

NOTE: Try it out link is real, but waiting for apple to enable private beta link, if you want to demo the real app during judging email me at kdavis2600@gmail.com with your Apple ID and I will add you to testflight where you can test immediately. Code at https://github.com/kdavis2600/elfie (set private due to the API keys)
Inspiration
We started from a simple clinical workflow problem: doctors lose time twice. First, they lose it during the visit because important details are buried inside long, messy conversations. Then they lose it again afterward because notes and supporting artifacts still have to be turned into something structured, reviewable, and shareable. Lab reports create a similar burden. Even when the information already exists, it often arrives as dense PDFs or phone photos that are hard to interpret quickly on a mobile device.
The Elfie track pushed us to build something practical instead of a generic medical chatbot. We wanted a mobile-first workflow that could fit into real care delivery, respect privacy constraints, and produce outputs a clinician could actually review and use. That is why Elfie Scribe evolved from an audio-transcription concept into a two-track product covering both challenge #1 and challenge #3: consultation documentation and lab analysis.
What it does
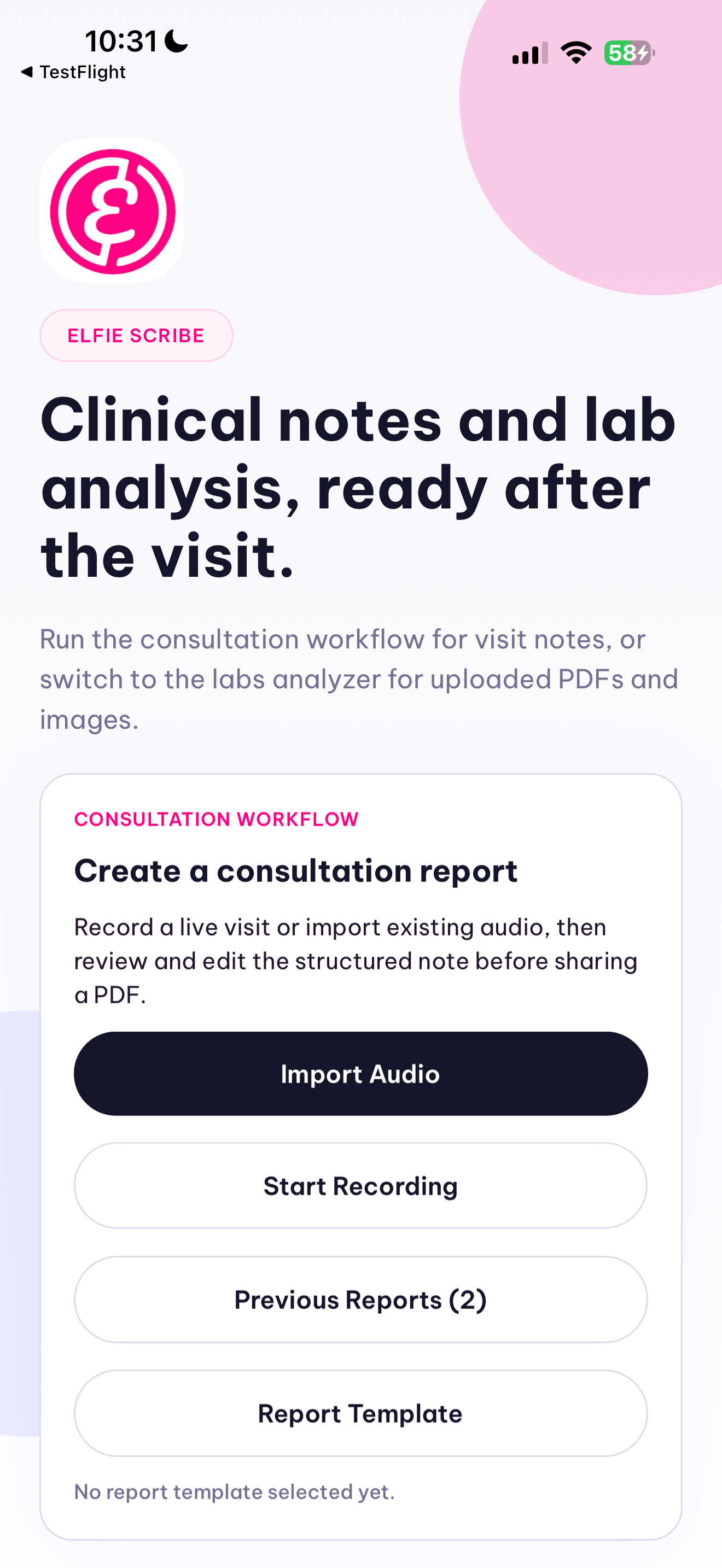
