-
-

Logo de nosso grupo de estudo (GREMLING) da Universidade Federal de Itajubá (UNIFEI).
-

Resultados da primeira parte do projeto.
-

Resultados da segunda parte do projeto.
-
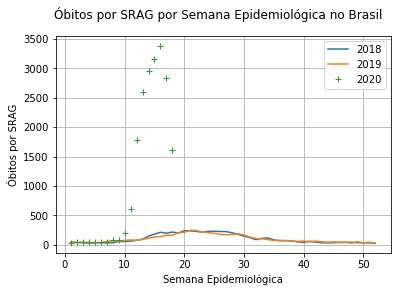
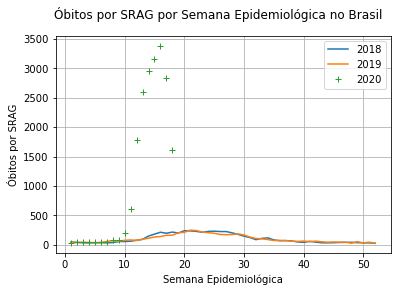
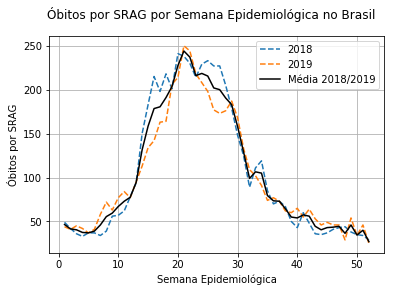
Óbitos por SRAG em 2018, 2019 e 2020.
-
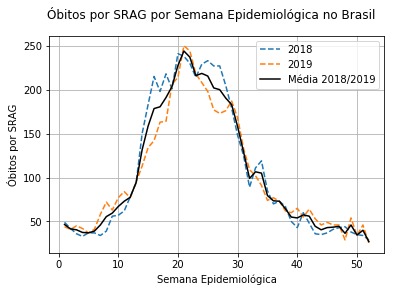
Curva média dos óbitos por SRAG em 2018/2019.
-
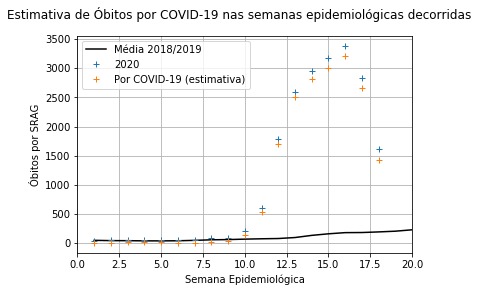
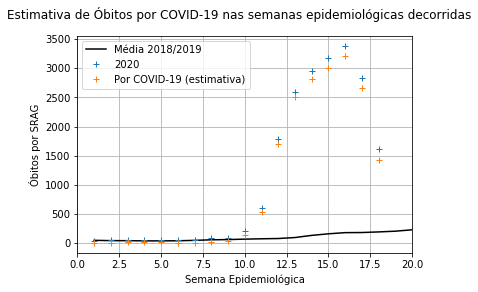
Estimativa dos óbitos por SRAG decorrentes do COVID-19 em 2020.



Quem somos:
Integrantes do grupo de estudos GREMLING (Grupo de Estudos em Machine Learning) da UNIFEI (Universidade Federal de Itajubá). Atualmente, somos graduandos em Bacharelado em Física com experiência em Data Science e Deep Learning aplicado em nossas respectivas pesquisas ("Solução de Equações Diferenciais Parciais Não Lineares com Deep Learning aplicadas à Relatividade Geral", e, "Aprendizado de Máquina na Redução de Dados Astronômicos.").
Proposta:
Visamos trabalhar na solução do desafio "D051 - IA e Ciência de Dados para Apoio à Decisão Clínica". Constituído de duas partes: Construir uma ferramenta computacional de análise de dados capaz de estimar o número de óbitos subnotificados decorrentes da COVID-19, e, construir uma ferramenta baseada em Inteligência Artificial (Deep Learning) para analisar radiografias e tomografias a fim de auxiliar no diagnóstico médico.
O que faz o projeto:
(OBS: É extremamente necessário que os repositórios do GitHub sejam consultados, já que toda a metodologia aplicada está lá contida, assim como os resultados obtidos.)
Parte 1: Um script simples capaz de trabalhar com bancos de dados provenientes de fontes confiáveis a fim de aplicar conceitos básicos de datascience, probabilidade e estatística para estimar a quantidade de casos de óbito por SRAG (Síndrome Respiratória Aguda) causados por COVID-19 que não foram catalogados como tal, estimando, assim, a porcentagem de casos de morte subnotificadas no Brasil.
Parte 2: Foi treinado um modelo utilizando ferramentas sofisticadas de Machine Learning para ser capaz de analisar imagens de radiografias de pulmões e tirar conclusões para auxiliar no diagnostico clínico. Sendo capaz de analisar (até o momento) um pulmão saudável de um pulmão com pneumonia, e, um pulmão saudável de um pulmão infectado com COVID-19.
Como foi construído:
Parte 1: Um script feito em Python 3.6 utilizando basicamente a biblioteca 'pandas' para trabalhar com datasets no formato CSV. Assim como utilizando outras bibliotecas padrão da linguagem.
Parte 2: Um script sofisticado utilizando os frameworks Tensorflow e Keras para treinar um modelo de reconhecimento de imagem utilizando dois datasets distintos, a fim de que a IA consiga diferenciar pulmões saudáveis de infectados pelas radiografias dos pulmões.
Realizações e conclusões:
Parte 1: Conseguimos chegar à conclusão de que há 9570 óbitos por SRAG causadas por COVID-19 que não foram catalogadas como tal, consistindo, então, em 52,82% dos casos de morte por SRAG registradas.
Parte 2: Conseguimos, com um dataset pequeno, obter a acurácia de 71% em diferenciar um pulmão saudável de um infectado, e com um dataset mais robusto, conseguimos chegar à 91% de acurácia.
Desafios e possíveis futuras implementações:
Parte 1: O modelo utilizado é muito simples. Poderíamos, com mais tempo disponível, criar e aplicar uma metodologia mais sofisticada que agregaria um grau maior de confiabilidade ao método. Como, por exemplo, utilizar dados de mais anos anteriores à pandemia, o que agregaria uma precisão maior à estimativa (foram utilizados dados dos anos 2018, 2019 e 2020, apenas).
Parte 2: Como não tivemos a nosso dispor nestes dias uma máquina de alto poder computacional, a eficácia dos modelos treinados ficou comprometida, assim como uma dificuldade em obter e trabalhar com datasets de radiografias em apenas um final de semana. Futuramente o modelo da Rede Neural assim como o método de treino poderia ser otimizado, o dataset poderia ser aumentado e mais bem trabalhado para auxiliar o treinamento da rede, e principalmente, termos a disposição uma máquina de alto poder computacional, para que possamos treinar a IA por uma grande quantidade de tempo de forma ininterrupta.





Log in or sign up for Devpost to join the conversation.