-
-
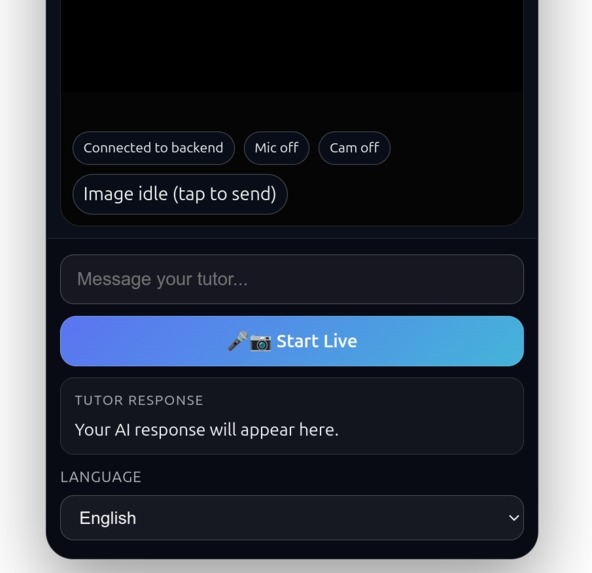
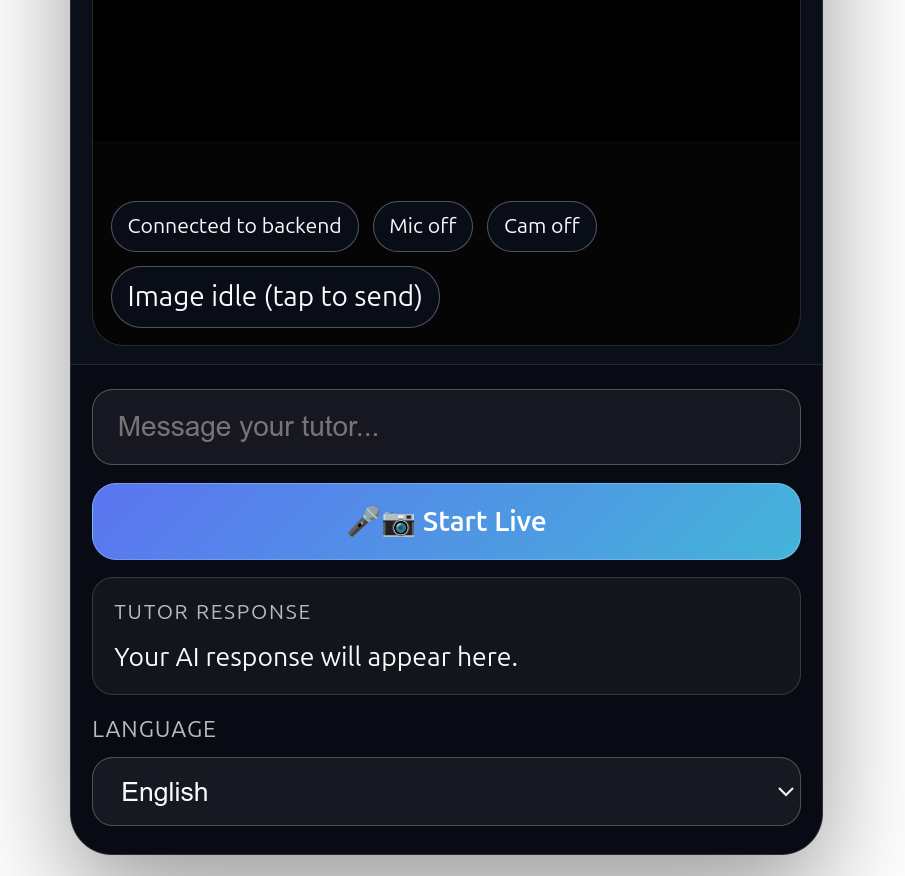
Gemini Live Tutor
-
Frontend
-