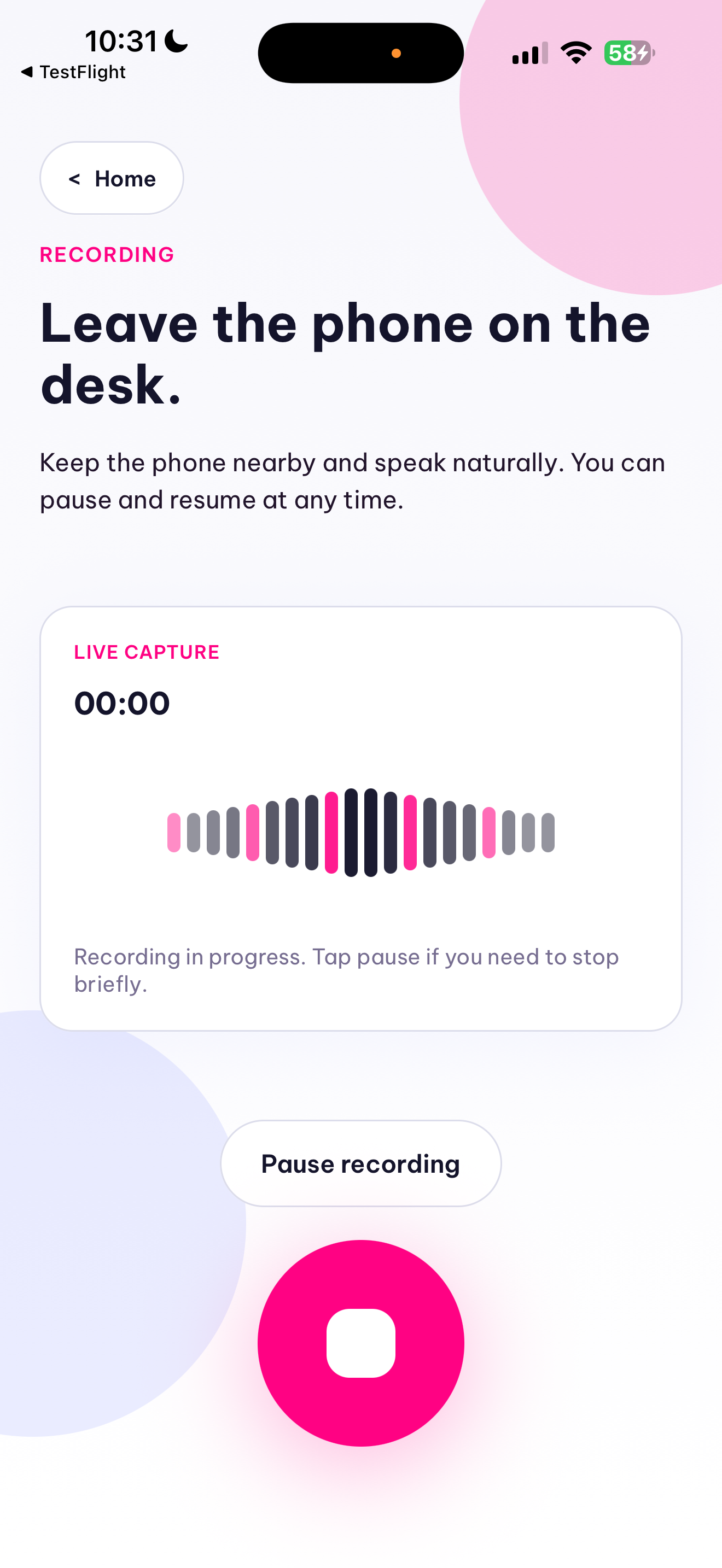
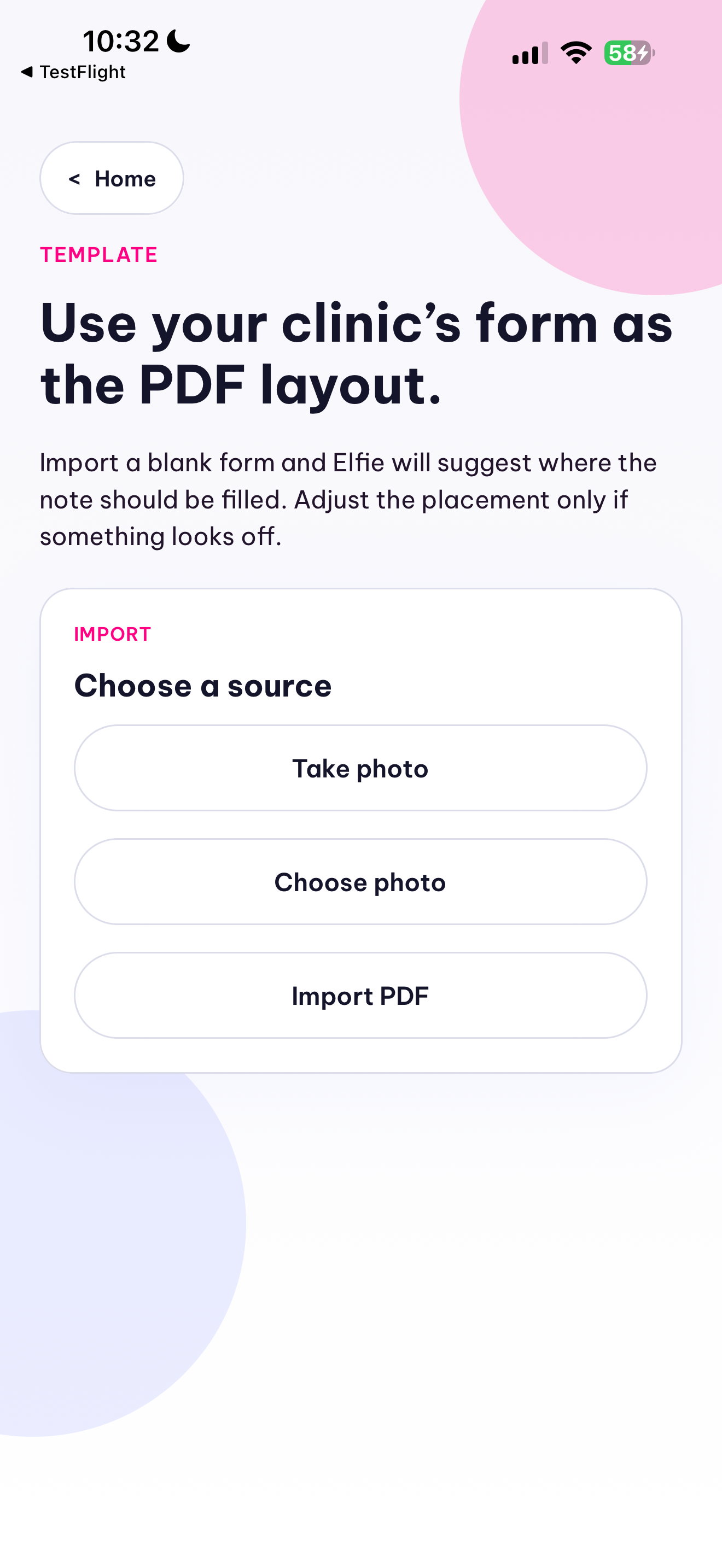
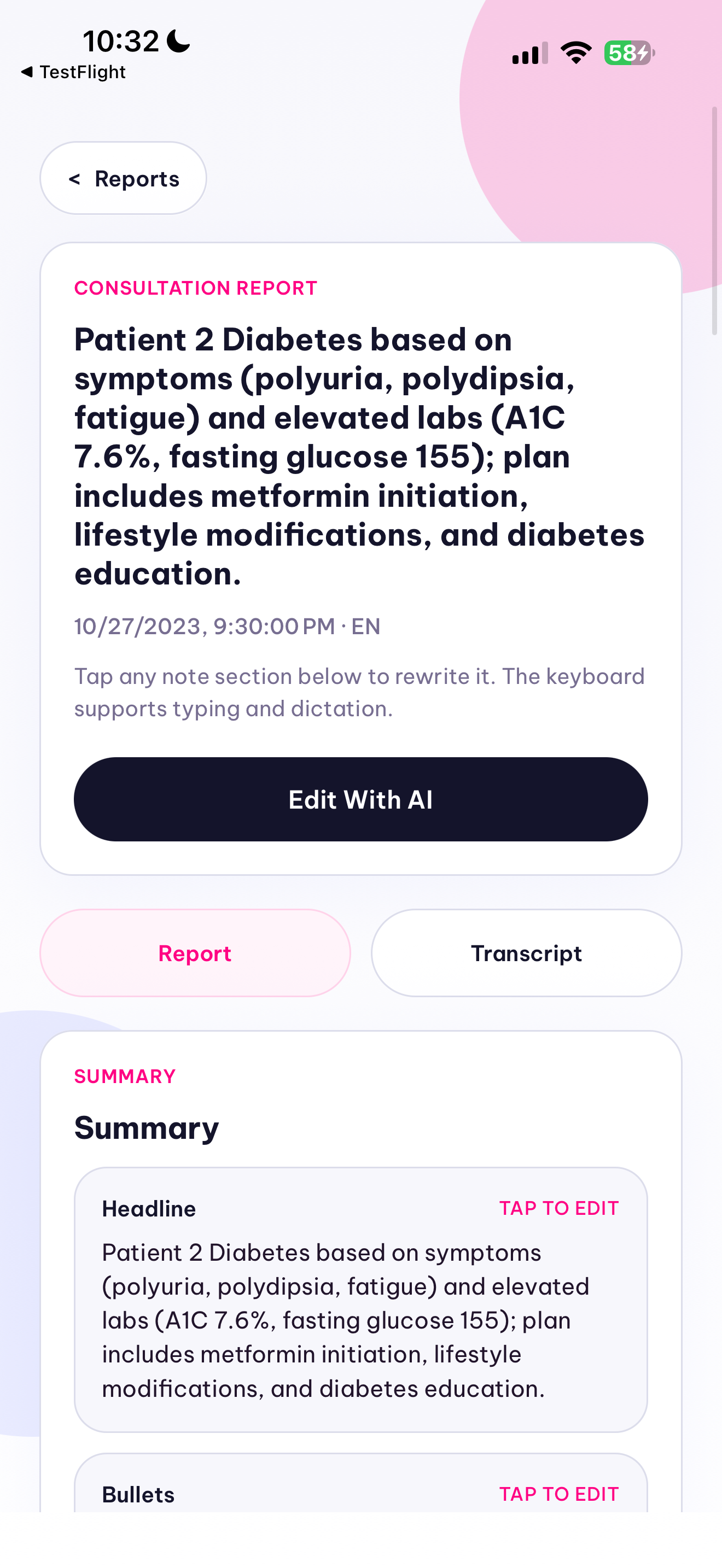
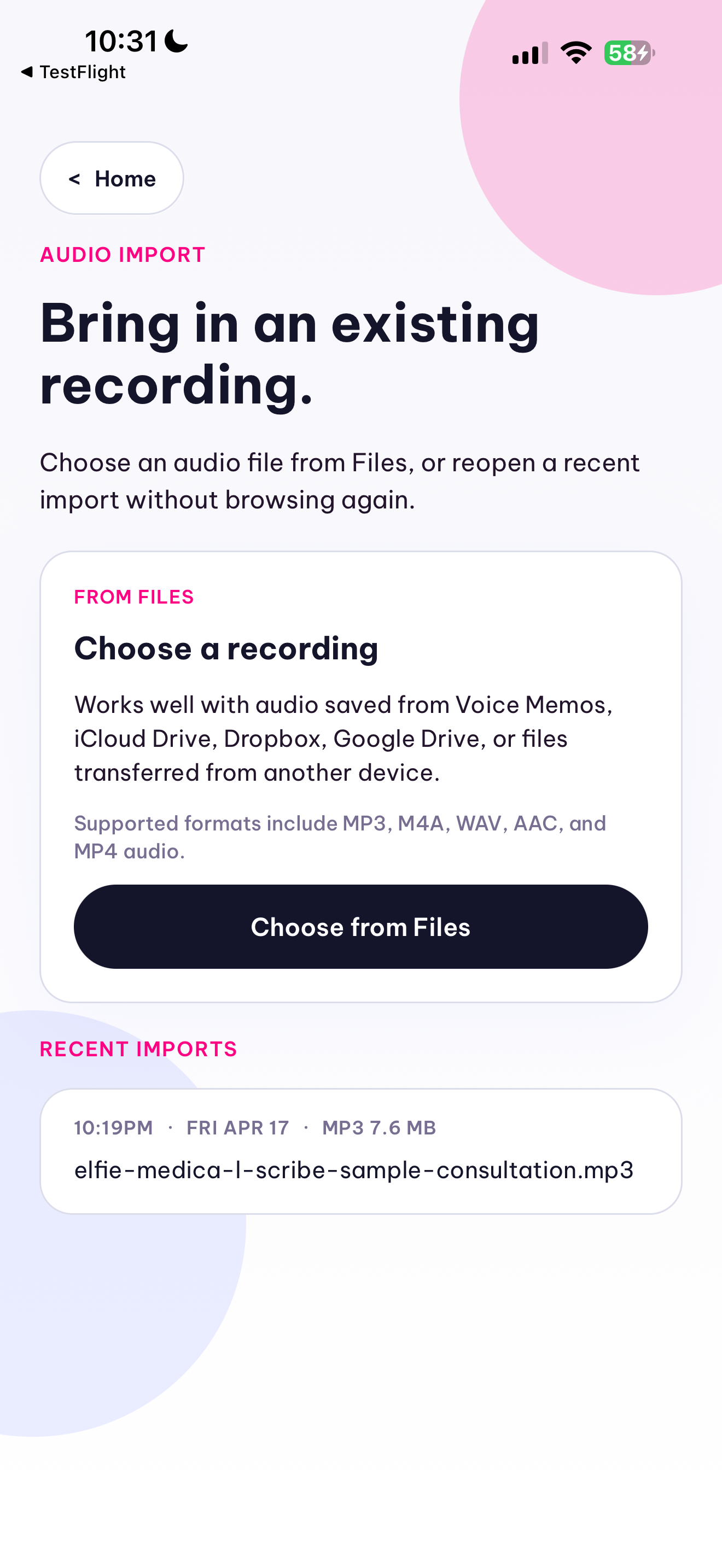
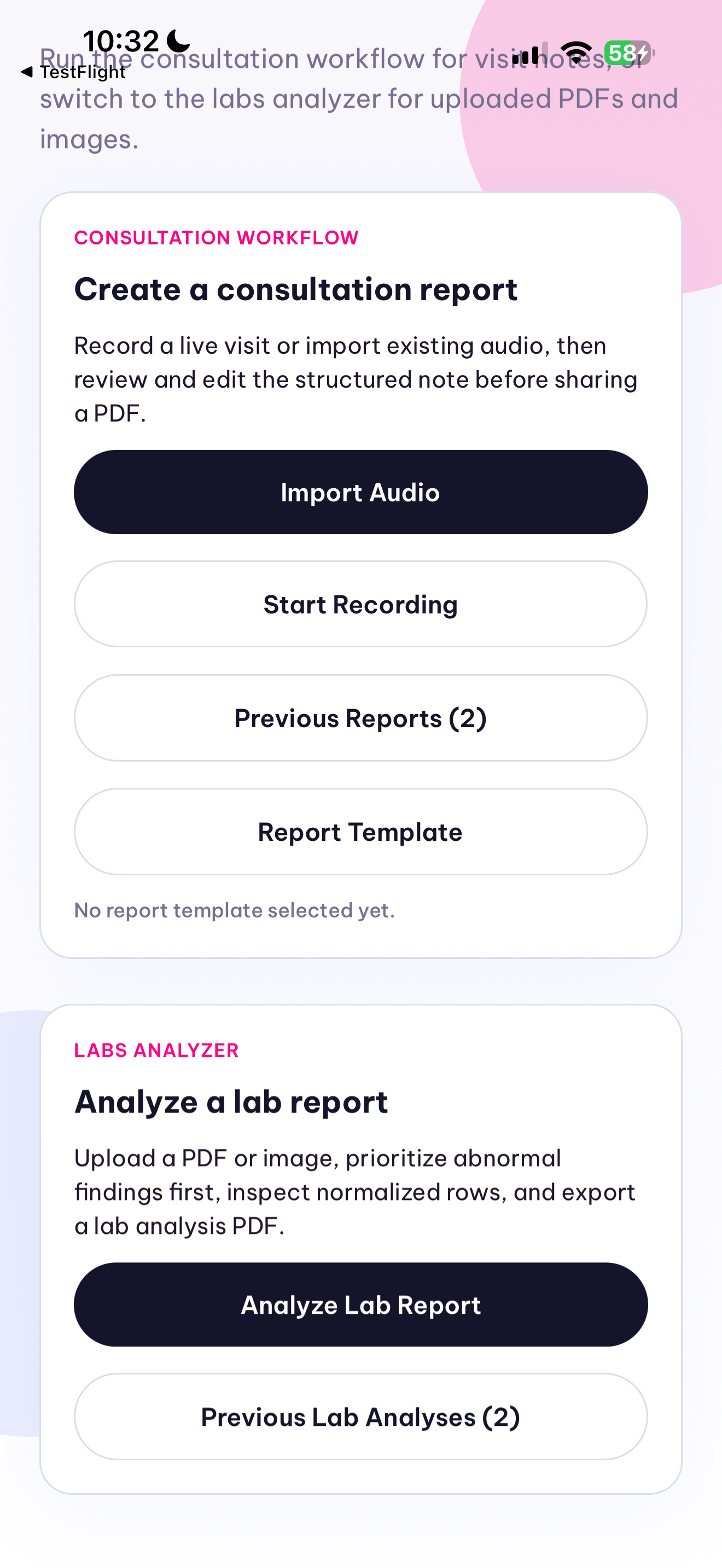
Elfie Scribe now supports two parallel workflows. In the consultation workflow, a clinician records or imports a visit, the backend normalizes the audio with ffmpeg, transcribes it with Qwen ASR, and converts the transcript into a structured SOAP-style ConsultationReport JSON object with qwen3.5-plus instead of generating unstructured prose. The result is rendered in-app as a clinician-reviewable note with explicit missing-information and ambiguity fields, persisted locally, exported as a PDF, and shareable from the phone. We also built a template system so a clinic can import a PDF or photographed paper form and map the structured note into its preferred documentation layout.
