended sweep can't die on one stalled API call. An early version hung silently at 0% CPU on a network stall with no timeout; we added hard per-request timeouts and a failure-visible progress log, so a multi-hour run degrades gracefully instead of freezing.
Why it matters
We put a price on knowing. Right now, that price is ~12–20× compute. But the quantity that sets it — Levin's $\log_2 t(p)$ — is exactly what cheaper, faster inference drives toward zero. As compute scales, the price of a prior falls to zero, and discovery becomes something you can simply buy. That is the world infinite inference is building. We measured the exchange rate.

Log in or sign up for Devpost to join the conversation.