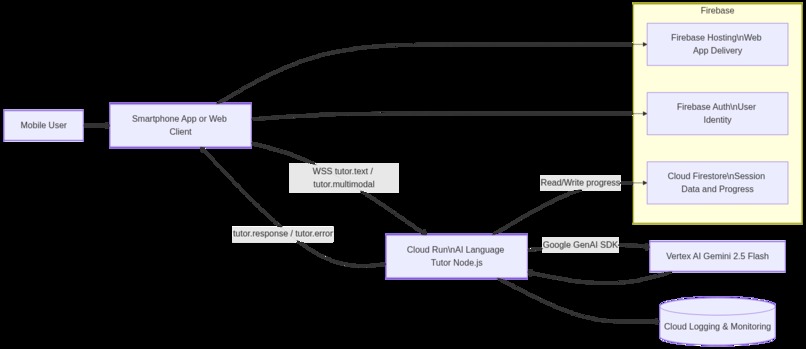
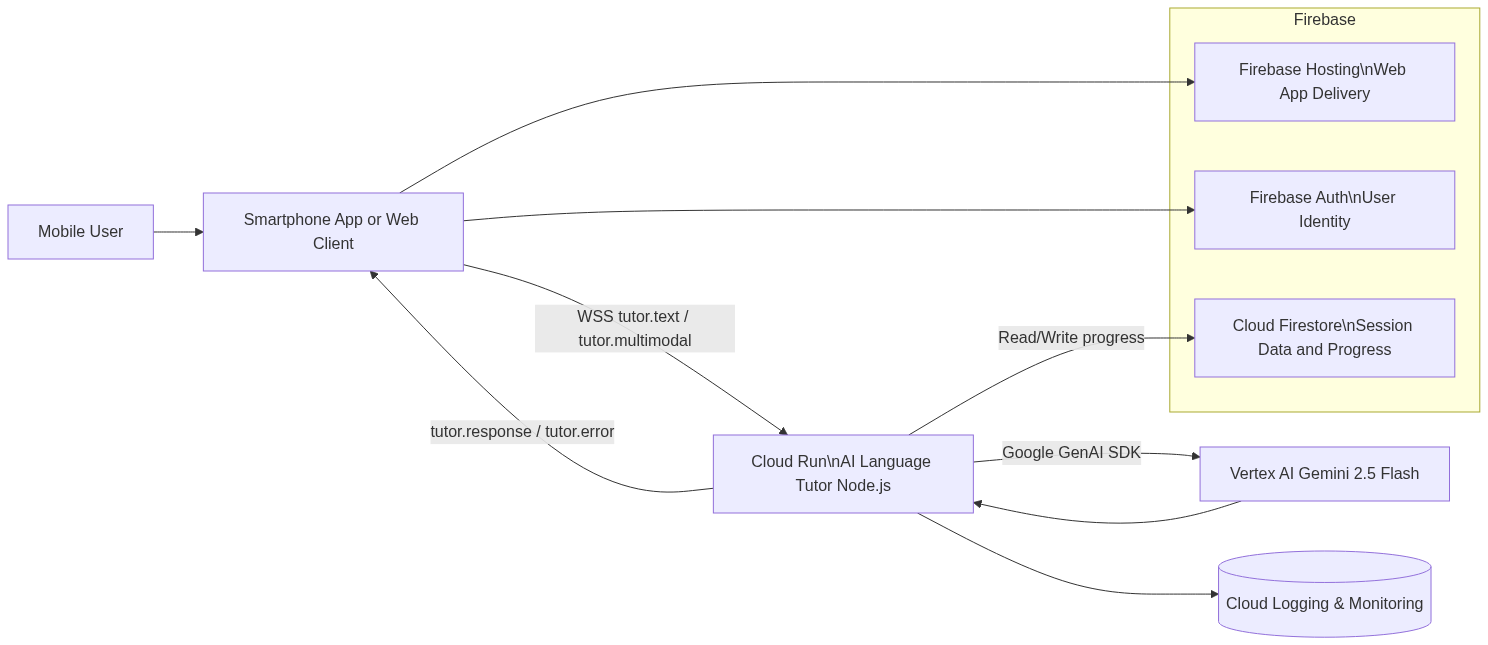
Backend

Gemini Live Tutor — Project Story
Inspiration
Language learning apps often feel artificial: flashcards, scripted dialogs, and no real context. I wanted to build something that feels like talking to a real tutor in daily life, directly from a phone.
The idea for Gemini Live Tutor was simple: let learners speak naturally, show the world around them, and get immediate feedback in their target language.
What it does
Gemini Live Tutor is a real-time, mobile-first AI language tutor.
- The user can type or speak a question.
- The app can capture camera context for visual prompts like "What is this?"
- The tutor responds in the selected language (English, Ukrainian, Spanish, German, French).
- Responses are shown as text and read aloud using speech synthesis.
- The experience is designed for fast conversational flow, not one-shot chat.
How we built it
| Layer | Technology |
|---|---|
| Frontend | React + Vite, optimized for mobile |
| Hosting | Firebase Hosting (HTTPS, global CDN) |
| Realtime channel | WebSocket /ws for low-latency messaging |
| Backend | Cloud Run — receives text/multimodal requests |
| AI | Vertex AI Gemini — language-aware multimodal responses |
Key implementation details:
- Microphone input via browser
SpeechRecognitionAPI with continuous listening mode. - Camera frames captured from a live
<video>element and sent as base64 JPEG. - Structured message protocol (
tutor.multimodal,tutor.response,tutor.error) over WebSocket. - CI/CD via GitHub Actions: preview deployments on pull requests, live deploy on merge to
main.
Challenges we ran into
- Mobile browser permissions — mic and camera require HTTPS and user gesture triggers; permission UX had to be clear and forgiving.
- Realtime reliability — handling WebSocket reconnect, status display, and mid-session errors gracefully.
- Multimodal consistency — balancing text-only and image+text requests without breaking conversation flow.
- Response formatting for TTS — stripping Markdown, headers, and code blocks so spoken output sounds natural.
- Deployment coordination — keeping
VITE_BACKEND_URLaligned across environments and CI secrets.
Accomplishments that we're proud of
- Built an end-to-end live tutoring flow from phone to model and back.
- Achieved real-time interaction with voice, text, and camera in a single interface.
- Deployed on fully managed GCP services: Firebase Hosting + Cloud Run + Vertex AI.
- Created a practical learning loop: see → ask → hear → repeat.
- Multi-language support with a simple UX that works for non-technical users.
What we learned
- Great AI demos are as much about UX and latency as model quality.
- Mobile web constraints (permissions, secure context, media APIs) strongly shape product design.
- WebSockets are powerful for conversational experiences, but connection state handling is critical.
- Multimodal prompts need clear structure to keep responses predictable and speech-friendly.
- Serverless + managed hosting (Cloud Run + Firebase) accelerates iteration for small teams.
What's next for Gemini Live Tutor
- Personalized memory — track user level, mistakes, and vocabulary progress across sessions.
- Session summaries — actionable practice tasks and spaced repetition after each conversation.
- Pronunciation coaching — phonetic-level feedback and scoring.
- Adaptive difficulty — responses that match the learner's current proficiency.
- Teacher / parent dashboard — progress analytics and session history.
- Offline resilience — graceful degradation for low-connectivity environments.
Built With
- actions
- babel
- eslint
- firebase
- github
- googlecloudrun
- hosting
- javascript
- react
- react-19
- vite
- websocket



Log in or sign up for Devpost to join the conversation.