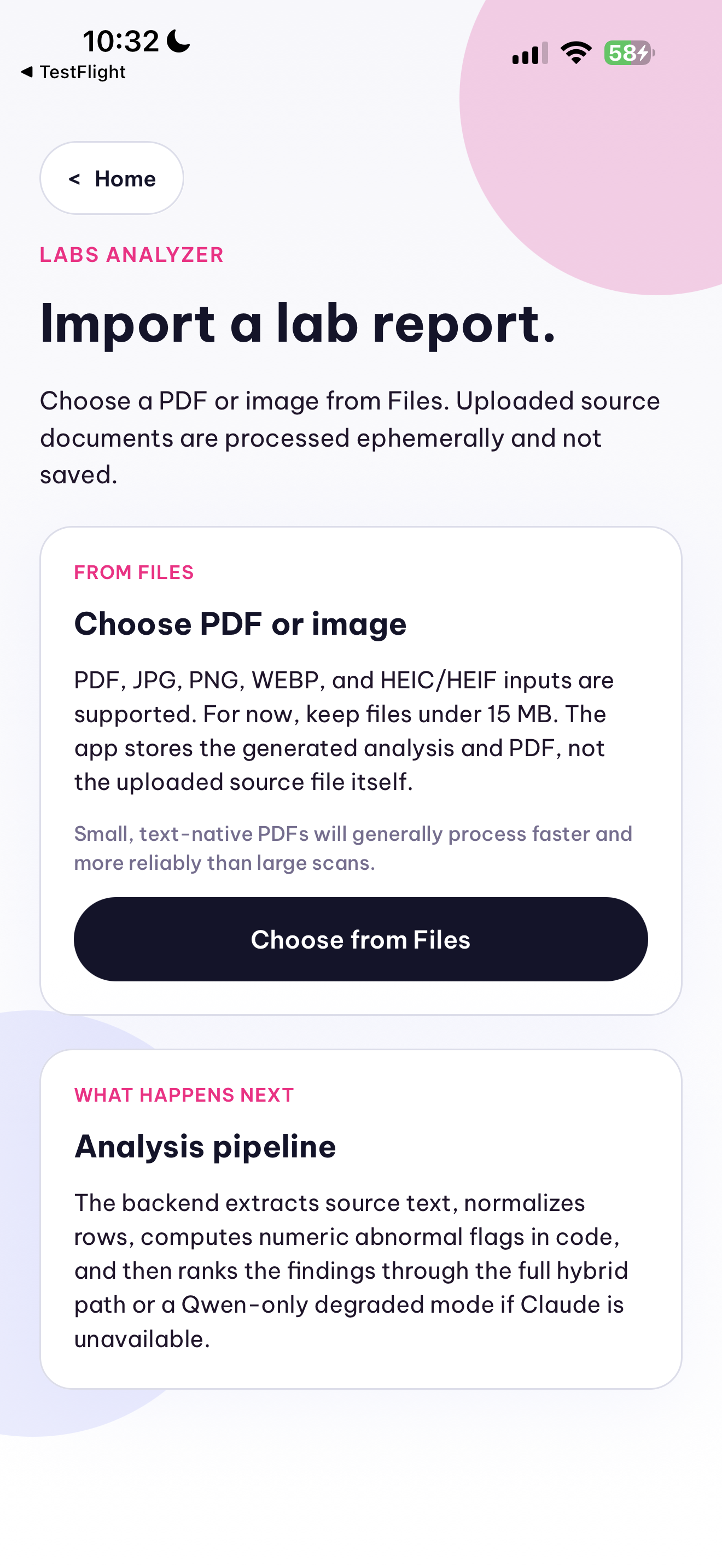
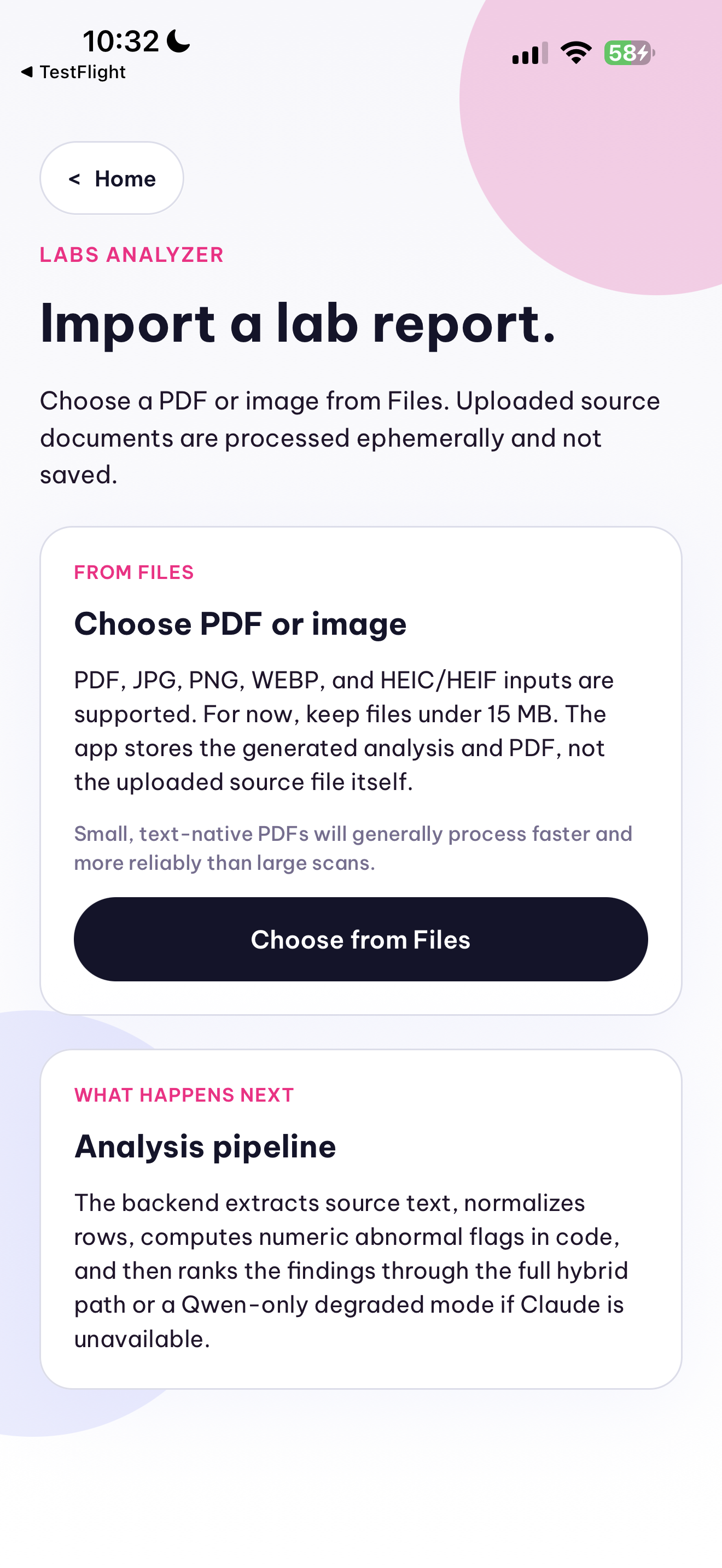
In the lab workflow, the app accepts an uploaded PDF or lab image and turns it into a structured LabAnalysisReport. Text-native PDFs are parsed page by page, while scanned pages or images fall back to OCR or Qwen vision extraction. The backend normalizes rows such as test name, value, unit, and reference range, computes abnormal flags deterministically in code, and generates a prioritized summary of abnormal findings, follow-up buckets, and a shareable PDF. Uploaded lab documents are processed ephemerally and not stored after analysis.
How we built it
We built Elfie Scribe as an iOS-first Expo + React Native app with Expo Router for recording, import, review, local persistence, and PDF/share flows. Behind it is a Railway-hosted Express backend that handles multipart uploads, audio preprocessing with ffmpeg and ffprobe, PDF text extraction and rasterization, model orchestration, and schema validation with Zod before anything reaches the mobile UI.
Both workflows use the same architectural pattern: raw input comes in on the phone, heavy preprocessing and inference stay off-device, model output is forced into structured JSON, and the app renders that structured object instead of trusting free-form prose. That shared design let us add lab analysis as a parallel workflow with its own schema and screens, rather than forcing lab data into the consultation-note model. It also let us keep privacy controls, persistence, export, and review behavior consistent across both tracks.
Challenges we ran into
The hardest engineering problems were reliability and normalization, not just “calling an LLM.” Consultation audio is long, noisy, multilingual, and often poorly structured, so we had to build deterministic preprocessing around ASR: chunking audio into ASR-friendly segments, preserving transcript fidelity across chunks, inferring speaker turns when possible, and handling latency without breaking the mobile UX.
The lab path introduced a different class of ambiguity. Some reports are text-native PDFs, others are scans or phone photos; layouts vary by lab; and values, units, and reference ranges are not presented consistently. We had to combine PDF extraction, OCR or vision fallback, row normalization, deduplication, and deterministic abnormal-flag computation so the result was more useful than “here is some text from a document.” The goal was a structured report that can prioritize what matters while still preserving source snippets and uncertainty.
Privacy and safety made both tracks harder. Free-form model output was not acceptable for downstream rendering or PDF generation, and sensitive clinical data should not be handled like a generic chat prompt. We therefore redact identifiers before consultation extraction by default, delete uploaded lab documents after processing, validate outputs against schemas, and surface missing information and ambiguities explicitly. This is still a hackathon MVP rather than a HIPAA-complete production system, but the architecture is much closer to a deployable or eventually self-hosted solution than a raw prompt-to-paragraph demo.
Use of AI (Qwen Model)
How effectively and meaningfully is Qwen used in your solution?
Qwen is the core inference layer in the product, not an optional enhancement. In challenge #1, Qwen powers the full consultation pipeline: qwen3-asr-flash converts normalized audio chunks into transcript text, and qwen3.5-plus converts that transcript into a structured ConsultationReport JSON object. In challenge #3, Qwen is again on the critical path: it extracts visible text from scanned lab images or rasterized PDF pages, converts lab content into normalized candidate rows, and supports a Qwen-only reasoning path when the hybrid reasoning layer is unavailable.
Qwen is deliberately wrapped in a typed orchestration layer instead of being called directly from the phone. The backend handles preprocessing, keeps credentials off-device, forces JSON-only outputs, validates responses with Zod, normalizes fields into canonical shapes, and runs a repair pass with qwen-flash if a response is malformed. On the lab side, deterministic code computes low/normal/high style flags whenever value and reference range are available, and an optional hybrid reasoning step can enrich prioritization on top of Qwen-extracted rows without replacing Qwen's role in the pipeline.
That means Qwen is used meaningfully across speech recognition, vision-based text extraction, structured data extraction, JSON repair, and fallback reasoning. We also used a local ollama qwen2.5-coder:32b sidecar for bounded development work such as prompt iteration and scaffolding, but the more important point is that the shipping product depends on Qwen to transform raw consultation audio and raw lab documents into structured artifacts that clinicians can review, save, export, and share.
Accomplishments that we're proud of
We are proud that this is no longer just a transcription demo. We shipped two end-to-end clinical workflows in one mobile app: consultation capture to structured note, and lab document upload to prioritized analysis. In both cases, the output is not trapped inside a model response. It can be reviewed in-app, saved locally, exported as a PDF, and shared directly from the device.
We are also proud that the product adapts to clinical reality instead of forcing clinicians into our format. The consultation side can map structured output onto an existing PDF or photographed paper template, and the labs side preserves raw values, ranges, snippets, and quality notes so users can inspect what the system extracted. And yes, we are also proud of the intro video.
What we learned
Our biggest learning is that “AI for healthcare” becomes much more credible when the model is only one component inside a constrained system. Structured schemas, validation, deterministic preprocessing, explicit uncertainty, and clinician review matter as much as model quality. A note or lab summary is more useful when the system can clearly say what is known, what is missing, and what is uncertain than when it simply sounds polished.
We also learned that multimodal clinical inputs demand different treatment. Audio, text-native PDFs, scans, and phone photos all fail in different ways, so a single prompt is not a system. The right pattern for us was Qwen plus orchestration: use models to transform messy unstructured inputs, but use code to handle file processing, normalization, privacy controls, and the parts of the workflow that need repeatable behavior.
What's next for Elfie
Next, we want to connect the two workflows more tightly so a clinician can move from a consultation note to supporting lab analysis in the same patient context. We also want to improve multilingual evaluation, speaker diarization, lab normalization coverage, and handling of scanned reports from different labs and countries. Longer term, bringing in patient history and prior labs could make both workflows more context-aware without compromising the privacy-first structure of the current system.
We would like to build this with Elfie for real, not leave it as a hackathon prototype. That means hardening the backend, improving compliance and deployment options, and moving toward a clinic- or hospital-hosted setup where sensitive data can stay within the organization. If there is a path to pilot work or one of the contract spots, we are ready for it.
Built With
- codex
- qwen
- react-native


Log in or sign up for Devpost to join the conversation.